



通过测试该架构的各个方面,发现训练数据是关键。 通过在数据集中包含更多运动和形状,您可以增加可变性并提高模型的性能。由于数据是通过代码生成的,因此生成更多样的数据不会花费太多时间;相反,您可以专注于完善逻辑。
此外,本文中讨论的 GAN 架构相对简单。 您可以通过集成先进技术或使用语言模型嵌入 (LLM) 而不是基本的神经网络嵌入来使其变得更加复杂。此外,调整嵌入大小等参数可以显著影响模型的有效性。
一、引 言
OpenAI 的 Sora、Stability AI 的 Stable Video Diffusion 以及许多其他已经出现或未来将出现的文本到视频模型都是继大型语言模型(LLM)之后的 2024 年最流行的人工智能趋势之一。
在本文中,将从头开始构建一个小型文本到视频模型。输入一个文本提示,我们训练的模型将根据该提示生成一个视频。
本项目代码已整理并放到GitHub存储库(欢迎Star):https://github.com/AI-mzq/From-Zero-to-AGI.git

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

二、我们将要做什么?
将遵循与传统机器学习或深度学习模型类似的方法,在数据集上进行训练,然后在未见过的数据上进行测试。
在文本到视频的背景下,假设有一个包含 10 万个狗捡球和猫追老鼠视频的训练数据集。我们将训练 T2V 模型来生成猫捡球或狗追老鼠的视频。那么,方法架构如下图所示:
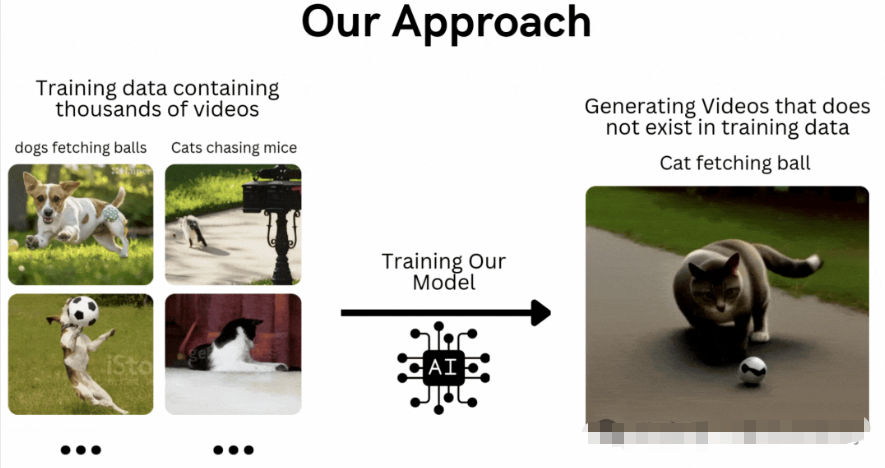
我们将使用 GAN(生成对抗网络)架构来创建我们的模型,而不是 OpenAI Sora 使用的扩散模型(Diffusion Model)。
我尝试使用扩散模型,但由于内存要求而崩溃!资源充足者可尝试,原理是类似的,只是将GAN换成了扩散模型。
另一方面,GAN 的训练和测试更容易、更快捷。
1、什么是GAN?
理解 GAN 架构很重要,因为本例的大部分架构都依赖于它。让我们一起来探讨它是什么、它的组件等等。
生成对抗网络 (GAN) 是一种深度学习模型,其中两个神经网络(生成器和判别器)相互竞争:一个从给定的数据集中创建新数据(如图像或音乐),另一个尝试判断数据是真是假。
这个过程一直持续到生成的数据与原始数据无法区分为止。
2、GAN 是如何工作的?
它由两个深度神经网络组成:生成器和判别器。这些网络在对抗性设置中一起训练,其中一个网络生成新数据,另一个网络评估数据是真实的还是虚假的。

简单概述下GAN工作原理:
- 训练集分析:生成器分析训练集以识别数据属性,而判别器独立分析相同的数据以学习其属性。
- 数据修改:生成器向数据的某些属性添加噪声(随机变化)。
- 数据传递:修改后的数据然后被传递到判别器。
- 概率计算:判别器计算生成的数据来自原始数据集的概率。
- 反馈循环:判别器向生成器提供反馈,指导生成器减少下一个周期的随机噪声。
- 对抗性训练:生成器试图最大化判别器的错误,而判别器则试图最小化自己的错误。通过多次训练迭代,两个网络都得到改进和发展。
- 平衡状态:训练继续,直到判别器无法再区分真实数据和合成数据,表明生成器已成功学会生成真实数据。至此,训练过程就完成了。
3、GAN训练示例
让我们以图像到图像转换的示例来解释 GAN 模型,重点是修改人脸。
- 输入图像:输入是人脸的真实图像。
- 属性修改:生成器修改脸部的属性,例如为眼睛添加太阳镜。
- 生成的图像:生成器创建一组添加了太阳镜的图像。
- 判别器的任务:判别器接收真实图像(戴太阳镜的人)和生成图像(添加太阳镜的人脸)的混合。
- 评估:判别器尝试区分真实图像和生成图像。
- 反馈循环:如果判别器正确识别出假图像,则生成器会调整其参数以产生更令人信服的图像。如果生成器成功欺骗了判别器,判别器就会更新其参数以改进其检测。
通过这个对抗过程,两个网络都在不断改进。生成器在创建真实图像方面变得更好,判别器在识别赝品方面也变得更好,直到达到平衡,判别器不再能够区分真实图像和生成图像之间的差异。至此,GAN 已经成功学会了产生现实的修改。
三、开始构建 T2V
1、安装依赖库
安装所需的库是构建文本到视频模型的第一步。
pip install -r requirements.txt
2、编码训练数据
我们至少需要10,000 个视频作为训练数据。如果数据量太少,效果将会很差!同时,训练视频数据集由一个以不同运动向不同方向移动的圆圈组成。当然,这是为了方便演示和资源的限制!当有必要时,我们可以将训练数据直接换成开源视频数据集!!
让我们对其进行编码并生成 10,000 个视频来看看它是什么样子。
# Create a directory named 'training_dataset'
os.makedirs('training_dataset', exist_ok=True)
# Define the number of videos to generate for the dataset
num_videos = 10000
# Define the number of frames per video (1 Second Video)
frames_per_video = 10
# Define the size of each image in the dataset
img_size = (64, 64)
# Define the size of the shapes (Circle)
shape_size = 10
设置一些基本参数后,接下来需要定义训练数据集的文本提示,根据该文本提示将生成训练视频。
# Define text prompts and corresponding movements for circles
prompts_and_movements = [
("circle moving down", "circle", "down"), # Move circle downward
("circle moving left", "circle", "left"), # Move circle leftward
("circle moving right", "circle", "right"), # Move circle rightward
("circle moving diagonally up-right", "circle", "diagonal_up_right"), # Move circle diagonally up-right
("circle moving diagonally down-left", "circle", "diagonal_down_left"), # Move circle diagonally down-left
("circle moving diagonally up-left", "circle", "diagonal_up_left"), # Move circle diagonally up-left
("circle moving diagonally down-right", "circle", "diagonal_down_right"), # Move circle diagonally down-right
("circle rotating clockwise", "circle", "rotate_clockwise"), # Rotate circle clockwise
("circle rotating counter-clockwise", "circle", "rotate_counter_clockwise"), # Rotate circle counter-clockwise
("circle shrinking", "circle", "shrink"), # Shrink circle
("circle expanding", "circle", "expand"), # Expand circle
("circle bouncing vertically", "circle", "bounce_vertical"), # Bounce circle vertically
("circle bouncing horizontally", "circle", "bounce_horizontal"), # Bounce circle horizontally
("circle zigzagging vertically", "circle", "zigzag_vertical"), # Zigzag circle vertically
("circle zigzagging horizontally", "circle", "zigzag_horizontal"), # Zigzag circle horizontally
("circle moving up-left", "circle", "up_left"), # Move circle up-left
("circle moving down-right", "circle", "down_right"), # Move circle down-right
("circle moving down-left", "circle", "down_left"), # Move circle down-left
]
使用这些提示定义了圆圈的几种运动。现在,我们需要编写一些数学方程来根据提示移动该圆圈。
# defining function to create image with moving shape
def create_image_with_moving_shape(size, frame_num, shape, direction):
# Create a new RGB image with specified size and white background
img = Image.new('RGB', size, color=(255, 255, 255))
# Create a drawing context for the image
draw = ImageDraw.Draw(img)
# Calculate the center coordinates of the image
center_x, center_y = size[0] // 2, size[1] // 2
# Initialize position with center for all movements
position = (center_x, center_y)
# Define a dictionary mapping directions to their respective position adjustments or image transformations
direction_map = {
# Adjust position downwards based on frame number
"down": (0, frame_num * 5 % size[1]),
# Adjust position to the left based on frame number
"left": (-frame_num * 5 % size[0], 0),
# Adjust position to the right based on frame number
"right": (frame_num * 5 % size[0], 0),
# Adjust position diagonally up and to the right
"diagonal_up_right": (frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position diagonally down and to the left
"diagonal_down_left": (-frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Adjust position diagonally up and to the left
"diagonal_up_left": (-frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position diagonally down and to the right
"diagonal_down_right": (frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Rotate the image clockwise based on frame number
"rotate_clockwise": img.rotate(frame_num * 10 % 360, center=(center_x, center_y), fillcolor=(255, 255, 255)),
# Rotate the image counter-clockwise based on frame number
"rotate_counter_clockwise": img.rotate(-frame_num * 10 % 360, center=(center_x, center_y), fillcolor=(255, 255, 255)),
# Adjust position for a bouncing effect vertically
"bounce_vertical": (0, center_y - abs(frame_num * 5 % size[1] - center_y)),
# Adjust position for a bouncing effect horizontally
"bounce_horizontal": (center_x - abs(frame_num * 5 % size[0] - center_x), 0),
# Adjust position for a zigzag effect vertically
"zigzag_vertical": (0, center_y - frame_num * 5 % size[1]) if frame_num % 2 == 0 else (0, center_y + frame_num * 5 % size[1]),
# Adjust position for a zigzag effect horizontally
"zigzag_horizontal": (center_x - frame_num * 5 % size[0], center_y) if frame_num % 2 == 0 else (center_x + frame_num * 5 % size[0], center_y),
# Adjust position upwards and to the right based on frame number
"up_right": (frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position upwards and to the left based on frame number
"up_left": (-frame_num * 5 % size[0], -frame_num * 5 % size[1]),
# Adjust position downwards and to the right based on frame number
"down_right": (frame_num * 5 % size[0], frame_num * 5 % size[1]),
# Adjust position downwards and to the left based on frame number
"down_left": (-frame_num * 5 % size[0], frame_num * 5 % size[1])
}
# Check if direction is in the direction map
if direction in direction_map:
# Check if the direction maps to a position adjustment
if isinstance(direction_map[direction], tuple):
# Update position based on the adjustment
position = tuple(np.add(position, direction_map[direction]))
else: # If the direction maps to an image transformation
# Update the image based on the transformation
img = direction_map[direction]
# Return the image as a numpy array
return np.array(img)
上面的函数用于根据所选方向移动每一帧的圆。只需要在其上运行一个循环,直到达到视频数量的次数即可生成所有视频。
# Iterate over the number of videos to generate
for i in range(num_videos):
# Randomly choose a prompt and movement from the predefined list
prompt, shape, direction = random.choice(prompts_and_movements)
# Create a directory for the current video
video_dir = f'training_dataset/video_{i}'
os.makedirs(video_dir, exist_ok=True)
# Write the chosen prompt to a text file in the video directory
with open(f'{video_dir}/prompt.txt', 'w') as f:
f.write(prompt)
# Generate frames for the current video
for frame_num in range(frames_per_video):
# Create an image with a moving shape based on the current frame number, shape, and direction
img = create_image_with_moving_shape(img_size, frame_num, shape, direction)
# Save the generated image as a PNG file in the video directory
cv2.imwrite(f'{video_dir}/frame_{frame_num}.png', img)
运行上述代码后,将生成整个训练数据集。
每个训练视频文件夹都包含其帧及其文本提示。让我们看一下训练数据集的样本。

在训练数据集中,没有包含圆圈向上移动然后向右移动的运动。将使用它作为测试提示来评估我们在未见过的数据上训练的模型。
需要注意的一点是,训练数据确实包含许多样本,其中物体远离场景或部分出现在相机前面,类似于 OpenAI Sora 演示视频中观察到的情况。

在训练数据中包含此类样本的原因是为了测试当圆圈从最角落进入场景而不破坏其形状时,我们的模型是否能够保持一致性。
现在训练数据已经生成,我们需要将训练视频转换为张量,这是 PyTorch 等深度学习框架中使用的主要数据类型。此外,执行归一化等转换有助于通过将数据扩展到更小的范围来提高训练架构的收敛性和稳定性。
3、预处理训练数据
我们必须为文本到视频任务编写一个数据集类,它可以从训练数据集目录中读取视频帧及其相应的文本提示,使其可在 PyTorch 中使用。
# Define a dataset class inheriting from torch.utils.data.Dataset
class TextToVideoDataset(Dataset):
def __init__(self, root_dir, transform=None):
# Initialize the dataset with root directory and optional transform
self.root_dir = root_dir
self.transform = transform
# List all subdirectories in the root directory
self.video_dirs = [os.path.join(root_dir, d) for d in os.listdir(root_dir) if os.path.isdir(os.path.join(root_dir, d))]
# Initialize lists to store frame paths and corresponding prompts
self.frame_paths = []
self.prompts = []
# Loop through each video directory
for video_dir in self.video_dirs:
# List all PNG files in the video directory and store their paths
frames = [os.path.join(video_dir, f) for f in os.listdir(video_dir) if f.endswith('.png')]
self.frame_paths.extend(frames)
# Read the prompt text file in the video directory and store its content
with open(os.path.join(video_dir, 'prompt.txt'), 'r') as f:
prompt = f.read().strip()
# Repeat the prompt for each frame in the video and store in prompts list
self.prompts.extend([prompt] * len(frames))
# Return the total number of samples in the dataset
def __len__(self):
return len(self.frame_paths)
# Retrieve a sample from the dataset given an index
def __getitem__(self, idx):
# Get the path of the frame corresponding to the given index
frame_path = self.frame_paths[idx]
# Open the image using PIL (Python Imaging Library)
image = Image.open(frame_path)
# Get the prompt corresponding to the given index
prompt = self.prompts[idx]
# Apply transformation if specified
if self.transform:
image = self.transform(image)
# Return the transformed image and the prompt
return image, prompt
我们将使用 batch-size为 16 的大小并对数据进行打乱以引入更多随机性。
# Define a set of transformations to be applied to the data
transform = transforms.Compose([
transforms.ToTensor(), # Convert PIL Image or numpy.ndarray to tensor
transforms.Normalize((0.5,), (0.5,)) # Normalize image with mean and standard deviation
])
# Load the dataset using the defined transform
dataset = TextToVideoDataset(root_dir='training_dataset', transform=transform)
# Create a dataloader to iterate over the dataset
dataloader = torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)
4、实现文本嵌入层
在transformer架构中看到过,起点是将文本输入转换为嵌入,以便在多头注意力中进行进一步处理,类似于这里,我们必须编写一个文本嵌入层,基于该层,GAN架构训练将在嵌入数据和图像张量上进行。
# Define a class for text embedding
class TextEmbedding(nn.Module):
# Constructor method with vocab_size and embed_size parameters
def __init__(self, vocab_size, embed_size):
# Call the superclass constructor
super(TextEmbedding, self).__init__()
# Initialize embedding layer
self.embedding = nn.Embedding(vocab_size, embed_size)
# Define the forward pass method
def forward(self, x):
# Return embedded representation of input
return self.embedding(x)
词汇量大小将基于训练数据,稍后我们将计算这些数据。嵌入大小将为 10。如果使用更大的数据集,可以使用自己选择的 Hugging Face 上提供的嵌入模型。
5、实现生成器层
现在我们已经知道生成器在 GAN 中的作用,让我们对这一层进行编码,然后了解其内容。
class Generator(nn.Module):
def __init__(self, text_embed_size):
super(Generator, self).__init__()
# Fully connected layer that takes noise and text embedding as input
self.fc1 = nn.Linear(100 + text_embed_size, 256 * 8 * 8)
# Transposed convolutional layers to upsample the input
self.deconv1 = nn.ConvTranspose2d(256, 128, 4, 2, 1)
self.deconv2 = nn.ConvTranspose2d(128, 64, 4, 2, 1)
self.deconv3 = nn.ConvTranspose2d(64, 3, 4, 2, 1) # Output has 3 channels for RGB images
# Activation functions
self.relu = nn.ReLU(True) # ReLU activation function
self.tanh = nn.Tanh() # Tanh activation function for final output
def forward(self, noise, text_embed):
# Concatenate noise and text embedding along the channel dimension
x = torch.cat((noise, text_embed), dim=1)
# Fully connected layer followed by reshaping to 4D tensor
x = self.fc1(x).view(-1, 256, 8, 8)
# Upsampling through transposed convolution layers with ReLU activation
x = self.relu(self.deconv1(x))
x = self.relu(self.deconv2(x))
# Final layer with Tanh activation to ensure output values are between -1 and 1 (for images)
x = self.tanh(self.deconv3(x))
return x
该生成器类负责根据随机噪声和文本嵌入的组合创建视频帧。它的目的是根据给定的文本描述生成逼真的视频帧。该网络从全连接层 (nn.Linear) 开始,它将噪声向量和文本嵌入组合成单个特征向量。然后,该向量被重塑并通过一系列转置卷积层 (nn.ConvTranspose2d),这些层逐渐将特征图上采样到所需的视频帧大小。
这些层使用 ReLU 激活 (nn.ReLU) 实现非线性,最后一层使用 Tanh 激活 (nn.Tanh) 将输出缩放到范围 [-1, 1]。因此,生成器将抽象的高维输入转换为连贯的视频帧,直观地表示输入文本。
6、实施判别器层
对生成器层进行编码后,我们继续实现判别器部分。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Convolutional layers to process input images
self.conv1 = nn.Conv2d(3, 64, 4, 2, 1) # 3 input channels (RGB), 64 output channels, kernel size 4x4, stride 2, padding 1
self.conv2 = nn.Conv2d(64, 128, 4, 2, 1) # 64 input channels, 128 output channels, kernel size 4x4, stride 2, padding 1
self.conv3 = nn.Conv2d(128, 256, 4, 2, 1) # 128 input channels, 256 output channels, kernel size 4x4, stride 2, padding 1
# Fully connected layer for classification
self.fc1 = nn.Linear(256 * 8 * 8, 1) # Input size 256x8x8 (output size of last convolution), output size 1 (binary classification)
# Activation functions
self.leaky_relu = nn.LeakyReLU(0.2, inplace=True) # Leaky ReLU activation with negative slope 0.2
self.sigmoid = nn.Sigmoid() # Sigmoid activation for final output (probability)
def forward(self, input):
# Pass input through convolutional layers with LeakyReLU activation
x = self.leaky_relu(self.conv1(input))
x = self.leaky_relu(self.conv2(x))
x = self.leaky_relu(self.conv3(x))
# Flatten the output of convolutional layers
x = x.view(-1, 256 * 8 * 8)
# Pass through fully connected layer with Sigmoid activation for binary classification
x = self.sigmoid(self.fc1(x))
return x
判别器类充当二元分类器,区分真实视频帧和生成的视频帧。其目的是评估视频帧的真实性,从而指导生成器产生更真实的输出。该网络由卷积层 (nn.Conv2d) 组成,用于从输入视频帧中提取分层特征,并使用 Leaky ReLU 激活 (nn.LeakyReLU) 增加非线性,同时允许负值的小梯度。然后,特征图被展平并通过全连接层 (nn.Linear),最终形成 sigmoid 激活 (nn.Sigmoid),输出一个概率分数,指示帧是真实的还是假的。
通过训练判别器对帧进行准确分类,同时训练生成器以创建更有说服力的视频帧,因为它的目的是欺骗判别器。
7、编码训练参数
我们必须设置训练 GAN 的基本组件,例如损失函数、优化器等。
# Check for GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Create a simple vocabulary for text prompts
all_prompts = [prompt for prompt, _, _ in prompts_and_movements] # Extract all prompts from prompts_and_movements list
vocab = {word: idx for idx, word in enumerate(set(" ".join(all_prompts).split()))} # Create a vocabulary dictionary where each unique word is assigned an index
vocab_size = len(vocab) # Size of the vocabulary
embed_size = 10 # Size of the text embedding vector
def encode_text(prompt):
# Encode a given prompt into a tensor of indices using the vocabulary
return torch.tensor([vocab[word] for word in prompt.split()])
# Initialize models, loss function, and optimizers
text_embedding = TextEmbedding(vocab_size, embed_size).to(device) # Initialize TextEmbedding model with vocab_size and embed_size
netG = Generator(embed_size).to(device) # Initialize Generator model with embed_size
netD = Discriminator().to(device) # Initialize Discriminator model
criterion = nn.BCELoss().to(device) # Binary Cross Entropy loss function
optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999)) # Adam optimizer for Discriminator
optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999)) # Adam optimizer for Generator
我们必须将代码转换为在 GPU 上运行(如果可用)的部分。我们已编写代码来查找 vocab_size,并且对生成器和判别器使用 Adam 优化器。当然,也可以选择其他优化器方法。将学习率设置为 0.0002,嵌入大小为 10,这比其他可供公众使用的 Hugging Face 模型要小得多。
8、训练循环编码
就像所有其他神经网络一样,我们将以类似的方式编码 GAN 训练。
# Number of epochs
num_epochs = 13
# Iterate over each epoch
for epoch in range(num_epochs):
# Iterate over each batch of data
for i, (data, prompts) in enumerate(dataloader):
# Move real data to device
real_data = data.to(device)
# Convert prompts to list
prompts = [prompt for prompt in prompts]
# Update Discriminator
netD.zero_grad() # Zero the gradients of the Discriminator
batch_size = real_data.size(0) # Get the batch size
labels = torch.ones(batch_size, 1).to(device) # Create labels for real data (ones)
output = netD(real_data) # Forward pass real data through Discriminator
lossD_real = criterion(output, labels) # Calculate loss on real data
lossD_real.backward() # Backward pass to calculate gradients
# Generate fake data
noise = torch.randn(batch_size, 100).to(device) # Generate random noise
text_embeds = torch.stack([text_embedding(encode_text(prompt).to(device)).mean(dim=0) for prompt in prompts]) # Encode prompts into text embeddings
fake_data = netG(noise, text_embeds) # Generate fake data from noise and text embeddings
labels = torch.zeros(batch_size, 1).to(device) # Create labels for fake data (zeros)
output = netD(fake_data.detach()) # Forward pass fake data through Discriminator (detach to avoid gradients flowing back to Generator)
lossD_fake = criterion(output, labels) # Calculate loss on fake data
lossD_fake.backward() # Backward pass to calculate gradients
optimizerD.step() # Update Discriminator parameters
# Update Generator
netG.zero_grad() # Zero the gradients of the Generator
labels = torch.ones(batch_size, 1).to(device) # Create labels for fake data (ones) to fool Discriminator
output = netD(fake_data) # Forward pass fake data (now updated) through Discriminator
lossG = criterion(output, labels) # Calculate loss for Generator based on Discriminator's response
lossG.backward() # Backward pass to calculate gradients
optimizerG.step() # Update Generator parameters
# Print epoch information
print(f"Epoch [{epoch + 1}/{num_epochs}] Loss D: {lossD_real + lossD_fake}, Loss G: {lossG}")
通过反向传播,损失将针对生成器和判别器进行调整。
当运行此代码时,它会开始训练并在每个 epoch 后打印生成器和判别器的损失。
## OUTPUT ##
Epoch [1/13] Loss D: 0.8798642754554749, Loss G: 1.300612449645996
Epoch [2/13] Loss D: 0.8235711455345154, Loss G: 1.3729925155639648
Epoch [3/13] Loss D: 0.6098687052726746, Loss G: 1.3266581296920776
...
...
9、保存训练后的模型
训练完成后,需要保存训练好的 GAN 架构的判别器和生成器,这只需两行代码即可实现。
# Save the Generator model's state dictionary to a file named 'generator.pth'
torch.save(netG.state_dict(), 'generator.pth')
# Save the Discriminator model's state dictionary to a file named 'discriminator.pth'
torch.save(netD.state_dict(), 'discriminator.pth')
10、生成 AI 视频
正如本例所讨论的,我们在未见过的数据上测试模型的方法与我们的训练数据涉及狗捡球和猫追老鼠的示例相当。因此,测试提示可能涉及诸如猫取球或狗追老鼠之类的场景。
在我们的具体情况中,圆圈向上然后向右移动的运动不存在于我们的训练数据中,因此模型不熟悉这种特定运动。然而,它已经接受了其他动作的训练。我们可以使用这个动作作为测试我们训练的模型并观察其性能的提示。
# Inference function to generate a video based on a given text prompt
def generate_video(text_prompt, num_frames=10):
# Create a directory for the generated video frames based on the text prompt
os.makedirs(f'generated_video_{text_prompt.replace(" ", "_")}', exist_ok=True)
# Encode the text prompt into a text embedding tensor
text_embed = text_embedding(encode_text(text_prompt).to(device)).mean(dim=0).unsqueeze(0)
# Generate frames for the video
for frame_num in range(num_frames):
# Generate random noise
noise = torch.randn(1, 100).to(device)
# Generate a fake frame using the Generator network
with torch.no_grad():
fake_frame = netG(noise, text_embed)
# Save the generated fake frame as an image file
save_image(fake_frame, f'generated_video_{text_prompt.replace(" ", "_")}/frame_{frame_num}.png')
# usage of the generate_video function with a specific text prompt
generate_video('circle moving up-right')
当我们运行上面的代码时,它将生成一个目录,其中包含我们生成的视频的所有帧。我们需要使用一些代码将所有这些帧合并成一个短视频。
# Define the path to your folder containing the PNG frames
folder_path = 'generated_video_circle_moving_up-right'
# Get the list of all PNG files in the folder
image_files = [f for f in os.listdir(folder_path) if f.endswith('.png')]
# Sort the images by name (assuming they are numbered sequentially)
image_files.sort()
# Create a list to store the frames
frames = []
# Read each image and append it to the frames list
for image_file in image_files:
image_path = os.path.join(folder_path, image_file)
frame = cv2.imread(image_path)
frames.append(frame)
# Convert the frames list to a numpy array for easier processing
frames = np.array(frames)
# Define the frame rate (frames per second)
fps = 10
# Create a video writer object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('generated_video.avi', fourcc, fps, (frames[0].shape[1], frames[0].shape[0]))
# Write each frame to the video
for frame in frames:
out.write(frame)
# Release the video writer
out.release()
确保文件夹路径指向新生成的视频所在的位置。运行此代码后,您的AI视频将已成功创建。让我们看看它是什么样子的。
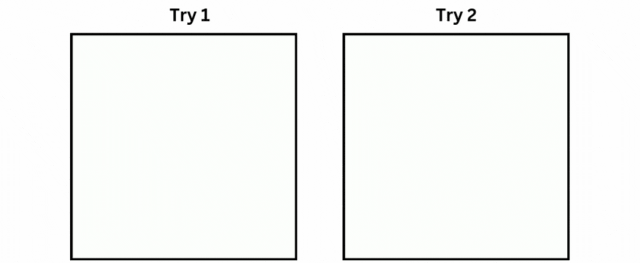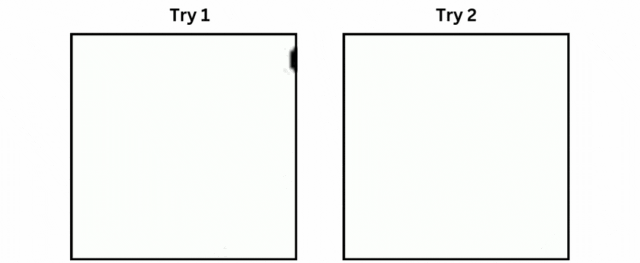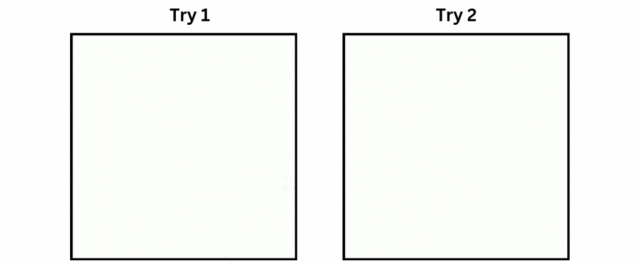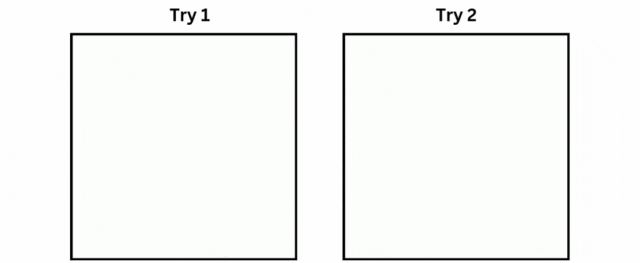
以相同的 epoch 数进行多次训练。在这两种情况下,圆圈都是从底部出现的一半开始。好的部分是我们的模型尝试在这两种情况下执行直立运动。例如,在尝试 1 中,圆圈向对角线移动,然后执行向上运动,而在尝试 2 中,圆圈向对角线移动,同时缩小尺寸。在这两种情况下,圆圈都没有向左移动或完全消失,这是一个好兆头。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









