




 本文探讨了信号预测中的自相关函数应用,通过最小二乘法求解预测系数,详细推导了矩阵形式的预测方程,并介绍了最小二乘法原理及在过拟合情况下的正则化处理。
本文探讨了信号预测中的自相关函数应用,通过最小二乘法求解预测系数,详细推导了矩阵形式的预测方程,并介绍了最小二乘法原理及在过拟合情况下的正则化处理。
作业推导:
E[d2]=E[(S(k)−Se(k))2]=E[(S(k)−∑i=1NaiS(k−i))2]E\left[d^{2}\right]=E\left[\left(S(k)-S_{e}(k)\right)^{2}\right]=E\left[\left(S(k)-\sum_{i=1}^{N} a_{i} S(k-i)\right)^{2}\right]E[d2]=E[(S(k)−Se(k))2]=E⎣⎡(S(k)−i=1∑NaiS(k−i))2⎦⎤
为了满足最佳预测需求,令:
∂E[d2]∂ai=0i=1,2,…,N\frac{\partial E\left[d^{2}\right]}{\partial a_{i}}=0 \quad i=1,2, \ldots, N∂ai∂E[d2]=0i=1,2,…,N
有:
E[2(S(k)−∑m=1NamS(k−m))S(k−i)]=E[2(S(k)S(k−i)−∑m=1NamS(k−m)S(k−i))]=0E\left[2\left(S(k)-\sum_{m=1}^{N}a_{m} S(k-m)\right)S\left(k-i\right)\right]=E\left[2\left(S(k)S\left(k-i\right)-\sum_{m=1}^{N}a_{m} S(k-m)S\left(k-i\right)\right)\right]=0E[2(S(k)−m=1∑NamS(k−m))S(k−i)]=E[2(S(k)S(k−i)−m=1∑NamS(k−m)S(k−i))]=0
那么可以得到:
E[S(k)S(k−i)]=E[(∑m=1NamS(k−m))S(k−i)]=∑m=1NE[S(k−m)S(k−i))]E\left[S(k\right)S\left(k-i)\right]=E\left[\left(\sum_{m=1}^{N}a_{m} S(k-m)\right)S\left(k-i\right)\right]=\sum_{m=1}^{N}E\left[S(k-m)S(k-i))\right]E[S(k)S(k−i)]=E[(m=1∑NamS(k−m))S(k−i)]=m=1∑NE[S(k−m)S(k−i))]
利用自相关函数的定义R(i)=E[S(k)S(k−i)],i=0,1,2,…,N−1\boldsymbol{R}(\boldsymbol{i})=\boldsymbol{E}[\boldsymbol{S}(\boldsymbol{k}) \boldsymbol{S}(\boldsymbol{k}-\boldsymbol{i})],i=0,1,2, \ldots, N-1R(i)=E[S(k)S(k−i)],i=0,1,2,…,N−1,可以将上式展开为:
R(1)=a1R(0)+a2R(1)+⋯+aNR(N−1)R(1) = a_1R(0)+a_2R(1)+\cdots+a_NR(N-1)R(1)=a1R(0)+a2R(1)+⋯+aNR(N−1)
R(2)=a1R(1)+a2R(0)+⋯+aNR(N−2)R(2) = a_1R(1)+a_2R(0)+\cdots+a_NR(N-2)R(2)=a1R(1)+a2R(0)+⋯+aNR(N−2)
⋮\vdots⋮
R(N)=a1R(N−1)+a2R(N−2)+⋯+aNR(0)R(N) = a_1R(N-1)+a_2R(N-2)+\cdots+a_NR(0)R(N)=a1R(N−1)+a2R(N−2)+⋯+aNR(0)
写成矩阵形式即为:
[R(1)R(2)⋮R(N)]=[R(0)R(1)⋯R(N−1)R(1)R(0)⋯R(N−2)⋮⋮⋮R(N−1)R(N−2)…R(0)][a1a2⋮aN]\left[\begin{array}{l}R(1) \\ R(2) \\ \vdots \\ R(N)\end{array}\right]=\left[\begin{array}{llll}R(0) & R(1) & \cdots & R(N-1) \\ R(1) & R(0) & \cdots & R(N-2) \\ \vdots & \vdots & & \vdots\\ R(N-1) &R(N-2) & \dots & R(0)\end{array}\right]\left[\begin{array}{l}a_{1} \\ a_{2} \\ \vdots \\ a_{N}\end{array}\right]⎣⎢⎢⎢⎡R(1)R(2)⋮R(N)⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡R(0)R(1)⋮R(N−1)R(1)R(0)⋮R(N−2)⋯⋯…R(N−1)R(N−2)⋮R(0)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡a1a2⋮aN⎦⎥⎥⎥⎤
最小二乘法
假设需要描述一个解不存在的巨型方程组Ax=bA\boldsymbol{x}=\boldsymbol{b}Ax=b(比如线性回归问题),通常做法是寻找一个x\boldsymbol{x}x,使得AxA\boldsymbol{x}Ax尽量接近b\boldsymbol{b}b。这里通常使用距离来描述近似,即找出使得∥b−Ax∥\|\mathbf{b}-A \mathbf{x}\|∥b−Ax∥尽量小的x\boldsymbol{x}x。
定义
If AAA is m×nm \times nm×n and b\mathbf{b}b is in Rm\mathbb{R}^{m}Rm, a least-squares solution of Ax=bA \mathbf{x}=\mathbf{b}Ax=b is an x^\hat{\mathbf{x}}x^ in Rn\mathbb{R}^{n}Rn such that
∥b−Ax^∥≤∥b−Ax∥\|\mathbf{b}-A \hat{\mathbf{x}}\| \leq\|\mathbf{b}-A \mathbf{x}\|∥b−Ax^∥≤∥b−Ax∥
for all x\mathbf{x}x in Rn\mathbb{R}^{n}Rn
定义损失函数L(x)=∑i=1m∥Aix−bi∥2L(\boldsymbol{x})=\sum^m_{i=1}\|\boldsymbol{A}_i\boldsymbol{x}-b_i\|^2L(x)=∑i=1m∥Aix−bi∥2,其中Ai\boldsymbol{A}_iAi是A中的第i行。
可以对L(x)L(\boldsymbol{x})L(x)进行化简:
L(x)=(xTAT−bT)(Ax−b)L(\boldsymbol{x})=(\boldsymbol{x}^TA^T-\boldsymbol{b}^T)(A\boldsymbol{x}-\boldsymbol{b})L(x)=(xTAT−bT)(Ax−b)
展开可得
L(x)=(Ax)TAx−2(Ax)Tb+bTbL(\boldsymbol{x})=(A\boldsymbol{x})^TA\boldsymbol{x}-2(A\boldsymbol{x})^T\boldsymbol{b}+\boldsymbol{b}^T\boldsymbol{b}L(x)=(Ax)TAx−2(Ax)Tb+bTb
那么现在的任务就是找到x\boldsymbol{x}x满足x=arg(min(L(x)))\boldsymbol{x}=arg(min(L(\boldsymbol{x})))x=arg(min(L(x)))
令∂L(x)x=2ATAx−2ATb=0\frac{\partial L(\boldsymbol{x})}{\boldsymbol{x}}=2A^TA\boldsymbol{x}-2A^T\boldsymbol{b}=0x∂L(x)=2ATAx−2ATb=0
即ATAx=ATbA^TA\boldsymbol{x}=A^T\boldsymbol{b}ATAx=ATb
当ATAA^TAATA可逆的时候,可以解得
x=(ATA)−1ATb\boldsymbol{x}=(A^TA)^{-1}A^T\boldsymbol{b}x=(ATA)−1ATb
计算时间复杂度为O(n2m)O(n^2m)O(n2m).
当矩阵具有某些特殊结构的时候,可以使用算法快速求解最小二乘问题。
有时样本数目不够多或者样本的维度过大,那么就有可能造成过拟合。这时候可以采用正则化的方法,在损失函数中增加一些多余的项,如:
L(x)=(xTAT−bT)(Ax−b)+ρxTxL(\boldsymbol{x})=(\boldsymbol{x}^TA^T-\boldsymbol{b}^T)(A\boldsymbol{x}-\boldsymbol{b})+\rho \boldsymbol{x}^T\boldsymbol{x}L(x)=(xTAT−bT)(Ax−b)+ρxTx
算法
梯度下降
使用负梯度作为搜算个方向。即令Δx=−∇f(x)\Delta{x}=-\nabla f(x)Δx=−∇f(x) 。
步骤
给定 初始点x∈domfx\in \boldsymbol{dom} fx∈domf
重复进行
- Δx:=−∇f(x)\Delta{x}:=-\nabla f(x)Δx:=−∇f(x)
- 检验是否满足停止准则,如果满足则停止。不满足则进行后续步骤。
- 直线搜索。通过精确或回溯直线搜索方法确定步长t。
- 修改。x:=x+tΔxx:=x+t\Delta xx:=x+tΔx
停止准则通常取为∥∇f(x)∥≤η\|\nabla f(x)\|\le \eta∥∇f(x)∥≤η。
梯度下降法考虑的是局部性质。对于许多问题,下降速度非常反满。当函数的等值曲线接近一个圆(球)时,最速下降法较快;当其为一个椭球时,最开始几步下降较快,后来就出现锯齿现象,下降缓慢。
牛顿法
牛顿法的思想是利用f(x)f(x)f(x)的泰勒级数前面几项来寻找方程f(x)=0f(x)=0f(x)=0的根。
Newton步径
对于x∈domfx\in \boldsymbol{dom} fx∈domf,称向量Δxnt=−∇2f(x)−1∇f(x)\Delta x_{\mathrm{nt}}=-\nabla^{2} f(x)^{-1} \nabla f(x)Δxnt=−∇2f(x)−1∇f(x)为f在x处的Newton步径。除非∇f(x)=0\nabla f(x)=0∇f(x)=0,否则都会有:
∇f(x)TΔxnt=−∇f(x)T∇2f(x)−1∇f(x)<0\nabla f(x)^{T} \Delta x_{\mathrm{nt}}=-\nabla f(x)^{T} \nabla^{2} f(x)^{-1} \nabla f(x)<0∇f(x)TΔxnt=−∇f(x)T∇2f(x)−1∇f(x)<0
所以Newton步径是下降方向,除非x为最有点。
函数f在x处的二阶泰勒展开为f^\hat{f}f^为:
f^(x+v)=f(x)+∇f(x)Tv+12vT∇2f(x)v\widehat{f}(x+v)=f(x)+\nabla f(x)^{T} v+\frac{1}{2} v^{T} \nabla^{2} f(x) vf(x+v)=f(x)+∇f(x)Tv+21vT∇2f(x)v
这是v的二次凸函数,在v=Δxntv=\Delta x_{nt}v=Δxnt处达到最小值。因此x加上Newton步径能够极小化f在x处的二阶近似。
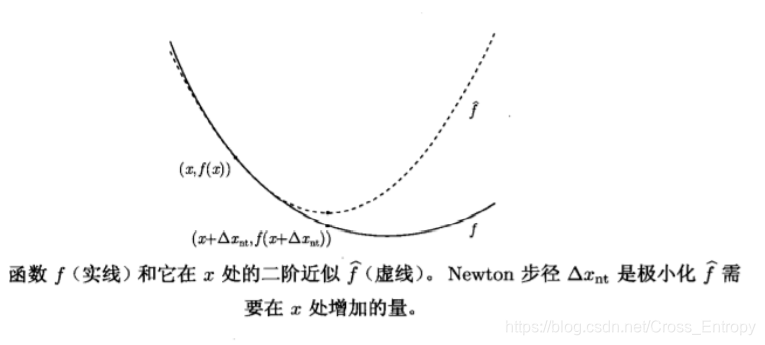
Newton减量
将
λ(x)=(∇f(x)T∇2f(x)−1∇f(x))1/2\lambda(x)=\left(\nabla f(x)^{T} \nabla^{2} f(x)^{-1} \nabla f(x)\right)^{1 / 2}λ(x)=(∇f(x)T∇2f(x)−1∇f(x))1/2
称为x处的Newton减量。
Newton减量也可以表示为λ(x)=(ΔxntT∇2f(x)Δxnt)1/2\lambda(x)=\left(\Delta x_{\mathrm{nt}}^{T} \nabla^{2} f(x) \Delta x_{\mathrm{nt}}\right)^{1 / 2}λ(x)=(ΔxntT∇2f(x)Δxnt)1/2。在回溯直线搜索中可以呗解释为f在x处沿Newton步径方向的方向导数,即:
−λ(x)2=∇f(x)TΔxnt=ddtf(x+Δxntt)∣t=0-\lambda(x)^{2}=\nabla f(x)^{T} \Delta x_{\mathrm{nt}}=\left.\frac{d}{d t} f\left(x+\Delta x_{\mathrm{nt}} t\right)\right|_{t=0}−λ(x)2=∇f(x)TΔxnt=dtdf(x+Δxntt)∣∣∣∣t=0
Newton减量也是仿射不变的。
算法步骤
给定 初始点x∈domfx \in \boldsymbol{dom} fx∈domf,误差阈值ϵ>0\epsilon>0ϵ>0
重复进行
-
计算Newton步径和Newton减量.
Δxnt:=−∇2f(x)−1∇f(x);λ2:=∇f(x)T∇2f(x)−1∇f(x)\Delta x_{\mathrm{nt}}:=-\nabla^{2} f(x)^{-1} \nabla f(x) ; \quad \lambda^{2}:=\nabla f(x)^{T} \nabla^{2} f(x)^{-1} \nabla f(x)Δxnt:=−∇2f(x)−1∇f(x);λ2:=∇f(x)T∇2f(x)−1∇f(x)
-
停止准则:如果λ2/2⩽ϵ\lambda^{2} / 2 \leqslant \epsilonλ2/2⩽ϵ,退出.
-
直线搜素:通过回溯直线确定搜索步长t.
-
改进:x:=x+tΔxntx:=x+t\Delta x_{nt}x:=x+tΔxnt
高斯牛顿法
高斯牛顿法适用于非线性最小二乘问题,并且只能处理二次函数.
对于非线性最小二乘问题x=argminx12∥f(x)∥2x=\arg \min _{x} \frac{1}{2}\|f(x)\|^{2}x=argminx21∥f(x)∥2
高斯牛顿法的思想是把f(x)f(x)f(x)泰勒展开,取一阶近似项.
f(x+Δx)=f(x)+f′(x)Δx=f(x)+J(x)Δxf(x+\Delta x)=f(x)+f^{\prime}(x) \Delta x=f(x)+J(x) \Delta xf(x+Δx)=f(x)+f′(x)Δx=f(x)+J(x)Δx
对上式求导,并令其为0.
有J(x)TJ(x)Δx=−J(x)Tf(x)J(x)^{T} J(x) \Delta x=-J(x)^{T} f(x)J(x)TJ(x)Δx=−J(x)Tf(x)
其中J(x)=[∂f∂x1∂f∂x2]J(x)=\left[\begin{array}{c}\frac{\partial f}{\partial x_{1}} \\ \frac{\partial f}{\partial x_{2}}\end{array}\right]J(x)=[∂x1∂f∂x2∂f].
令H=JTJ,B=−JTfH=J^{T} J, \quad B=-J^{T} fH=JTJ,B=−JTf,则上式可化为HΔx=BH\Delta x = BHΔx=B,从而可以得到调整量Δx\Delta xΔx.这就要求H可逆。
步骤
给定 初始点x∈domfx \in \boldsymbol{dom} fx∈domf
重复进行
- 计算J,H,BJ,H,BJ,H,B,从而得到Δx\Delta xΔx
- 如果满足停止准则则退出
- 改进:x:=x+tΔxntx:=x+t\Delta x_{nt}x:=x+tΔxnt

















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









