




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列
论文名:TPDiff: Temporal Pyramid Video Diffusion Model
论文链接:https://arxiv.org/pdf/2503.09566
项目链接:https://showlab.github.io/TPDiff/
导读
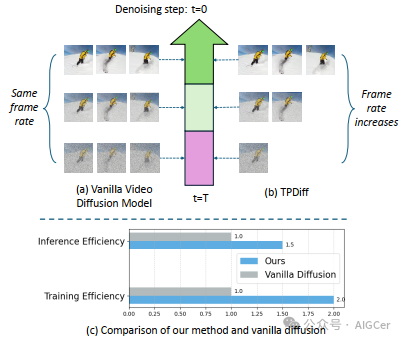
视频扩散模型的发展揭示了一个重大挑战:巨大的计算需求。为了缓解这一挑战,我们注意到扩散的逆过程具有内在的熵减特性。鉴于视频模态中的帧间冗余,在高熵阶段保持全帧率是不必要的。基于这一见解,我们提出了TPDiff,一个统一的框架来提高训练和推理效率。通过将扩散过程划分为几个阶段,我们的框架在扩散过程中逐步提高帧率,仅在最后阶段以全帧率运行,从而优化计算效率。为了训练多阶段扩散模型,我们引入了一个专门的训练框架:分阶段扩散。通过在对齐的数据和噪声下求解扩散的分区概率流常微分方程(ODE),我们的训练策略适用于各种扩散形式,并进一步提高了训练效率。全面的实验评估验证了我们方法的通用性,证明了训练成本的降低和推理效率的提高。
简介
随着扩散模型的发展,视频生成取得了重大突破。最先进的视频扩散模型不仅使个人能够进行艺术创作,还在机器人技术和虚拟现实等其他领域展现出巨大潜力。尽管视频扩散模型性能强大,但对空间和时间分布进行联合建模的复杂性使得它们的训练成本高得令人望而却步。此外,随着对长视频需求的增加,训练和推理成本也将相应持续增加。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









