




向量Embedding是目前检索增强生成(RAG)应用程序的核心。它们捕获数据对象(如文本,图像等)的语义信息,并以数字数组表示。在时下的生成式AI应用中,这些向量Embedding通常由Embedding模型生成。如何为RAG应用程序选择合适的Embedding模型呢?总体来说,这取决于具体用例以及具体需求。接下来,让我们拆分步骤来分别来看。
一、确定具体用例
我们基于RAG应用程序需求考虑以下问题:
首先,通用模型是否足以满足需求?
其次,是否有特定的需求?
在大多数情况下,针对所需模态,通常选择通用模型。
二、选择通用模型
如何选择通用模型呢?HuggingFace中Massive Text Embedding Benchmark(MTEB)排行榜罗列了当前各种专有和开源文本Embedding模型,对于每个Embedding模型,MTEB列出了各种指标,包括模型参数、内存、Embedding维度、最大token数量,以及其在检索、摘要等任务中的得分。
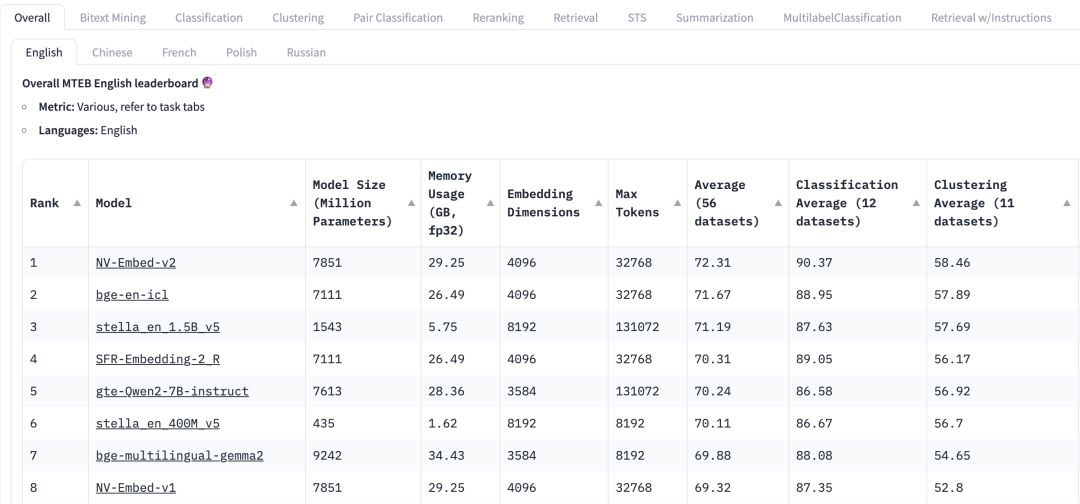
在为RAG应用程序选择Embedding模型的时候,需要考虑以下因素:
任务:在MTEB排行榜顶部,我们会看到各种任务选项卡。对于一个RAG应用程序,我们可能需要更关注“检索”任务,我们可以选择 Retrial 这个选项卡。
语言:基于RAG应用的数据集语言来选择对应语言的Embedding模型。
得分:表示模型在特定基准数据集或多个基准数据集上的表现。根据任务的不同,使用不同的评估指标。通常,这些指标的取值范围在0到1之间,值越高表示性能越好。
模型规模和内存用量:这些指标让我们了解模型运行时所需的计算资源。虽然检索性能随着模型规模的增加而提高,但需要注意的是,模型规模也直接影响延迟。此外,较大的模型可能会过拟合,其泛化性能低,从而在生产中表现不佳。因此,我们需要在生产环境中寻求性能和延迟之间的平衡。一般来说,我们可以先从一个小的、轻量级的模型开始,先快速构建RAG应用。在应用的基础流程正常运行之后,我们可以切换到更大、性能更高的模型,来对应用做进一步优化。
Embedding维度:这是Embedding向量的长度。虽然更大的Embedding维度可以捕获数据中更细微的细节,但是效果不一定是最佳。例如,我们是否真的需要8192维度来处理文档数据呢?可能不需要。另一方面,较小的Embedding维度提供了更快的推理速度,并且在存储和内存方面更高效。因此,我们需要在捕获数据内容和执行效率之间寻求良好的平衡。
最大token数量:表示单个Embedding的最大token数量。对于常见的RAG应用程序,Embedding较好的分块大小通常是单个段落,此时,最大token为512的Embedding模型应该足够。然而,在某些特殊情况下,我们可能需要token数量更大的模型来处理更长的文本。
三、在RAG应用中评估模型
虽然我们可以从MTEB排行榜找到通用模型,但我们需要谨慎对待其结果。谨记,这些结果是模型的自我报告,有可能某些模型产生了夸大其性能的分数,因为它们可能在训练数据中包含了MTEB数据集,毕竟这些是公开的数据集。另外,模型使用基准的数据集可能无法准确代表我们应用里使用的数据。因此,我们需要在自己的数据集上评估Embedding模型。
3.1 数据集
我们可以从RAG应用使用的数据中,生成一个小型标记数据集。我们以如下数据集为例。
| Language | Description |
|---|---|
| C/C++ | A general-purpose programming language known for its performance and efficiency. It provides low-level memory manipulation capabilities and is widely used in system/software development, game development, and applications requiring high performance. |
| Java | A versatile, object-oriented programming language designed to have as few implementation dependencies as possible. It is widely used for building enterprise-scale applications, mobile applications (especially Android), and web applications due to its portability and robustness. |
| Python | A high-level, interpreted programming language known for its readability and simplicity. It supports multiple programming paradigms and is widely used in web development, data analysis, artificial intelligence, scientific computing, and automation. |
| JavaScript | A high-level, dynamic programming language primarily used for creating interactive and dynamic content on the web. It is an essential technology for front-end web development and is increasingly used on the server-side with environments like Node.js. |
| C# | A modern, object-oriented programming language developed by Microsoft. It is used for developing a wide range of applications, including web, desktop, mobile, and games, particularly within the Microsoft ecosystem. |
| SQL | A domain-specific language used in programming and managing relational databases. It is essential for querying, updating, and managing data in databases, and is widely used in data analysis and business intelligence. |
| PHP | A server-side scripting language designed primarily for web development. It is embedded into HTML and is widely used for building dynamic web pages and applications, with a strong presence in content management systems like WordPress. |
| Golang | A statically typed, compiled programming language designed by Google. Known for its simplicity and efficiency, it is used for building scalable and high-performance applications, particularly in cloud services and distributed systems. |
| Rust | A systems programming language focused on safety and concurrency. It provides memory safety without using a garbage collector and is used for building reliable and efficient software, particularly in systems programming and web assembly. |
3.2 创建Embedding
接下来,我们采用pymilvus[model]对于上述数据集生成相应的向量Embedding。关于 pymilvus[model] 使用,参见https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name):
openai_ef = model.dense.OpenAIEmbeddingFunction(
model_name=model_name,
api_key=os.environ["OPENAI_API_KEY"]
)
docs_embeddings = openai_ef.encode_documents(df['description'].tolist())
return docs_embeddings, openai_ef
然后,把生成的Embedding存入到Milvus 的collection。
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 查询
我们定义查询函数,方便对于向量Embedding进行召回。
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 评估Embedding模型性能
我们采用 OpenAI的两个 Embedding模型,text-embedding-3-small 和 text-embedding-3-large,对于如下两个查询进行比较。有很多评估指标,例如准确率、召回率、MRR、MAP等。在这里,我们采用准确率和召回率。
准确率(Precision) 评估检索结果中的真正相关内容的占比,即返回的结果中有多少与搜索查询相关。
Precision = TP / (TP + FP)
其中,检索结果中与查询真正相关的内容 True Positives(TP), 而 False Positives(FP) 指的是检索结果中不相关的内容。
召回率 (Recall)评估从整个数据集中成功检索到相关内容的数量。
Recall = TP / (TP + FN)
其中,False Negatives (FN) 指的是所有未包含在最终结果集中的相关项目
对于这两个概念更详细的解释,参见 https://zilliz.com/learn/information-retrieval-metrics
查询 1:auto garbage collection
相关项:Java, Python, JavaScript, Golang
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Rust | ❎ Rust |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Precision | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
查询 2:suite for web backend server development
相关项:Java, JavaScript, PHP, Python (答案包含主观判断)
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Precision | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
在这两个查询中,我们通过准确率和召回率对比了两个Embedding模型 text-embedding-3-small 和 text-embedding-3-large 。我们可以以此为起点,增加数据集中数据对象的数量以及查询的数量,如此才能更有效地评估Embedding模型。
四、总结
在检索增强生成(RAG)应用中,选择合适的向量Embedding模型至关重要。本文阐述了从实际业务需求出发,从MTEB选择通用模型之后,采用准确率和召回率对于模型基于特定业务的数据集进行测试,从而选择最合适的Embedding模型,进而有效地提高RAG应用的召回准确率。
完整代码可通过链接获取:
链接: https://pan.baidu.com/s/1CqewAUpWxrnbUuDUIun-Lw?pwd=1234
提取码: 1234
五、全套的AI大模型学习资源分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









