



Datawhale干货
作者:koin
AI+安全的实践系列分享来了!
11月20日,国内首个AI大模型攻防赛在世界互联网大会乌镇峰会收官。

颁奖仪式:乌镇峰会热议AI反诈:国内首个AI大模型攻防赛收官,全球十强亮相
通过攻防双向赛道竞技,大赛最终角逐出全球十强。
赛后Datawhale邀请到了本届十强,为大家带来系列复盘分享。
今天,我们和防守方向的Top5团队聊一聊。

国内首个AI大模型攻防赛全球十强乌镇亮相
赛道二出题人代表点评
全球AI攻防挑战赛评审委员会成员,中国科学院计算技术研究所副研究员、博导 敖翔:
“康佬带我飞队”采用了层次化集成学习的思想,用多个不同类型的基模型和抽样的训练数据进行训练,再层次化混合推理结果及其相关预测标签作为B榜的伪监督数据进行模型调优。在数据和标签的融合策略上思路清晰且系统化,展现了团队良好的竞赛经验和工程化思维,最终也取得了赛道二的最佳效果。
复盘分享
写在前面
大家好,我是koin,很荣幸受邀分享方案。本次比赛数据量百万级,模型训练的随机性很大,直到比赛最后一天,榜上的名次变化都非常大,最后还是依靠一些运气侥幸才获得了第五名,首先感谢天池平台提供这样一个交流学习的机会,同时在这里也要感谢我们team另外两位模型融合大佬,特别是炼丹蓝图制定师:clwclw。
下面介绍一下整个比赛期间我们做的工作:
数据可视化
本次比赛数据集规模100w+ ,A榜测试集10w,B榜测试集10w ,大致数据可以分为生活类,证件类,海报类,其他。

数据清洗
按照官方的说法,数据的构建方式为在原始图像数据上针对文字区域采用copy move,splicing,removal,局部AIGC等方式进行数字篡改编辑。
实际可视化效果发现数据标注质量不佳,不排除纯模型伪标签给到选手的可能,难以进行人工清洗。
比赛中途尝试过去除部分超过白边的框,模型掉点,榜上有轻微的提点。

数据去重
在初赛阶段,我们发现划分的验证集精度明显高于线上A榜测试集精度(验证集95+,线上70+),怀疑是线上线下数据分布差异大,并且验证集中可能出现和训练集高度相似的样本,通过简单的真值可视化筛查,发现训练集中确实存在大量的相似样本,可能是官方对训练集做了一定的离线增强处理。
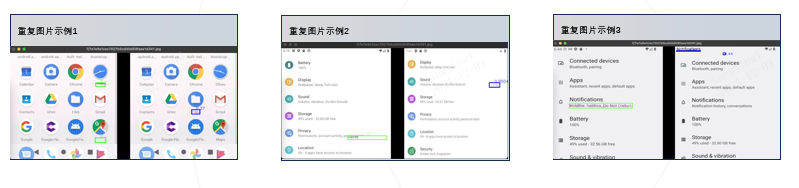
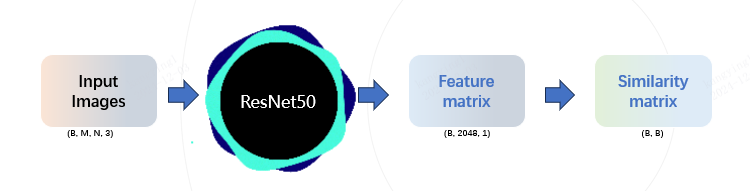
所以使用ResNet50快速的构建图片的特征库,然后基于构建的特征库,计算了测试集中所有样本和训练集所有样本的相似度,筛选出相似度top2的样本,并通过可视化发现有一定数量的测试集在训练集中也存在高度相似的样本,对此我们也基于找出的共3.5w数据,训练了一个专家模型,用于后续的模型融合。
数据拆分
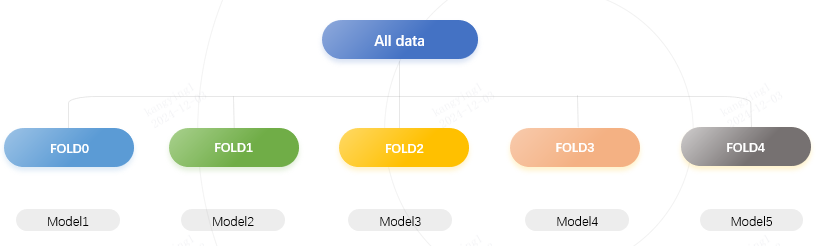
考虑到数据集样本数量较多(100w,相当于COCO的数倍),一方面对过于宽泛的数据分布,模型的学习难度较大,可能会发生欠拟合;另一方面,使用多个模型学习不同的数据分布,再通过wbf等方式进行模型融合,可以提高最终的检测精度;此外,百万量级数据全量训练,即使在训练资源充足的前提下,每个样本也仅能被训练到几次,难以对在线数据增强方案进行优化。
因此,采用类似五折交叉验证的方式,将数据分成5份,训练了5个模型并分别提交测试性能。
数据伪标签
在初赛A榜期间,尝试用当时最好的模型,对全量数据打了伪标签,补充了阈值0.8以上的框的标注,伪标签的增加同样是线下掉点,线上轻微提升,但是B榜掉点,这也体现了数据分布的随机性。

模型选型
从官方给定的baseline出发,考虑现在比较新的transformer模型,前期全量数据实验选定后续都是用CO-DETR-ViT模型,时间不够的情况下,后期新加入一些CO-DETR-SWIN-L的模型,所有的模型TTA后使用WBF进行融合。

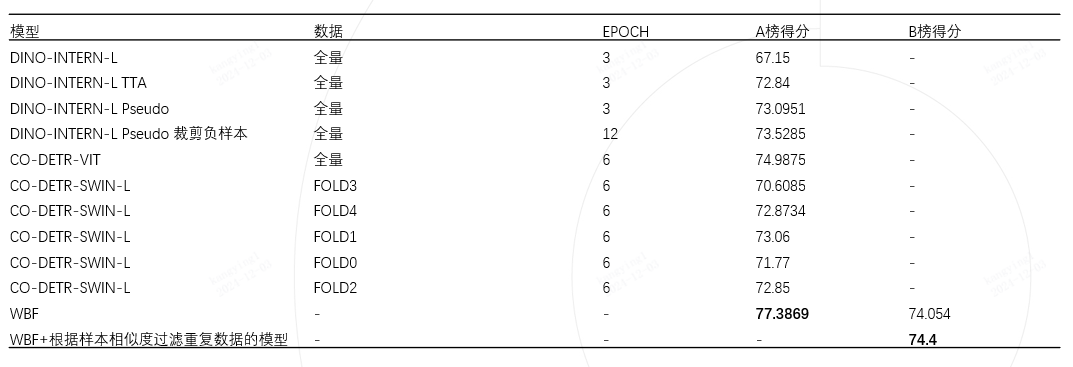
模型指标
从比赛开始到结束我们的模型指标迭代见下表。
总结反思
感谢主办方举办这次比赛,可以在超大规模的数据上验证和沉淀我们的算法能力,因为我们团队都是在职员工,所以在国庆期间资源充足的情况下做了很多无脑的全量实验,缺乏对于超大规模数据的细致分析,在与其他团队赛后交流过程也发现我们其实有很多值得改进的地方,大致总结如下:



















 2376
2376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









