



一、引言
-
大模型(Large Models)是人工智能发展的里程碑,特别是基于深度学习的预训练模型(如 GPT、BERT)。
-
随着模型参数规模的指数级增长,大模型在自然语言处理(NLP)、计算机视觉(CV)等领域取得了突破性成果。
-
本文将深入解析大模型的核心技术、应用场景、优化策略及未来挑战。
二、大模型的背景与定义
1.1 什么是大模型
-
大模型指的是参数规模超过亿级甚至千亿级的深度学习模型。
-
特点:
- 高容量:能够捕捉复杂模式和分布。
- 通用性:支持多任务、多模态(如文本、图像、音频)学习。
- 可扩展性:在预训练基础上,通过少量样本(Few-shot)或无监督微调(Zero-shot)完成特定任务。
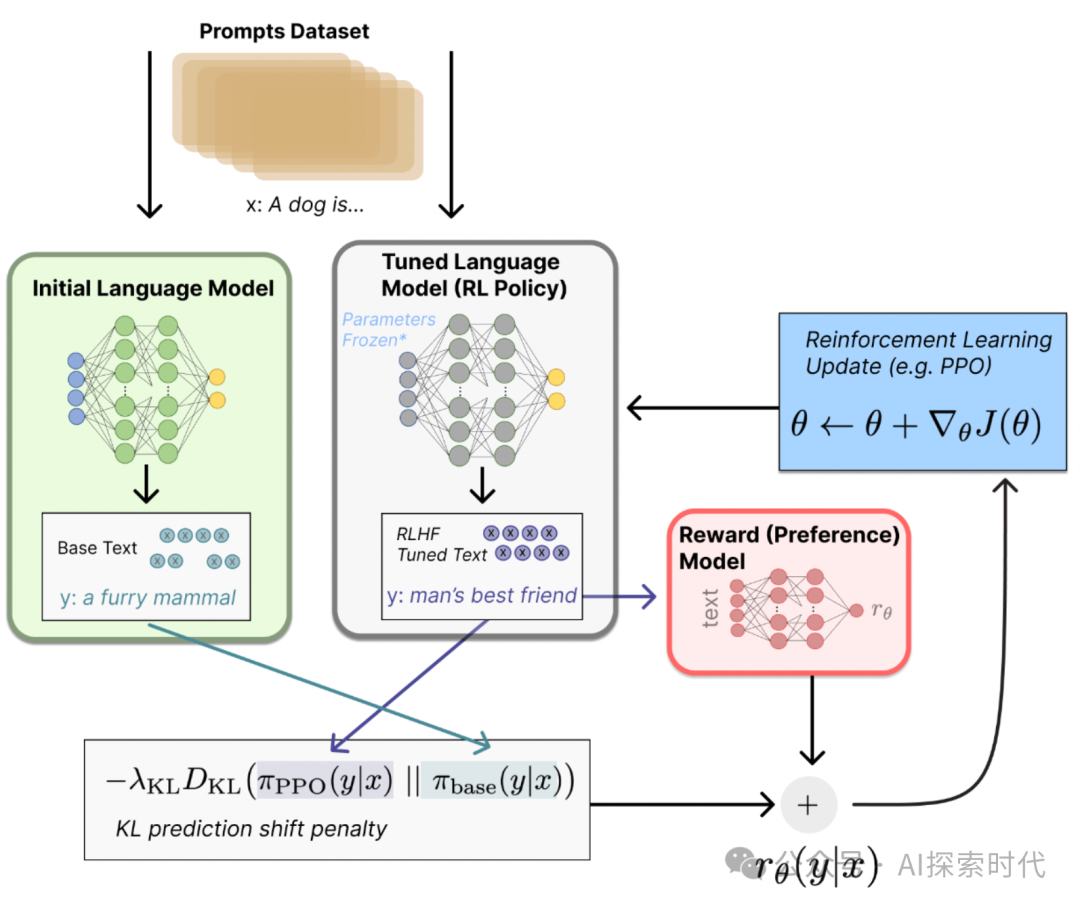
1.2 大模型发展的阶段
-
1.0 传统机器学习模型:如 SVM、决策树。
-
2.0 深度学习模型:如 CNN、RNN。
-
3.0 预训练模型:BERT、GPT。
-
4.0 多模态模型:如 OpenAI 的 CLIP,DeepMind 的 Gato。
1.3 参数规模的增长
-
参数规模从早期的百万级(如 LSTM)发展到百亿级(如 GPT-3)再到万亿级(如 GPT-4、PaLM)。
-
参数规模增长的驱动力:
-
更强的硬件支持(GPU/TPU)。
-
更高效的分布式训练算法。
-
海量标注与非标注数据的积累。
2. 大模型的核心技术
2.1 模型架构
-
Transformer 架构:
-
基于注意力机制(Attention Mechanism),实现更好的全局信息捕获。
-
Self-Attention 的时间复杂度为 O(n2)O(n2),适合并行化训练。
-
改进的 Transformer:
-
Sparse Attention(稀疏注意力):降低计算复杂度。
-
Longformer:处理长文本输入。
2.2 数据处理与预训练
-
数据处理:
-
使用海量数据(如文本、代码、图像)进行去噪和清洗。
-
多模态融合技术,将图像与文本联合编码。
-
预训练目标:
-
自回归(Auto-Regressive):预测下一个 token(如 GPT)。
-
自编码(Auto-Encoding):掩盖部分输入并恢复原始内容(如 BERT)。
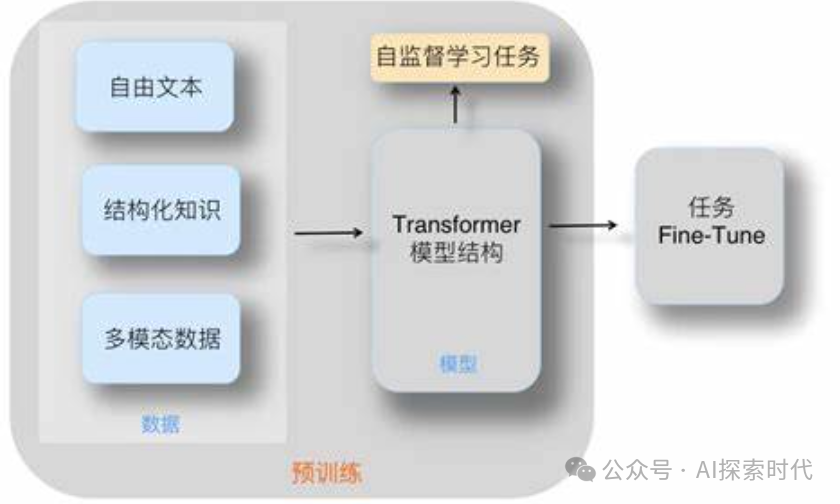
2.3 模型训练与优化
-
分布式训练:
-
数据并行(Data Parallelism):多个设备共享模型权重,不同设备处理不同数据。
-
模型并行(Model Parallelism):将模型切分为多个部分,分布到不同设备。
-
优化技术:
-
混合精度训练(Mixed Precision Training):提升训练速度,降低显存占用。
-
大批量训练(Large Batch Training):结合学习率调度策略。
2.4 模型压缩
-
模型蒸馏(Knowledge Distillation):用大模型指导小模型训练。
-
参数量化(Quantization):减少模型权重的精度(如 32-bit 到 8-bit)。
-
稀疏化(Sparsification):去除冗余参数。
3. 大模型的应用场景
3.1 自然语言处理
-
文本生成:如 ChatGPT、Bard。
-
机器翻译:如 Google Translate。
-
文本摘要:从长文档中提取核心信息。
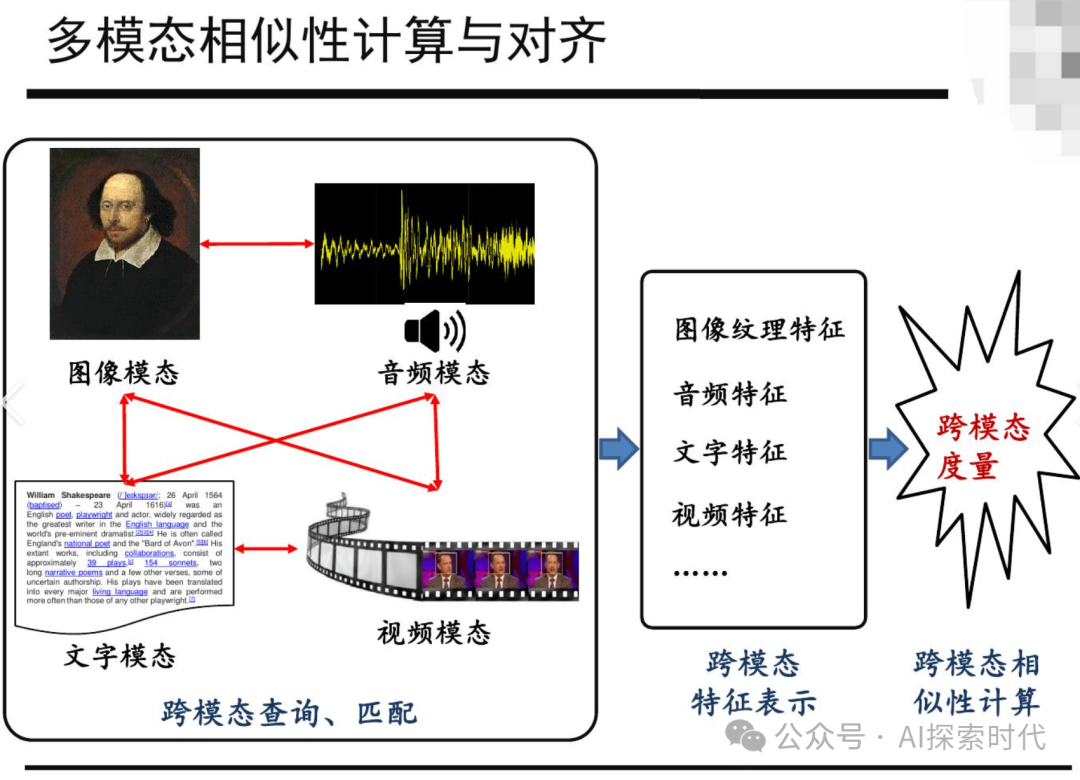
3.2 多模态学习
-
图像与文本结合:如 OpenAI 的 DALL·E,通过文本生成图像。
-
视频理解:如 DeepMind 的 Flamingo,支持跨模态推理。
-
医学影像分析:结合文本描述辅助诊断。
3.3 科学研究
-
蛋白质折叠预测:如 DeepMind 的 AlphaFold。
-
化学反应模拟:利用大模型加速新材料发现。
4. 大模型的挑战
4.1 计算资源与成本
-
训练大模型需要大量计算资源(如数千张 GPU),成本高昂。
-
推理效率仍是瓶颈,特别是在边缘设备上。
4.2 数据质量与偏差
-
大模型对数据高度依赖,低质量数据可能导致偏差。
-
隐私和伦理问题:如训练数据中包含敏感信息。
4.3 可解释性
-
大模型通常被视为“黑盒”,其决策过程难以理解。
-
需要开发更好的模型可视化和解释技术。
4.4 通用性与专用性
- 通用大模型在某些领域表现优异,但专用领域可能需要针对性优化。
5. 大模型的未来
5.1 模型设计的创新
-
向高效化、稀疏化方向发展,如 Modular Transformer。
-
探索生物启发的架构(如脑启发计算)。
5.2 更好的多模态集成
- 实现真正的“通用智能”(AGI),支持跨模态任务协作。
5.3 环境友好型 AI
-
开发绿色 AI 技术,降低碳排放。
-
通过知识重用减少训练次数。
5.4 开放与合作
-
开源大模型(如 Meta 的 LLaMA)促进了研究社区的合作。
-
更多跨学科应用,如金融、医学、物理等。
结论
大模型是当前 AI 技术的核心驱动力,从技术架构到实际应用都带来了深远影响。然而,随着模型规模的持续扩大,也暴露出资源消耗、伦理风险等挑战。未来,优化模型效率、提升可解释性、推动多模态融合将成为关键研究方向。
三、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









