



 【导读】
【导读】
本文分析 YOLO11 在车辆检测上的性能。相比前代(YOLOv8/v10),YOLO11 通过架构改进提升了速度、精度和在复杂环境(小目标、遮挡)下的鲁棒性。使用多车型数据集测试表明,其精度(mAP)、召回率等指标更优,同时保持实时推理速度。该模型在检测复杂形状车辆方面进步显著,对自动驾驶和交通监控有应用潜力。>>更多资讯可加入CV技术群获取了解哦~
目录
车辆检测是先进智能交通系统(ITS)开发的关键组成部分,该系统依赖于准确且实时的信息来优化交通流量、提升安全性和支持自动驾驶技术。随着道路上车辆数量的持续增长,对能够在各种条件下(如天气、光照和车辆类型变化)运行的 robust 车辆检测系统的需求变得至关重要。在交通监控中,车辆检测使实时分析交通模式、拥堵管理和事件检测成为可能,从而促进更高效的城市交通。此外,车辆检测是车辆分类和跟踪系统的基础,这些系统对于动态收费、交通执法和基础设施规划至关重要。

论文标题:
YOLOV11 FOR VEHICLE DETECTION: ADVANCEMENTS, PERFORMANCE, AND APPLICATIONS IN INTELLIGENT TRANSPORTATION SYSTEMS
论文链接:
https://arxiv.org/pdf/2410.22898
本文旨在评估YOLO11在车辆检测中的性能,重点关注其处理复杂和实时检测场景的能力。通过利用深度学习的最新进展并整合架构创新,YOLO11 旨在提升对各类车辆的检测精度,包括小型及部分遮挡的物体,同时保持适用于自动驾驶和交通管理等实时应用的效率。
本研究对 YOLO11 进行了全面的性能分析,将其结果与前代模型 YOLOv8 和 YOLOv10 进行了对比。通过精度、召回率、F1 得分和平均精度(mAP)等关键指标评估其优缺点。此外,还通过分析其在多样化条件下的速度和鲁棒性,探讨 YOLO11 在智能交通系统中的实际应用潜力。通过此次评估,论文旨在突出 YOLO11 在车辆检测领域的重要贡献,并为下一代交通系统提供实践应用的洞察。
一、研究方法
-
数据集
为了评估YOLO11在车辆检测中的性能,使用了与之前分析YOLOv8和YOLOv10时相同的数据集。该数据集包含1,321张标注图像,涵盖了交通系统中常见的多种车辆类型,包括汽车、卡车、公交车、摩托车和自行车。每张图像的分辨率为 416 x 416 像素,为 YOLO11 模型提供了统一的输入尺寸。该数据集记录了车辆在各种真实世界条件下的场景,包括白天和夜晚、不同天气模式(如雨天和雾天),以及遮挡和车辆与摄像头距离不同的复杂场景。这种多样性确保模型能够接触到广泛的环境,模拟智能交通系统和自动驾驶应用中遇到的真实世界条件。
每张图像都附有边界框注释和类别标签,以指示画面中每辆车辆的精确位置和类型。该数据集被分为70%用于训练、15%用于验证和15%用于测试,确保了准确的模型评估所需的平衡分布。该数据集曾在先前研究中用于评估YOLOv8和YOLOv10的性能,为比较提供了坚实基础,使我们能够在相同条件下评估YOLO11的改进与性能,确保研究间的连续性和可比性。
-
数据增强
为了提升YOLO11模型的泛化能力并使其能够处理各种真实世界场景,我们在训练过程中应用了多种数据增强技术。这些增强技术有助于模拟不同的环境条件、光照变化及物体方向。具体采用的增强方法包括:色调调整、饱和度调整、亮度调整、旋转、平移、缩放、剪切、透视变换、垂直翻转、水平翻转、拼贴增强11种增强方法。
-
千款模型+海量数据,开箱即用!
在Coovally平台上汇聚了国内外开源社区超1000+热门模型,覆盖YOLO系列、DETR等主流视觉算法。同时集成300+公开数据集,涵盖图像分类、目标检测、语义分割等场景,一键下载即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!

Coovally 还提供强大的数据增强功能,通过自动化应用多样化的数据增强功能(如旋转、翻转、色彩调整、噪声添加等),有效扩充训练数据,从而显著提升模型的泛化能力、鲁棒性并降低过拟合风险,用户可通过直观配置轻松实现。
二、YOLO11 架构
YOLO11 的架构相较于前代版本(尤其是 YOLOv8)实现了显著提升。YOLO11 引入了新的层、模块和优化措施,既提升了计算效率又提高了检测精度,使其成为车辆检测等实时任务的理想选择。
-
骨干网络
YOLO11 的骨干网络负责从输入图像中提取多尺度特征。这涉及一系列卷积层和自定义模块,以生成不同分辨率的特征图。YOLO11 引入了 C3k2 模块,并保留了前一版本中的空间金字塔池化快速(SPPF)模块,同时对 C2PSA 模块进行了新的改进 。
-
颈部
YOLO11的颈部设计用于聚合不同分辨率的特征图,并将其传递给检测头。YOLO11将C3k2块集成到颈部,以提升特征聚合的速度和性能。
-
检测头
YOLO11 的检测头负责生成模型的最终预测结果。与之前版本类似,检测头输出边界框、类别概率和置信度分数。
三、训练与验证设置
-
超参数
YOLO11 的训练过程使用了多个关键超参数来平衡模型性能和计算效率。初始学习率设置为 η = 0.01,并应用了余弦退火调度策略,以在 epoch 间逐步衰减,由以下方程表示:
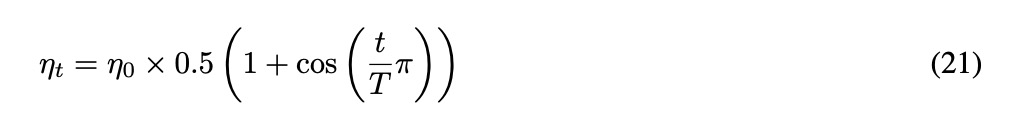
-
训练过程
模型采用带动量(动量值为0.937)和权重衰减(权重衰减率为0.0005)的随机梯度下降(SGD)优化器进行训练。实施了多尺度训练策略,将输入图像尺寸随机缩放至320×320至640×640像素之间,以提升模型在不同图像分辨率下的鲁棒性。
-
验证标准
在验证过程中,使用了多个指标来评估模型的性能:
• 平均平均精度(mAP):评估检测准确性的主要指标,mAP 在多个交并比(IoU)阈值(从 0.5 到 0.95)范围内计算:

其中 AP 是每个 IoU 阈值下的平均精度。
• 精确率和召回率:精确率衡量所有检测中正确检测的比例,而召回率衡量所有真实目标中正确检测的比例。
• 推理时间:测量处理单张图像所需的时间,以确保模型适用于实时应用。YOLO11 的推理时间与 YOLOv8 和 YOLOv10 进行了比较。
-
早期停止与检查点保存
为防止过拟合,采用了早期停止策略,并定期监测验证集性能。检查点定期保存,以便回滚到性能最佳的模型。
这种一致的训练和验证设置允许对 YOLO11 的性能进行全面评估,并可直接与前代模型 YOLOv8 和 YOLOv10 进行比较。
四、结果与性能评估
-
评估指标
使用标准物体检测指标评估 YOLO11 在车辆检测数据集上的性能,包括准确性、鲁棒性和效率,以便与 YOLOv8 和 YOLOv10 进行直接比较。
-
YOLO11 的性能
YOLO11 的性能评估涵盖多种车辆类型(汽车、摩托车、卡车、公交车、自行车),包含定量与定性分析(图1-6),揭示了其在实际检测中的能力与局限性。
-
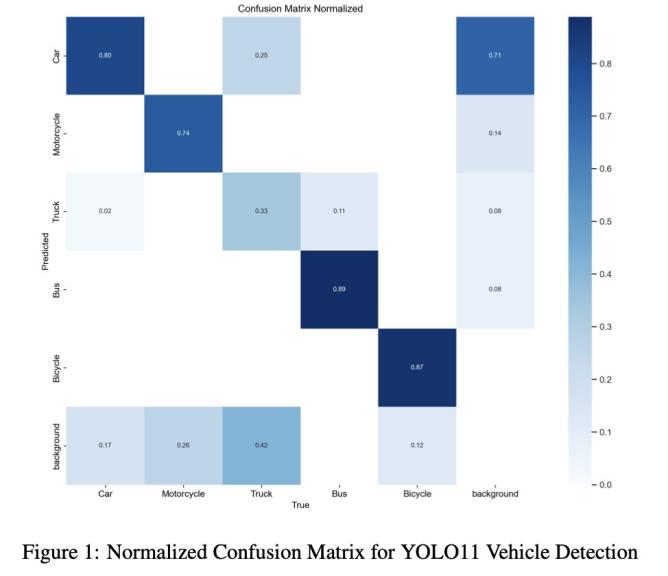
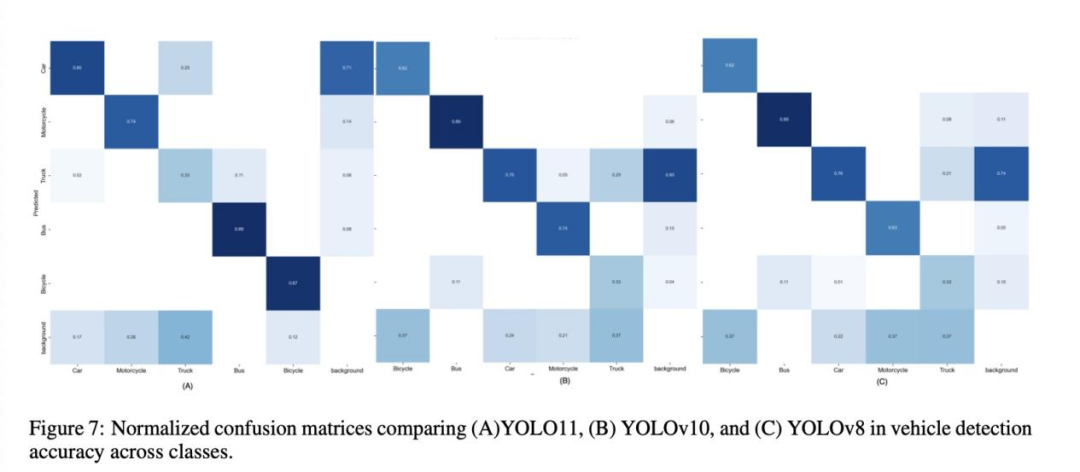
混淆矩阵分析 (图1)
-
汽车: 分类准确性高。
-
摩托车: 表现良好,但与自行车存在少量混淆。
-
卡车和公交车: 存在显著互混淆,可能与视觉相似性有关。
-
自行车: 分类准确性极高,误分类极少。
-
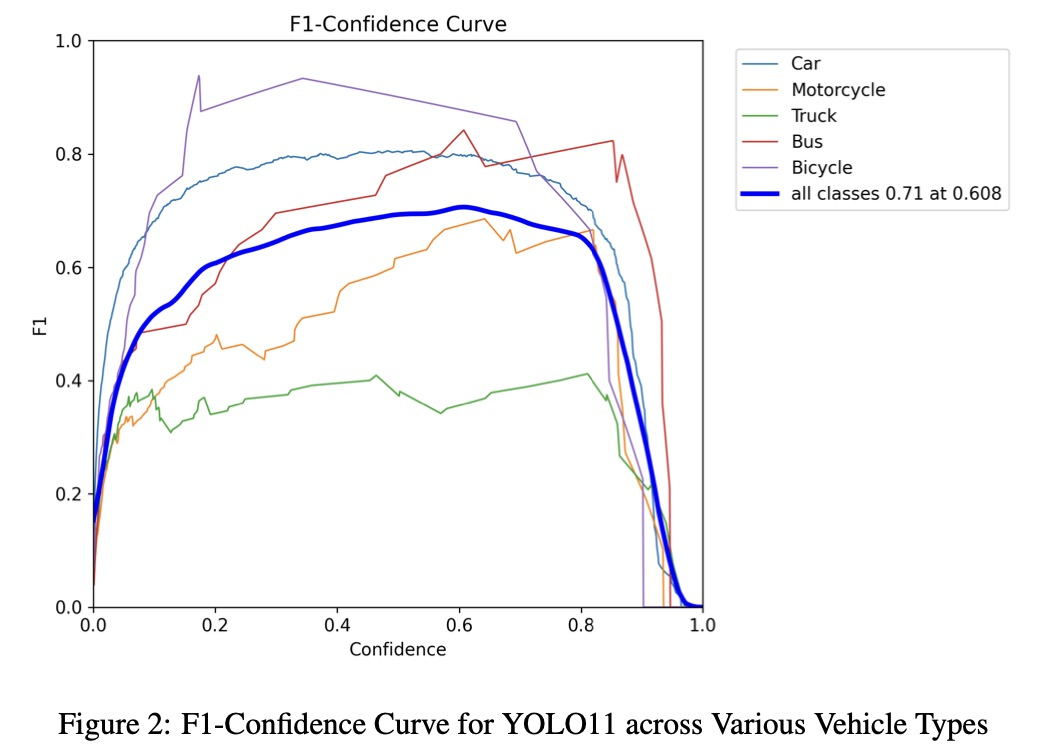
F1-置信度曲线 (图2)
置信度阈值约为 0.61 时达到最佳 F1 分数 0.71,表明此时精度与召回率平衡。
-
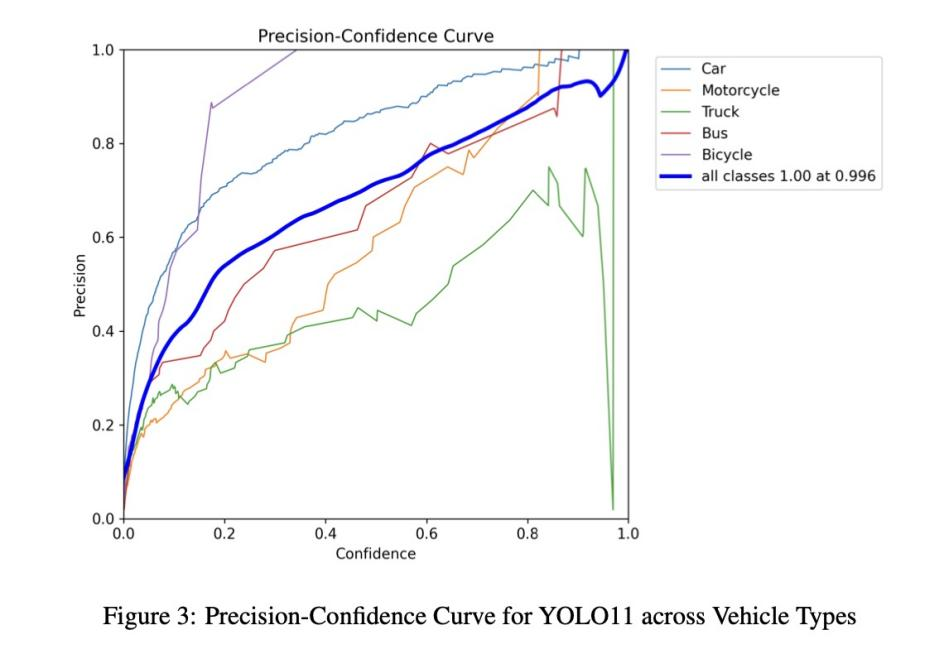
精度-置信度曲线 (图3)
大部分置信度阈值下保持高精度,峰值精度 1.0(置信度阈值 0.996)。
汽车和公交车精度始终高;摩托车和卡车在某些点精度较低。
-
精度-召回率曲线 (图4) & mAP
所有类别的 mAP@0.5 (IoU=0.5时的平均精度) 为 0.743。
各类别性能:
-
汽车:0.837
-
摩托车:0.679
-
卡车:0.355
-
公交车:0.863
-
自行车:0.982
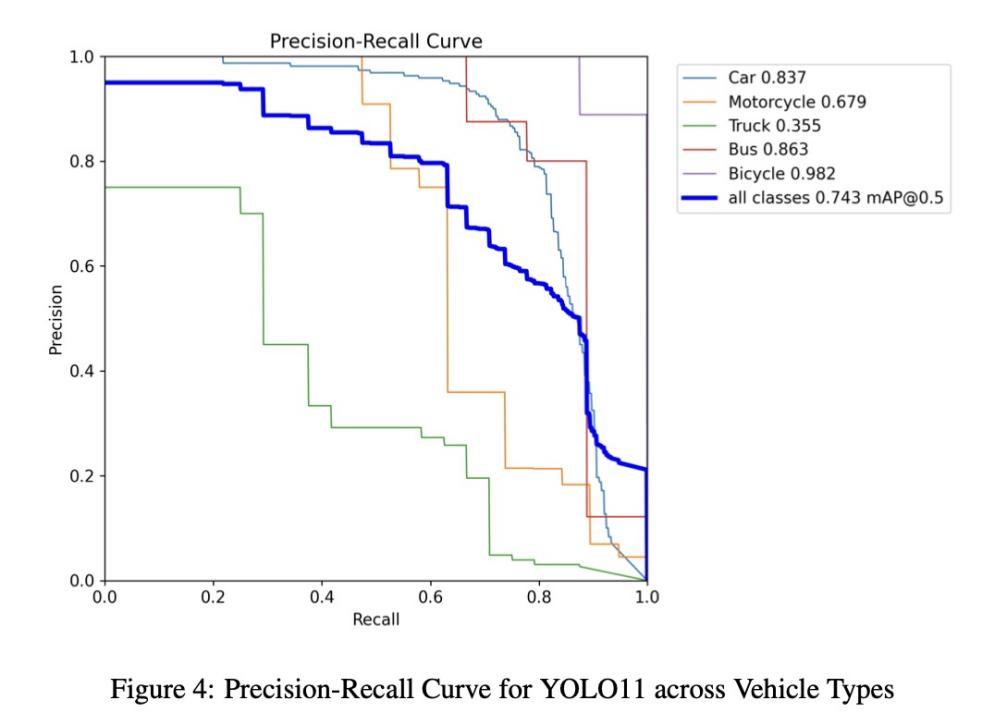
汽车和自行车实现高精度和高召回率;摩托车和卡车在部分阈值下召回率较低。
-
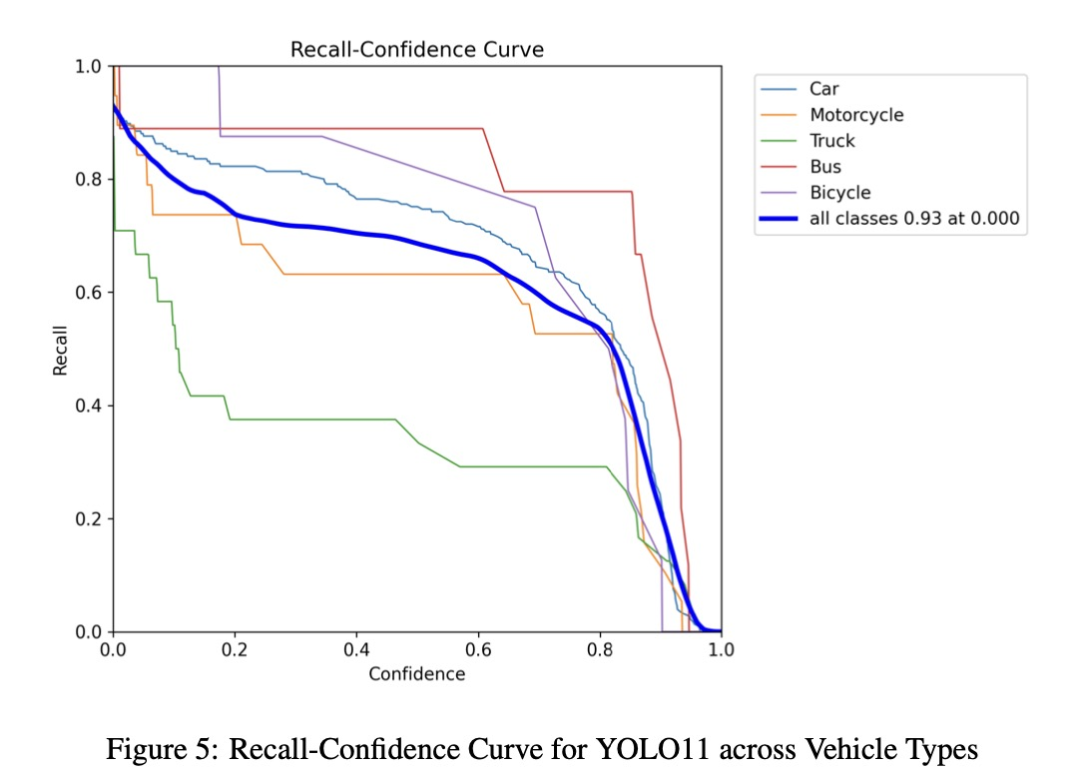
召回率-置信度曲线 (图5)
低置信度阈值下达到峰值召回率 0.93。
置信度阈值增加导致召回率下降,体现精度与召回率间的权衡。
-
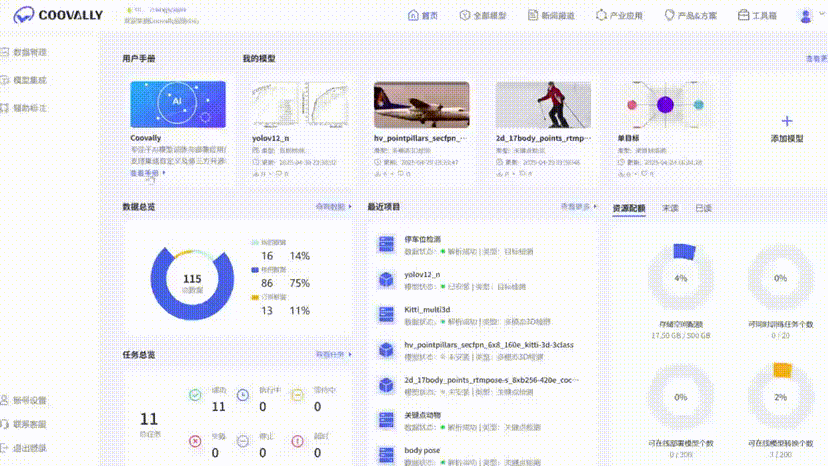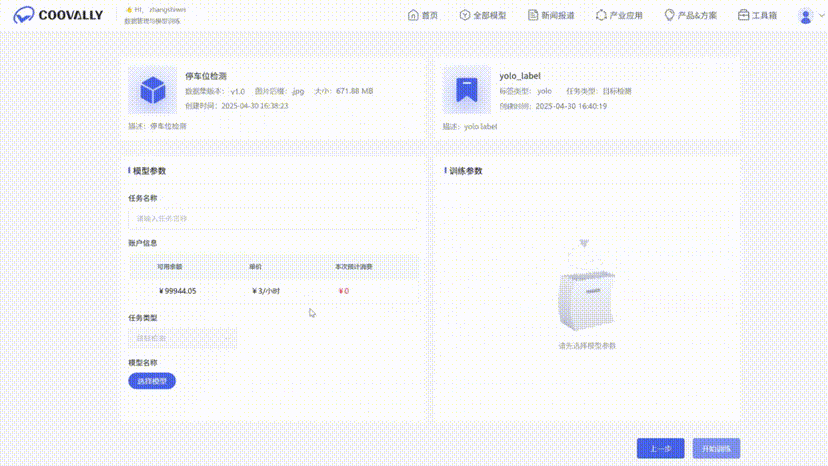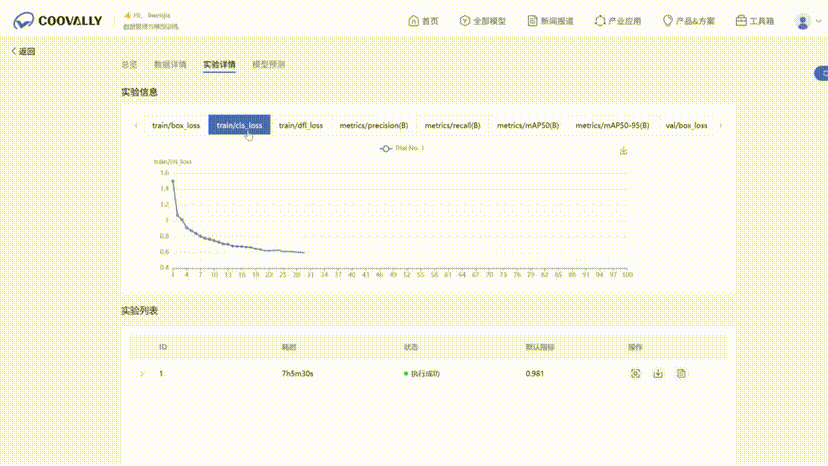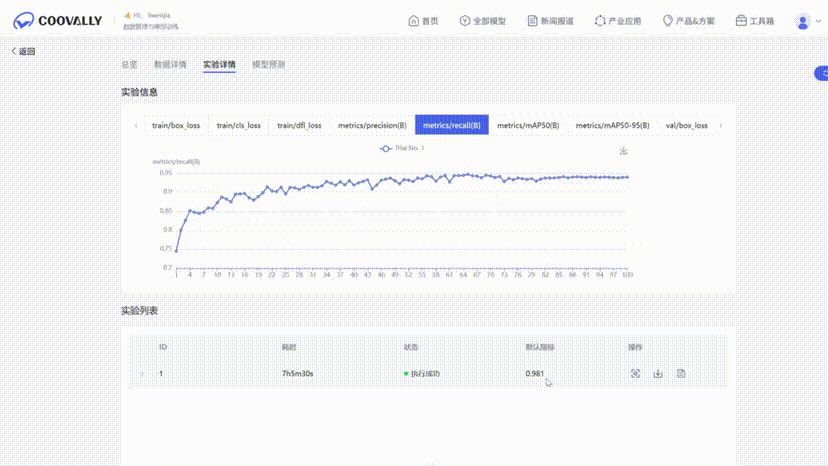
训练与验证损失 (图6)
损失曲线稳步下降,表明模型有效学习且未显著过拟合,其精度、召回率和 mAP 的稳定表现凸显了可靠性。
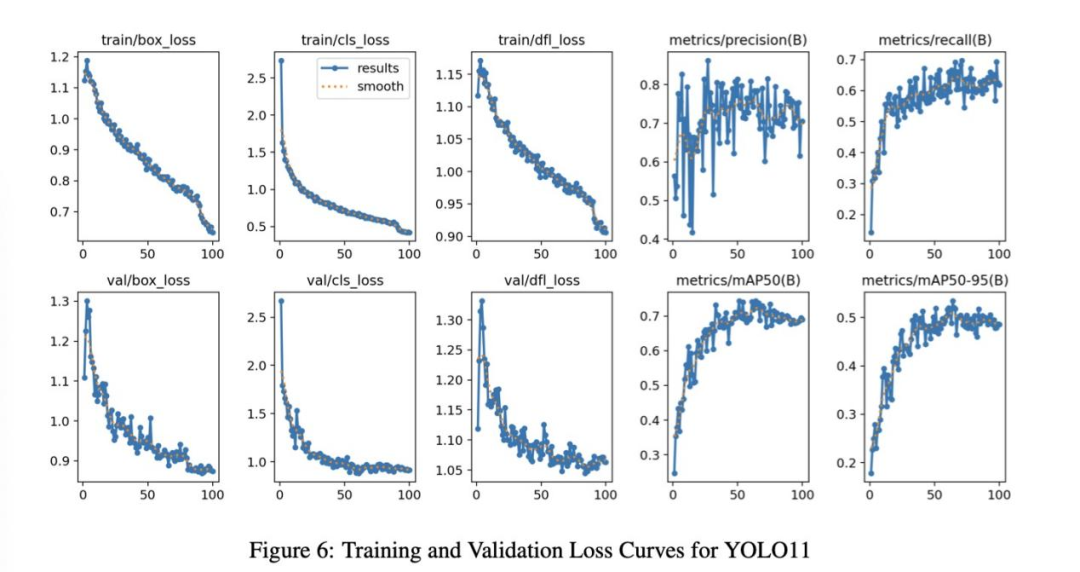
性能总结: YOLO11 在常见车辆(如汽车、公交车)检测上表现出色,精度和召回率高;在卡车和摩托车检测上存在局限,需进一步优化。
-
与 YOLOv8 和 YOLOv10 的比较
YOLO11 在车辆检测任务(涵盖汽车、卡车、公交车、摩托车、自行车)的准确性(精度、召回率)、速度和鲁棒性上,相较于 YOLOv8 和 YOLOv10 展现出显著进步,尤其在精度和召回率指标方面。
-
无需代码,训练结果即时可见!
在Coovally平台上,上传数据集、选择模型、启动训练无需代码操作,训练结果实时可视化,准确率、损失曲线、预测效果一目了然。无需等待,结果即训即看,助你快速验证算法性能!
-
从实验到落地,全程高速零代码!
无论是学术研究还是工业级应用,Coovally均提供云端一体化服务:
-
免环境配置:直接调用预置框架(PyTorch、TensorFlow等);
-
免复杂参数调整:内置自动化训练流程,小白也能轻松上手;
-
高性能算力支持:分布式训练加速,快速产出可用模型;
-
无缝部署:训练完成的模型可直接导出,或通过API接入业务系统。
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
五、讨论
-
优势与不足
-
优势:
-
小型/遮挡物体检测优: 对摩托车、自行车等小型或被遮挡车辆检测准确性提升(得益于新增的 C2PSA (Cross Stage Partial with Spatial Attention) 模块增强空间注意力)。
-
精度-召回率平衡: 各类别(尤其汽车、公交车)均取得高分,表明识别真目标能力强且误检少。
-
高 mAP: 在多个 IoU 阈值下实现更高平均精度,鲁棒性强。
-
实时性高: 推理速度达 290 FPS,计算效率与高准确性结合。
-
环境鲁棒性: 在不同环境条件(光照、物体尺寸)下表现稳定,适应复杂场景(如视觉杂乱、低光)。
-
不足:
-
相似类别混淆: 难以区分视觉相似的卡车和公交车(尤其在遮挡或复杂视角下)。
-
罕见类别表现差: 对卡车等相对罕见类别召回率低。
-
高置信度阈值敏感: 提高置信度阈值时,卡车和摩托车等类别的召回率显著下降。
-
泛化性局限: 在与训练数据差异大的场景(极端天气、独特光照、严重遮挡)中性能可能下降。需领域适应或迁移学习技术提升泛化能力。
-
实际应用意义
YOLO11 的高精度、高效性、实时能力和环境适应性使其在以下领域具有广泛应用潜力:
-
自动驾驶: 提升环境感知能力,支持安全导航和决策(识别多种车辆、处理遮挡/光照变化)。
-
智能交通系统 (ITS): 高效追踪车辆、识别拥堵/事故、区分车辆类型,为自适应信号灯、拥堵控制提供数据。
-
城市监控与安全: 实时处理视频流,追踪目标车辆、检测违规、提升公共安全(适应户外光照/天气变化)。
-
物流与车队管理: 自动化车辆检测追踪(如仓库卡车进出)、优化车辆分类与路线规划。
-
自动收费系统: 快速准确识别车辆类型,实现动态定价,减少拥堵。
结论
YOLO11 在车辆检测中展现出显著的性能提升(精度、召回率、mAP),尤其在检测小型/遮挡物体(摩托车、自行车)方面。其架构优化(如 C2PSA 模块)实现了鲁棒的实时检测(290 FPS)和对复杂环境的适应性,使其在自动驾驶、交通监控等实际应用中极具价值。
-
未来研究方向
-
恶劣条件适应性: 提升在暴雨、雾霾、夜间等低能见度场景下的性能。
-
架构创新: 探索集成Transformer或改进注意力机制以提升处理复杂动态场景的能力。
-
泛化能力扩展: 增强模型对更广泛车辆类型的识别能力。
-
领域适应技术: 应用领域适应技术提升模型在未知环境中的可靠性和灵活性,巩固其在智能交通和实时检测中的核心地位。




















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









