




具身人工智能正在成为AI领域的热门方向,而导航能力是智能体在物理环境中生存和完成任务的基础。想象一个智能体既能在室内为你端茶送水,又能在户外巡逻监控,甚至驾驶汽车穿越繁忙的街道——这正是研究者们长期追求的通用导航能力。
近日,北京大学团队联合GalBot、中国科学技术大学、北京智源人工智能研究院等多个机构,推出了NavFoM(导航基础模型),首次实现了跨不同机器人形态和任务类型的通用导航能力,无需针对特定任务进行微调,在多个基准测试中取得了最先进或极具竞争力的性能。

论文链接:
https://arxiv.org/pdf/2509.12129
项目主页:
https://pku-epic.github.io/NavFoM-Web/
通用导航的挑战与现有方法的局限
现有的导航方法大多局限于狭窄的任务领域和特定的机器人形态。例如,一个在室内导航表现优异的模型,可能无法直接应用于无人机或自动驾驶场景。这种局限性源于:
-
不同机器人的运动机制差异巨大(四足、轮式、飞行等)
-
不同任务的空间尺度迥异(室内几米vs.道路上百米)
-
视觉观察的视角和时间信息难以统一处理
尽管视觉语言模型在开放世界任务中展现出强大的零样本泛化能力,但这些能力尚未在具身导航领域得到充分探索。
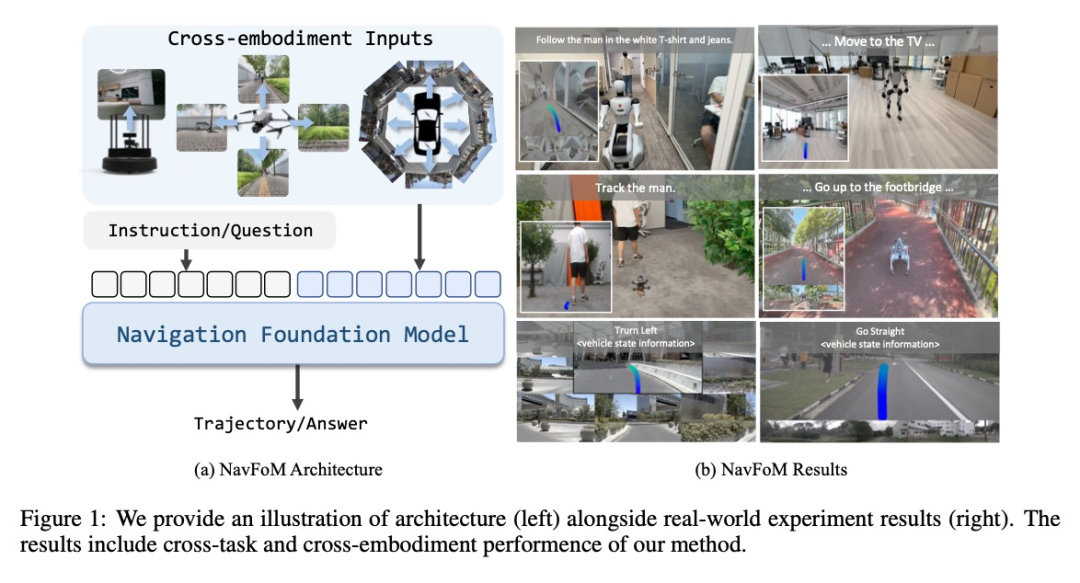
NavFoM模型的核心创新
-
统一的导航任务定义
NavFoM采用统一的框架处理多样化导航任务:移动机器人根据文本指令和从多个相机捕获的图像序列,预测导航轨迹。无论是轮式机器人的2D轨迹还是无人机的3D轨迹,都可在同一框架下处理。
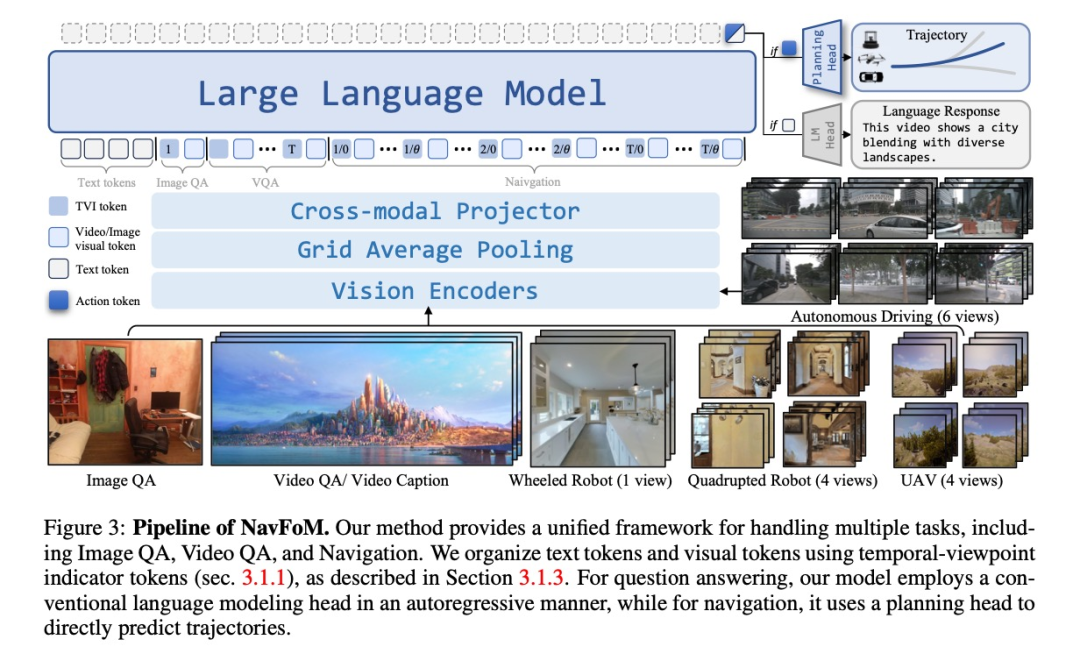
-
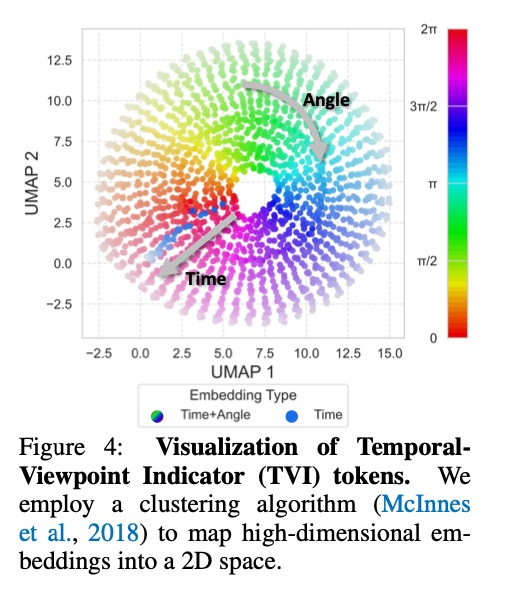
时间-视角指示器(TVI)token
为解决视觉token缺乏视角和时间信息的问题,研究团队创新性地提出了TVI token,它包含:
-
角度嵌入:使用正弦余弦值表示方位角,确保循环连续性
-
时间嵌入:使用时间步的正弦位置编码
-
基础嵌入:可学习的嵌入,表示视觉token起始点
这种设计使模型能够灵活处理图像问答、视频问答和导航等不同类型的任务。
-
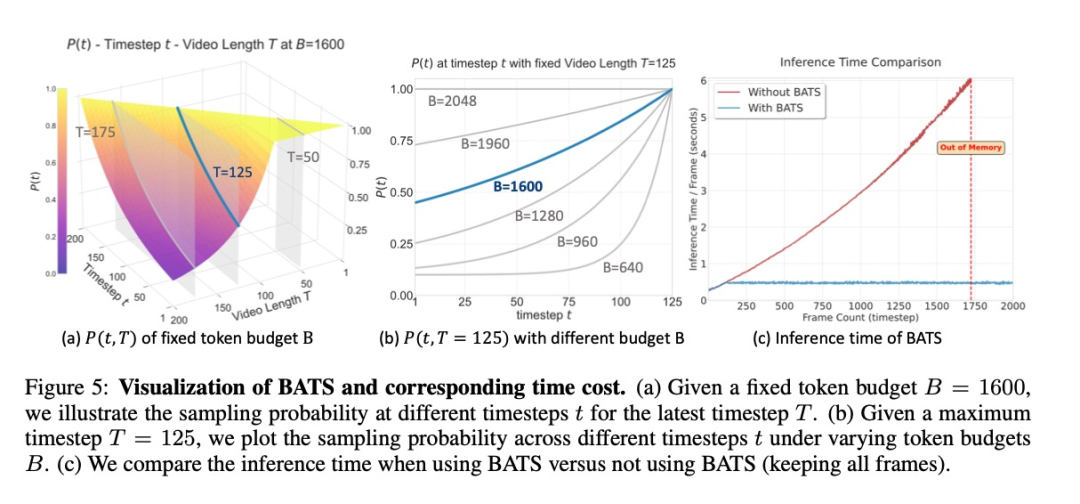
基于预算的动态调整采样策略(BATS)
在实际部署中,实时视频会产生大量视觉token,增加计算负担。BATS策略受「遗忘曲线」启发,使用基于指数增长的采样概率动态选择关键帧,在有限的token预算下保持稳定的推理速度。
-
大规模训练数据与高效训练
为训练NavFoM,团队收集了1270万训练样本,包括:
-
802万导航样本:涵盖视觉语言导航、目标搜索、目标跟踪和自动驾驶
-
476万开放世界问答样本:提供丰富的环境理解知识
-
覆盖多种机器人类型(四足、无人机、轮式和车辆)和任务场景
训练效率方面,团队采用视觉特征缓存机制,将训练时间减少2.9倍,同时显著降低GPU内存使用。
在Coovally 模型训练平台集成 1000+主流模型,为用户提供从训练到部署的一站式解决方案,大幅降低算法选型和工程实现的复杂度。

!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
在实际使用中,开发者还可以借助 Coovally 平台,通过 SSH 协议使用熟悉的工具(如 VS Code、Cursor、WindTerm 等)远程连接 Coovally 云端算力资源,进行实时代码开发与调试,享受本地级操作体验的同时,充分利用平台提供的高性能 GPU 加速训练过程。

卓越的性能表现
-
基准测试结果
NavFoM在多个权威基准测试中表现出色:
-
视觉语言导航:在VLN-CE R2R和RxR基准上取得SOTA性能,多视图设置下成功率从56.3%提升至64.4%
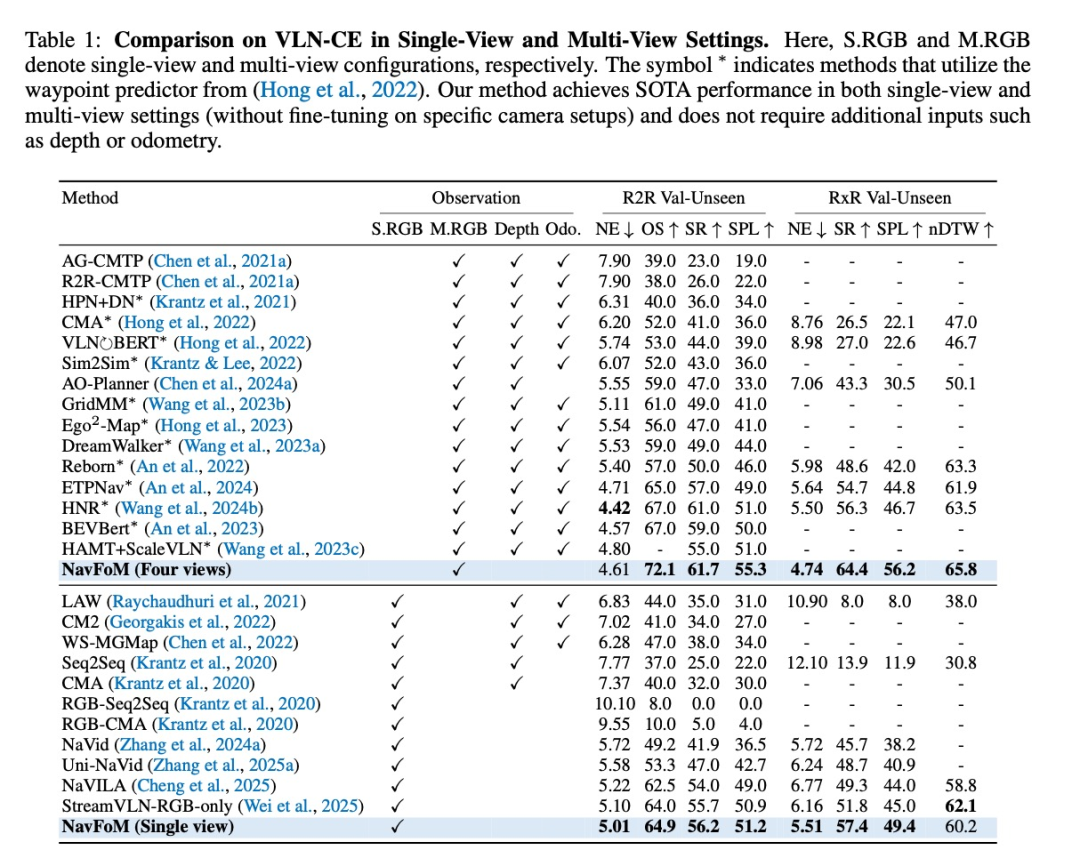
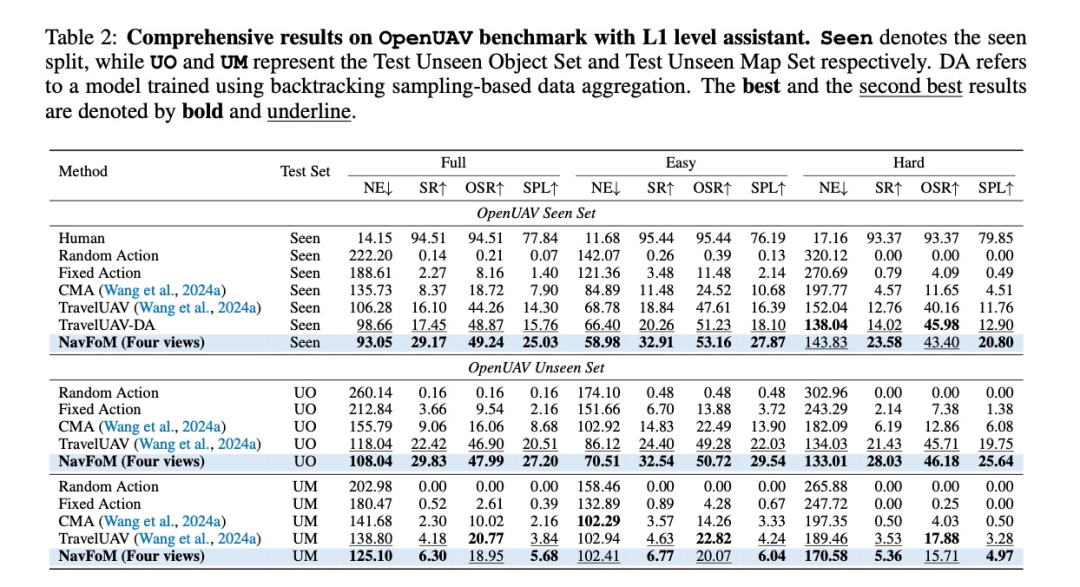
-
目标搜索:在HM3D-OVON零样本基准上,成功率从40.8%提升至45.2%
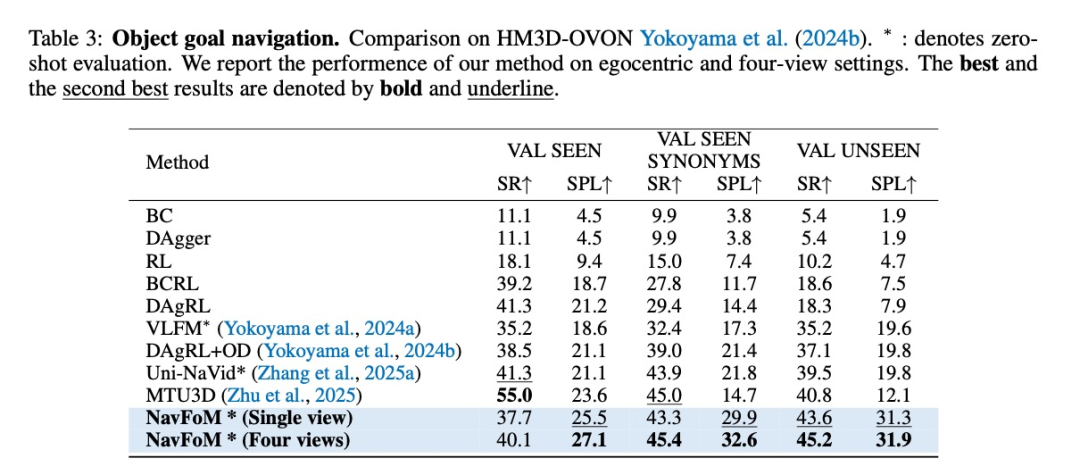
-
主动目标跟踪:在EVT-Bench上达到88.4%的成功率
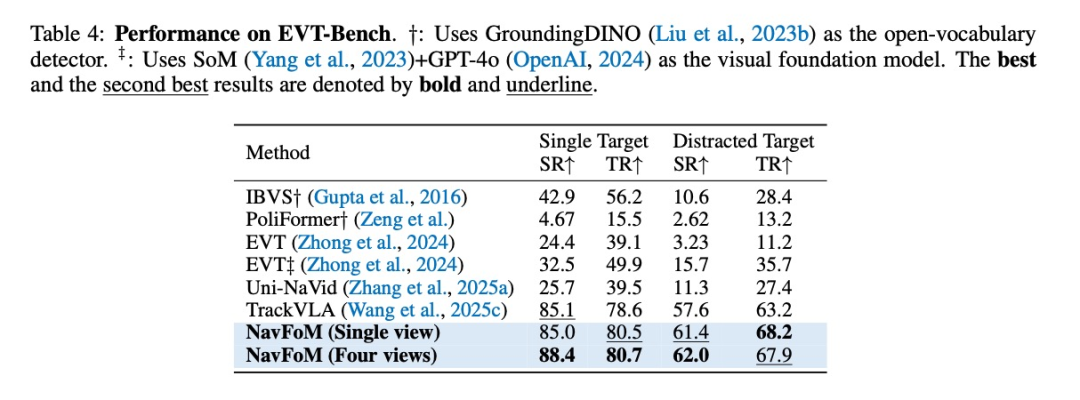
-
自动驾驶:在nuScenes和NAVSIM基准上与专业方法性能相当
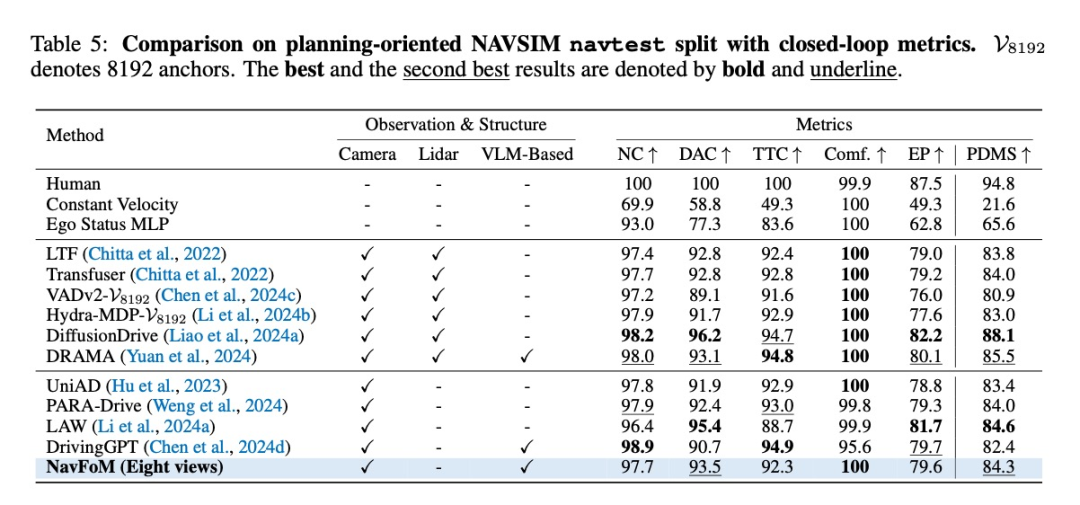
-
真实世界验证
团队在110个可复现测试案例中验证了NavFoM的实用性,包括复杂室内外环境。此外,在四足机器人、人形机器人、无人机和轮式机器人等多种平台上的实验表明,模型能够处理现实世界的复杂场景并完成长距离指令。
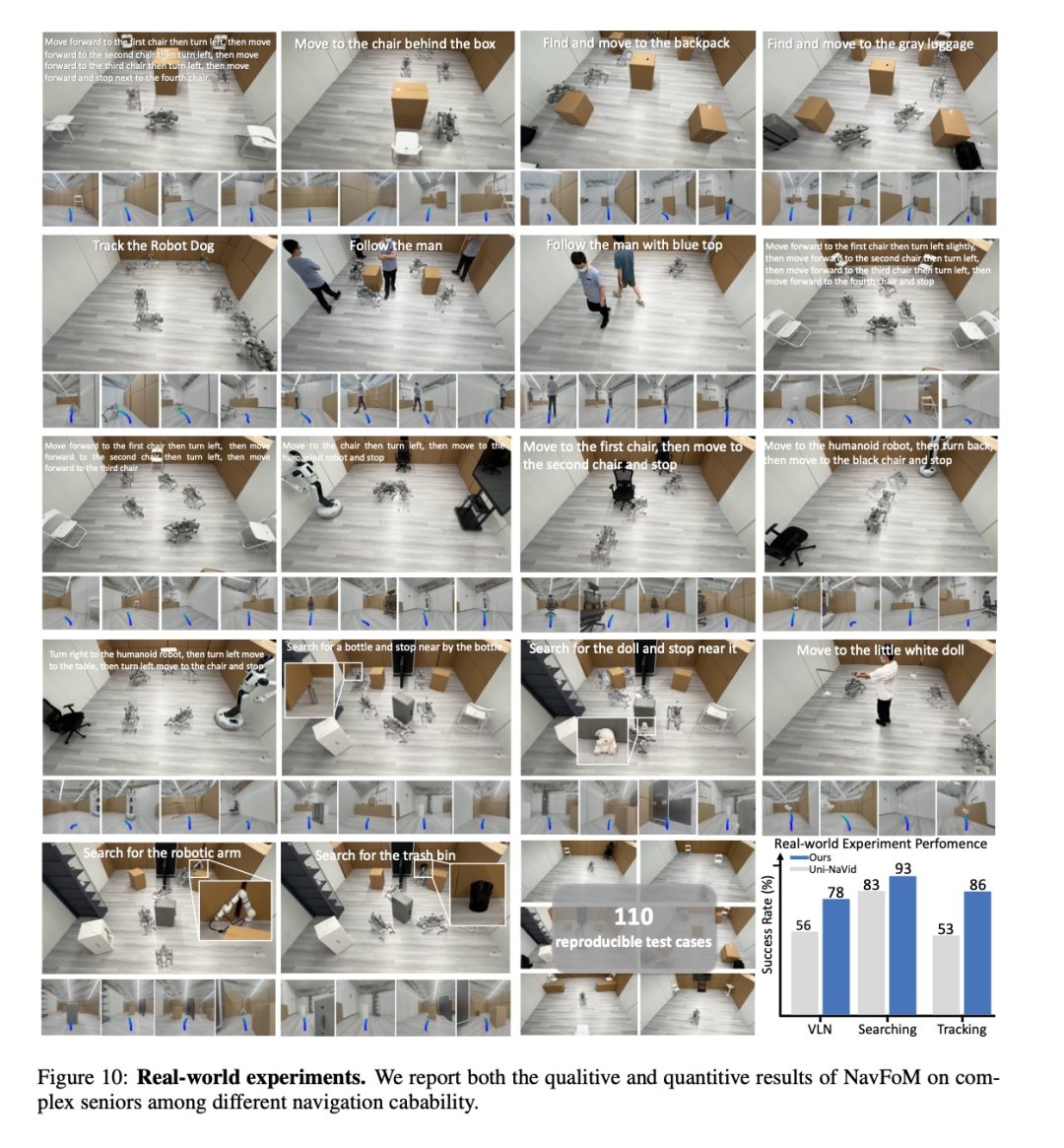

-
技术细节与消融研究
研究表明,多任务协同训练显著提升模型性能——目标搜索任务中,成功率从单任务训练的10.3%提升至多任务的45.2%。同时,增加相机数量一般会提高性能,但存在收益递减点。
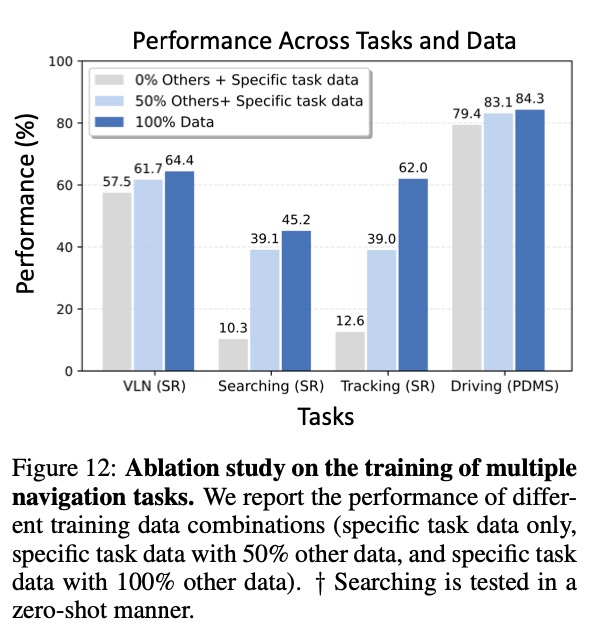
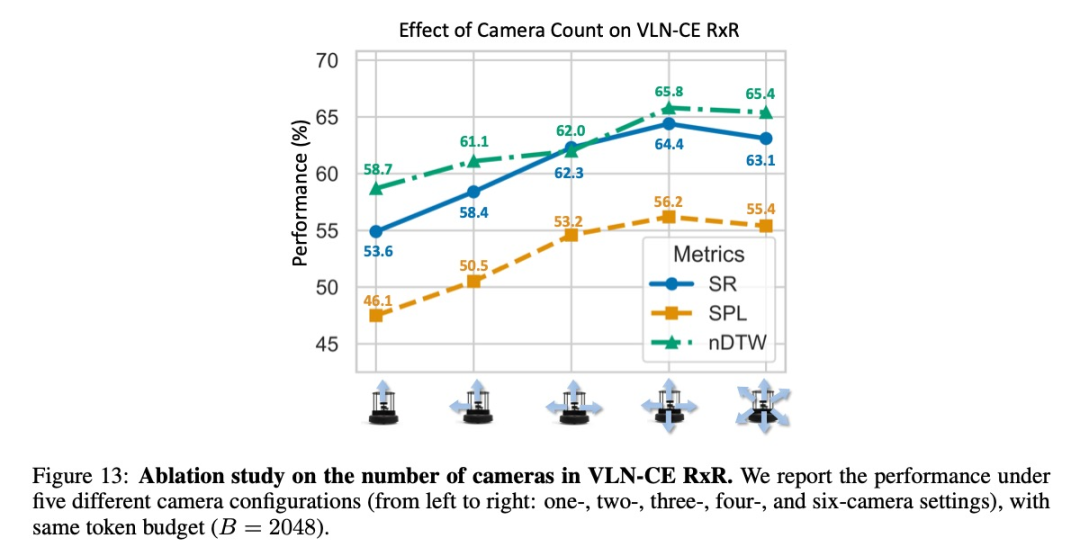
BATS策略在各种token预算下均优于其他采样方法,而TVI token的设计也被证明对模型性能至关重要。
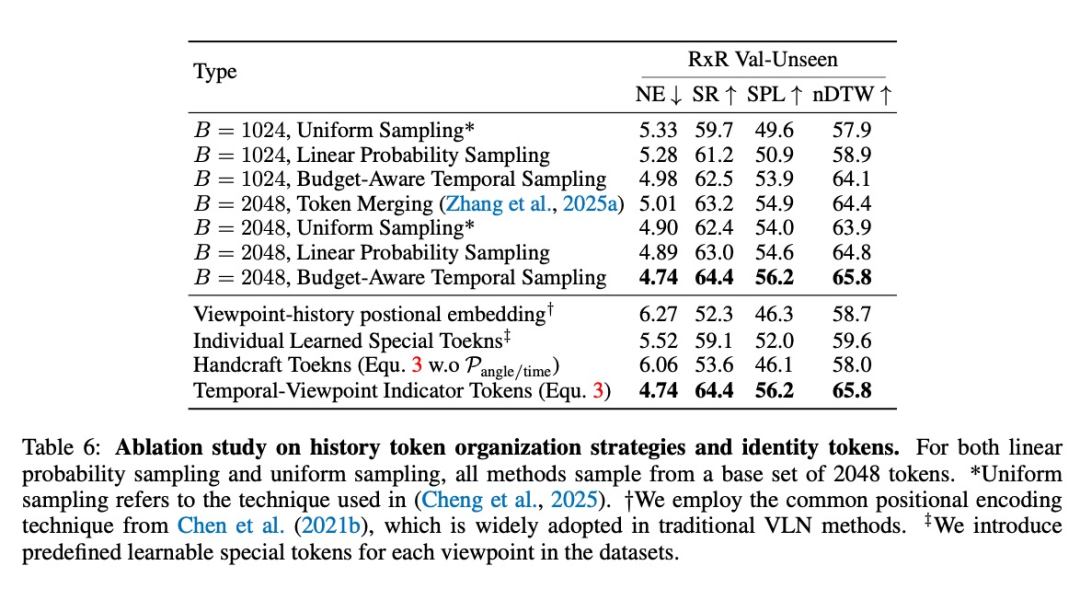
Coovally平台还可以直接查看“实验日志”。提供直观的可视化训练界面,清晰设置参数,监控训练过程(Loss, mAP等指标实时可视化)。
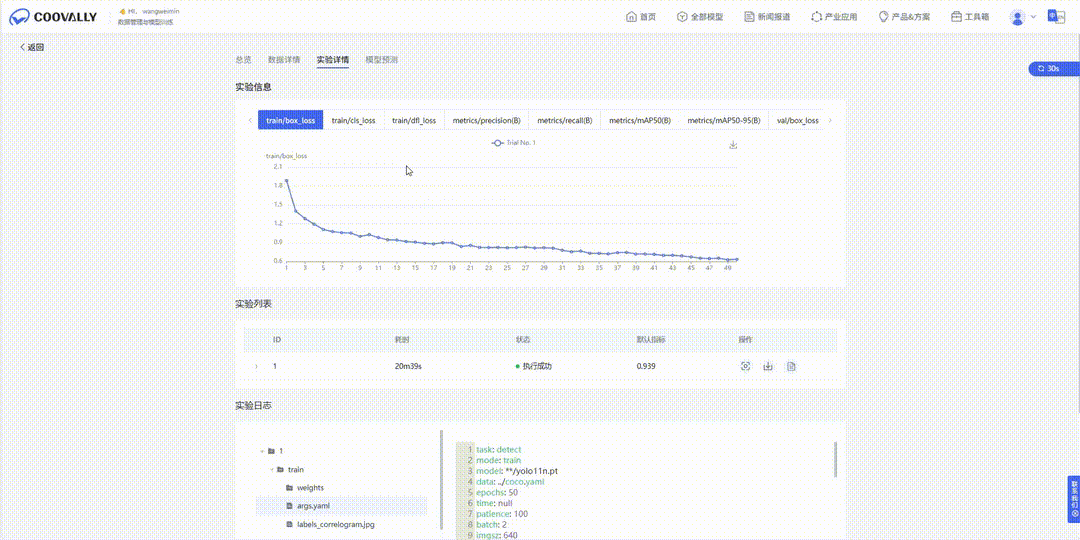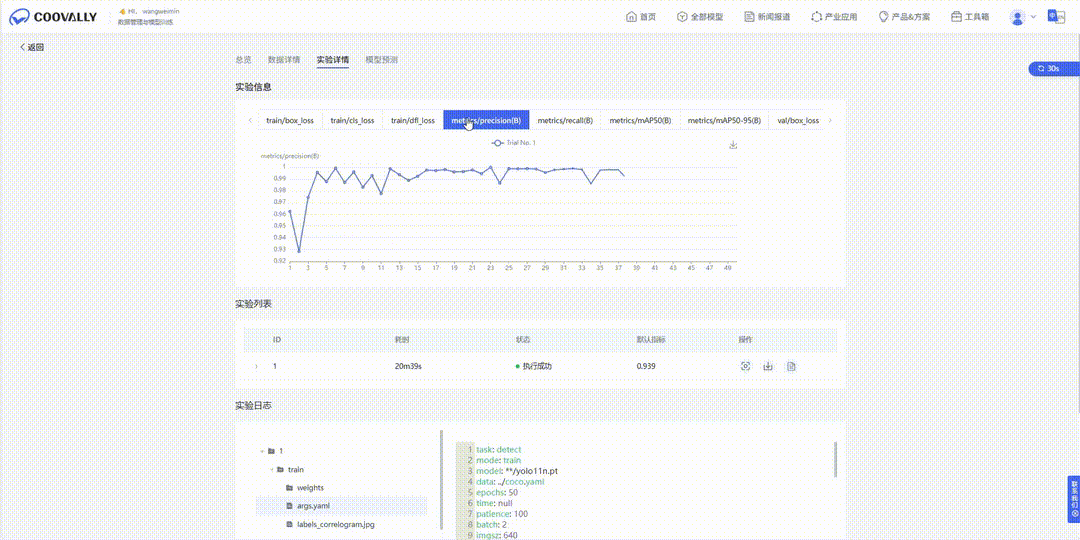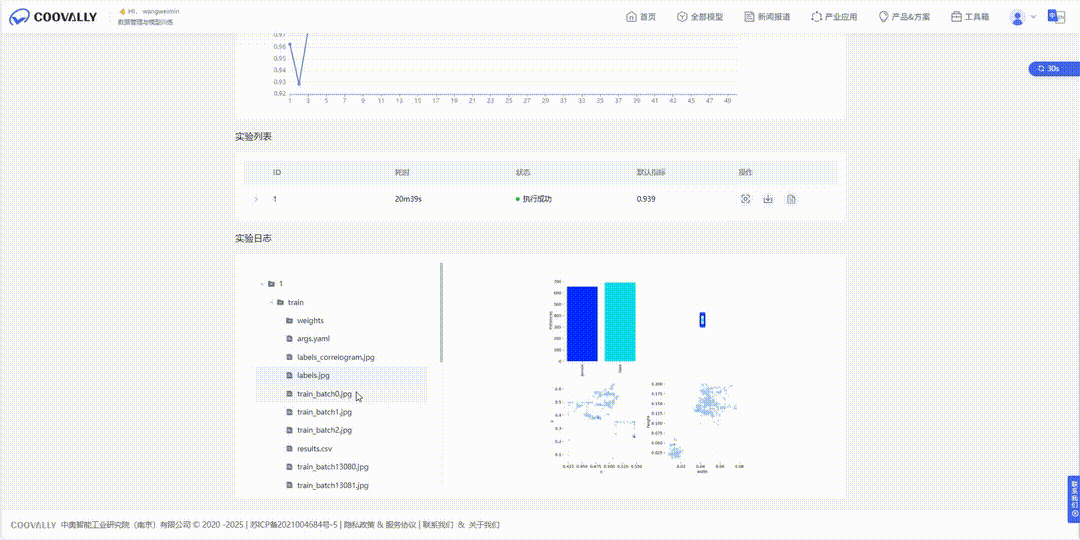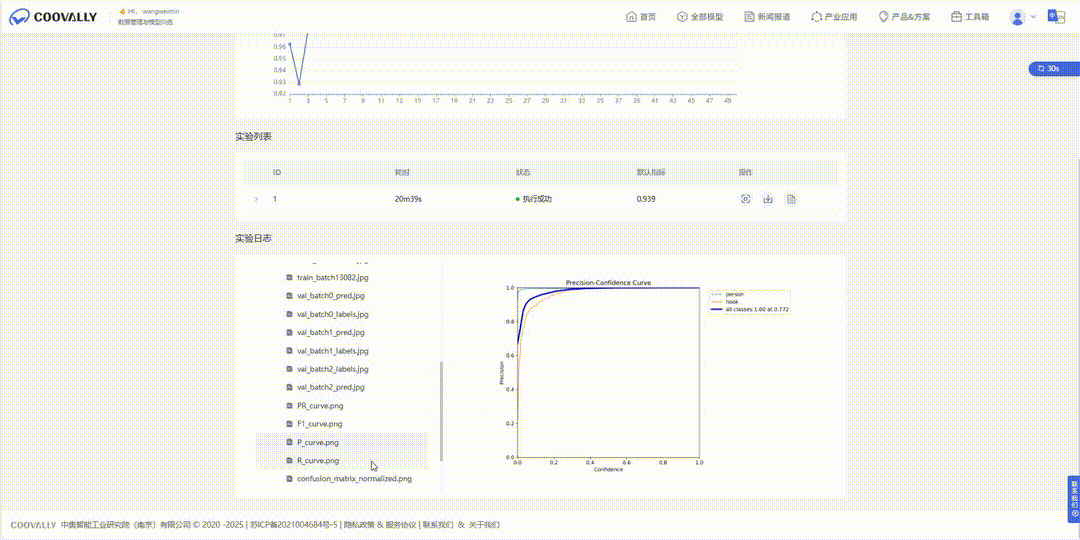
并行实验,效率倍增! 一键发起多个训练任务并行运行,结果一目了然,快速锁定候选者。支持分布式训练,充分利用硬件资源,大幅缩短训练时间。
未来展望
NavFoM作为通用导航基础模型的开创性工作,为具身智能领域提供了新的思路和方向。研究者认为这只是一个起点,未来可能在以下方向继续探索:
-
更高效的视角和时间信息整合方法
-
支持更多机器人形态和复杂任务
-
在更复杂现实场景中的进一步验证
随着技术的不断成熟,我们离真正通用的具身智能体又近了一步。



















 3811
3811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









