



 本文详细介绍了在 Docker 中解决 CUDA driver version is insufficient for CUDA runtime version 错误的方法,包括使用 nvidia-docker 替代 docker,以及如何正确挂载宿主机文件,确保容器能正常运行 GPU 加速应用如 Caffe。
本文详细介绍了在 Docker 中解决 CUDA driver version is insufficient for CUDA runtime version 错误的方法,包括使用 nvidia-docker 替代 docker,以及如何正确挂载宿主机文件,确保容器能正常运行 GPU 加速应用如 Caffe。
遇到报错:Check failed: error == cudaSuccess (35 vs. 0) CUDA driver version is insufficient for CUDA runtime version
参考:
CUDA driver version is insufficient for CUDA runtime version - ONLY DOCKER
Ok I found the solution right after creating the issue:
Instead of sudo docker run -v /home/ubuntu/nvDocker/:/data/ -p 5000:5000 nvidia/digits:6.0-rc I have to use sudo nvidia-docker run -v /home/ubuntu/nvDocker/:/data/ -p 5000:5000 nvidia/digits:6.0-rc
Maybe master/docs/DockerInstall.md should be updated.
从一开始用Docker建立container开始,就要用nvidia-docker 代替 docker。
如果要加载本地宿主机上的文件,直接使用
nvidia-docker run -ti -v /home/dock/Downloads:/usr/Downloads bvlc/caffe:gpu 会出现类似
error while loading shared libraries: libboost_system.so.1.54.0的错误(可参考官网:https://github.com/BVLC/caffe/tree/master/docker)。解决方法可以用数据卷的挂载方法。
解决方法:
1. 首先建立数据卷container(可参考下文挂载方法二)。
创建一个普通的容器。用--name给他指定了一个名(不指定的话会生成一个随机的名子)。:
nvidia-docker run -v /home/dock/Downloads:/usr/Downloads --name dataVol ubuntu64 /bin/bash其中的ubuntu64可以为任意的Image name.
2. 随后建立要使用的container:
创建一个新的容器,来使用这个数据卷。
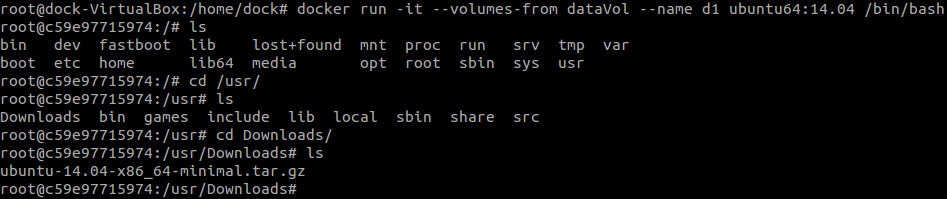
nvidia-docker run -it --volumes-from dataVol bvlc/caffe:gpu /bin/bash此容器可以正常使用caffe及GPU。
(选读)挂载方法:
以下内容转载自:https://blog.youkuaiyun.com/huludan/article/details/52641090
REF:
https://blog.youkuaiyun.com/huludan/article/details/52641090
https://my.oschina.net/piorcn/blog/324202
http://blog.youkuaiyun.com/yangzhenping/article/details/43667785
方法一:docker可以支持把一个宿主机上的目录挂载到镜像里。
docker run -it -v /home/dock/Downloads:/usr/Downloads ubuntu64 /bin/bash
通过-v参数,冒号前为宿主机目录,必须为绝对路径,冒号后为镜像内挂载的路径。

现在镜像内就可以共享宿主机里的文件了。
默认挂载的路径权限为读写。如果指定为只读可以用:ro
docker run -it -v /home/dock/Downloads:/usr/Downloads:ro ubuntu64 /bin/bash
方法二:docker还提供了一种高级的用法。叫数据卷。
数据卷:“其实就是一个正常的容器,专门用来提供数据卷供其它容器挂载的”。感觉像是由一个容器定义的一个数据挂载信息。其他的容器启动可以直接挂载数据卷容器中定义的挂载信息。
看示例:
docker run -v /home/dock/Downloads:/usr/Downloads --name dataVol ubuntu64 /bin/bash
创建一个普通的容器。用--name给他指定了一个名(不指定的话会生成一个随机的名子)。

再创建一个新的容器,来使用这个数据卷。
docker run -it --volumes-from dataVol ubuntu64 /bin/bash
--volumes-from用来指定要从哪个数据卷来挂载数据。
如何在Docker容器内外互相拷贝数据?
从容器内拷贝文件到主机上
- docker cp <containerId>:/file/path/within/container /host/path/target
从主机上拷贝文件到容器内
参考自:
http://stackoverflow.com/questions/22907231/copying-files-from-host-to-docker-container
1.用-v挂载主机数据卷到容器内
- docker run -v /path/to/hostdir:/mnt $container
- 在容器内拷贝
- cp /mnt/sourcefile /path/to/destfile
2.直接在主机上拷贝到容器物理存储系统
A. 获取容器名称或者id :
- $ docker ps
B. 获取整个容器的id
- $ docker inspect -f '{{.Id}}' 步骤A获取的名称或者id
C. 在主机上拷贝文件:
- $ sudo cp path-file-host /var/lib/docker/aufs/mnt/FULL_CONTAINER_ID/PATH-NEW-FILE
- 或者
- $ sudo cp path-file-host /var/lib/docker/devicemapper/mnt/123abc<<id>>/rootfs/root
例子:
- $ docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- d8e703d7e303 solidleon/ssh:latest /usr/sbin/sshd -D cranky_pare
- $ docker inspect -f '{{.Id}}' cranky_pare
- or
- $ docker inspect -f '{{.Id}}' d8e703d7e303
- d8e703d7e3039a6df6d01bd7fb58d1882e592a85059eb16c4b83cf91847f88e5
- $ sudo cp file.txt /var/lib/docker/aufs/mnt/**d8e703d7e3039a6df6d01bd7fb58d1882e592a85059eb16c4b83cf91847f88e5
3.用输入输出符
- docker run -i ubuntu /bin/bash -c 'cat > /path/to/container/file' < /path/to/host/file/
或者
- docker exec -it <container_id> bash -c 'cat > /path/to/container/file' < /path/to/host/file/

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









