




FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.11.9
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
1. 准备知识
1.1 检查环境
# 导入PyTorch库
import torch
# 导入PyTorch的神经网络模块
import torch.nn as nn
# 导入torchvision中的transforms模块,用于图像预处理
import torchvision.transforms as transforms
# 导入整个torchvision库
import torchvision
# 从torchvision库中导入transforms和datasets模块
from torchvision import transforms, datasets
# 导入操作系统接口库os,图像处理库PIL,路径操作库pathlib,以及警告控制库warnings
import os, PIL, pathlib, warnings
# 设置硬件设备,如果有GPU则使用,没有则使用cpu
# torch.device()函数用于指定设备,"cuda"表示GPU,"cpu"表示CPU
# torch.cuda.is_available()函数用于检查系统是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 打印当前PyTorch版本
print(torch.__version__)
# 打印当前设备,以确认是使用GPU还是CPU
device
输出:

1.2 数据导入
导入本地数据
# 导入所需的模块
import os, PIL, random, pathlib
# 设置数据目录的路径
data_dir = './data/'
# 将字符串路径转换为Path对象,便于进行路径操作
data_dir = pathlib.Path(data_dir)
# 使用glob方法获取data_dir下的所有文件和文件夹的路径,并存储在列表data_paths中
data_paths = list(data_dir.glob('*'))
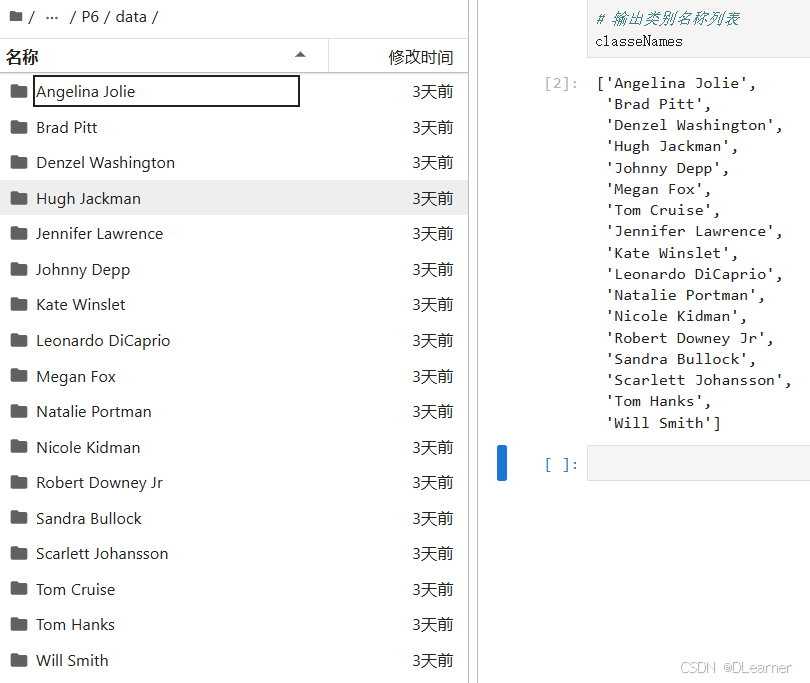
# 通过列表推导式,从data_paths列表中的每个路径字符串中提取出类别名称
# 假设路径的结构是 './data/类别名称/文件名',这里通过split("/")分割路径,并取第二个元素作为类别名称
classeNames = [str(path).split("/")[1] for path in data_paths]
# 输出类别名称列表
classeNames
输出:
# 导入torchvision库中的transforms模块
from torchvision import transforms
# 导入torchvision库中的datasets模块
from torchvision import datasets
# 使用transforms.Compose()创建一个transforms.Compose对象,用于串联多个图像变换操作
train_transforms = transforms.Compose([
# transforms.Resize([224, 224]):将输入图片resize成统一尺寸224x224
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip():随机水平翻转图片,这一行被注释掉了,所以实际上不会执行随机水平翻转操作
# transforms.RandomHorizontalFlip(), # 随机水平翻转
# transforms.ToTensor():将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
# transforms.Normalize():标准化处理,转换为标准正态分布(高斯分布),使模型更容易收敛
# 这里的mean和std是预定义的值,通常是基于ImageNet数据集计算得到的
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
# 使用datasets.ImageFolder加载数据集,指定数据集的路径和变换操作
# "./data/" 是数据集的路径,transform=train_transforms 指定了上面定义的图像变换操作
total_data = datasets.ImageFolder("./data/", transform=train_transforms)
# total_data变量现在包含了应用了变换操作的数据集,可以用于训练深度学习模型
total_data
输出:

# 假设total_data是使用ImageFolder加载的数据集
total_data.class_to_idx
输出:

1.3 划分数据集
# 计算训练集大小,占总数据集的80%
train_size = int(0.8 * len(total_data))
# 计算测试集大小,即总数据集减去训练集大小
test_size = len(total_data) - train_size
# 使用random_split函数随机分割数据集为训练集和测试集
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
# 设置批处理大小
batch_size = 32
# 创建训练集的DataLoader
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True, # 是否打乱数据
num_workers=1) # 加载数据的子进程数量
# 创建测试集的DataLoader
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True, # 是否打乱数据
num_workers=1) # 加载数据的子进程数量
# 遍历测试集的DataLoader
for X, y in test_dl:
# 打印特征数据X的形状,[N, C, H, W]分别代表批次大小、通道数、高度、宽度
print("Shape of X [N, C, H, W]: ", X.shape)
# 打印标签数据y的形状和数据类型
print("Shape of y: ", y.shape, y.dtype)
break # 只打印第一个批次的数据形状和类型
输出:

2. 调用官方/本地的VGG-16模型
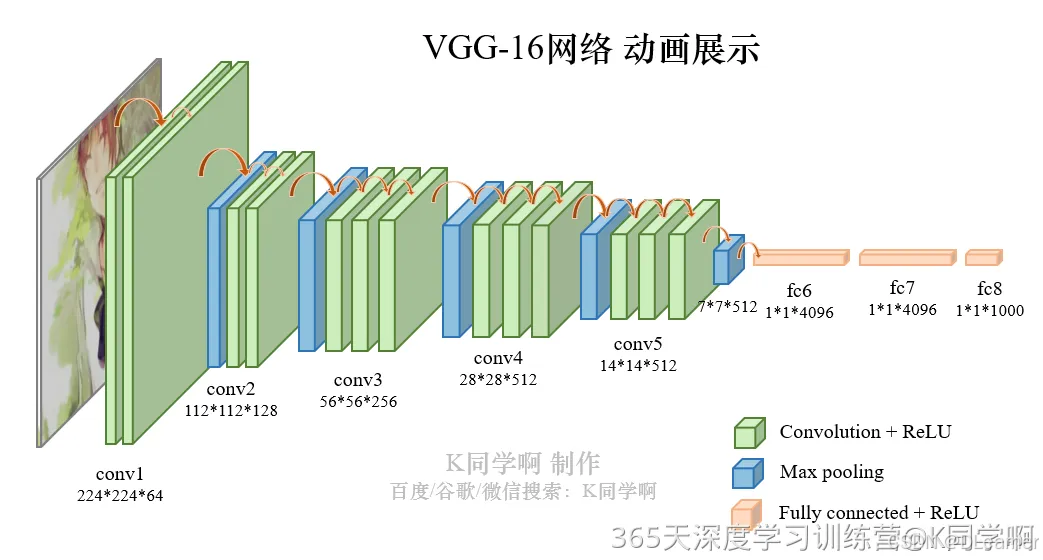
VGG-16(Visual Geometry Group-16)是由牛津大学视觉几何组(Visual Geometry Group)提出的一种深度卷积神经网络架构,用于图像分类和对象识别任务。VGG-16在2014年被提出,是VGG系列中的一种。VGG-16之所以备受关注,是因为它在ImageNet图像识别竞赛中取得了很好的成绩,展示了其在大规模图像识别任务中的有效性。
以下是VGG-16的主要特点:
- 深度:VGG-16由16个卷积层和3个全连接层组成,因此具有相对较深的网络结构。这种深度有助于网络学习到更加抽象和复杂的特征。
- 卷积层的设计:VGG-16的卷积层全部采用3x3的卷积核和步长为1的卷积操作,同时在卷积层之后都接有ReLU激活函数。这种设计的好处在于,通过堆叠多个较小的卷积核,可以提高网络的非线性建模能力,同时减少了参数数量,从而降低了过拟合的风险。
- 池化层:在卷积层之后,VGG-16使用最大池化层来减少特征图的空间尺寸,帮助提取更加显著的特征并减少计算量。
- 全连接层:VGG-16在卷积层之后接有3个全连接层,最后一个全连接层输出与类别数相对应的向量,用于进行分类。
VGG-16结构说明:
● 13个卷积层(Convolutional Layer),分别用blockX_convX表示;
● 3个全连接层(Fully connected Layer),用classifier表示;
● 5个池化层(Pool layer)。
import torch
import torchvision.models as models
# 检查是否有可用的GPU,如果有则使用GPU,否则使用CPU
device = "cuda" if torch 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









