




前言
如果前两周去长三角,见的更多是客户的话,那么本周在北京出差的这几天(25年9.23-9.27),见的更多是合作伙伴,比如千寻、智元、中科院软件所、北京人形、某石油服务商等等
- 过程中顺带看了下银河通用的太空舱——说白了,就是机器人售卖站
我当时也实际点了瓶水,其中的轮式人形机器人「先移动到储存柜、抓水,后持水的同时 转身再移动到顾客柜台,最后放下水」的整个过程还是相对稳定、可控的 - 说到移动,便不可避免的会提到导航,不过,现有的轮式人形基本都集成了SLAM在内的移动导航功能
说到导航,这两天 则又看到了本文正要解读的NavFoM,个人觉得,该工作的创新不少,值得多读几遍
- 且我费了比较大的劲,把原论文行文过程中提到的所有参考文献,全都逐一的把对应的论文名称直接列了出来,方便大家 根据“论文名称”直接搜索、查阅对应论文
- 顺带感慨下,我个人认为:如果想打造技术影响力,有两个最佳途径:1 开源,2 分享。而对于我个人或我司,在1之前,暂先使劲的 全力的分享,无限利他中推动自我
第一部分 NavFoM
1.1 引言与相关工作
1.1.1 引言
如NavFoM原论文所说,对于具身智能体和人类来说,导航是一项基础能力,使其能够在物理环境中智能移动以完成特定任务
- Shah等,2023a,Gnm: A general navigation model to drive any robot
- Bar等,2025,Navigation world models
- Zhang等,2024b,Vision-and-language navigation today and tomorrow: A survey in the era of foundation models
- 而实现稳健的导航能力,需要对环境上下文和任务指令有深入理解,这些信息通常通过视觉和语言观测呈现,这与视觉语言模型(VLMs)类似
- 然而,视觉语言模型
Liu等,2023a,Visual instruction tuning
Yang等,2024a,Qwen2 technical report
Guo等,2025,Seed1. 5-vl technical report
最近在检索、分类和描述等任务上展现了卓越的零样本泛化能力,这些任务基于大规模开放世界数据进行,无需依赖领域特定的微调
相比之下,具身导航
Savva等,2019a,Habitat: A Platform for Embodied AI Research
Deitke等,2022,Procthor: Large-scale embodied ai using procedural generation
依然受限于狭窄的任务领域、具身特定的架构以及受限的指令格式
为了实现通用型导航,学术界对此领域的兴趣日益增长
- Zhang 等,2024a
Navid: Video-based vlm plans the next step for vision-and language navigation- Cheng 等,2025
Navila: Legged robot vision-language-action model for navigation- Shah 等,2023a
Gnm: A general navigation model to drive any robot- Long 等,2024
Instructnav: Zero shot system for generic instruction navigation in unexplored environment
然而,以往研究受限于设计的局限性和应用领域的有限性,导致进展缓慢
- 在跨任务导航中,现有方法
1 Zhang 等,2025a,Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks
2 Yin 等,2025,Unigoal: Towards universal zero-shot goal-oriented navigation
3 Zhu 等,2025,Move to understand a 3d scene:Bridging visual grounding and exploration for efficient and versatile embodied navigation
通常假设机器人拥有一致的相机配置,并统一处理视觉-语言导航、目标搜索及目标跟踪等多种任务 - 而对于跨载体导航,目前的方法
Eftekhar 等,2024,The one ring: a robotic indoor navigation generalist
Hirose 等,2023,Exaug: Robot-conditioned navigation policies via geometric experience augmentation
往往是隐式学习载体的物理形态先验,但通常仅限于特定的导航任务。导航任务与载体之间的这种分歧,凸显了当前缺乏能够在多样载体下处理不同任务的基础性导航模型
对此,来自1 Peking University、2 Galbot、3 USTC、4BAAI、5 University of Adelaide、6 Zhejiang University、7 Differential Robotics的研究者提出了一个跨任务和跨形态的具身导航基础模型——NavFoM,该模型在八百万个涵盖多种形态与任务的导航样本上进行训练
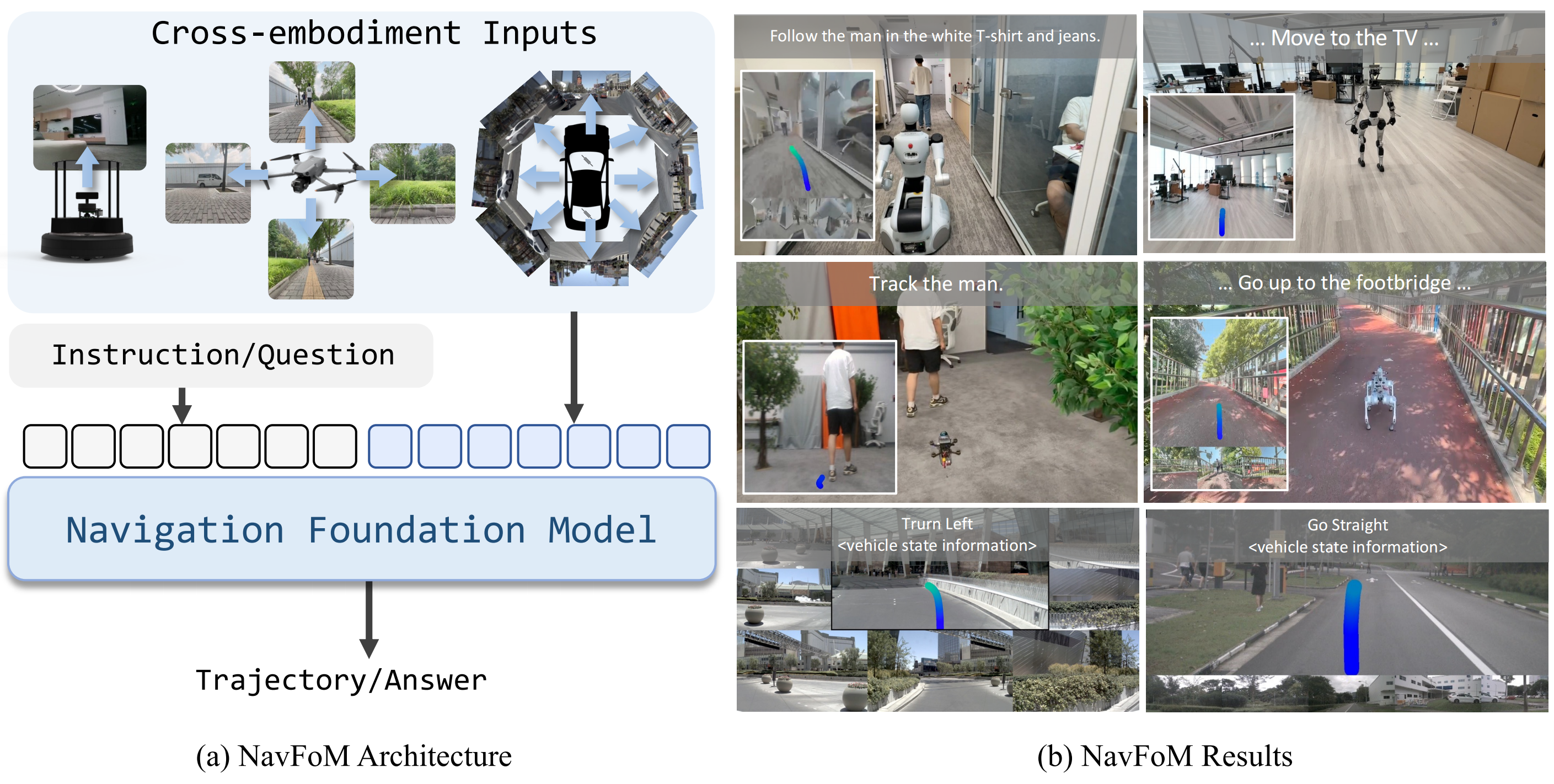
- 其paper地址为:Embodied Navigation Foundation Model
其对应的作者为:
Jiazhao Zhang1,2,∗、Anqi Li1,2,∗、Yunpeng Qi3,4,∗、Minghan Li2,∗
Jiahang Liu2、Shaoan Wang1、Haoran Liu1,2、Gengze Zhou5
Yuze Wu6、Xingxing Li6、Yuxin Fan6、Wenjun Li6
Zhibo Chen3、Fei Gao6,7、Qi Wu5、Zhizheng Zhang2,4,†、He Wang1,2,4,† - 其项目地址为:pku-epic.github.io/NavFoM-Web
截止到25年9.27,尚未开源,且尚不知其是否有开源的计划
具体而言,其受人类主要依靠视觉感知完成多种导航任务能力的启发,以及近期纯视觉导航方法「Shah等,2023a-Gnm: A general navigation model to drive any robot;Zeng等」的成功,作者将通用导航任务表述为:处理以自我视角拍摄的视频(由安装在机器人上的一个或多个摄像头采集)以及语言指令,并预测后续轨迹以完成这些指令
这一任务表述与目前大多数现有导航任务设置兼容「Contributors, 2023-Openscene: The largest up-to-date 3d occupancy prediction benchmark in autonomous driving;Wang等2024a-Towards realistic uav vision-language navigation: Platform, benchmark, and methodology」
- 且为了在不同摄像头配置下实现可泛化的模型对齐,作者引入了时序-视角指示符token(TVI token),用于标识摄像头设置的视角以及导航时域的信息
通过动态调整这些TVI token,他们的方法能够在不同摄像头配置间实现协同调优,并支持与图像问答和视频问答样本的联合训练
Shen等2024-Longvu: Spatiotemporal adaptive compression for long video-language understanding
Li等2023-Llama-vid: An image is worth 2 tokens in large language models - 此外,为了解决实际部署中如硬件内存成本和推理速度等限制,作者还提出了一种token预算感知时序采样(BATS)策略,该策略根据受token预算约束的遗忘曲线动态采样导航历史token
这种token采样方法在性能与推理速度之间实现了平衡,提升了他们方法在真实场景部署中的实用性质 - 且他们按照「Zhang等2024a-Navid: Video-based vlm plans the next step for vision-andlanguage navigation」的方法,将导航数据与图像和视频问答数据进行联合调优,实现了NavFoM的大规模端到端综合训练
1.1.2 相关工作
第一,对于用于导航的大模型
将大型模型(LLMs 和 VLMs)集成到机器人导航中,已使该领域从传统的基于学习的方法转向利用预训练知识,实现对开放世界的理解以及强大的泛化能力
- 一种直接的方法
Zhou 等, 2023,Navgpt: Explicit reasoning in vision-and-language navigation with large language models
Shah 等, 2022,Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action
Qiao 等, 2023,March in chat: Interactive prompting for remote embodied referring expression
是在零样本的情况下使用现成的 LLMs
这些工作强调通过思维链机制
Pan 等, 2023,Langnav: Language as a perceptual representation for navigation
Long 等, 2023,Discuss before moving: Visual language navigation via multi-expert discussions
Lin 等, 2025,Navcot: Boosting llm-based vision-and-language navigation via learning disentangled reasoning
和结构化推理框架
Chen 等, 2024b,Mapgpt: Map-guided prompting for unified vision-and-language navigation
Qiao 等,2025,Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms
提升可解释性
然而,将密集的视觉信息抽象为文本会导致环境观测变得稀疏,并且仅限于静态环境 - 另一种途径
Cheng 等, 2025,即Navila: Legged Robot Vision-Language-Action Model for Navigation
简介:提出流式 VLN 框架,采用“慢-快”双分支视频语言模型,在线处理长时序视频流,解决长距离导航中的上下文遗忘问题,在 VLN-CE RxR 上刷新指标
则是对基于视频或图像的
Zhou 等,2025,即Vision-Only Legged Robot Navigation with Pre-trained Image Models
Zheng 等, 2024,即Towards Learning a Generalist Model for Embodied Navigation
Zhang 等, 2025c,即NaV³: Understanding Any Instruction, Navigating Anywhere, Finding Anything
视觉-语言模型进行端到端微调,利用导航数据使 VLMs 掌握导航能力
这点挺类似于微调VLM得到VLA,而这里则微调VLM得到VLN
然而,现有方法大多聚焦于同构体,忽视了不同体态和任务之间潜在的训练协同作用。在本工作中,作者首次尝试将导航策略拓展到跨体态和跨任务的更广泛领域
第二,对于跨形态导航
在具身人工智能领域,开发能够在不同形态——如形状、尺寸和传感器配置各异——之间泛化的导航模型仍然是一项重大挑战
- 近期的研究工作
Shah等,2023a;b,即GNM: A General Navigation Model to Drive Any Robot、ViNT: A Foundation Model for Visual Navigation
后者在 GNM 基础上扩展为“视觉导航基础模型”ViNT,引入可提示的目标图像编码器,支持任意目标图像或语言指令作为导航目标
Yang等,2024b,即Pushing the Limits of Cross-Embodiment Learning for Manipulation and Navigation
Wang等,2020,即Environment-Agnostic Multitask Learning for Natural Language Grounded Navigation
Eftekhar等,2024,即The One Ring: A Robotic Indoor Navigation Generalist
Hirose等,2023,即ExAug: Robot-Conditioned Navigation Policies via Geometric Experience Augmentation
Putta等,2024,即Embodiment Randomization for Cross-Embodiment Navigation
Curtis等,2024,即Embodiment-Agnostic Navigation Policy Trained with Visual Demonstrations
Wang等,2025a,即X-Nav: Learning End-to-End Cross-Embodiment Navigation for Mobile Robots
Zhang等,2025b,即NaV³: Understanding Any Instruction, Navigating Anywhere, Finding Anything
展示了基于Transformer的策略在大规模跨形态数据集上训练后,无需手动对齐观测与动作空间,便能在多种机器人平台上实现稳健性能的潜力 - 然而,这些模型通常在处理多模态输入时,并未引入显式的空间与时间线索,导致由于不同形态数据的几何解释差异而产生歧义
此外,这种方法还可能带来数据利用效率低下以及对分布外形态泛化能力有限等问题。Eftekhar等,2024,The One Ring: A Robotic Indoor Navigation Generalist
Wang等,2025b,X-Nav: Learning End-to-End Cross-Embodiment Navigation for Mobile Robots
相比之下,NavFoM引入了时空指示符token,用于编码观测配置,使模型能够更好地理解来自不同形态的多模态输入
第三,对于跨任务导航
近期在具身人工智能领域的进展
- O’Neill 等,2024,即Open X-Embodiment
- Team 等,2024,即Octo
- Kim 等,即OpenVLA
- Bjorck等,2025,即Gr00t N1
- Black 等,2024,即π0
- Intelligence 等,2025,即A Vision-Language-Action Model with Open-World Generalization,说白了,就是π0.5
- Bu 等,2025b;a
简介:提出任务-centric 隐动作空间,将不同机器人动作统一为潜变量,用单一 Transformer 策略完成跨具身、跨任务导航与操作,零样本迁移至 10 种机器人
- Qu 等,2025,即EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
表明,基于基础模型构建的通用模型能够有效地在不同任务之间迁移知识
- 在导航领域,以往的研究
Zhou 等,2024,即Towards Learning a Generalist Model for Embodied Navigation
Wang 等,2022,即VIENNA: A Unified Reinforcement Learning Framework for Vision-Language Navigation
Long 等,2024,即InstructNav: Zero-Shot System for Generic Instruction Navigation in Unexplored Environmen
Song 等,2025,即Towards Long-Horizon Vision-Language Navigation: Platform, Benchmark and Method
Zhang 等,2025a,即Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Gao 等,2025,即OctoNav: Towards Generalist Embodied Navigation
用单一 Transformer 完成 VLN、ObjNav、跟踪等任务,仍假设固定相机配置,未引入可扩展的时空 token
Yin 等,2025,即UniGoal: Towards Universal Zero-Shot Goal-Oriented Navigation
Ruan 等,2025,即From Reactive to Cognitive: Brain-Inspired Spatial Intelligence for Embodied Agents
表明,将不同类别导航任务的数据进行整合,可以显著提升模型在多种导航场景下的表现 - 早期的工作VIENNA「Wang 等2022,即VIENNA」利用强化学习在模拟环境中训练智能体
近期,Uni-Navid「Zhang 等2025a,即Uni-NaVid」基于视频视觉-语言模型提出了一种通用模型,通过跨任务学习掌握了四类任务的通用导航技能,包括视觉-语言导航、目标物体导航、具身问答以及跟随人类
然而,这些方法仅限于受限环境(如室内可控环境),而NavFoM的工作将研究范围扩展到更广泛的场景(如自动驾驶和无人机导航),并在统一的通用框架下对所有任务进行建模
在该框架中,模型以RGB视频和自然语言指令为输入,输出可执行的轨迹
1.2 NavFoM的完整方法论
首先,定义一系列问题
对于通用导航任务。作者考虑一种通用的导航设置:
- 移动体接收到一条文本指令L和一系列图像
,在时间步长 {1, ..., T} 之下 从 N 个不同的摄像头实时捕获
- 给定这些观测和指令,他们的模型π需要预测一条导航轨迹
,其中每个
代表一个位置和朝向的航点
需要注意的是,z仅在机体为无人机(UAV)时使用,θ表示偏航角(由于他们的任务不需要敏捷的飞行动作,因此仅需偏航角即可)
总之,最后该模型根据映射驱动移动实体来执行指令
其次,对于基本架构而言
作者将原始的视频视觉-语言模型VLM
比如
- Li等2023,Llama-Vid: An Image is Worth 2 Tokens in Large Language Models
提出极度压缩的视觉 token 方案,将单张图像仅用 2 个 token 表示,使 LLM 在不增加序列长度的情况下同时处理长视频、多图像与文本,成为后续视频 VLM 的常用基线- Shen等2024,LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
提出时空自适应压缩机制,将任意长视频压缩至固定 token 预算,支持小时级视频问答与导航,被后续多篇视频 VLM 作为视觉编码器组件扩展为用于导航和问答的双分支架构『Wang等2025c,即TrackVLA,其提出首个“跟踪 VLA”模型,采用双分支结构(导航 + 问答)共享视觉-语言编码器,单模型零样本完成跟踪、VLN、问答三项任务,成为 NavFoM 双分支架构的直接参考』
为处理多项任务(包括图像问答、视频问答和导航)提供了统一的框架。作者使用时序-视角指示符token(见下文1.2.1节-对应于原论文第3.1.1节)对文本token和视觉token进行组织,具体细节如下文1.2.3节-对应于第3.1.3节所述
- 在问答任务中,模型采用传统的自回归语言建模头
- 而在导航任务中,则使用规划头直接预测路径
- 对于导航任务,作者首先使用视觉编码器和跨模态投影器
参照Liu 等人2023a,即Visual Instruction Tuning,说白了,就是LLaVA,进一步而言,提出的 LLaVA 系列视觉指令调优框架,给出“视觉编码器 → 跨模态投影 → LLM”的标准三路设计,被后续几乎所有 VLM/VLA 工作(含 NavFoM)采用为默认投影方案
对观测到的图像进行编码,以获得视觉token
至于文本指令则依照现有语言模型比如LLaVA中的常见做法——被嵌入以生成语言标记
————————
- 对于问答任务,作者遵循已有方法LLaVA,以自回归方式预测下一个token。
另,与已有研究(NaVid、Uni-NaVid、TrackVLA、Navila)类似,NavFoM实现了导航和问答样本的联合调优
1.2.1 导航基础模型:涉及对观测的编码、时序视角指示器(TVI) token、token预算感知时序采样BATS、LLM转发
首先,对于观测编码
给定在时间步长 T 从 N 个多视角相机捕获的以自我为中心的 RGB 序列,作者采用了预训练的视觉编码器DINOv2和SigLIP『这是一种被广泛采用的方法,比如用在了Kim等推出的OpenVLA,以及Tong等2024发布的Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs)』,以提取视觉特征
,其中P为patch数量(设为576),C为特征维度
其次,对于嵌入维度表示
- 为了节省token和提高计算效率,作者直接沿通道维度将
和
连接起来,并将得到的表示记为
- 在导航过程中,实时捕获的视频会产生大量帧,从而生成大量视觉特征
为了解决这一问题,作者对视觉特征采用网格池化策略——类似NaVid、Uni-NaVid「见图3,网格平均池化」,以生成更为紧凑的表示
具体而言,作者采用了两种分辨率尺度:

其中,提供细粒度的观测,而
提供粗粒度的观测
在本例中,作者将细粒度特征用于最新的导航观测和图像问答(在时间步T),而将粗粒度特征用于导航历史和视频数据(跨时间步 1 到 T)
个人认为,这个处理确实很有针对性,赞
最后,按照已有的多模态大语言模型——LLaVA、Llama-Vid,作者采用跨模态投影器(一个两层 MLP)将视觉特征投射到大语言模型的潜在空间中:
1.2.1.1(原论文3.1.1节) 时序视角指示器(TVI)token
鉴于视觉token本身并未包含视角和时序信息,多视图导航模型中的一个关键挑战在于,使大语言模型(LLM)能够识别哪些token对应于不同的时间步或不同的摄像头视角
以往的方法
- 要么仅适用于特定的摄像头配置或具身体(InstructNav;OctoNav)
- 要么只是简单地将所有视角图像的token拼接在一起
Zheng 等,2024;Fu 等, 2025b
从而忽略了LLM token组织的灵活性
为实现对任意摄像头排列的灵活处理,作者引入了时序-视角指示token,这一灵感来源于为时间/模态/任务识别专门设计的token已被证明具有显著效果
- Guo 等, 2025,即Seed1.5-VL Technical Report
该系统验证了 “专门设计的模态/时间/任务标识 token” 能显著提升 LLM 对多模态序列的理解与学习效率,为 TVI token 提供直接灵感- Chen 等,2023,即MiniGPT-v2: Large Language Model as a Unified Interface for Vision-Language Multi-Task Learning
提出用特殊任务 token(如 [vqa]、[grounding])统一多任务输出,证明显式标识符可降低任务间冲突,被后续工作广泛借鉴
该方法已被广泛认为有助于LLM的学习
在作者的设置中,指示token被应用于多种任务,包括图像问答、视频问答和导航,并且应满足以下三个重要属性:
- 视角感知:Token 的角度嵌入必须保留方位角的圆周连续性(例如,0≡2π),确保嵌入之间的距离度量能够反映几何上的接近程度(例如,当
时,
)
- 时间感知:Token 必须能够唯一标识所有摄像机视角下帧的时间顺序,同时对不规则采样间隔具有鲁棒性
- 可分离性:指示器token可以编码视角信息或时间信息(用于视频问答),也可以完全不包含此类信息(用于图像问答)
为满足这些需求,作者提出的时序-视角指示器TVI token (其中时间步和视角分别记作 t 和 ϕ)由三种类型的嵌入组成:
- 角度嵌入
- 时间嵌入
- 以及可学习的基础嵌入
最终如下表达式 所示
其中,通过对方位角的余弦值和正弦值分别应用正弦位置编码(Vaswani等人,2017)后进行拼接实现,
则作为对
的正弦位置编码实现。在此,
和
均采用两层MLP实现——设计类似于Liu等人(2023a)LLaVA中所用
针对不同任务和TVI token,作者采用不同的指示token组件组合来表征各类视觉token的属性
- 对于导航任务,包含了时间和视角信息
- 对于视频问答任务,作者引入了时间信息
- 对于图像问答任务,仅使用EBase作为指示,标识后续token为视觉token
这一策略为组织差异显著的样本类型提供了灵活的方法,并促进了LLM的学习(对应原论文第3.1.3节)
且在图4——时序视角指示器(TVI)token的可视化。我们采用聚类算法(McInnes等,2018)将高维嵌入映射到二维空间 中展示了TVI Tokens的聚类结果(McInnes等人,2018),可以观察到这些token根据视角θ (以彩虹色条表示)和时间步t (以颜色值表示)被区分开
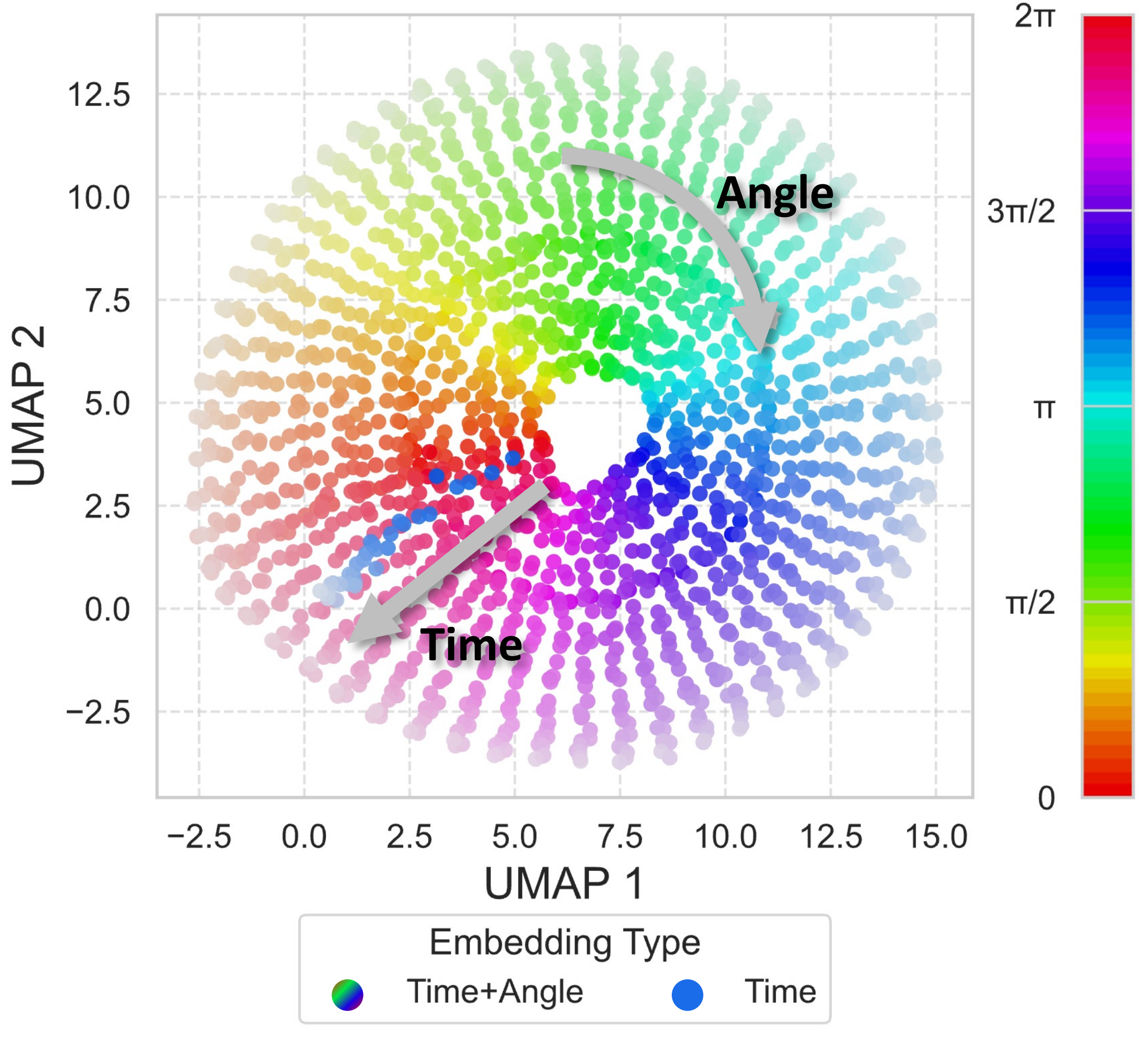
1.2.1.2(原论文3.1.2节) 面向token预算的时序采样(BATS)
在导航过程中,实时采集的视频可能会生成过多的视觉token,从而增加推理和训练时间,影响实际部署
以往的方法主要通过两种方式解决这一问题:
- TokenMerging(Zhang 等2025a,即Uni-NaVid)
该方法在训练时引入了额外的计算开销,并导致评估阶段推理速度不一致 - Uniform Sampling(Cheng 等2025,即Navila)
由于缺乏短期上下文,常常无法充分捕捉到最新的观测
此外,在涉及可变摄像机视角设置(帧数显著增加)的场景下,这两种策略都需要额外的修改
为此,作者提出了预算感知时序采样(BATS)方法,其设计目标包括:
- 满足实际应用需求(即限制最大Token长度,以适应推理速度和GPU内存限制)
- 保留更多近期信息,从而提升理解与规划能力,同时保持足够的历史上下文以支持导航能够直接适应不同数量的摄像头
具体而言
- 给定一个Token预算
和一个多视角视频序列
,该方法受“遗忘曲线”启发。在这种情况下,当捕获的帧token数量超过token预算时,作者为每一帧计算一个采样概率(定义为公式4):
其中ϵ(作者使用ϵ=0.1)确保采样概率的下界处于近似范围内,k表示指数衰减率 - 因此,期望采样帧的数量可以计算为(定义为公式5):
作者约束期望的 token 数量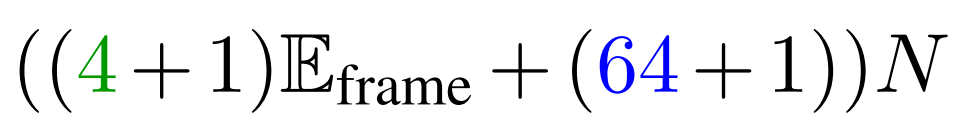 不超过
不超过 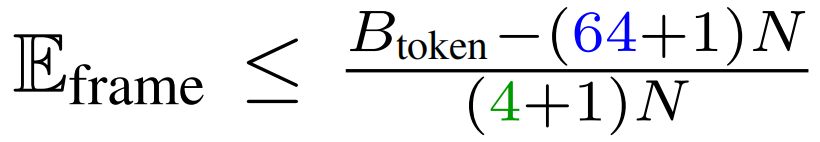 ,并且当帧数 T 充分大时,数量采样帧的均值将收敛于期望值(见图5(c))
,并且当帧数 T 充分大时,数量采样帧的均值将收敛于期望值(见图5(c))
且可以采用Brent方法(Brent, 2013)针对不同的T离线计算k,从而得到相应的
——————
需要注意的是,由于作者设置了下界概率ϵ,当T非常大时(例如,在四摄像头配置且token预算的情况下
),公式5可能无解
然而,这种情况极为罕见(如图2中的列表任务)
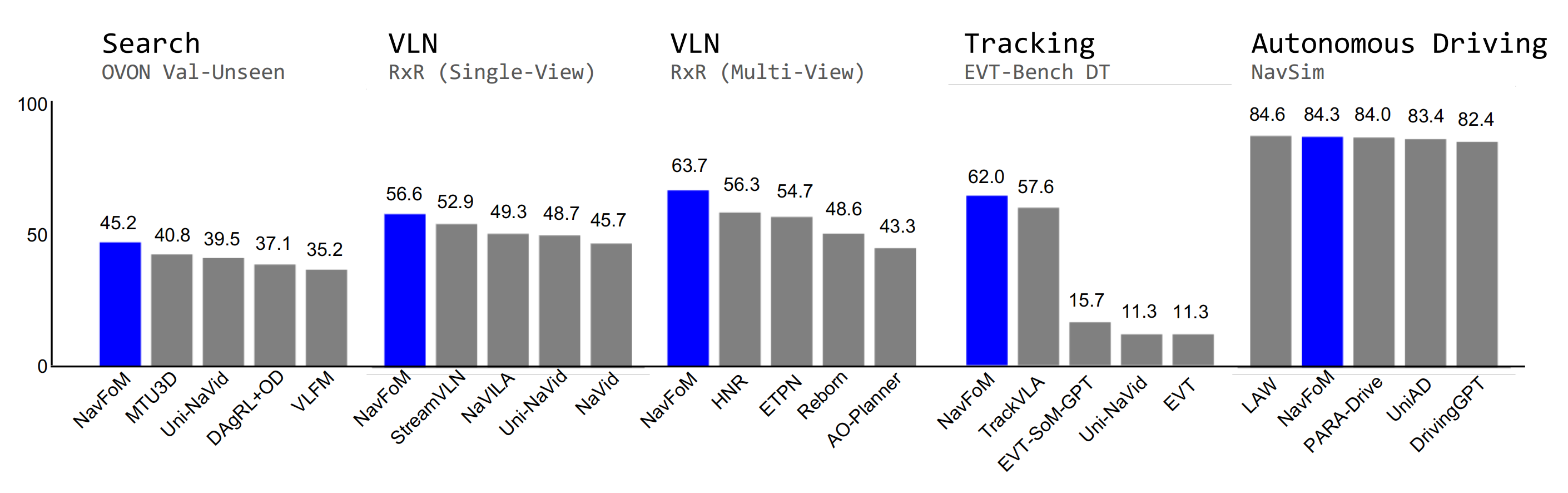
因为在VLN-CE RxR(Ku等, 2020)中,大多数时间步大约为122步。关于BATS的使用细节,请参见附录A.2
另,作者在图5中绘制了时间步采样概率分布和时间效率
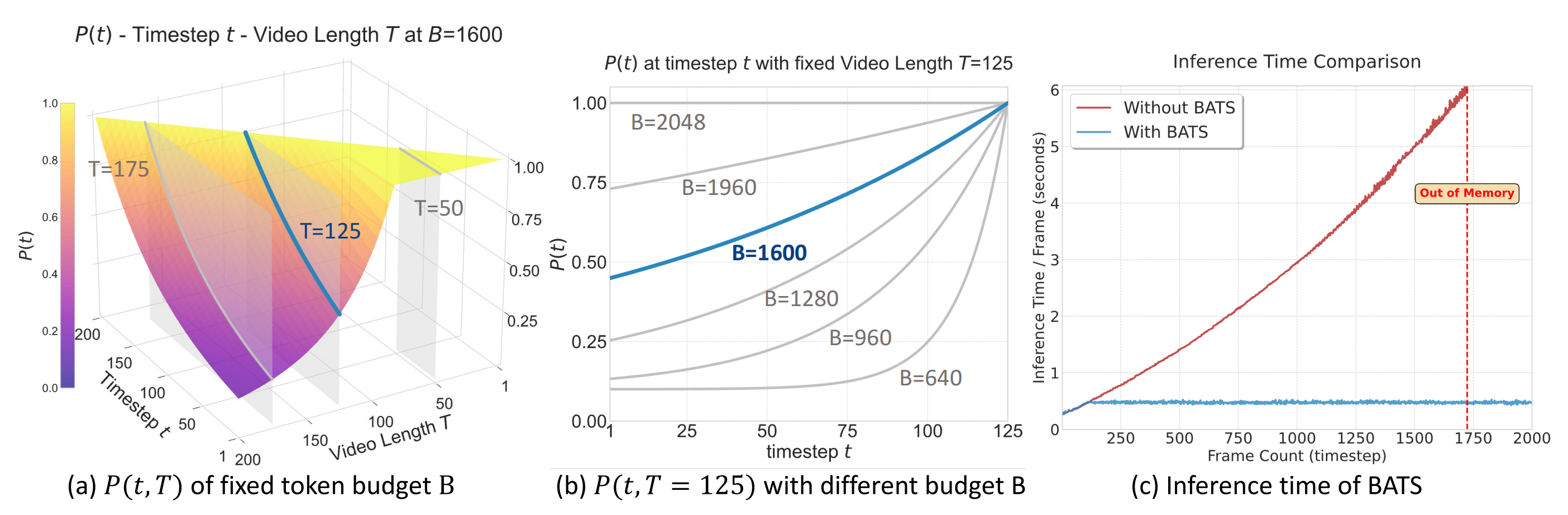
BATS的可视化及其对应的时间成本
- (a) 在固定的token预算B=1600的情况下,展示了在最新时间步T下,不同时间步t的采样概率
- (b) 在最大时间步T=125的条件下,作者绘制了在不同token预算B下,不同时间步t的采样概率
- (c) 对比了使用BATS与不使用BATS(保留所有帧)时的推理时间
从图中(图b)可以观察到:他们的方法在不同的 token 预算 B 和时间步 T 下,能够平滑地获得合理的 P(t)
- 当 token 预算较高时,BATS策略能够自适应地采样更多的历史 token
- 即使在 token 数较少的情况下,他们的策略仍然保持了合理的下界
此外,他们注意到 BATS 在整个导航过程中始终保持了稳定的推理速度
1.2.1.3(原论文3.1.3节) LLM转发
首先,对于Token组织
获得视觉tokens 后(通过BATS采样,见3.1.2节)以及语言tokens
,作者使用TVI Tokens(见3.1.1节)对这些tokens进行组织,以便LLM进行转发
具体而言,作者在图6中详细展示了针对不同任务的Token组织策略
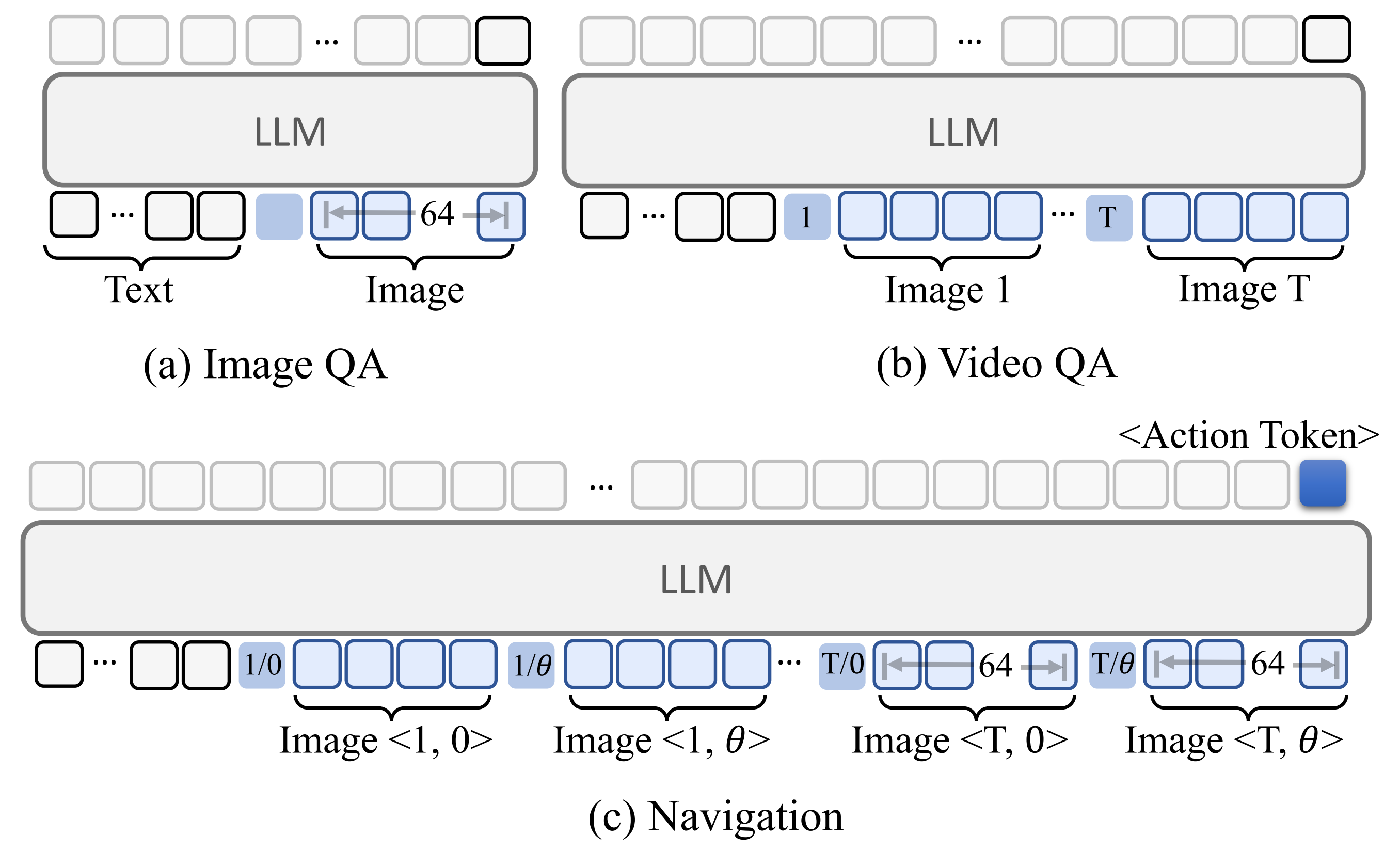
- 对于图像问答 Image QA
使用——仅包含TVI Token的基础嵌入,结合细粒度视觉Token (每张图片64个Token)来表示图像
- 对于视频问答 Video QA
引入——包含TVI Token的基础嵌入和时间嵌入,以对每一帧进行时间信息编码,并采用粗粒度视觉Token(每帧4个Token),以避免Token数量过多
- 对于导航任务
采用——融合了TVI Token的基础、时间和角度嵌入,来同时表示时间和视角信息
在这里,最近的观测使用细粒度视觉Token,而历史观测则采用粗粒度Token。总之,该Token组织策略提升了LLM对输入Token的理解能力,并支持图像问答、视频问答及导航任务的统一框架
其次,对于轨迹预测
对于导航任务,给定来自 LLM 前向传递的预测动作隐藏状态 ,作者应用规划模型
(实现为一个三层多层感知机)来提取轨迹信息
『For the navigation task, given the predicted action hidden state EAT from the forward pass of the LLM, we apply a plannning model Aθ(implemented as a three-layer MLP) to extract the trajectory information τT』
- 需要注意的是,原始轨迹的长度可能从几米(室内导航)到数十米(自动驾驶和无人机)不等。在这种情况下,直接预测原始轨迹可能会导致航点分布发散
- 因此,参照Shah等人(2023a)的方法,作者将轨迹的航点通过任务相关的缩放因子
归一化到[−1,1]的分布
具体来说,作者针对室内导航、无人机和汽车分别采用了三种不同的缩放因子,详见附录A.1。轨迹预测可表述如下
其中Mis设置为8,并且通过乘以将归一化轨迹重新缩放为绝对值
- 轨迹损失通过均方误差(MSE)计算,
,其中idx表示有效动作索引
对于轮式机器人/车辆实体,;对于无人机,
- 在问答任务中,作者在下一个token预测的监督框架下采用交叉熵损失
故,对于包含导航和问答样本的一个批次,总损失定义为。其中,β是一个常数缩放因子(设为10),用于放大导航损失,因为该损失源自均方误差,数值上通常较小
1.2.2 数据
为了对NavFoM进行微调,作者收集并处理了大量全面且多样化的训练样本,总计1270万条实例。其中包括802万条导航样本、315万条基于图像的问答样本,以及161万条基于视频的问答样本,且他们的训练样本规模超过了以往的方法(Zhang等,2024a;2025a)
- 导航样本涵盖了多种移动实体(轮式机器人、四足机器人、无人机和汽车),涉及视觉与语言导航、目标物体导航、主动视觉跟踪和自动驾驶等多种任务
- 所有导航数据均以统一的方式收集,包括先前捕获的视频(来自单摄像头和多摄像头)、指令以及预测的轨迹路径点
对于问答样本,作者依据现有的视频视觉-语言模型(VLMs)(Shen等,2024;Li等,2023),从现成的数据集收集了基于图像的问答和基于视频的问答数据
// 待更
1.2.3 实现细节
首先,对于训练配置
他们的模型在配备有56块NVIDIA H100 GPU的集群服务器上训练约72小时,总计使用4,032 GPU小时
- 对于问答数据,所有帧以1 FPS的速率采样,以减少连续帧之间的冗余
- 对于离散导航数据(例如,Habitat环境 Savva等人,2019a),作者在机器人执行每一步离散动作后采样(关于如何将离散动作转换为轨迹的详细信息,见附录A.1)
- 对于连续导航环境(例如,EVT-Bench Wang等人,2025c,自动驾驶Caesar等人,2020b;Contributors,2023),数据以2 FPS的速率采样,以避免冗余
在训练过程中,视觉编码器(DINOv2 和 SigLIP),以及大语言模型(Qwen2-7B)均采用默认的预训练权重初始化
且按照VLM「Liu等人LLaVA」的训练范式,作者仅对指定的可训练参数进行单轮微调
其次,对于通过缓存视觉特征加速训练
由于视频序列较长(数百帧),在大批量处理中对所有图像进行在线编码会导致极高的计算开销
- 为了解决这一问题,作者采用了一种视觉特征缓存机制(Yan等,2022),并构建了视觉特征数据库(见图8)
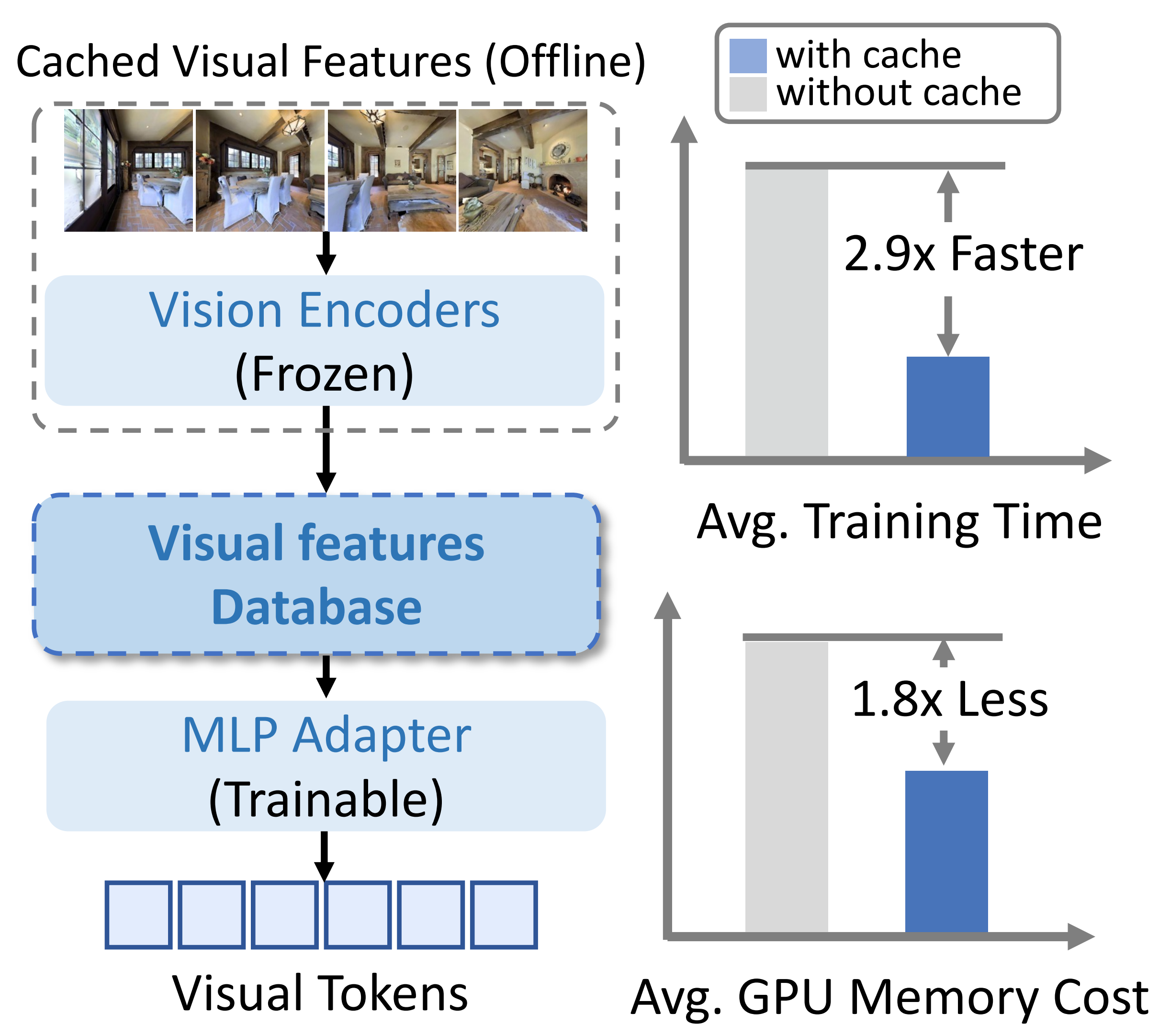
- 需要注意的是,作者仅缓存粗粒度的视觉token(每帧4个token),这相比存储完整视频大大节省了磁盘空间,因为单次导航通常会生成数十个视频
而对于图像问答和导航中的最新观测,作者仍然使用视觉编码器在线提取细粒度视觉token(每帧64个token)。这种方法有效减少了训练时间(提升2.9倍)和GPU内存占用(减少1.8倍)
1.3 实验
// 待更


















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











