



本文详细介绍了vLLM高性能大语言模型推理框架,重点解析其PagedAttention和连续批处理技术如何解决传统LLM推理的内存与调度瓶颈。文章从环境配置、安装步骤到OpenAI兼容服务器搭建,全面展示了vLLM在提升吞吐量、降低延迟和高并发能力方面的优势,并通过代码示例演示了离线批量推理、API调用等实践应用,为开发者构建高性能LLM服务提供完整指南。
引言
vLLM 是一个以 Python 为主、C++/CUDA 为辅实现的高性能大语言模型(LLM)推理和服务库。
vLLM 的核心优势在于:你可以通过参数,精细控制大模型(LLM)如何运行在 GPU 上,可以“榨干” GPU显卡硬件的每一分性能。vLLM 不是只支持 GPU,但它几乎完全为 GPU 而生。
对于 GPU 用户:vLLM 是一个革命性的工具,能显著提升服务吞吐量和降低显存占用,是构建高性能 LLM 服务的首选引擎之一。
对于 CPU 用户:虽然 vLLM 提供了 CPU 支持,但这更像是一个辅助功能,用于开发和调试。强烈不建议在生产环境或对性能有要求的场景中使用 vLLM 的 CPU 模式。对于 CPU 推理,你应该优先考虑 llama.cpp 或 Ollama。
因此,在选择 vLLM 之前,请务必确认你的主要运行环境是 GPU。如果你的工作流主要围绕 CPU 展开,那么 vLLM 可能并不适合你。
备注:
OpenAI-API-Compatible(OpenAI API 兼容性)不是一个具体的软件或工具,而是一套接口规范和约定。它规定了应用程序应该如何向一个AI服务发送请求,以及该服务应该如何返回响应,其格式与 OpenAI 官方的 API 完全一致。
要理解 vLLM 对 GPU 显卡硬件的支持,首先我们有必要搞清楚以下问题:
1。为什么说 vLLM 是大型语言模型推理领域的革命性突破?
vLLM (Virtual Large Language Model) 之所以被认为是大型语言模型推理领域的革命性突破,核心在于它从根本上解决了传统推理引擎在处理动态、高并发请求时面临的内存管理和调度效率瓶颈。它通过引入PagedAttention 和 连续批处理(Continuous Batching)等创新技术,显著提升了推理的吞吐量、降低了延迟,并大幅提高了高并发处理能力。
2。vLLM 主要解决了哪些大模型推理瓶颈问题?
vLLM的核心贡献在于精准解决了传统LLM推理引擎的几个关键痛点:
(1)KV缓存内存瓶颈与碎片化:
问题: 传统方法预分配连续KV缓存导致:
----内存浪费: 短序列预留了大量未使用的内存。
----内存碎片: 频繁分配/释放不同大小的连续内存块导致外部碎片,可用内存总和足够但无法满足新的大块请求。
----OOM风险: 长序列或高并发时,极易因无法找到足够大的连续内存块而失败(Out-Of-Memory)。
vLLM解决方案: PagedAttention 通过分页和非连续分配,彻底消除外部碎片,实现接近100%的KV缓存内存利用率,并能安全处理远超传统方法限制的序列长度和并发数。
(2)静态批处理的低效与延迟:
问题: 静态批处理中,GPU必须等待批次内最慢的请求完成才能处理下一批。这导致:
----GPU利用率低下: 大量计算周期浪费在等待上。
----高延迟: 新请求加入队列的等待时间(TTFT)和完成时间(E2E Latency)显著增加,尤其在高并发和请求长度差异大时。
vLLM解决方案: 连续批处理 实现了细粒度的、动态的批次管理。GPU在每一步都处理当前活跃的请求,持续保持高计算利用率,新请求能几乎无等待地加入,已完成请求能立即退出,大幅降低平均和尾延迟。
(3)无法高效共享KV缓存:
问题: 在多用户、多对话场景中,大量请求可能包含相同的前缀(如系统指令、对话历史)。传统方法无法有效共享这部分KV缓存,导致重复计算和内存冗余。
vLLM解决方案: PagedAttention 的块结构天然支持跨请求共享相同的物理内存块。这显著减少了重复计算(虽然共享主要节省内存,但避免了重新计算共享部分的开销)和内存占用,是支持超高并发的关键因素之一。
(4)长序列/超长提示词处理困难:
问题: 传统方法处理超长提示词(如长文档摘要、代码库分析)时,预分配的巨大连续KV缓存极易导致OOM,即使总内存足够。长Prefill阶段也会长时间阻塞GPU。
vLLM解决方案: PagedAttention 按需分配块,无需预分配最大长度,安全处理超长序列。分块调度 将长Prefill分解,避免阻塞,让短请求也能及时响应。
(5)高并发下的资源竞争与不公平性:
问题: 在高并发下,传统方法容易出现:
----资源饥饿: 短请求被长请求或长Prefill阻塞,响应时间不可预测。
----吞吐量骤降: 内存碎片和静态批处理导致系统无法有效利用资源处理更多请求。
vLLM解决方案: 连续批处理 + 分块调度 提供了更公平的调度机制,优先处理接近完成的请求,防止长任务垄断资源。PagedAttention 的高效内存管理消除了高并发下的主要资源瓶颈(内存),使系统能稳定支持极高并发。
3。vLLM 是如何彻底改变硬件GPU性能指标的?
(1)显著提升吞吐量 (Throughput):
原因: 更高效的内存利用率和更智能的调度策略。
机制:
----PagedAttention (分页注意力): 将KV缓存(Key-Value Cache,存储模型中间状态)分割成固定大小的“块”(Blocks),非连续存储在内存中(类似操作系统虚拟内存的分页)。这极大地减少了内存碎片,允许在有限GPU内存中容纳更多并发请求的KV缓存。
----连续批处理 (Continuous Batching / Iterative Batching): 摒弃传统静态批处理(一批请求必须全部处理完才能开始下一批)。vLLM在推理的每一步(解码一个token)后,动态地将新请求加入批次,并将已完成(或因长度限制暂停)的请求移出批次。这确保了GPU计算资源始终处于高利用率状态,避免了因等待“慢”请求而导致的GPU空闲。
----分块调度 (Chunked Prefill): 将长提示词(Prompt)的预处理(Prefill)阶段也分割成小块,与解码阶段交织调度。这避免了单个超长提示词长时间独占GPU,让系统更公平、更高效地处理混合长短的请求。
效果: 在相同硬件上,vLLM的吞吐量(处理token数/秒)通常能达到传统方法的2倍到4倍甚至更高,尤其是在处理大量并发、长短不一的请求时优势更明显。
(2)有效降低延迟 (Latency):
原因: 减少排队等待时间,更公平地调度资源。
机制:
----连续批处理: 新请求无需等待整个批次完成,可以在下一轮迭代立即加入处理队列,显著减少了首token延迟(Time To First Token, TTFT)和后续token生成延迟(Time Per Output Token, TPOT)。
----分块调度: 防止超长提示词阻塞整个系统,使得短请求也能快速得到响应。
----高效的内存管理: 减少因内存不足或碎片化导致的请求排队或失败。
效果: 在高并发场景下,vLLM能显著降低用户请求的平均延迟和P99延迟(99%的请求延迟),提供更流畅的交互体验。
(3)大幅提高高并发能力 (High Concurrency):
原因: 内存效率的飞跃和动态调度的灵活性。
机制:
----PagedAttention: 通过消除内存碎片和实现KV缓存共享(见下文),使得在有限GPU内存中能同时处理的请求数量大幅增加。
----连续批处理: 系统可以动态地管理活跃请求池,根据资源情况(主要是剩余内存块)和请求状态(Prefill/Decoding)灵活调整并发度,最大化资源利用率。
----KV缓存共享: PagedAttention天然支持跨请求共享相同的KV缓存块(例如,多个用户使用相同的系统提示词)。这极大地节省了内存,使得在相同内存下能支持更多并发用户。
效果: vLLM能在同一块GPU上同时处理数十倍甚至上百倍于传统方法的并发请求数量,尤其适合部署在线服务。
在介绍vLLM安装之前,我们先了解一个非常快的 Python 环境管理器 uv,借助 uv 我们可以快速安装 vLLM。
1.UV
1.1.UV 简介
一个极其快速的 Python 包和项目管理器,用 Rust 编写。uv 开源项目在GitHub上目前已高达65.3k Star数。

1.2.UV 安装
在macOS 或者 Linux 环境下,安装UV:
curl -LsSf https://astral.ac.cn/uv/install.sh | sh
curl -LsSf 是一个常见的命令组合,用于从网络获取资源。
以下是各参数的含义:
-L 或 --location:跟随重定向。如果服务器返回重定向响应,curl 会自动请求新地址。
-s 或 --silent:静默模式。不显示进度条和错误信息,使输出更简洁。
-S 或 --show-error:与 -s 一起使用时,在发生错误时显示错误信息。
-f 或 --fail:在服务器错误(如 404、500)时,curl 返回非零退出码,而非显示错误页面。
在安装 uv之后,可以运行 uv 命令来检查 uv 是否可用,如下图所示:
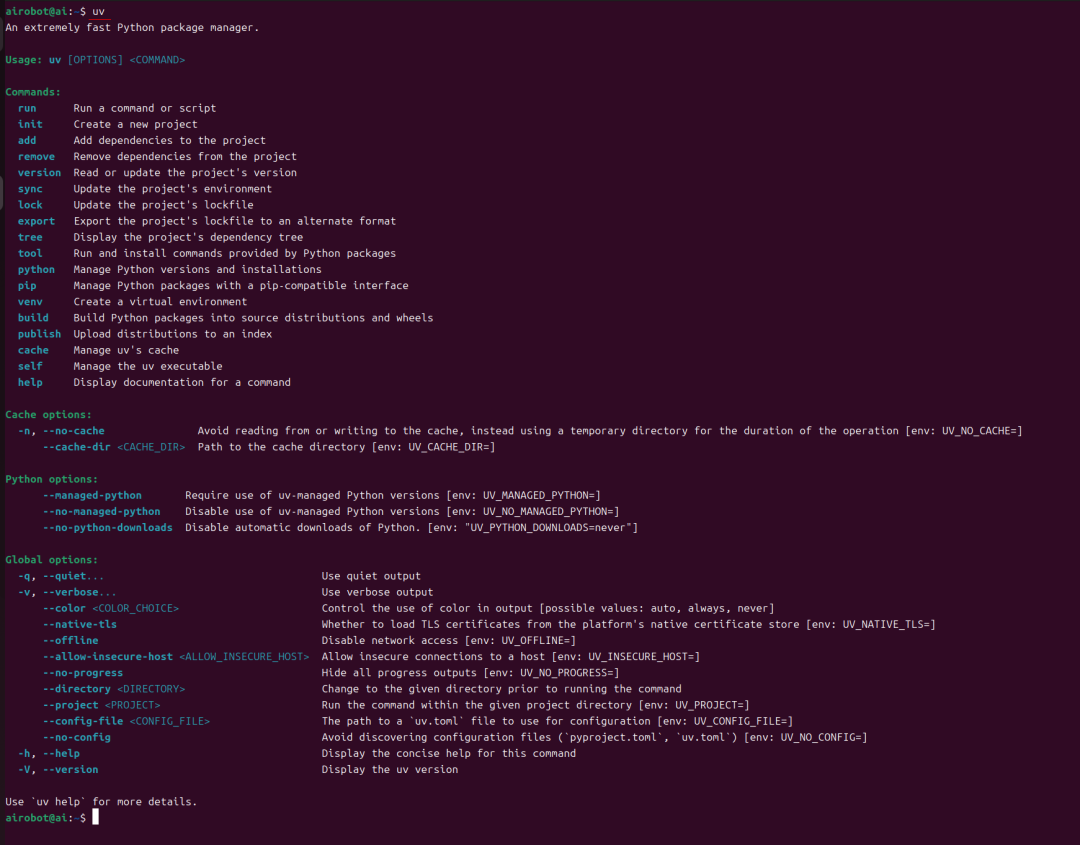
1.3.UV 功能
uv 为 Python 开发提供基本功能,从安装 Python 和编写简单脚本到处理支持多个 Python 版本和平台的大型项目。
uv 的界面可以分为多个部分,这些部分可以独立使用或一起使用。




uv 为常见的 pip、pip-tools 和 virtualenv 命令提供了即插即用的替代方案。
uv 通过高级功能扩展了它们的接口,例如依赖项版本覆盖、平台无关的解析、可重现的解析、替代解析策略等等。
无需更改现有工作流程即可迁移到 uv,并通过 uv pip 接口体验 10-100 倍的加速。




具体相关内容介绍,感兴趣的小伙伴可参考文章末尾处的uv官方中文文档。
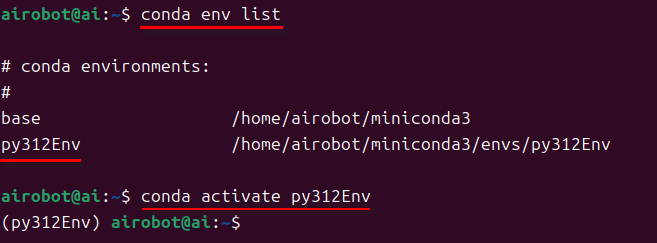
2.安装 conda 环境
已安装conda的小伙伴,若对下面的conda安装不感兴趣,则可以直接忽略本章节内容。
未安装 conda 环境的小伙伴,可以参考conda 环境安装步骤如下:
步骤 1: 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
步骤 2: 运行安装脚本
chmod 755 Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
在安装过程中,你会看到一些许可协议和提示信息。按 Enter 键滚动阅读许可协议,然后输入 yes 接受许可协议。接下来,你可以选择安装路径,默认路径通常是 /home/用户/miniconda3(也就是 ~/miniconda3),如果你不需要更改路径可以直接按 Enter 键继续。
步骤 3: 初始化 Conda
安装完成 miniconda3 后,执行初始化 Conda命令行如下:
~/miniconda3/bin/conda init bash
source ~/.bashrc
步骤 4: 创建一个新的 Conda 环境并安装 Python 3.12
conda create -n py312Env python=3.12
步骤 5: 激活新环境
激活刚刚创建的环境:
conda activate py312Env
步骤 6:验证安装
最后,验证 Conda 版本:
conda -V
验证 Python 版本是否正确安装:
python --version
步骤 7:退出conda环境
conda deactivate
具体如下图所示:
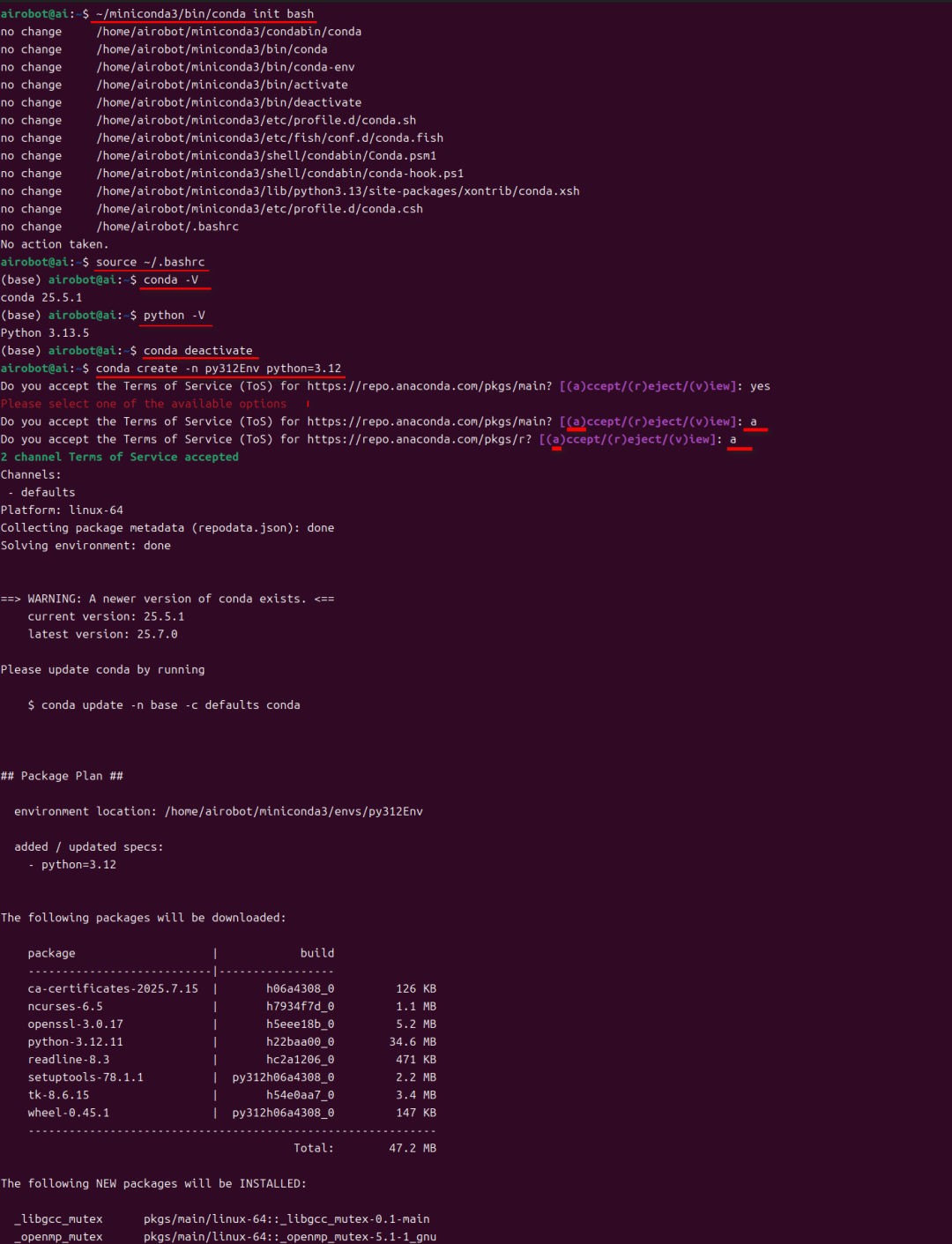
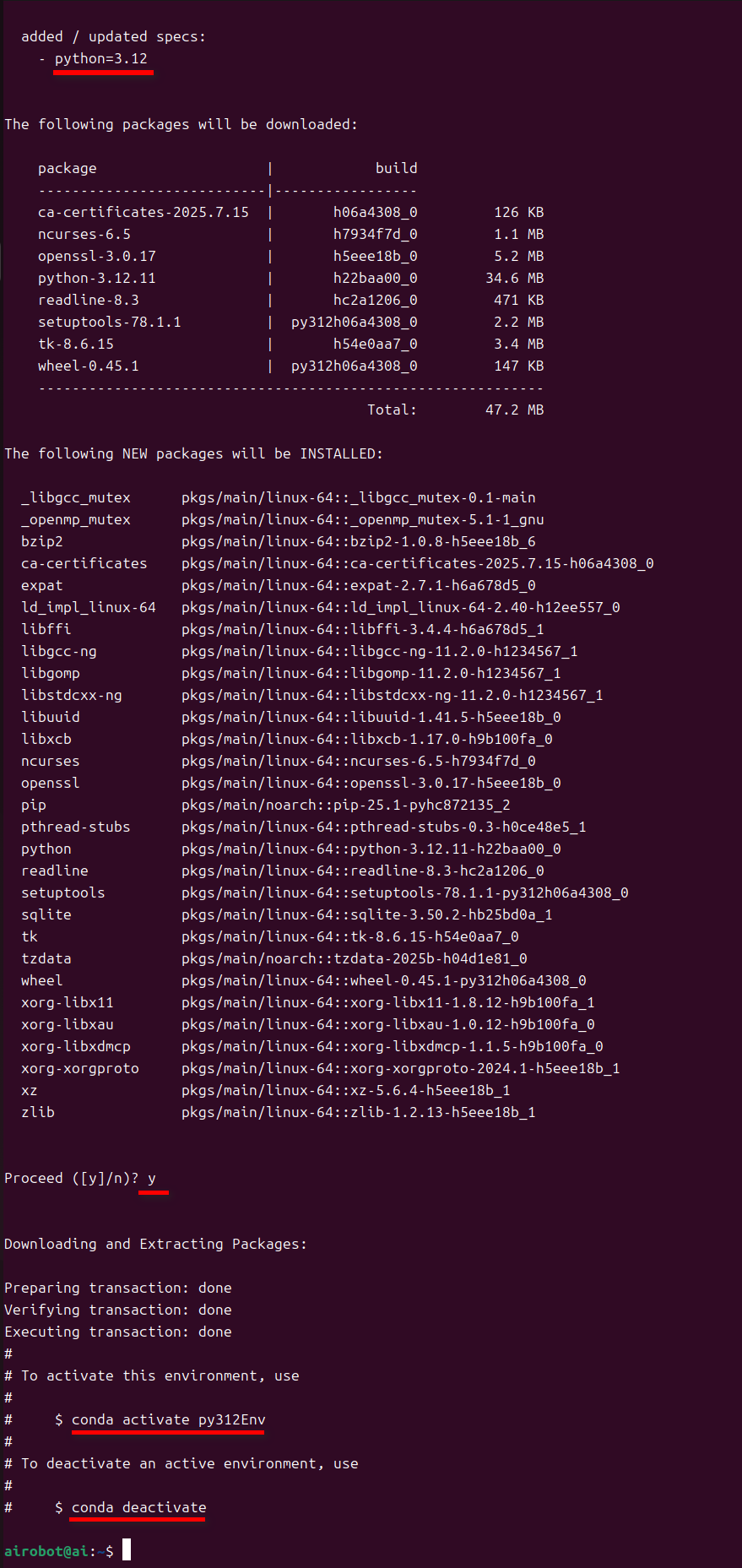
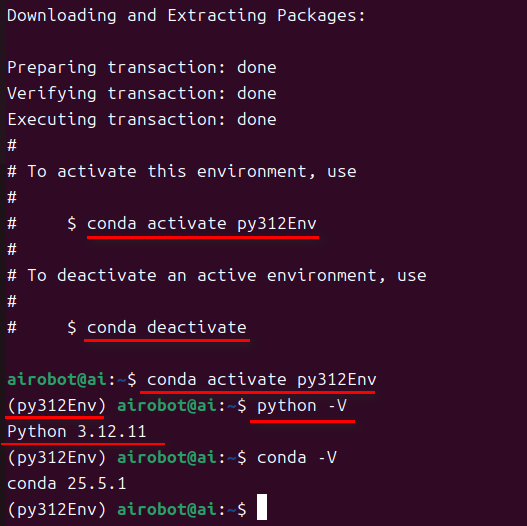
3.检查 NVIDIA GPU 显卡和驱动
3.1.检查操作系统类型和 NVIDIA 显卡
查看操作系统类型,执行以下命令:
uname -m
可输出 x86_64(64位)或 aarch64(ARM64)
查看系统是否可以识别到 NVIDIA 显卡,执行以下命令:
lspci | grep -i nvidia
若有显卡,则可查看到显卡型号如 NVIDIA Corporation AD102 [GeForce RTX 4090]
3.2.检查显卡驱动
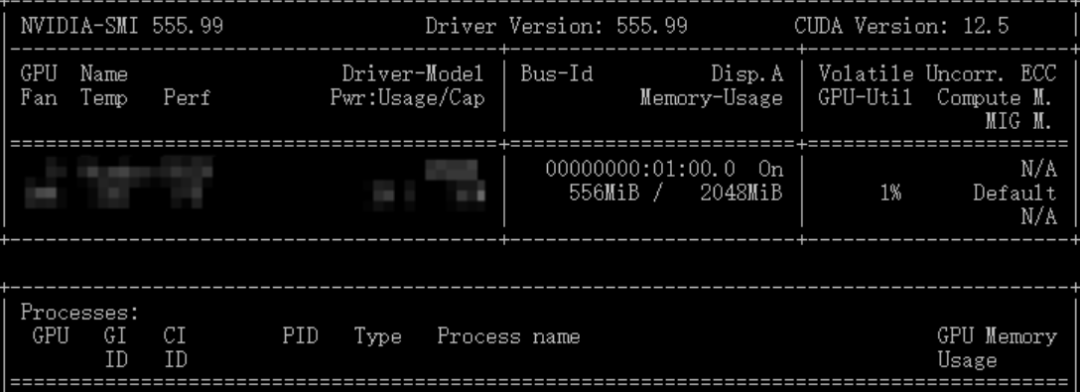
若已装了驱动,则显卡驱动查询方法为输入如下命令:
nvidia-smi
输出右上角显示 如 CUDA Version: 12.5,即最高支持的 CUDA 版本,如下图所示:
备注:
CUDA(Compute Unified Device Architecture)是 NVIDIA(英伟达)推出的并行计算平台和编程模型,本质是一套软硬件结合的技术体系,旨在让开发者能够利用 NVIDIA GPU(显卡)的强大算力执行通用计算任务(而不仅是图形渲染)。它与显卡的关系可以概括为:CUDA 是 GPU 的“大脑指挥系统”,让显卡从“图形处理器”升级为“通用超级计算器”。
3.3.检查CUDA版本与显卡驱动兼容性
访问NVIDIA官方文档,进入 CUDA Toolkit Release Notes 网址:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-driver,查找目标CUDA版本对应的驱动版本要求,如下图所示:
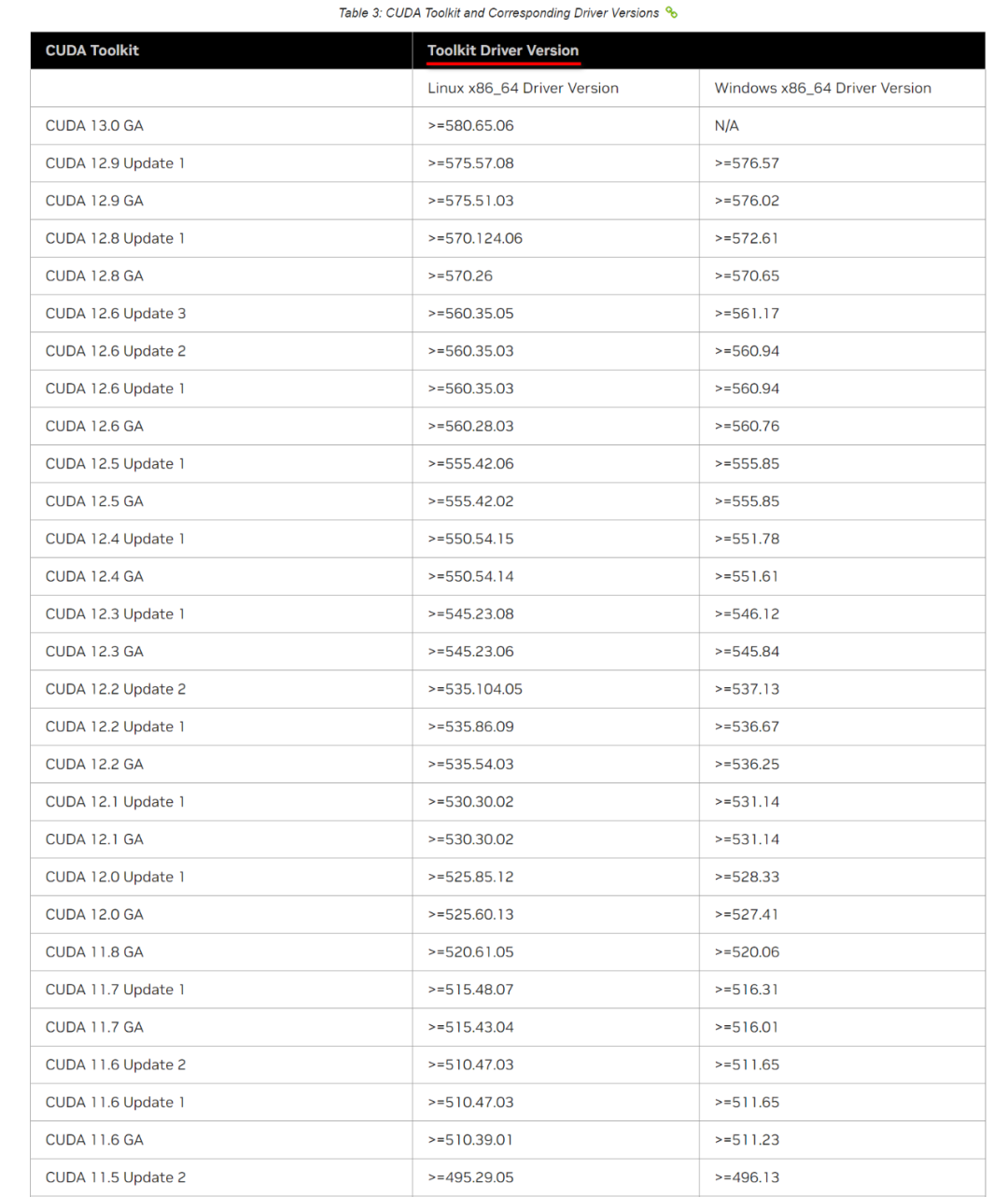
GPU显卡算力与CUDA版本的关系,主要体现在显卡的Compute Capability(算力)决定了支持的CUDA版本。
注意:CUDA 驱动,是向下兼容的,其决定了可安装的 CUDA Toolkit 的最高版本。
3.4.安装/升级显卡驱动
- 方法1:官方包(推荐)
sudo apt update
sudo apt install nvidia-driver-xxx
sudo reboot
备注:
将上面的xxx替换为你需要安装的驱动版本号(如 535、545)
- 方法2:手动安装.run文件(从NVIDIA驱动下载官网)
chmod +x NVIDIA-Linux-x86_64-535.113.01.run
sudo ./NVIDIA-Linux-x86_64-535.113.01.run
前往NVIDIA驱动下载的官方网址https://www.nvidia.com/en-us/drivers/,输入显卡型号和操作系统类型,选择 >= 目标CUDA版本要求的驱动版本。
至此,确保你的机器有 NVIDIA GPU,并且安装了与 CUDA 版本兼容的驱动。
4.vLLM
4.1.vLLM 简介
vLLM 是一个用于 LLM 推理和服务的快速易用库。它提供了一种用于大语言模型(LLM)推理的框架,旨在提高模型的吞吐量和降低延迟。vLLM通过优化内存管理和调度策略,显著提升了模型在高并发场景下的性能。vLLM 开源项目在GitHub上目前已高达55.8k Star数。
vLLM 最初由加州大学伯克利分校的天空计算实验室开发,现已发展成为一个由学术界和工业界共同贡献的社区驱动项目。

4.2.构建并安装 vLLM GPU 后端
4.2.1.vLLM 安装要求
操作系统:Linux
Python:3.9 ~ 3.12
GPU:计算能力 7.0 或更高(例如 V100、T4、RTX20xx、A100、L4、H100 等)
4.2.3.vLLM 安装
4.2.3.1.vLLM 安装方法1:
如果你正在使用 NVIDIA GPU,可以直接使用 pip 安装 vLLM。
建议使用 uv(一个非常快的 Python 环境管理器)来创建和管理 Python 环境。见上面章节 1.2.UV 安装。安装 uv 后,您可以使用以下命令创建新的 Python 环境并安装 vLLM:
uv venv --python 3.12 --seed
source .venv/bin/activate
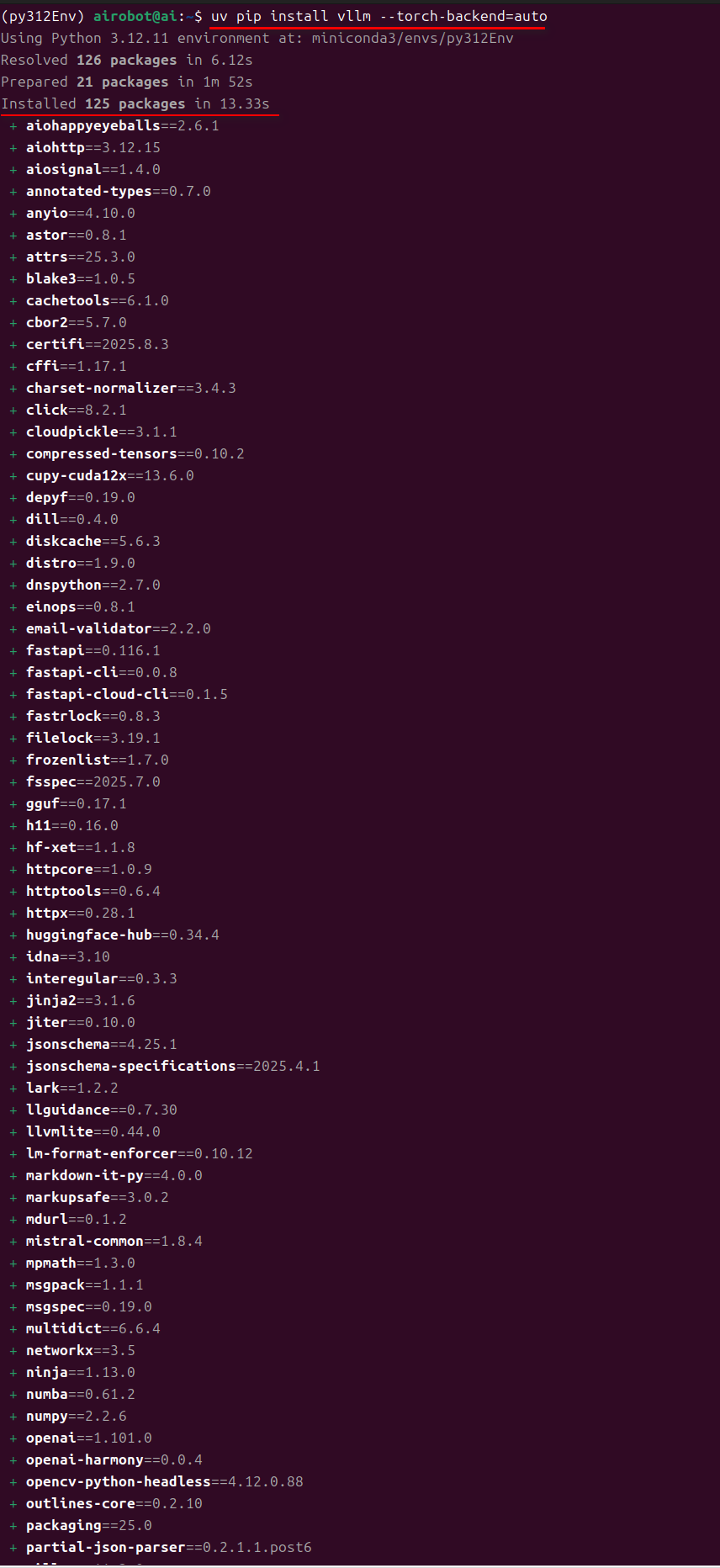
uv pip install vllm --torch-backend=auto
uv 可以通过 --torch-backend=auto(或 UV_TORCH_BACKEND=auto)在运行时检查已安装的 CUDA 驱动版本,从而自动选择合适的 PyTorch 后端。要选择特定的后端(例如 cu126),请设置 --torch-backend=cu126(或 UV_TORCH_BACKEND=cu126)。
4.2.3.2.vLLM 安装方法2:
另一种方法是使用 uv run 配合 --with [dependency] 选项,这允许您运行诸如 vllm serve 这样的命令而无需创建任何永久环境。
这种方法不推荐,最好是新建独立的虚拟Python环境,避免vLLM在安装过程中与当前已存在的Python环境出现安装包版本依赖冲突问题。
uv run --with vllm vllm --help
4.2.3.2.vLLM 安装方法3:(推荐)
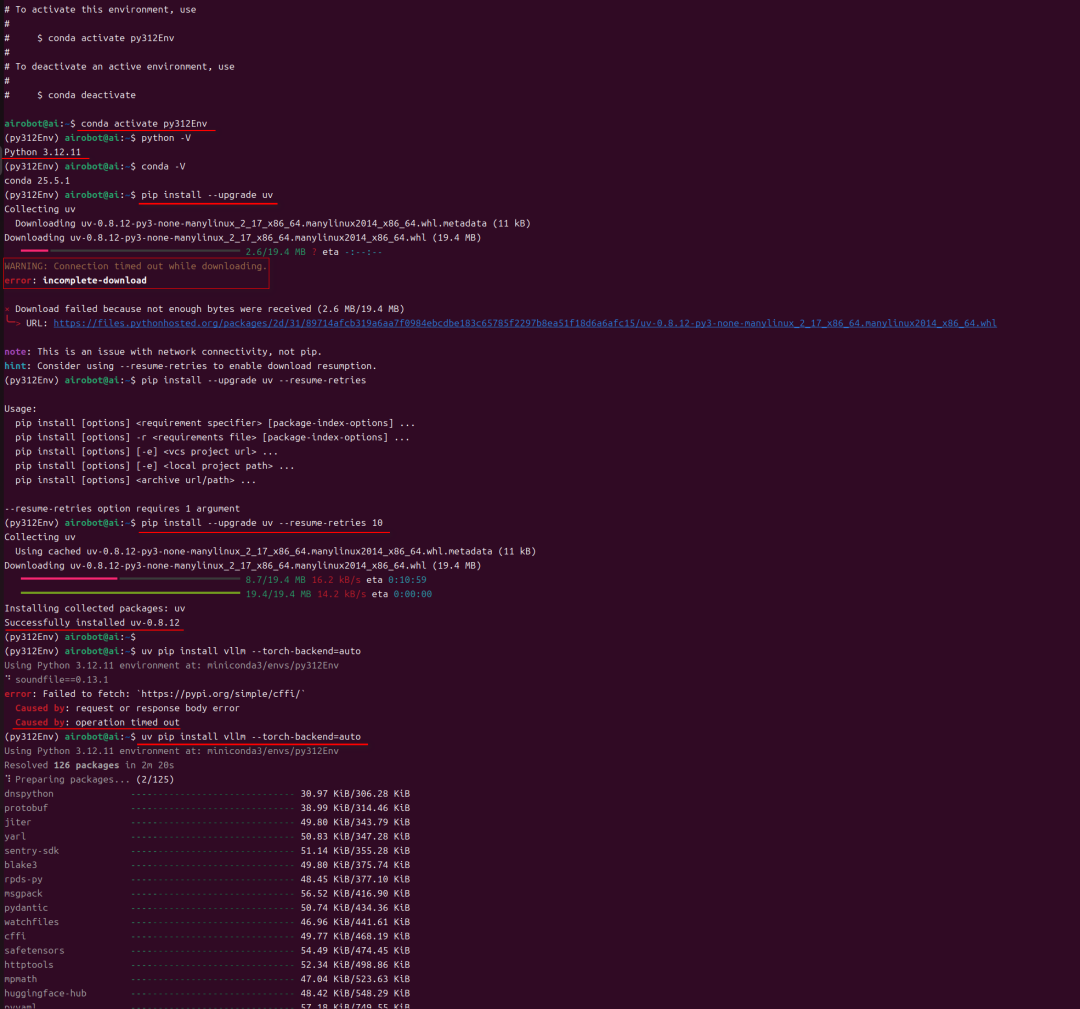
第三种方法,也可以使用 conda 来创建和管理 Python 环境。如果希望在 conda 环境中管理 uv,可以通过 pip 将其安装到 conda 环境中。
conda create -n py312Env python=3.12 -y
conda activate py312Env
pip install --upgrade uv
uv pip install vllm --torch-backend=auto
如果上述命令执行失败(比如,因为网络超时,或者由于安装包解析加载异常而导致下载过程中提示缺少依赖包),则多尝试执行几次就好了。
具体如下图所示:
5.vLLM CLI
vLLM CLI 是vLLM框架提供的命令行接口(Command Line Interface),用于通过终端命令直接与模型进行交互。它允许用户快速测试模型功能、输入提示(prompt)并获取模型的响应,适合用于快速验证和调试。
vLLM安装成功后,vllm-cli会随着vLLM的安装一起被部署到你的Python环境中。
常用的 vLLM CLI 终端命令如下:
- 查看vllm命令行帮助
vllm --help
其中,可用的命令包括:
vllm {chat,complete,serve,bench,collect-env,run-batch}
- 启动一个与OpenAI API兼容的服务器,并在启动时指定一个模型和端口,该服务器基于vLLM框架运行:
vllm serve meta-llama/Llama-2-7b-hf --port 8100
在你的vLLM服务器已经运行起来后,我们就可以像调用 OpenAI API 一样与大模型进行交互了。
备注:
对于 NVIDIA GPU 显卡,直接安装 pip install vllm,默认使用CUDA 后端。
执行 vllm serve 命令,指定vLLM后端的两种方式:
方式1:执行 vllm serve 命令启动服务前,设置如下:
export VLLM_BACKEND=cuda
方式2:执行 vllm serve 命令时,带上参数如下:
–backend cuda
备注:
vLLM 后端的定位:是完整的推理引擎,是端到端的推理服务系统(属于应用层/框架层)。
vLLM 后端,是 LLM 推理的“超级加速器”,通过 PagedAttention 和连续批处理,让大模型在有限硬件上实现高吞吐、低延迟的工业级服务。
- 通过运行的API服务器,生成聊天补全:
(1)直接无参数连接本地 API:
vllm chat
(2)指定 API 访问地址url:
vllm chat --url http://{vllm-serve-host}:{vllm-serve-port}/v1
(3)使用一个简单提示词快速聊天:
vllm chat --quick “hi”
- 通过运行的API服务器,根据给定的提示生成文本补全:
(1)直接无参数连接本地 API:
vllm complete
(2)指定 API 访问地址url:
vllm complete --url http://{vllm-serve-host}:{vllm-serve-port}/v1
(3)使用一个简单提示词快速文本补全:
vllm complete --quick “The future of AI is”
文本补全的功能,是通过一个正在运行的API(应用程序接口)服务器来实现的。API服务器提供了一种通过网络请求和响应来访问服务的方式,使得客户端可以发送请求并获取相应的文本补全结果。
6.vLLM 离线批量推理
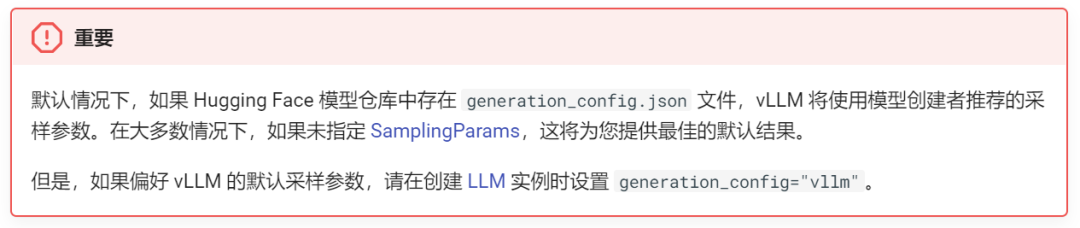
安装 vLLM 后,你就可以开始为一系列输入提示生成文本(即离线批量推理)。可参阅示例如下:
from vllm import LLM, SamplingParams
Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
# Create an LLM.
llm = LLM(model="mistralai/Mistral-7B-Instruct-v0.2")
# Generate texts from the prompts.
# The output is a list of RequestOutput objects
that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling\_params)
# Print the outputs.
print("\nGenerated Outputs:\n" + "-" \* 60)
for output in outputs:
prompt = output.prompt
generated\_text = output.outputs[0].text
print(f"Prompt: {prompt!r}")
print(f"Output: {generated\_text!r}")
print("-" \* 60)
if __name__ == “__main__”:
main()
代码解释:
此示例的第一行导入了类 LLM 和 SamplingParams。
from vllm import LLM, SamplingParams
-
LLM 是使用 vLLM 引擎运行离线推理的主要类。
-
SamplingParams 指定了采样过程的参数。
在下一段代码中,定义了一系列输入提示词prompts和用于文本生成的采样参数。采样温度设置为 0.8,核采样概率设置为 0.95。
prompts = [
“Hello, my name is”,
“The president of the United States is”,
“The capital of France is”,
“The future of AI is”,
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
接着,LLM 类初始化了 vLLM 的引擎和 Mistral-7B 模型用于离线推理。
llm = LLM(model=“mistralai/Mistral-7B-Instruct-v0.2”)
关于 vLLM 支持的模型列表,可以在下面vLLM官方网址查阅:
https://docs.vllm.com.cn/en/latest/models/supported_models.html
vLLM 离线推理可以使用 vLLM 的 LLM 类,在你自己的代码中实现。
现在,有趣的部分来了!
输出,通过 llm.generate 生成。它将输入提示添加到 vLLM 引擎的等待队列中,并执行 vLLM 引擎以高吞吐量生成输出。
输出,以 RequestOutput 对象的列表形式返回,其中包括所有输出标记。
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
备注:
ModelScope(魔搭)是由阿里巴巴公司研发的开源模型社区与平台,旨在为开发者和研究者提供丰富的预训练人工智能模型、工具及资源,支持快速部署和开发AI应用。文章末尾处已附上 ModelScope 魔搭的官方网址,感兴趣的小伙伴可以自行前往。
1。核心功能:
开源模型库:提供多种领域的预训练模型,包括自然语言处理(NLP)、计算机视觉(CV)、语音识别、多模态等,涵盖达摩院自研及第三方开源模型。
模型体验与部署:支持在线体验模型效果,并提供推理API、微调工具和本地/云端部署方案。
统一框架:通过Python库(modelscope)简化模型调用,兼容PyTorch、TensorFlow等主流框架。
2。主要优势:
低代码使用:只需几行代码即可调用复杂模型,降低开发门槛。
行业适配:覆盖电商、金融、医疗等场景的专用模型,满足不同行业需求。
中文友好:包含大量针对中文优化的模型,如文言文理解、中文对话模型等。
3。适用场景:
快速原型开发:直接调用现成模型验证想法。
学术研究:复用预训练模型或发布新模型。
企业应用:定制微调行业模型,如客服机器人、质检系统等。
ModelScope 降低了AI模型的应用门槛,特别适合中文场景或需要快速落地的开发者。用户可自由下载模型权重,部分商用需注意许可证限制。
7.vLLM 兼容 OpenAI 的服务器
vLLM 可以部署为自动实现 OpenAI API 协议(即符合 OpenAI-API-Compatible 标准规范)的服务器。这使得 vLLM 可以作为使用 OpenAI API 应用程序的即插即用替代品。默认情况下,它在 https://IP:8000 启动服务器。您可以使用 --host 和 --port 参数指定IP地址和端口。
vLLM 服务器目前一次托管一个模型,并实现了诸如列出模型、创建聊天补全和创建补全等端点。
vLLM实战应用示例:
假设你有一台装有 2 张 A100 GPU 的服务器,你想为 Qwen2.5-7B-Instruct 模型启动一个高性能、带 API Key 的服务,并允许网络访问。可启动一个支持 OpenAI-API-Compatible 访问的 vLLM 服务,如下:
vllm serve Qwen/Qwen2.5-7B-Instruct \
–host 0.0.0.0 \
–port 8080 \
–tensor-parallel-size 2 \
–gpu-memory-utilization 0.85 \
–max-model-len 32768 \
–dtype bfloat16 \
–api-key “VLLM-PROD-KEY-12345” \
–served-model-name qwen-instruct
命令详解:
–Qwen/Qwen2.5-7B-Instruct: 模型名称,可以是Hugging Face上的模型标识符,也可以是本地大模型路径。
–host 0.0.0.0:监听所有网络接口,这样局域网内的其他机器也可以访问。
–port 8080: 指定服务在所有网卡的 8080 端口上可用。
–tensor-parallel-size 2: 大模型被切分到 2 张 A100 上。
–gpu-memory-utilization 0.85: 留出 15% 的显存作为缓冲,防止 OOM。
–max-model-len 32768: 充分利用 Qwen2.5 的长上下文能力。
–dtype bfloat16: 在 A100 上使用最佳的数据类型。
–api-key “VLLM-PROD-KEY-12345”: 设置了API访问密钥。
–served-model-name qwen-instruct: 这是一个非常有用的选项。它允许你给服务起一个更简单的别名。客户端在调用时,model 参数只需填写 qwen-instruct,而不是长长的 Qwen/Qwen2.5-7B-Instruct。
该vLLM服务器可以与 OpenAI API 相同的格式进行查询。例如,列出所有的模型:
curl https://vLLM服务器IP:8000/v1/models
可以通过传入参数 --api-key 或设置环境变量 VLLM_API_KEY,来实现使服务器需要检查 HTTP 头中的 API 密钥。
8.使用 vLLM 的 OpenAI Completions API
OpenAI Completions API 是 OpenAI 提供的一组核心接口,用于生成文本补全结果。简单来说,你向它提供一段文本(称为 prompt),它会根据模型的理解和训练数据,自动续写或生成后续内容。
8.1.功能本质:文本补全
输入:一段文本(prompt)。
输出:模型根据 prompt 生成的后续文本(completion)。
示例:
输入:“The sky is”
输出:“blue because of Rayleigh scattering.”
8.2.工作原理
模型通过分析 prompt 的上下文(语义、语法、风格),预测最可能的后续文本序列。
支持控制生成结果的参数(如长度、随机性、重复惩罚等)。
8.3.典型应用场景
| 场景 | 示例 |
| 内容创作 | 写文章、诗歌、广告文案、邮件草稿 |
| 代码生成 | 输入函数描述,生成代码片段 |
| 文本翻译 | 输入"Translate to French: Hello",输出 “Bonjour” |
| 问答系统 | 输入问题,生成答案 |
| 文本摘要 | 输入长文章,生成摘要 |
8.4.关键参数说明
调用 Completions API 时,可通过参数控制生成行为:
| 参数 | 作用 | 示例值 |
| model | 指定使用的模型(如 gpt-4, gpt-3.5-turbo-instruct) | “gpt-3.5-turbo-instruct” |
| prompt | 输入的文本提示 | “Once upon a time” |
| max_tokens | 限制生成文本的最大长度(1 token ≈ 0.75 个英文单词) | 512 |
| temperature | 控制随机性(0=确定性输出,1=高随机性) | 0.7 |
| top_p | 核采样(替代 temperature,控制词汇选择的多样性) | 0.9 |
| stop | 设置停止符(遇到指定字符时停止生成) | [“\n”, “User:”] |
| n | 一次性生成多个候选结果 | 3 |
8.5.示例代码
8.5.1.调用 OpenAI 官方 API
由于此 vLLM 服务器与 OpenAI API 兼容,还可以将其作为任何使用 OpenAI API 的应用程序的即插即用替代品。
例如,另一种查询服务器的方式是通过 openai Python 包:
from openai import OpenAI
openai_api_key = “EMPTY”
openai_api_base = “https://vLLM服务器IP:8000/v1”
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model=“Qwen/Qwen2.5-1.5B-Instruct”, prompt=“San Francisco is a”)
print(“Completion result:”, completion)
8.5.2.调用本地兼容服务(如 vLLM/Ollama)
from openai import OpenAI
client = OpenAI(
base_url=“http://localhost:8000/v1”, # 本地服务地址(如 vLLM/Ollama)
api_key=“not-needed” # 本地服务通常无需真实密钥
)
response = client.completions.create(
model=“llama3”, # 本地加载的模型名
prompt=“The future of AI is”,
max_tokens=30
)
print(response.choices[0].text)
输出示例: “transforming industries and enhancing human capabilities.”
8.6.使用curl命令输入提示查询大模型
vLLM 服务器启动后,可以使用curl命令,输入提示查询大模型如下:
curl https://vLLM服务器IP:8000/v1/completions \
-H “Content-Type: application/json” \
-d '{
“model”: “Qwen/Qwen2.5-1.5B-Instruct”,
“prompt”: “San Francisco is a”,
“max_tokens”: 7,
“temperature”: 0
}’
9.使用 vLLM 的 OpenAI Chat Completions API
vLLM 也被设计为支持 OpenAI Chat Completions API。
OpenAI Chat Completions API 是 OpenAI 提供的核心对话接口,专门用于构建基于多轮对话的应用(如聊天机器人、智能客服、AI助手等)。与传统的 Completions API 不同,它通过结构化的对话历史(Messages) 实现上下文理解,是当前 OpenAI 最主流、功能最强大的 API(支持 GPT-4、GPT-4o 等最新模型)。
聊天界面是一种更动态、交互性更强的方式与大模型进行通信,允许来回对话并存储在聊天历史中。这对于需要上下文或更详细解释的任务非常有用。
9.1.功能本质:对话式交互
输入:一组结构化的消息列表(messages),包含角色(role)和内容(content)。
输出:大模型根据对话历史生成的最新回复(assistant 角色的消息)。
关键角色:
system:设定模型行为(如“你是一个翻译助手”)。
user:用户输入(问题或指令)。
assistant:模型之前的回复(用于多轮对话)。
9.2.工作原理
模型通过分析 messages 列表中的完整对话上下文(包括历史交互),生成符合逻辑的回复。
支持动态调整对话流程(如修正错误、追问细节)。
9.3.典型应用场景
| 场景 | 示例 |
| 聊天机器人 | 客服机器人、虚拟助手(如 ChatGPT) |
| 多轮任务处理 | 代码调试(逐步修复错误)、数据分析(分步骤解释结果) |
| 复杂指令理解 | 长文本总结、跨文档信息整合 |
| 角色扮演 | 模拟面试官、历史人物对话 |
9.4.关键参数与功能
9.4.1.工具调用(Function Calling)
让大模型调用外部函数(如查询天气、数据库操作):
“tools”: [{
“type”: “function”,
“function”: {
“name”: “get_weather”,
“description”: “获取城市天气”,
“parameters”: {“type”: “object”, “properties”: {“city”: {“type”: “string”}}}
}
}]
9.4.2.多模态支持
支持输入图片(content 可为文本+图片混合):
{
“role”: “user”,
“content”: [
{“type”: “text”, “text”: “图中是什么?”},
{“type”: “image_url”, “image_url”: {“url”: “https://example.com/image.jpg”} }
]
}
9.5.代码示例
9.5.1.基础对话
from openai import OpenAI
openai_api_key = “EMPTY”
openai_api_base = “https://vLLM服务器IP:8000/v1”
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "你是一个幽默的诗人"},
{"role": "user", "content": "写一首关于月亮的短诗"}
]
)
print(response.choices[0].message.content)
输出:月亮挂在天上,像块没刷干净的锅,
星星们窃窃私语:“今晚谁洗碗?”
9.5.2.多轮对话 + 工具调用
定义工具函数
def get_weather(city):
return f"{city}当前天气:晴,25°C"
openai_api_key = “EMPTY”
openai_api_base = “https://vLLM服务器IP:8000/v1”
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
调用API
response = client.chat.completions.create(
model=“gpt-4o”,
messages=[
{“role”: “user”, “content”: “北京今天天气怎么样?”}
],
tools=[{
“type”: “function”,
“function”: {
“name”: “get_weather”,
“parameters”: {“properties”: {“city”: {“type”: “string”}}}
}
}]
)
检查是否需要调用工具
if response.choices[0].message.tool_calls:
tool_call = response.choices[0].message.tool_calls[0]
if tool_call.function.name == “get_weather”:
city = eval(tool_call.function.arguments)[“city”]
result = get_weather(city)
print(result) # 输出:北京当前天气:晴,25°C
9.6.使用curl命令创建聊天补全端点与模型交互
vLLM 服务器启动后,可以使用curl命令,创建聊天补全端点与模型交互如下:
curl https://vLLM服务器IP:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
重要提示:
如果你的应用需要“像人一样对话”,用 Chat Completions API;
如果你的应用需要只是“补全一句话”,用 Completions API。
10.vLLM支持的 Attention 后端
目前,vLLM 支持多种后端,可在不同平台和加速器架构上高效进行注意力计算。它会自动选择与您的系统和模型规范兼容的最佳性能后端。
如果需要,也可以通过将环境变量 VLLM_ATTENTION_BACKEND 配置为以下选项之一来手动设置您选择的后端:FLASH_ATTN、FLASHINFER 或 XFORMERS。
FLASH_ATTN、FLASHINFER 和 XFORMERS 比较:
1。性能和效率
FLASH_ATTN:通过分块计算和内存优化,显著减少显存占用,提升计算速度。在长序列任务中表现优异,计算速度比传统方法快2-3倍。
FLASHINFER:专注于推理阶段的优化,通过预计算和缓存机制,提高推理速度。在固定序列长度的场景下,性能优越。
XFORMERS:提供多种注意力机制的优化实现,如稀疏注意力和分块注意力。在中等序列长度下,速度较快,显存占用较低。
2。适用场景
FLASH_ATTN:适合长序列训练,如大型语言模型(LLM)和长文本处理。
FLASHINFER:适用于需要高速推理的场景,如实时问答系统和在线服务。
XFORMERS:适用于需要灵活注意力机制的场景,如图像处理和多模态任务。
因此,根据具体需求,我们选择合适的工具,以达到最佳的性能和效率:
(1)长序列训练:优先选择 FLASH_ATTN,性能最优。
(2)高速推理:选择 FLASHINFER,响应速度快。
(3)灵活应用:选择 XFORMERS,支持多种注意力机制。
3。易用性和集成性
FLASH_ATTN:需要额外安装和配置,对硬件要求较高(支持A系列和H系列显卡)。
FLASHINFER:提供便捷的API,易于集成到现有框架中,适合快速部署。
XFORMERS:由Meta开源,与PyTorch兼容性好,文档齐全,易于使用。
4。社区支持和生态
FLASH_ATTN:由斯坦福大学团队维护,社区活跃,更新频繁。
FLASHINFER:社区支持良好,适用于工业级应用。
XFORMERS:Meta官方支持,拥有广泛的用户基础和丰富的资源。
备注:
vLLM支持的 Attention 后端的定位:是大模型核心算法的底层实现(属于算法层/算子层)。
vLLM支持的Attention 后端,是大模型核心算法的底层实现。
11.小结
vLLM 的革命性在于它借鉴了操作系统的虚拟内存和分页思想,创造性地将其应用于LLM推理的核心——KV缓存管理(PagedAttention),并结合连续批处理和分块调度,构建了一个高度动态、内存高效、调度智能的推理引擎。
vLLM 从根本上解决了传统方法在内存碎片化、资源利用率低、调度僵化、无法共享缓存、处理长序列困难等方面的瓶颈问题,从而在吞吐量、延迟、高并发支持等关键性能指标上实现了数量级的提升,为大规模部署高性能、低成本的LLM在线服务铺平了道路。可以说,vLLM重新定义了LLM推理的性能标准。
重要提示:
- 企业生产环境高性能推理,必须使用 GPU + vLLM。
- 长期 CPU 推理,建议使用 LLaMA.cpp 或 Ollama。
vLLM的CPU模式,仅用于开发验证,实际性能远低于专用CPU框架(如LLaMA.cpp)。
希望以上内容对小伙伴们了解和使用 vLLM 推理引擎,搞大模型LLM加速推理有所帮助!更多内容小伙伴们也可以关注我整理的以下相关的官方资料。
传送门:
uv GitHub地址:
https://github.com/astral-sh/uv
uv 官方中文文档:
https://docs.astral.ac.cn/uv
vLLM GitHub地址:
https://github.com/vllm-project/vllm
vLLM 官方中文文档:
https://docs.vllm.com.cn/en/latest/index.html
vLLM 客户端命令行指南:
https://docs.vllm.ai/en/latest/cli/index.html
ModelScope (魔搭)官方网址:
https://modelscope.cn/home
NVIDIA 官方网址:
https://www.nvidia.com/en-us/drivers/
CUDA版本对应的驱动版本官方文档:
S:由Meta开源,与PyTorch兼容性好,文档齐全,易于使用。
4。社区支持和生态
FLASH_ATTN:由斯坦福大学团队维护,社区活跃,更新频繁。
FLASHINFER:社区支持良好,适用于工业级应用。
XFORMERS:Meta官方支持,拥有广泛的用户基础和丰富的资源。
备注:
vLLM支持的 Attention 后端的定位:是大模型核心算法的底层实现(属于算法层/算子层)。
vLLM支持的Attention 后端,是大模型核心算法的底层实现。
11.小结
vLLM 的革命性在于它借鉴了操作系统的虚拟内存和分页思想,创造性地将其应用于LLM推理的核心——KV缓存管理(PagedAttention),并结合连续批处理和分块调度,构建了一个高度动态、内存高效、调度智能的推理引擎。
vLLM 从根本上解决了传统方法在内存碎片化、资源利用率低、调度僵化、无法共享缓存、处理长序列困难等方面的瓶颈问题,从而在吞吐量、延迟、高并发支持等关键性能指标上实现了数量级的提升,为大规模部署高性能、低成本的LLM在线服务铺平了道路。可以说,vLLM重新定义了LLM推理的性能标准。
重要提示:
- 企业生产环境高性能推理,必须使用 GPU + vLLM。
- 长期 CPU 推理,建议使用 LLaMA.cpp 或 Ollama。
vLLM的CPU模式,仅用于开发验证,实际性能远低于专用CPU框架(如LLaMA.cpp)。
希望以上内容对小伙伴们了解和使用 vLLM 推理引擎,搞大模型LLM加速推理有所帮助!更多内容小伙伴们也可以关注我整理的以下相关的官方资料。
传送门:
uv GitHub地址:
https://github.com/astral-sh/uv
uv 官方中文文档:
https://docs.astral.ac.cn/uv
vLLM GitHub地址:
https://github.com/vllm-project/vllm
vLLM 官方中文文档:
https://docs.vllm.com.cn/en/latest/index.html
vLLM 客户端命令行指南:
https://docs.vllm.ai/en/latest/cli/index.html
ModelScope (魔搭)官方网址:
https://modelscope.cn/home
NVIDIA 官方网址:
https://www.nvidia.com/en-us/drivers/
CUDA版本对应的驱动版本官方文档:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-driver
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 5868
5868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









