




文章目录
JPEG原理分析及JPEG解码器的调试
原理分析
JPEG编解码流程图
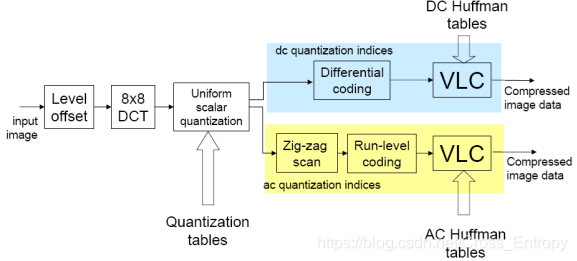
- 将传入的图像进行零电平偏置,其实就是将所有像素的数值减去128,将其范围从[0,255]变成[-128,127]。
- 进行8×8的DCT变换,实现能量集中和去相关,便于去除图像的空间冗余度。
- 使用量化表进行量化。利用根据人眼视觉特性设计的量化的量化矩阵进行量化,低频细量化,高频粗量化,进而减少视觉冗余。
- 最后对量化后的直流系数进行差分和VLC编码;对交流系数进行zig-zag扫描和游程编码最后再进行VLC编码。从而减少数据冗余。
DC系数编码
由于直流系数 F(0,0)反映了该子图像中包含的直流成分,通常较大,又由于两个相邻的子图像的直流系数通常具有较大的相关性,所以对 DC 系数采用差值脉冲编码(DPCM),即对本像素块直流系数与前一像素块直流系数的差值进行无损编码。
AC系数编码
首先,进行游程编码(RLC),并在最后加上块结束码(EOB);然后,系数序列分组,将非零系数和它前面的相邻的全部零系数分在一组内;每组用两个符号表示[(Run,Size),(Amplitude)]
其中Amplitude表示非零系数的幅度值;Run:表示零的游程即零的个数;Size:
表示非零系数的幅度值的编码位数;
JPEG文件格式
Segment组织形式
JPEG 在文件中以 Segment 的形式组织,它具有以下特点:
- 均以 0xFF 开始,后跟 1 byte 的 Marker 和 2 byte 的 Segment length(该长度包含Length本身所占用的 2 byte,指的是length及其后的数据长度)
- 采用 Motorola 序(相对于 Intel 序),即保存时高位在前,低位在后;
- Data 部分中,0xFF 后若为 0x00,则跳过此字节不予处理;
JPEG 的 Segment Marker
non-hierarchical Huffman coding
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| S O F 0 SOF_0 SOF0 | 0xFFC0 | Baseline DCT |
| S O F 1 SOF_1 SOF1 | 0xFFC1 | Extended sequential DCT |
| S O F 2 SOF_2 SOF2 | 0xFFC2 | Progressive DCT |
| S O F 3 SOF_3 SOF3 | 0xFFC3 | Spatial (sequential) lossless |
hierarchical Huffman coding
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| S O F 5 SOF_5 SOF5 | 0xFFC5 | Differential sequential DCT |
| S O F 6 SOF_6 SOF6 | 0xFFC6 | Differential progressive DCT |
| S O F 7 SOF_7 SOF7 | 0xFFC7 | Differential spatial lossless |
non-hierarchical arithmetic coding
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| JPG | 0xFFC8 | Reserved for JPEG extensions |
| S O F 9 SOF_9 SOF9 | 0xFFC9 | Extended sequential DCT |
| S O F 10 SOF_{10} SOF10 | 0xFFCA | Progressive DCT |
| S O F 11 SOF_{11} SOF11 | 0xFFCB | Spatial (sequential) Lossless |
hierarchical arithmetic coding
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| S O F 1 3 SOF_13 SOF13 | 0xFFCD | Differential sequential DCT |
| S O F 1 4 SOF_14 SOF14 | 0xFFCE | Differential progressive DCT |
| S O F 15 SOF_{15} SOF15 | 0xFFCF | Differential progressive DCT |
Huffman table specification
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| DHT | 0xFFC4 | Define Huffman table(s) |
arithmetic coding conditioning specification
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| DAC | 0xFFCC | Define arithmetic conditioning table |
Restart interval termination
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| RSTm | 0xFFD0~0xFFD7 | Restart with modulo 8 counter m |
Other marker
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| SOI | 0xFFD8 | Start of image |
| EOI | 0xFFD9 | End of image |
| SOS | 0xFFDA | Start of scan |
| DQT | 0xFFDB | Define quantization table(s) |
| DNL | 0xFFDC | Define number of lines |
| DRI | 0xFFDD | Define restart interval |
| DHP | 0xFFDE | Define hierarchical progression |
| EXP | 0xFFDF | Expand reference image(s) |
| A P P n APP_n APPn | 0xFFE0~0xFFEF | Reserved for application use |
| J P G n JPG_n JPGn | 0xFFF0~0xFFFD | Reserved for JPEG extension |
| COM | 0xFFFE | Comment |
Reserved markers
| Symbol | Code Assignment(0xFF+Marker) | Description |
|---|---|---|
| TEM | 0xFF01 | For temporary use in arithmetic coding |
| RES | 0xFF02~0xFFBF | Reserved |
Segment详细信息
SOI & EOI
| 标志 | 字节数 | 含义 |
|---|---|---|
| SOI | 2字节 | Start of Image,图像开始 |
| EOI | 2字节 | End of Image,图像结束 |
APP0
共有9个字段
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 1-9共9个字段的总长度 |
| 标识符 | 5字节 | 固定值0x4A46494600,即字符串“JFIF0” |
| 版本号 | 2字节 | 一般是0x0102,表示JFIF的版本号1.2 |
| X和Y的密度单位 | 1字节 | 只有三个值可选 0:无单位;1:点数/英寸;2:点数/厘米 |
| X方向像素密度 | 2字节 | X方向像素密度 |
| Y方向像素密度 | 2字节 | Y方向像素密度 |
| 缩略图水平像素数目 | 1字节 | 缩略图水平像素数 |
| 缩略图垂直像素数目 | 1字节 | 缩略图垂直像素数 |
| 缩略图RGB位图 | 长度可能是3的倍数 | 缩略图RGB位图数据 |
DQT
即定义量化表。
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 所有字段的总长度 |
| 量化表×n | 数据长度-2字节 | 详细内容见下表 |
量化表中字段的含义:
| 字段 | 字节数 | 含义 |
|---|---|---|
| 量化精度及量化表ID | 1字节 | 高四位精度,0表示8位,1表示16位 低四位为量化表ID,取值范围为0-3 |
| 表项 | (64×(精度+1))字节 | 表格的具体内容 |
本标记段中,量化表可以重复出现,表示有多个量化表,但最多只能出现4次。
SOF0
即帧图像开始 。
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 所有字段的总长度 |
| 精度 | 1字节 | 每个数据样本的位数 通常是8位,一般软件都不支持 12位和16位 |
| 图像高度 | 2字节 | 图像高度(单位:像素) |
| 图像宽度 | 2字节 | 图像宽度(单位:像素) |
| 颜色分量数 | 1字节 | 只有3个数值可选 1:灰度图; 3:YCrCb或YIQ; 4:CMYK 而JFIF中使用YCrCb,故这里颜色分量数恒为3 |
| 颜色分量信息 | 颜色分量数×3字节 (通常为9字节) |
颜色分量ID 1字节 水平/垂直采样因子 1字节 高四位为水平采样因子,低四位为垂直采样因子 量化表 1字节 当前分量所使用量化表的ID |
DHT
即定义哈夫曼表。
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 所有字段的总长度 |
| Huffman表×n | 数据长度-2字节 | 详细内容见下表 |
Huffman表中的内容:
| 字段 | 字节数 | 含义 |
|---|---|---|
| 表ID和表类型 | 1字节 | 高四位表示类型,0表示直流,1表示交流 低四位为Huffman表ID,DC表和AC表分开编码 |
| 不同位数的码字数量 | 16字节 | 不同位数码字的数量 |
| 编码内容 | 16个不同位数的码字数量之和(字节) | 编码的具体内容 |
Huffman表可以重复出现,但最多4次。对于Huffman表的存储方式在下面会有介绍。
SOS
即扫描开始。
| 字段 | 字节数 | 含义 |
|---|---|---|
| 数据长度 | 2字节 | 所有字段的总长度 |
| 颜色分量数 | 1字节 | 应该和SOF中的相应字段值相同 1:灰度图是;3: YCrCb或YIQ;4:CMYK |
| 颜色分量信息 | 2字节 | 其中包括 颜色分量ID 1字节 直流/交流系数表号 1字节 高四位:直流分量使用的哈夫曼树编号;低四位交流分量使用的哈夫曼树编号。 |
| 压缩图像数据 | 2字节 | 谱选择开始 1字节 固定值0x00 谱选择结束 1字节 固定值0x3F 谱选择 1字节 在基本JPEG中总为00 |
Huffman表存储方式说明
在标记段DHT内,包含了一个或者多个的哈夫曼表。对于单一个哈夫曼表,应该包括了三部分
- 哈夫曼表ID和表类型
- 这个字节的值为一般只有四个0x00、0x01、0x10、0x11。
- 0x00表示DC直流0号表
- 0x01表示DC直流1号表
- 0x10表示AC交流0号表
- 0x11表示AC交流1号表
- 这个字节的值为一般只有四个0x00、0x01、0x10、0x11。
- 不同位数的码字数量
- 编码内容
- 第一字段:JPEG文件的哈夫曼编码最长只有16位。所以这个字段的16个字节分别表示1-16位的编码码字在哈夫曼树中的个数。
- 第二字段:这个字段记录了哈夫曼树中各个叶子结点的权。所以,上一字段(不同位数的码字数量)的16个数值之和就应该是本字段的长度,也就是哈夫曼树中叶子结点个数。
举个例子:FF C4 00 3E 00 00 03 01 01 01 01 01 01 01 00 00 00 00 00 00 04 05 06 03 02 01 00 09 07 08
其中
- 红色部分表示哈夫曼表的ID和表的类型,本例中0x00表示此部分数据描述的是DC交流0号表。
- 蓝色部分表示为不同码长的码字的数量。本例中,即码长为1的码字有0个,码长为2的码字有3个,码长为3的码字有1个,以此类推。
- 绿色部分的字节数等于蓝色部分的数值相加。此处为10字节。表示每个叶子节点从小到大(所谓从小到大实际上是指的码长和出现顺序)排序后,对应的权值(权值对直流和交流系数的含义不同)。
建立huffman树/表
Huffman码表的建立方式比较简单,
具体方法为:
- 第一个码字必定为0
- 如果第一个码字位数为1,则码字为0;
- 如果第一个码字位数为2,则码字为00;
- 以此类推
- 从第二个码字开始
- 如果它和它前面的码字位数相同,则当前码字为它前面的码字加1;
- 如果它的位数比它前面的码字位数大,则当前码字是前面的码字加1后再在后边添若干个0,直至满足位数长度为止。
按照上述方法,可以根据上一个例子建立一个霍夫曼码表:
| 序号 | 码长 | 码字 | 权值 |
|---|---|---|---|
| 1 | 2 | 00 | 4 |
| 2 | 2 | 01 | 5 |
| 3 | 2 | 10 | 6 |
| 4 | 3 | 110 | 3 |
| 5 | 4 | 1110 | 2 |
| 6 | 5 | 11110 | 1 |
| 7 | 6 | 111110 | 0 |
| 8 | 7 | 1111110 | 9 |
| 9 | 8 | 11111110 | 7 |
| 10 | 9 | 111111110 | 8 |
代码解析
具体实现为:
/*
* Takes two array of bits, and build the huffman table for size, and code
* 使用两个关于bits的数组构建出来huffmantable
* lookup will return the symbol if the code is less or equal than HUFFMAN_HASH_NBITS.
* lookup表会返回编码后的码字,如果编码长度小于等于HUFFMAN_HASH_NBITS
* code_size will be used to known how many bits this symbol is encoded.
* 编码大小会被用来表示这个符号的长度为多少bit
* slowtable will be used when the first lookup didn't give the result.
* 当上述查找表无法使用给出答案的时候,使用slowtable
*/
static void build_huffman_table(const unsigned char* bits, const unsigned char* vals, struct huffman_table* table)
{
//bits为每个长度出现的频次,vals是权值,table是要构建的霍夫曼表
unsigned int i, j, code, code_size, val, nbits;
unsigned char huffsize[HUFFMAN_BITS_SIZE + 1], * hz;
unsigned int huffcode[HUFFMAN_BITS_SIZE + 1], * hc;
int next_free_entry;
/*
* Build a temp array
* huffsize[X] => numbers of bits to write vals[X]
* huffsize[x]表示用多少bit去表示vals[X]
* bits数组表示该huffman编码长度的出现的次数
* 下列代码将所有子节点初始化
*/
hz = huffsize;
for (i = 1; i <= 16; i++)
{
for (j = 1; j <= bits[i]; j++)
*hz++ = i;
}
*hz = 0;
//初始化lookup表,全部赋值为最大值。初始化slowtable全为0
memset(table->lookup, 0xff, sizeof(table->lookup));
for (i = 0; i < (16 - HUFFMAN_HASH_NBITS); i++)
table->slowtable[i][0] = 0;
/* Build a temp array
* huffcode[X] => code used to write vals[X]
* huffcode[X] 表示用来表示vals[X]的编码
*/
code = 0;
hc = huffcode;
hz = huffsize;
nbits = *hz;
while (*hz)
{
//当长度没有变化的时候下一个编码为上一个+1
while (*hz == nbits)
{
*hc++ = code++;
hz++;
}
//当长度发生变换的时候则是+1补零
code <<= 1;
nbits++;
}
/*
* Build the lookup table, and the slowtable if needed.
* 建立慢速查找表,如果有需要
*/
next_free_entry = -1;
//如果 huffsize[i]不为0,则执行循环
for (i = 0; huffsize[i]; i++)
{
//获取值,编码,和码长
val = vals[i];
code = huffcode[i];
code_size = huffsize[i];
//建立权值和码长的关系
table->code_size[val] = code_size;
if (code_size <= HUFFMAN_HASH_NBITS)
{
/*
* Good: val can be put in the lookup table, so fill all value of this
* column with value val
* 如果code_size小于HUFFMAN_HASH_NBITS,即查找表的固定长度
* 就重复 1UL << (HUFFMAN_HASH_NBITS - code_size) 次
* 就相当于把表格中码字后边的所有位数补全,并把它的值全赋值成val
*/
int repeat = 1UL << (HUFFMAN_HASH_NBITS - code_size);
code <<= HUFFMAN_HASH_NBITS - code_size;
while (repeat--)
table->lookup[code++] = val;
}
else
{
uint16_t* slowtable = table->slowtable[code_size - HUFFMAN_HASH_NBITS - 1];
//如果当前查找表已经有值了,那就存储到下一个位置
while (slowtable[0])
slowtable += 2;
slowtable[0] = code;
slowtable[1] = val;
slowtable[2] = 0;
/* TODO: NEED TO CHECK FOR AN OVERFLOW OF THE TABLE */
}
}
}
JPEG中Huffman解码过程
代码解析
直接用代码进行说明吧:
static int get_next_huffman_code(struct jdec_private* priv, struct huffman_table* huffman_table)
{
int value, hcode;
unsigned int extra_nbits, nbits;
uint16_t* slowtable;
//读取HUFFMAN_HASH_NBITS比特,并赋值给hcode
look_nbits(priv->reservoir, priv->nbits_in_reservoir, priv->stream, HUFFMAN_HASH_NBITS, hcode);
//在霍夫曼码表中找到对应的权值
value = huffman_table->lookup[hcode];
if (__likely(value >= 0))
{
unsigned int code_size = huffman_table->code_size[value];
//跳过code_size比特
skip_nbits(priv->reservoir, priv->nbits_in_reservoir, priv->stream, code_size) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









