




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:TA-V2A: Textually Assisted Video-to-Audio Generation
论文链接:https://arxiv.org/pdf/2503.10700
开源代码:暂无
导读
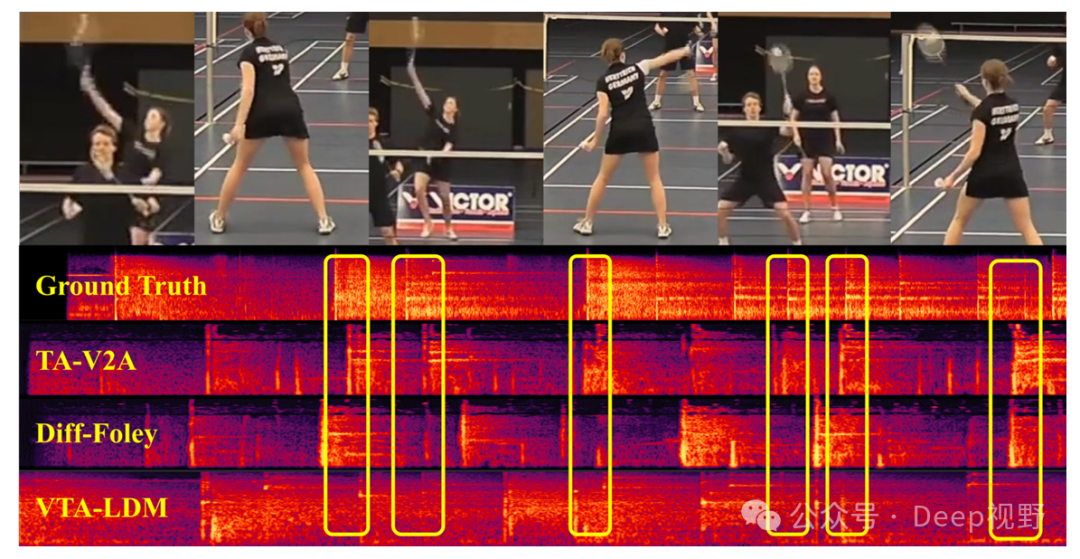
近年来,视频到音频这一特定模态转换任务受到了广泛关注。从视频中生成相应音频的能力对于增强虚拟现实体验、自动视频拟音合成以及提高机器人感知和理解环境的性能等应用至关重要。
简介
随着人工智能生成内容(AIGC)的不断发展,视频到音频(V2A)生成已成为一个关键领域,在多媒体编辑、增强现实和自动化内容创作等方面具有广阔的应用前景。虽然Transformer和扩散模型推动了音频生成的发展,但从视频中提取精确语义信息仍然是一个重大挑战,因为当前模型往往仅依赖基于帧的特征,从而丢失了序列上下文信息。为了解决这一问题,我们提出了TA-V2A方法,该方法整合了语言、音频和视频
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









