






介绍:手上有onnx模型文件,想用mingw32编译来推理,但onnx格式是不支持mingw32的,所以转为mnn格式来实现。MNN是一个高效、轻量的深度学习框架,支持深度模型推理与训练。
mingw32编译可以参考这篇。
61、Window11+Clion+MinGW32编译MNN使用_mnn win11 编译-优快云博客
1.下载文件和安装环境
1下载MNN,GitHub给的是源文件,可以按需要选择对应的编译器进行编译,本文只介绍mingw32进行编译。
下载解压得到一个MNN-master文件夹。
下载Cmake,下载最近版本的.msi安装包,安装时将其加入到环境变量。
CMake - Upgrade Your Software Build System
2.生成模型转换工具
mnn提供了从onnx生成mnn的模型转换工具MNNConvert,但是需要用Visual Studio来编译MNN-master文件夹的代码来生成这个MNNConvert转换工具。
可以直接用我生成好的,就不用安装Visual Studio,GitHub地址如下:
https://github.com/ZhuangJialin1996/MyMNNConvert
下面是演示用Visual Studio生成这两个工具文件,用现成的可以跳过。
Visual Studio下载地址:Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器
安装ninja,参考这篇。
问题描述:在Windows下没有预装ninja工具_windows安装ninja-优快云博客
这里用的是vs2022,勾选C++开发工具,安装。
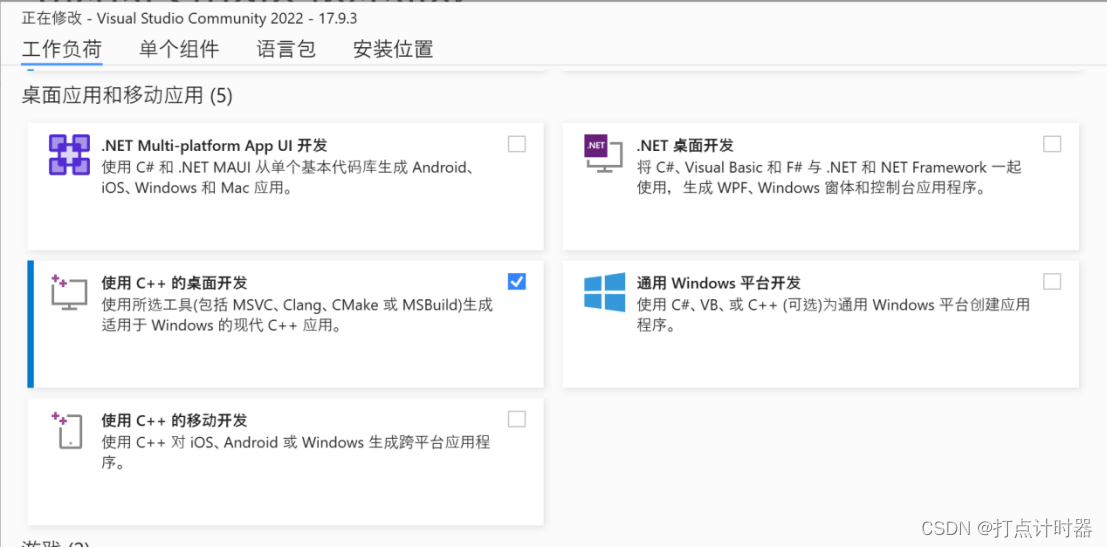
PS:VS盗版可能出现问题,慎用。
vs2022安装好后,按照mnn文档给的流程生成可执行文件。
打开VS编译x64架构程序的虚拟环境

跳转到MNN-master文件夹下,执行以下指令。
mkdir build
cd build
cmake -G "Ninja" -DMNN_BUILD_SHARED_LIBS=OFF -DMNN_BUILD_CONVERTER=ON -DCMAKE_BUILD_TYPE=Release -DMNN_WIN_RUNTIME_MT=ON ..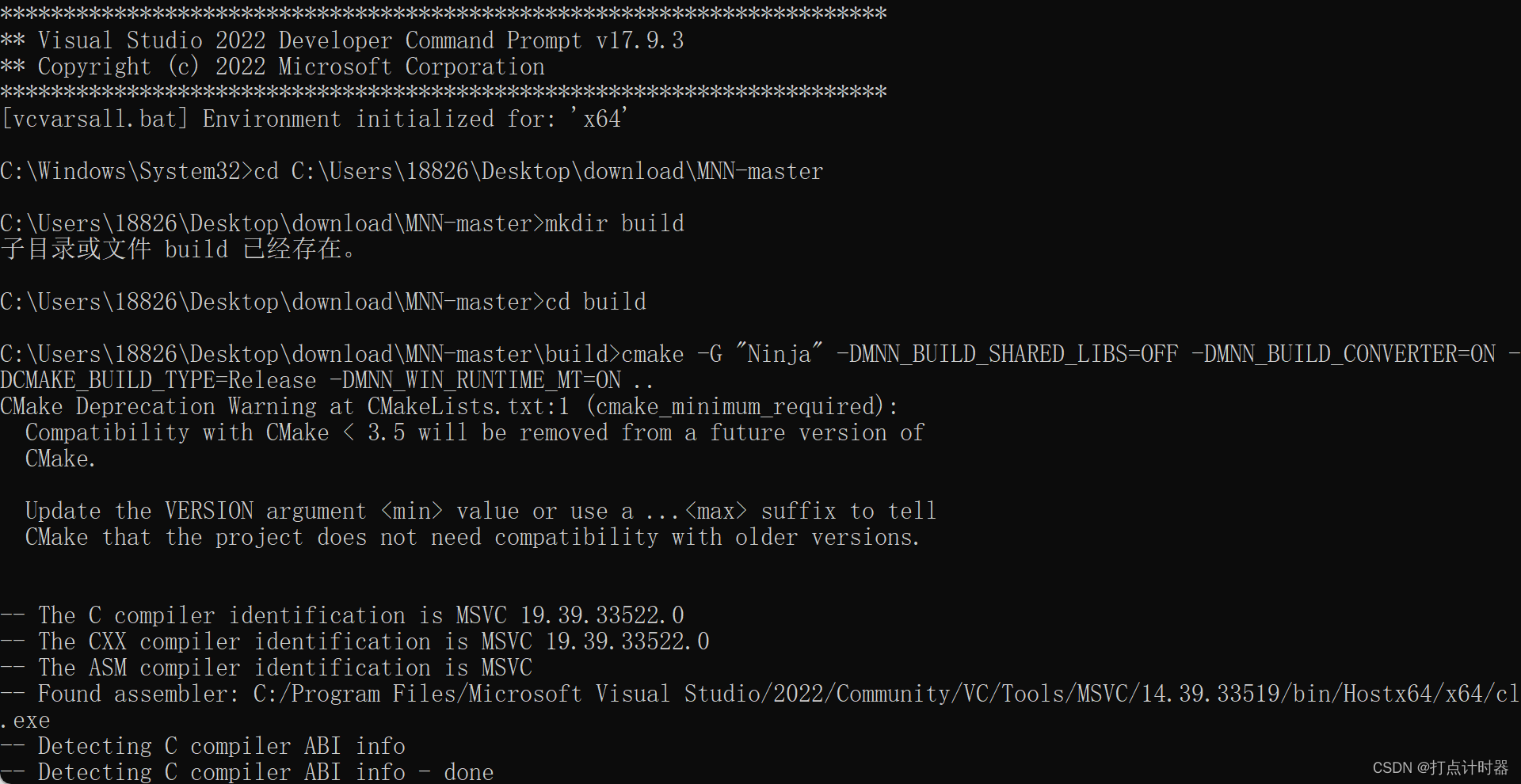
构建后,编译。
ninja完成后会在MNN-master\build下生成MNNConvert.exe工具和MNNConvert.pdb库
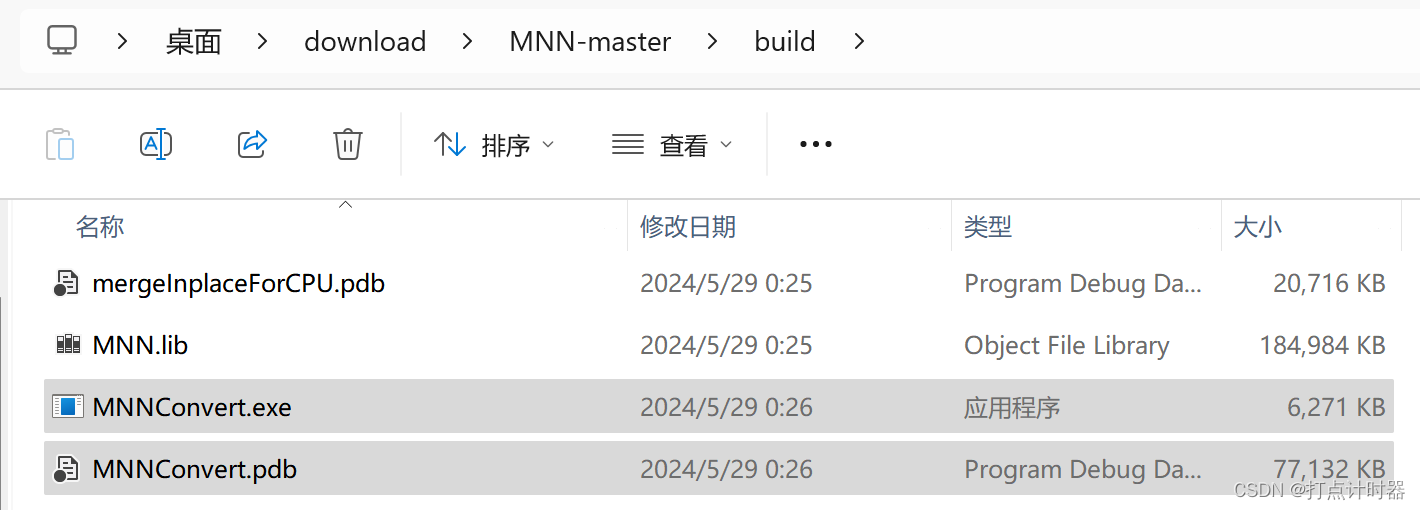
3.进行模型转换
有了工具就可以进行下面的模型转换。将上面两个工具文件,和onnx模型放进来。
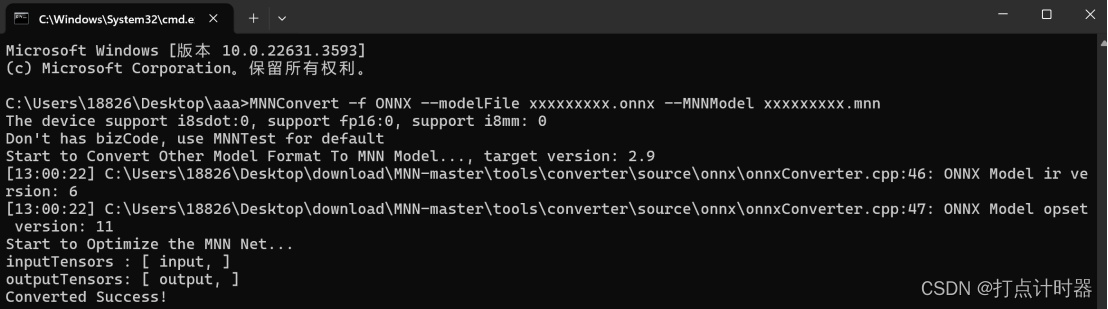
然后用下面的命令行将xxxxxxxxx.onnx的模型转换为xxxxxxxxx.mnn模型,文件名自己定义
命令行
MNNConvert -f ONNX --modelFile xxxxxxxxx.onnx --MNNModel xxxxxxxxx.mnn模型转换完成

4.编译mnn生成mnn的库文件
下面是编译mnn生成后面C++推理需要的库文件。
我这里用的编译器是QT5.9.9自带的mingw32,根据安装QT的位置,先配置一下编译器路径到环境变量
qt下载地址
Index of /new_archive/qt/5.9/5.9.9
到MNN-master文件夹内,修改CMakeLists.txt配置,配置选项根据自己环境和需求来自定义配置
这里给出我的配置,做为参考:
# build options
option(MNN_USE_SYSTEM_LIB "For opencl and vulkan, use system lib or use dlopen" OFF)
option(MNN_BUILD_HARD "Build -mfloat-abi=hard or not" OFF)
option(MNN_BUILD_SHARED_LIBS "MNN build shared or static lib" ON)
option(MNN_WIN_RUNTIME_MT "MNN use /MT on Windows dll" OFF)
option(MNN_FORBID_MULTI_THREAD "Disable Multi Thread" OFF)
option(MNN_OPENMP "Use OpenMP's thread pool implementation. Does not work on iOS or Mac OS" OFF)
option(MNN_USE_THREAD_POOL "Use MNN's own thread pool implementation" ON)
option(MNN_BUILD_TRAIN "Build MNN's training framework" OFF)
option(MNN_BUILD_DEMO "Build demo/exec or not" OFF)
option(MNN_BUILD_TOOLS "Build tools/cpp or not" ON)
option(MNN_BUILD_QUANTOOLS "Build Quantized Tools or not" OFF)
option(MNN_EVALUATION "Build Evaluation Tools or not" OFF)
option(MNN_BUILD_CONVERTER "Build Converter" OFF)
option(MNN_SUPPORT_DEPRECATED_OP "Enable MNN's tflite quantized op" OFF)
option(MNN_DEBUG_MEMORY "MNN Debug Memory Access" OFF)
option(MNN_DEBUG_TENSOR_SIZE "Enable Tensor Size" OFF)
option(MNN_GPU_TRACE "Enable MNN Gpu Debug" OFF)
option(MNN_SUPPORT_RENDER "Enable MNN Render Ops" OFF)
option(MNN_SUPPORT_TRANSFORMER_FUSE "Enable MNN transformer Fuse Ops" OFF)
option(MNN_PORTABLE_BUILD "Link the static version of third party libraries where possible to improve the portability of built executables" OFF)
option(MNN_SEP_BUILD "Build MNN Backends and expression separately. Only works with MNN_BUILD_SHARED_LIBS=ON" OFF)
option(NATIVE_LIBRARY_OUTPUT "Native Library Path" OFF)
option(NATIVE_INCLUDE_OUTPUT "Native Include Path" OFF)
option(MNN_AAPL_FMWK "Build MNN.framework instead of traditional .a/.dylib" OFF)
option(MNN_WITH_PLUGIN "Build with plugin op support." OFF)
option(MNN_BUILD_MINI "Build MNN-MINI that just supports fixed shape models." OFF)
option(MNN_USE_SSE "Use SSE optimization for x86 if possiable" OFF)
option(MNN_BUILD_CODEGEN "Build with codegen" OFF)
option(MNN_ENABLE_COVERAGE "Build with coverage enable" OFF)
option(MNN_BUILD_PROTOBUFFER "Build with protobuffer in MNN" ON)
option(MNN_BUILD_OPENCV "Build OpenCV api in MNN." OFF)
option(MNN_BUILD_LLM "Build llm library based MNN." OFF)
option(MNN_BUILD_DIFFUSION "Build diffusion demo based MNN." OFF)
option(MNN_INTERNAL "Build with MNN internal features, such as model authentication, metrics logging" OFF)
option(MNN_JNI "Build MNN Jni for java to use" OFF)在当前目录打开命令行,指定使用mingw32来进行编译
mkdir build_mingw32
cd build_mingw32
cmake -G "MinGW Makefiles" ..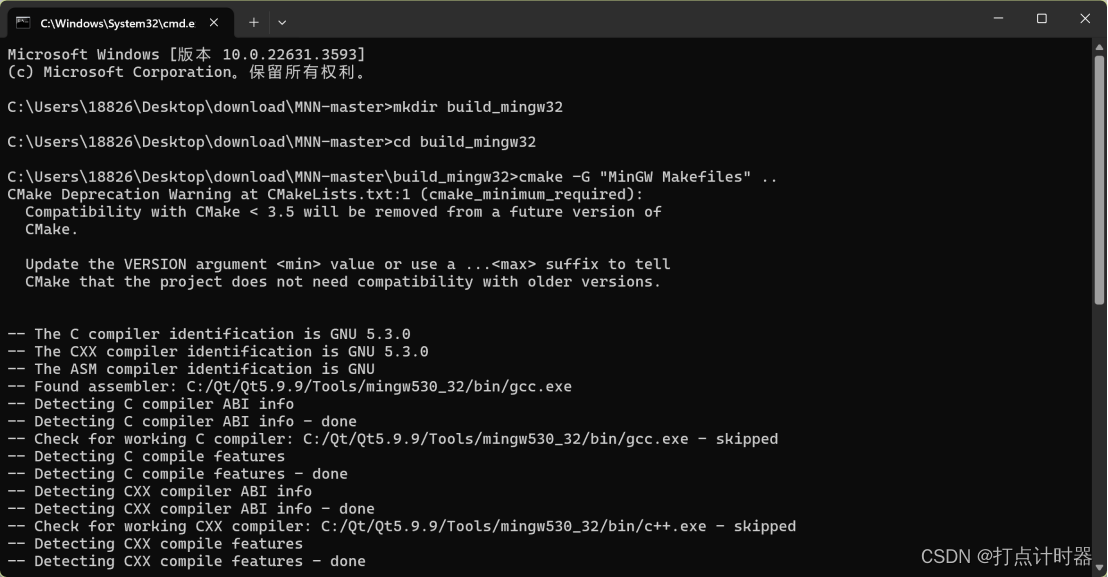
等待Cmake完成,再执行编译命令
make -j8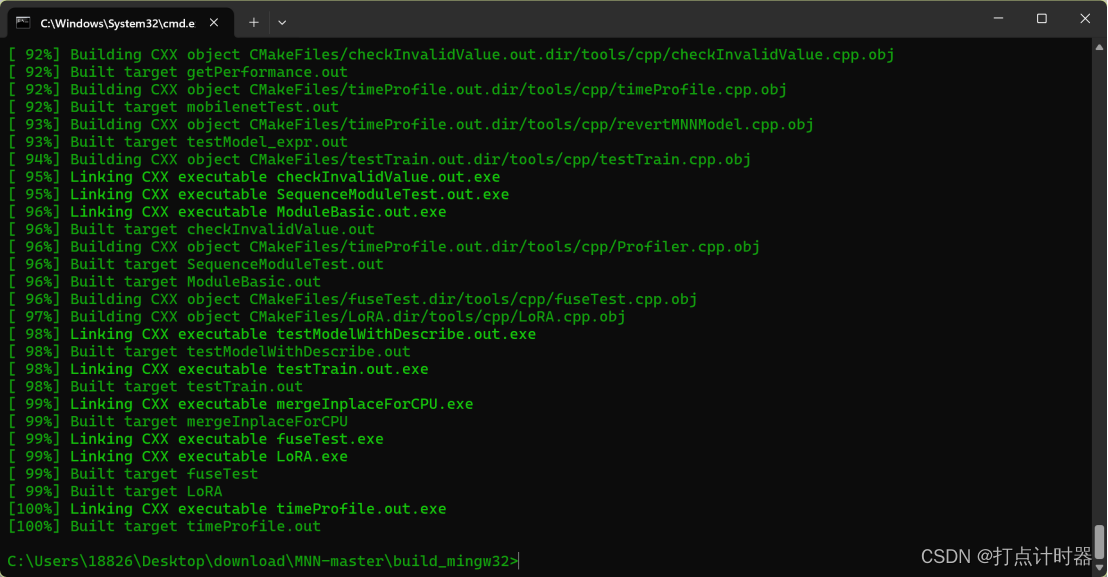
PS:如果make命令不存在,把qt的mingw32-make.exe复制一个改成make.exe。
编译完成,生成的两个库文件libMNN.dll、libMNN.dll.a就是推理需要的库文件。
5.C++进行模型推理
前面生成的两个库文件libMNN.dll、libMNN.dll.a,再加上include\MNN文件夹里面的头文件,可以用来模型推理。
官方给出了3种方法,session、Module和Expr的方式(参考官方文档)进行推理,
Session API使用 — MNN-Doc 2.1.1 documentation
Module API使用 — MNN-Doc 2.1.1 documentation
下面演示使用session
#include "MNN/Interpreter.hpp"
#include "MNN/Tensor.hpp"
#include "MNN/ImageProcess.hpp"
int main()
{
// 加载模型
std::string modelFilePath = "./xxxxxxxxx.mnn";
auto net = std::shared_ptr<MNN::Interpreter>(MNN::Interpreter::createFromFile(modelFilePath.c_str()));
MNN::ScheduleConfig config;
config.type = MNN_FORWARD_AUTO;
auto session = net->createSession(config);
// 从txt中读取测试输入数据
std::vector<float> inputData;
// 赋值给inputData
inputData[0] = 1; // 根据具体数据修改
// 网络输入数据
auto inputTensor = net->getSessionInput(session, NULL);
memcpy(inputTensor->host<float>(), inputData.data(), inputData.size() * sizeof(float));
// 执行推理
net->runSession(session);
auto outputTensor = net->getSessionOutput(session, NULL);
// 网络输出数据
float* outputData = outputTensor->host<float>();
return 0;
}下面演示使用Module
#include "MNN/expr/ExprCreator.hpp"
#include "MNN/expr/Module.hpp"
using namespace MNN::Express;
int main() {
// 从模型文件加载并创建新Module
// 输入名:多个输入时按顺序填入,其顺序与后续 onForward 中的输入数组需要保持一致
const std::vector<std::string> input_names{"input"};
// 输出名,多个输出按顺序填入,其顺序决定 onForward 的输出数组顺序
const std::vector<std::string> output_names{"output"};
MNN::ScheduleConfig sConfig;
sConfig.type = MNN_FORWARD_OPENCL;
std::shared_ptr<MNN::Express::Executor::RuntimeManager> rtmgr(MNN::Express::Executor::RuntimeManager::createRuntimeManager(sConfig), MNN::Express::Executor::RuntimeManager::destroy);
// rtmgr->setCache(".cachefile");
Module::Config mdconfig; // default module config
std::unique_ptr<Module> module; // module
// 若rtMgr为 nullptr ,Module会使用Executor的后端配置
module.reset(Module::load(input_names, output_names, EncodermodelPath.c_str(), rtmgr, &mdconfig));
std::vector<VARP> inputs(1);
// 对于 tensoflow 转换过来的模型用NHWC,由 onnx 转换过来的模型用NCHW
inputs[0] = MNN::Express::_Input({1, inlength}, NCHW, halide_type_of<float>());
// 设置输入数据
std::vector<float*> input_pointer = {inputs[0]->writeMap<float>()};
for (int i = 0; i < inlength; ++i) {
input_pointer[0][i] = data_norm[0][i];
}
// 执行推理
std::vector<MNN::Express::VARP> outputs = module->onForward(inputs);
// 获取输出
auto output_ptr = outputs[0]->readMap<float>();
return 1;
}
















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









