




【导读】
本文系统回顾了YOLO在多模态目标检测领域的最新进展,重点梳理了当前主流研究中如何结合红外、深度图、文本等多源信息,解决单一RGB模态在弱光、遮挡、低对比等复杂环境下的感知瓶颈。文章围绕轻量化多模态融合、动态模态选择机制、开放词汇检测等核心方向,分析了如MM-YOLO、LMS-YOLO、YOLO-World等代表性工作所引入的门控机制、模态对齐策略与跨模态语义引导方法,展现了YOLO从单模态检测器向多模态感知平台的演进路径。>>更多资讯可加入CV技术群获取了解哦
从2016年YOLO横空出世到今天,目标检测早已成为AI落地最广的计算机视觉技术之一。但传统RGB图像检测,尤其在光照不佳、遮挡严重、类间相似等复杂场景中,模型易“看不清、认不准”。于是,多模态融合检测技术快速崛起,YOLO也不再局限于“看图识物”,而是学会了“多感官协同感知”。
本文将结合近年来YOLO家族与多模态目标检测的前沿研究,带你快速了解:
-
YOLO+多模态为何成为趋势?
-
当前主流的多模态融合方法有哪些?
-
多模态检测如何实现轻量部署?
-
开放词汇、语义引导等新范式如何与YOLO结合?
一、RGB-only YOLO,为何渐显疲态?
YOLO虽然已发展到YOLOv8、YOLOv9,检测速度与精度持续优化,但其对输入模态的依赖仍主要局限于RGB图像。而在现实场景中,RGB存在天然“感知盲区”:
-
夜间/低光场景:RGB图像信息严重丢失,红外图像或热成像反而更稳定;
-
雾霾/雨雪/遮挡环境:RGB图像噪声强、轮廓模糊;
-
工业/农业等场景:RGB分辨率有限,无法感知深度、材质、热能等关键特征。
为了解决这些问题,越来越多研究者开始探索多模态感知,即结合RGB + 红外 + 深度图 + 雷达点云 + 文本等多源信息进行更鲁棒的目标检测。
二、YOLO + 多模态,正成为研究热点
近年来,多模态检测逐步成为主流趋势,而YOLO作为工业界最受欢迎的检测骨干,也在这一浪潮中不断进化。下面我们盘点几个关键研究方向及代表性论文。
-
动态模态选择与开放词汇融合
【YOLO-UniOW: 统一开放世界与开放词汇检测】
内容:提出“通用开放世界目标检测”(Uni-OWD)新范式,首次在YOLO架构上统一开放词汇(动态类别扩展)和开放世界(未知物体识别)任务。通过自适应决策学习(AdaDL) 替代传统跨模态融合,在CLIP潜在空间直接对齐图像与文本特征,显著降低计算开销;结合通配符学习策略,无需增量学习即可将未知物体标注为“未知”并支持动态词汇扩展。
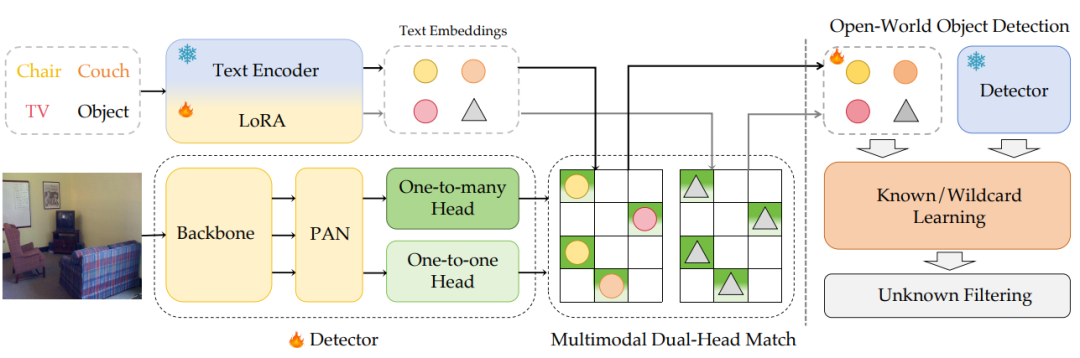
亮点:
-
效率:在LVIS数据集达34.6 AP、69.6 FPS,推理速度较YOLO-World提升31%
-
动态适应:未知类别召回率68.5%,错误归类率仅7.2%
-
开源支持:代码已公开,适用于自动驾驶、安防监控等开放场景
【Mamba-YOLO-World: 开放词汇检测的高效特征融合】
内容:将状态空间模型(Mamba)引入开放词汇检测,设计MambaFusion-PAN颈部网络:
-
线性复杂度融合:通过并行/串行引导选择性扫描算法(PGSS/SGSS),以O(N)复杂度替代传统O(N²)注意力机制
-
多模态中介:利用Mamba隐藏状态传递文本与图像信息,避免特征拼接带来的计算膨胀
-
轻量化:在COCO零样本检测任务中,以更低FLOPs超越YOLO-World
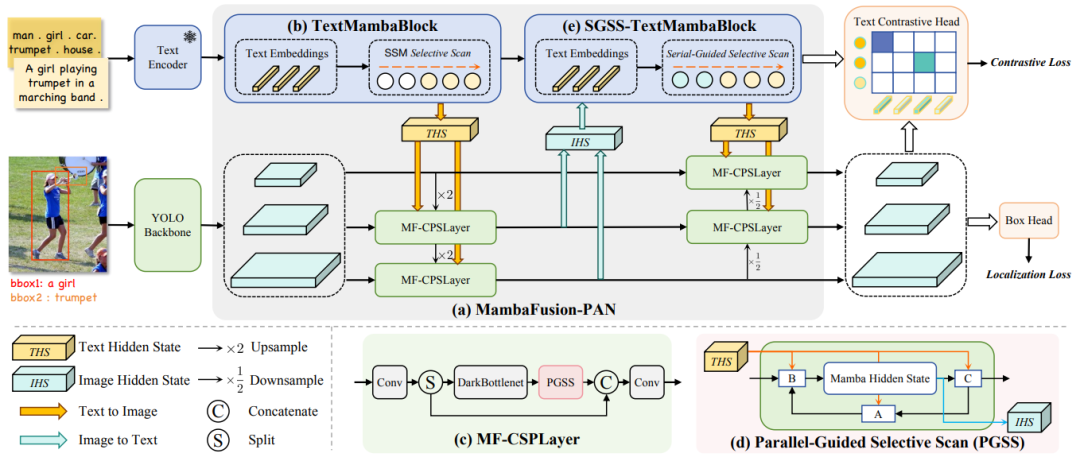
亮点:
-
开放词汇性能:LVIS数据集mAP达35.1%,参数量减少18%
-
工业适配:适合无人机巡检、机器人视觉等需实时扩展类别的场景
-
轻量化多模态部署:边缘计算友好型YOLO
【CDC-YOLOFusion: 跨尺度动态卷积融合可见光-红外目标检测 】
内容:针对可见光-红外双模态特征融合问题,提出跨尺度动态卷积融合(CDCF)模块:
-
动态核生成:通过跨模态核交互损失,自适应学习模态相关卷积核,聚焦共同显著特征与独特特征
-
跨模态数据交换(CDS):交换可见光与红外图像的局部区域,增强模型对模态差异的鲁棒性
-
轻量化设计:嵌入YOLOv5架构,参数量仅0.81M,较基准模型低7.7倍
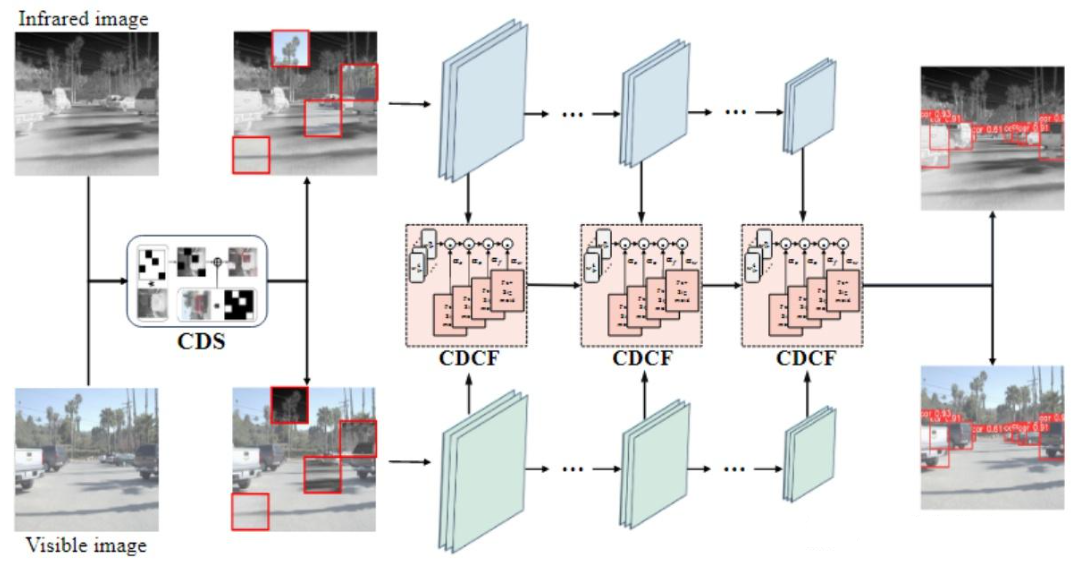
亮点:
-
动态融合:在FLIR、KAIST等数据集上mAP提升4.2%
-
实时性:支持边缘设备部署(Jetson Orin Nano >30 FPS)
-
专利技术:已申请专利,适用于夜间安防、车载夜视系统
【LMSFA-YOLO:基于多尺度特征融合的轻量级遥感图像目标检测网络】
内容:提出轻量多尺度卷积(LMSConv) 与轻量跨阶段部分模块(LMSCSP),优化计算成本并增强多尺度特征提取;结合混合局部通道注意力(MLCA) 构建EMCASPP模块,融合局部与通道空间信息;引入ShapeIoU损失函数替代原IoU,强化边界框形状约束。
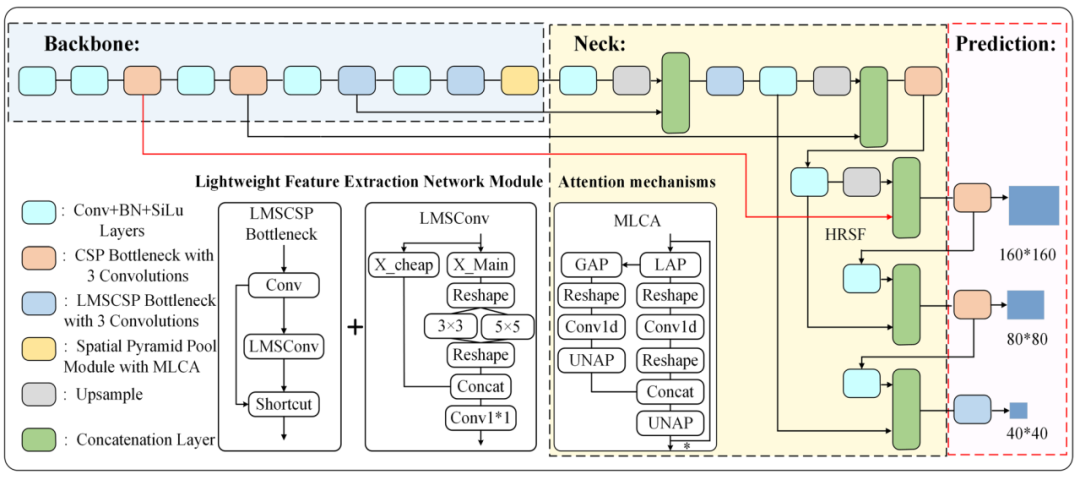
亮点:
-
边缘计算高效性:参数量减少35.8%,VisDrone数据集mAP提升7.0%,Jetson Orin Nano实时推理>30 FPS。
-
多尺度感知:高分辨率浅层特征保留细节,显著提升AI-TOD数据集小目标mAP 7.6%。
-
基础架构优化:为多模态检测奠定底座
【YOLOv13:超图增强的自适应视觉感知网络】
内容:虽为单模态模型,但其轻量化技术对多模态扩展有重要参考价值:
-
HyperACE机制:用超图建模像素间高阶相关性,替代局部成对交互,增强复杂场景感知
-
FullPAD范式:全流程聚合分发多尺度特征,改善梯度传播
-
深度可分离卷积模块:替换大核卷积,YOLOv13-N较YOLOv12参数量降35.8%,mAP提升3%
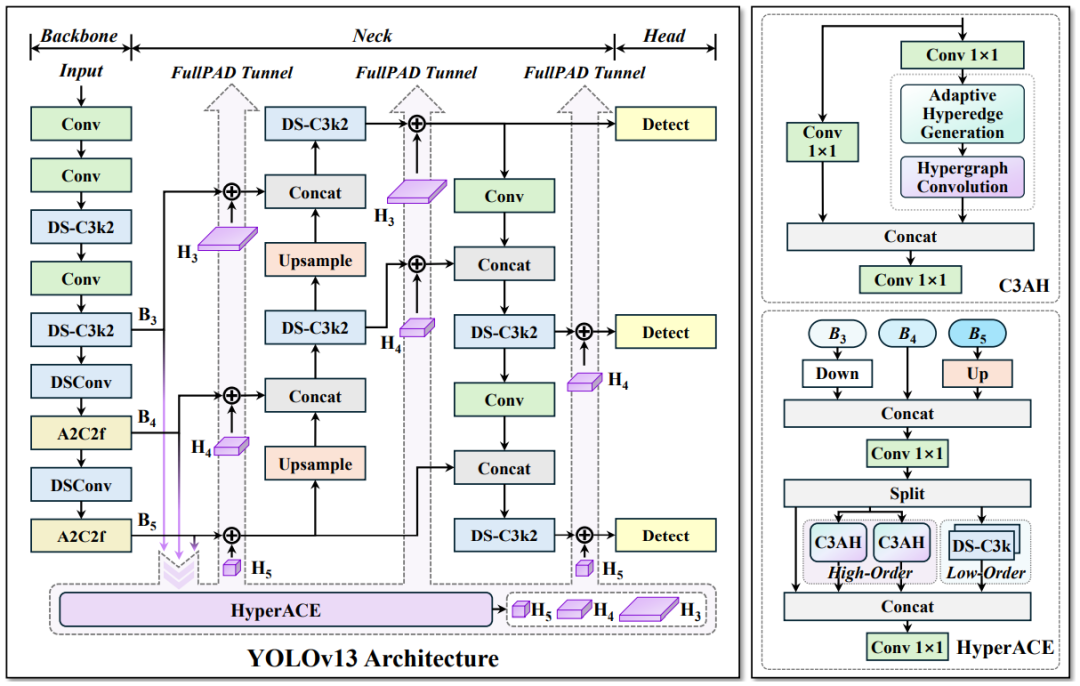
亮点:
-
轻量化创新:在MS COCO上以7.8M参数实现42.1% mAP
-
多模态潜力:超图机制可扩展至多模态高阶关联建模,为动态融合提供新思路
三、未来趋势:YOLO + 多模态,还能怎么进化?
随着大模型、边缘智能与多模态感知的发展,YOLO系列已不再是单一图像检测的工具,而逐步演化为面向多源数据理解的高效视觉平台。展望未来,YOLO + 多模态检测将在以下几个方向继续突破:
-
模态感知更“聪明”:动态融合与选择机制主导主流
尽管现有多模态YOLO方法(如MM-YOLO、CDC-YOLOFusion)已实现图像层面的双流融合,但仍普遍依赖静态策略(如通道拼接或加权求和)。未来的YOLO框架将更注重模态感知与动态决策能力:
-
模态感知路由(Modality-Aware Routing):通过轻量感知子网络,识别场景中不同模态的重要性(如红外在夜间优先),实现输入可变、策略自适应的感知路径;
-
注意力门控 + 任务驱动融合:借助Transformer或状态空间结构(如Mamba)进行信息加权,按检测目标动态调整模态贡献;
-
跨模态对比/蒸馏机制:通过语义层对齐或互相监督,提升“模态协作”的智能程度。
-
从“融合模态”到“理解语义”:开放词汇 + 多模态成趋势
当前YOLO多模态检测多聚焦在视觉模态的物理融合(RGB + 热成像等),而未来趋势将更多向跨模态语义融合靠拢,尤其是结合自然语言模型,推动目标检测从“定类定框”向“理解图文语境”进化:
-
语言引导检测(Language Prompted Detection):如YOLO-World、YOLO-UniOW所展示的,YOLO未来将全面支持文本类目输入、文本区域定位等任务;
-
开放词汇支持(Open-Vocabulary):借助CLIP等预训练语言视觉模型,支持用户自定义检测类别或用“自然语言”定义复杂目标(如“红衣骑车人”、“玻璃内的花瓶”);
-
开放世界适应(Open-World Detection):在实际场景中识别未知目标、打上“未知”标签并记录分布,实现持续学习与知识迁移。
-
多模态YOLO轻量化+部署优化将成为“标配”
即使融合多种模态,YOLO依旧要承担边缘部署与实时处理的责任,这就要求未来模型具备极致轻量化与高能效比:
-
结构设计模块化:如LMS-YOLO所示,将轻量Backbone(GhostNet、ShuffleNet)与多模态融合解耦,便于在资源受限平台灵活剪裁;
-
计算友好型融合策略:避免高维拼接与Transformer堆叠,转向状态空间、线性注意力或低秩表示方式;
-
自适应部署:未来YOLO可能内置“部署感知优化模块”,根据目标平台(如Jetson、RK3588、安卓终端)自动调整模态策略与模型宽度。
-
多模态 + YOLO将成为行业级解决方案的通用范式
未来多模态YOLO不仅是论文里的实验模型,更将成为工程落地与产品部署中的核心技术底座:
-
自动驾驶:结合RGB + 激光雷达 + 摄像头语义信息,实现极端场景下的低延迟、高鲁棒目标感知;
-
安防监控:实现低光夜间环境中的热成像-图像联合检测,结合语义标签进行行为识别;
-
空天遥感与无人机巡检:融合多光谱、深度图、语义地图等多源信息进行精细检测;
-
机器人感知系统:结合视觉+语言,实现动态场景交互,如“检测桌上的蓝色物体并抓取”。
总结
在安防、工业巡检、无人机、自动驾驶、农业监测等关键应用中,复杂环境和设备资源限制成为常态。仅依赖单一RGB模态,YOLO再快、再准,也会“看瞎眼”。而多模态目标检测,正是提升模型认知能力、落地实用性的必经之路。
未来,多模态YOLO也许不再是“一个模型+多个模态”,而是一个更智慧的感知大脑,根据环境灵活组合、主动选择信息源,实现真正意义上的“全场景智能感知”。



















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









