





本文字数:17039;估计阅读时间:43 分钟
作者:Lionel Palacin
本文在公众号【ClickHouseInc】首发

摘要
本文介绍如何结合 Drain3 和 ClickHouse 的 UDF(用户自定义函数)来对原始应用日志进行自动结构化处理。我们通过识别日志模板并提取关键字段为独立列,在确保日志既可查询又可还原的前提下,实现了近 50 倍的压缩率。
在我们近期的一篇博客中,针对一组示例 Nginx 访问日志数据集,成功实现了超过 170 倍的压缩效果。这一成果依赖于将原始日志转换为结构化数据,并存储到列式数据库中。每一列都经过精细优化和排序,以最大限度提升压缩效率。
这在 Nginx 的场景中相对容易实现,因为它的日志格式结构明确、统一。每一条日志都有固定的格式,使得字段提取和结构化映射变得十分简单。
本文将进一步探索在 ClickHouse 中实现自动化日志聚类,以提高日志压缩率的方法。虽然从技术角度看,这种方式是可行的,但要将其打造成可在生产环境中使用的功能,还面临不少挑战。ClickStack 团队目前正考虑将这一能力纳入后续产品开发计划中。
除了结构化日志:应用日志的挑战
接下来的问题是:我们能否将相同的压缩思路推广到 observability 平台接收的各种应用日志中?相比于像 Nginx 这样格式固定的第三方系统,自定义的应用日志往往缺乏一致性,格式各异,结构也不固定。
因此,核心挑战是如何在海量非结构化日志中自动识别出规律性模式,提取出有价值的信息,并以列式格式进行高效存储。值得注意的是,日志聚类正是一种能够在大规模日志中识别这种模式的有效方法。
本文将介绍如何利用日志聚类,将非结构化的应用日志转化为适合列式存储的结构化数据,并探讨如何将这一过程自动化,以支持生产环境的落地使用。
什么是日志聚类?
日志聚类是一种自动化技术,能够根据日志的结构和内容对相似的日志行进行归类。它的目标是在不依赖人工定义解析规则的前提下,从大规模非结构化日志中发现重复模式。
我们来看一个具体的例子。以下是几条来自某个自定义应用程序的日志:
AddItemAsync called with userId=ea894cf4-a9b8-11f0-956c-4a218c6deb45, productId=0PUK6V6EV0, quantity=4
GetCartAsync called with userId=7f3e16e6-a9f9-11f0-956c-4a218c6deb45
AddItemAsync called with userId=a79c1e20-a9a0-11f0-956c-4a218c6deb45, productId=LS4PSXUNUM, quantity=3
GetCartAsync called with userId=9a89945c-a9f9-11f0-8bd1-ee6fbde68079从这些日志来看,我们可以将它们分为两类,它们各自遵循固定的格式。
第一种模式:AddItemAsync called with userId={*}, productId={*}, quantity={*}
第二种模式:GetCartAsync called with userId={*}
每种日志模式都对应一个聚类,而大括号中的字段(如 {*})表示可以提取为独立列的动态变量,用于结构化存储。这种技术在我们的实验中非常有潜力,接下来我们将尝试如何将它应用到更大规模的日志数据中并实现自动化。
日志聚类的好处远不止提升压缩率。它还能帮助我们及早发现异常模式,通过对相似事件的聚合,大大加快排查故障的速度。不过在本文中,我们主要关注它如何通过结构化重复日志,从而优化存储效率。
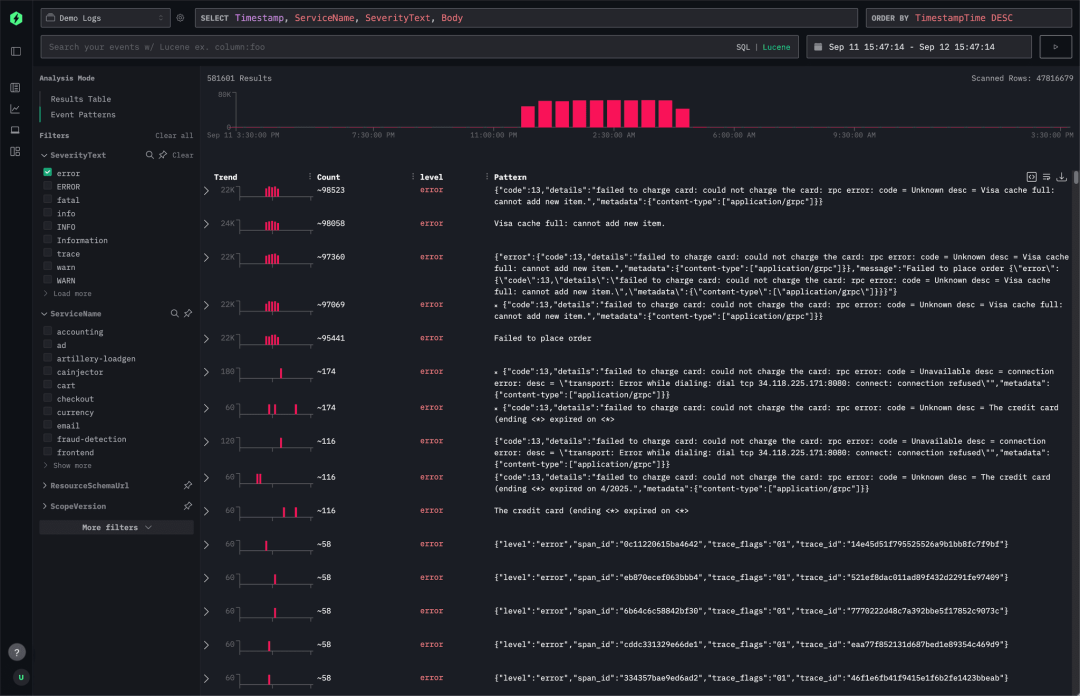
ClickStack 目前已在使用事件模式识别功能,辅助进行根因分析。系统会自动将相似日志归为一类,并追踪这些日志聚类随时间的演变,帮助用户快速定位反复出现的问题,并识别异常发生的时间和位置,从而加速整体日志分析流程。
下面是 HyperDX 平台中事件模式识别的一个示意截图。
使用 Drain3 挖掘日志模式
根据不同的使用需求,实现日志聚类可能涉及构建完整的日志采集处理流程,比如语义和语法比对、情感分析、模式提取等。而在我们的实践中,我们专注于识别日志模板,以便将日志高效结构化存储。Drain3 是完成这项任务的理想工具——这是一个 Python 包,支持对日志流进行实时模板挖掘。ClickStack 中的事件模式识别功能正是基于 Drain3 实现的。
你可以在本地运行 Drain3,亲自体验它如何快速从一组日志中提取出日志模板。
首先,下载一份用于测试的日志样本。这些日志是使用 OpenTelemetry 演示项目生成的。
wget https://datasets-documentation.s3.eu-west-3.amazonaws.com/otel_demo/logs_recommendation.sample接着,我们编写一个简单的 Python 脚本,通过标准输入将日志传入 Drain3 进行挖掘。
#!/usr/bin/env python3
import sys
from collections import defaultdict
from drain3 import TemplateMiner
from drain3.template_miner_config import TemplateMinerConfig
def main():
lines = [ln.strip() for ln in sys.stdin if ln.strip()]
cfg = TemplateMinerConfig(); cfg.config_file = None
miner = TemplateMiner(None, cfg)
counts, templates, total = defaultdict(int), {}, 0
for raw in lines:
r = miner.add_log_message(raw)
cid = r["cluster_id"]; total += 1
counts[cid] += 1
templates[cid] = r["template_mined"]
items = [ (cnt, templates[cid]) for cid, cnt in counts.items() ]
items.sort(key=lambda x: (-x[0], x[1]))
for cnt, tmpl in items:
cov = (cnt / total * 100.0) if total else 0.0
print(f"{cov:.2f}\t{tmpl}")
if __name__ == "__main__":
main()然后运行脚本,对这批日志进行处理。
$ cat logs_recommendation.sample | python3 drain3_min.py
50.01 2025-09-15 <*> INFO [main] [recommendation_server.py:47] <*> <*> resource.service.name=recommendation trace_sampled=True] - Receive ListRecommendations for product <*> <*> <*> <*> <*>
49.99 Receive ListRecommendations for product <*> <*> <*> <*> <*>输出结果显示了两个被识别出的日志模板,以及它们各自覆盖的日志比例。运行效果不错,接下来我们继续在 ClickHouse 中实现这一功能。
在 ClickHouse 中挖掘日志模式
虽然在本地运行 Drain3 可以帮助我们进行测试验证,但最理想的方式是在日志存储所在地——ClickHouse 中直接执行日志模式识别。
ClickHouse 支持通过用户自定义函数(UDF)运行自定义代码,包括 Python 脚本。
下面的示例使用本地部署的 ClickHouse Server,但同样的方式也适用于 ClickHouse Cloud 环境。
部署 UDF
在本地部署 UDF 时,需要通过 XML 文件进行定义(例如:/etc/clickhouse-server/drain3_miner_function.xml)。以下是一个注册 Python 版本 Drain3 日志模板提取函数的示例。该函数接收字符串数组(即原始日志)作为输入,返回对应的日志模板数组作为输出。
<functions>
<function>
<type>executable_pool</type>
<name>drain3_miner</name>
<return_type>Array(String)</return_type>
<return_name>result</return_name>
<argument>
<type>Array(String)</type>
<name>values</name>
</argument>
<format>JSONEachRow</format>
<command>drain3_miner.py</command>
<execute_direct>1</execute_direct>
<pool_size>1</pool_size>
<max_command_execution_time>100</max_command_execution_time>
<command_read_timeout>100000</command_read_timeout>
<send_chunk_header>false</send_chunk_header>
</function>
</functions>随后,将 Python 脚本保存到 /var/lib/clickhouse/user_scripts/drain3_miner.py。这份脚本相较前文的示例更为完整,因篇幅原因此处省略,完整源码可通过提供的链接查看(https://raw.githubusercontent.com/ClickHouse/examples/refs/heads/main/blog-examples/log_clustering/drain3_miner.py)。
同时,请确保在 ClickHouse 服务器上已经全局安装了 Drain3 Python 包,以便所有用户都可调用。在 ClickHouse Cloud 中,只需提供一个包含依赖项的 requirements.txt 文件,即可完成环境准备。
# Install drain3 for all users
sudo pip install drain3
# Verify the clickhouse user has access to it
sudo -u clickhouse python3 -c "import drain3"摄取日志数据
为了演示整个流程,我们准备了一组示例日志数据集,结合了 Nginx 访问日志和来自 OpenTelemetry 演示项目中多个服务的日志。以下 SQL 示例展示了如何将这些日志写入一个简单的表中。
-- Create table
CREATE TABLE raw_logs
(
`Body` String,
`ServiceName` String
)
ORDER BY tuple();
-- Insert nginx access logs
INSERT INTO raw_logs SELECT line As Body, 'nginx' as ServiceName FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/http_logs/nginx-66.log.gz', 'LineAsString')
-- Insert recommendation service logs
INSERT INTO raw_logs SELECT line As Body, 'recommendation' as ServiceName FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/otel_demo/logs_recommendation.log.gz', 'LineAsString')
-- Insert cart service logs
INSERT INTO raw_logs SELECT line As Body, 'cart' as ServiceName FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/otel_demo/logs_cart.log.gz', 'LineAsString')挖掘日志模板
在 UDF 部署完成并将多服务日志导入到统一表后,我们可以正式开始实验。下图展示了整个日志处理流程的概览。

接下来我们来看具体的执行方式。以下 SQL 查询展示了如何从 recommendation service 的日志中提取日志模板。
WITH drain3_miner(groupArray(Body)) AS results
SELECT
JSONExtractString(arrayJoin(results), 'template') AS template,
JSONExtractUInt(arrayJoin(results), 'count') AS count,
JSONExtractFloat(arrayJoin(results), 'coverage') AS coverage
FROM
(
SELECT Body
FROM raw_logs
WHERE (ServiceName = 'recommendation') AND (randCanonical() < 0.1)
LIMIT 10000
)
FORMAT VERTICALRow 1:
──────
template: <*> <*> INFO [main] [recommendation_server.py:47] <*> <*> resource.service.name=recommendation trace_sampled=True] - Receive ListRecommendations for product <*> <*> <*> <*> <*>
count: 5068
coverage: 50.68
Row 2:
──────
template: Receive ListRecommendations for product <*> <*> <*> <*> <*>
count: 4931
coverage: 49.31
Row 3:
──────
template: 2025-09-27 02:00:00,319 WARNING [opentelemetry.exporter.otlp.proto.grpc.exporter] [exporter.py:328] [trace_id=0 span_id=0 resource.service.name=recommendation trace_sampled=False] - Transient error StatusCode.UNAVAILABLE encountered while exporting logs to my-hyperdx-hdx-oss-v2-otel-collector:4317, retrying in 1s.
count: 1
coverage: 0.01可以看到,仅两个模板就已经覆盖了 recommendation service 中 99.99% 的日志数据。我们将以这两个模板作为结构化基础,而那些未被覆盖的长尾日志可以原样保留,以备后续分析使用。
日志实时结构化处理
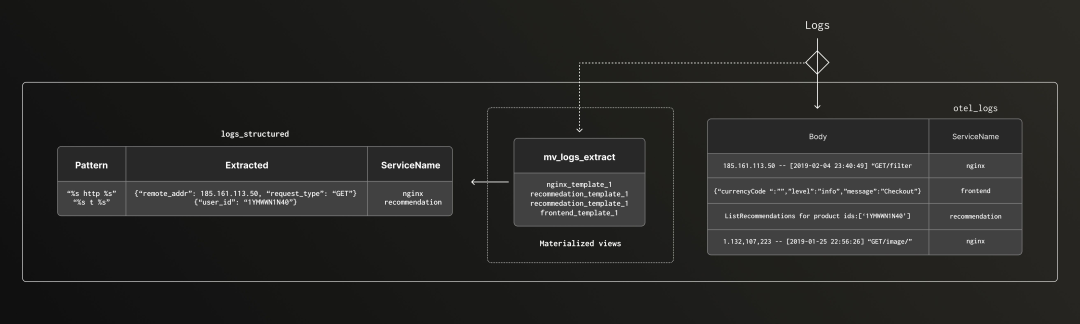
在掌握了如何识别并提取日志模板后,我们便可以将这些模板用于实时结构化处理,将新进入系统的原始日志即时转化为结构化数据,从而实现高效存储。
下图展示了我们在实际部署中所采用的大规模日志采集与结构化处理流程的架构概览。
应用日志模板
我们创建了一个物化视图(Materialized View),它会在每次有新日志写入原始日志表时自动触发执行。该视图基于之前识别出的日志模板,从每条日志中提取出变量字段,并将这些字段结构化存储。在这个示例中,所有结构化日志会被写入到同一个目标表中,字段以 Map 类型(键值对)的形式保存。
在创建视图前,首先需要定义目标表 logs_structured。
CREATE TABLE logs_structured
(
`ServiceName` LowCardinality(String),
`TemplateNumber` UInt8,
`Extracted` Map(LowCardinality(String), String)
) ORDER BY (ServiceName, TemplateNumber)接下来我们定义视图。以下是一个只支持单个服务的最小实现版本,若想支持所有服务,可参考链接中的完整 SQL 示例(https://raw.githubusercontent.com/ClickHouse/examples/refs/heads/main/blog-examples/log_clustering/mv.sql)。
CREATE MATERIALIZED VIEW IF NOT EXISTS mv_logs_structured_min
TO logs_structured
AS
SELECT
ServiceName,
/* which template matched */
multiIf(m1, 1, m2, 2, 0) AS TemplateNumber,
/* extracted fields as Map(LowCardinality(String), String) */
CAST(
multiIf(
m1,
map(
'date', g1_1,
'time', g1_2,
'service_name', g1_3,
'trace_sampled', g1_4,
'prod_1', g1_5,
'prod_2', g1_6,
'prod_3', g1_7,
'prod_4', g1_8,
'prod_5', g1_9
),
m2,
map(
'prod_1', g2_1,
'prod_2', g2_2,
'prod_3', g2_3,
'prod_4', g2_4,
'prod_5', g2_5
),
map() -- else: empty map
),
'Map(LowCardinality(String), String)'
) AS Extracted
FROM
(
/* compute once per row */
WITH
'^([^\\s]+) ([^\\s]+) INFO \[main\] \[recommendation_server.py:47\] \[trace_id=([^\\s]+) span_id=([^\\s]+) resource\.service\.name=recommendation trace_sampled=True\] - Receive ListRecommendations for product ids:\[([^\\s]+) ([^\\s]+) ([^\\s]+) ([^\\s]+) ([^\\s]+)\]$' AS pattern1,
'^Receive ListRecommendations for product ([^\\s]+) ([^\\s]+) ([^\\s]+) ([^\\s]+) ([^\\s]+)$' AS pattern2
SELECT
*,
match(Body, pattern1) AS m1,
match(Body, pattern2) AS m2,
extractAllGroups(Body, pattern1) AS g1,
extractAllGroups(Body, pattern2) AS g2,
/* pick first (and only) match’s capture groups */
arrayElement(arrayElement(g1, 1), 1) AS g1_1,
arrayElement(arrayElement(g1, 1), 2) AS g1_2,
arrayElement(arrayElement(g1, 1), 3) AS g1_3,
arrayElement(arrayElement(g1, 1), 4) AS g1_4,
arrayElement(arrayElement(g1, 1), 5) AS g1_5,
arrayElement(arrayElement(g1, 1), 6) AS g1_6,
arrayElement(arrayElement(g1, 1), 7) AS g1_7,
arrayElement(arrayElement(g1, 1), 7) AS g1_8,
arrayElement(arrayElement(g1, 1), 7) AS g1_9,
arrayElement(arrayElement(g2, 1), 1) AS g2_1,
arrayElement(arrayElement(g2, 1), 2) AS g2_2,
arrayElement(arrayElement(g2, 1), 3) AS g2_3,
arrayElement(arrayElement(g2, 1), 4) AS g2_4,
arrayElement(arrayElement(g2, 1), 5) AS g2_5
FROM raw_logs where ServiceName='recommendation'
) WHERE m1 OR m2;不过在实际应用中,这种方式可能存在扩展性问题——系统会对每条日志尝试匹配所有模板,即使某些模板根本无法匹配。稍后我们会介绍一种更高效的优化方案。
为了触发视图执行,我们重新将日志数据写入 raw_logs 表中。
CREATE TABLE raw_logs_tmp as raw_logs
EXCHANGE TABLES raw_logs AND raw_logs_tmp
INSERT INTO raw_logs SELECT * FROM raw_logs_tmp启用完整版本的物化视图后,我们可以在 logs_structured 表中查看结构化结果。对每个服务的大部分日志都成功完成了解析。对于无法匹配的日志,系统将其标记为 TemplateNumber=0,这部分日志可以后续单独处理。
SELECT
ServiceName,
TemplateNumber,
count()
FROM logs_structured
GROUP BY
ServiceName,
TemplateNumber
ORDER BY
ServiceName ASC,
TemplateNumber ASC┌─ServiceName────┬─TemplateNumber─┬──count()─┐
│ cart │ 0 │ 66162 │
│ cart │ 3 │ 76793139 │
│ cart │ 4 │ 61116119 │
│ cart │ 5 │ 41877952 │
│ cart │ 6 │ 1738375 │
│ nginx │ 0 │ 16 │
│ nginx │ 7 │ 66747274 │
│ recommendation │ 0 │ 5794 │
│ recommendation │ 1 │ 10537999 │
│ recommendation │ 2 │ 10565640 │ └────────────────┴────────────────┴──────────┘查询时还原原始日志
虽然我们已经实现了日志字段的自动提取,但过程中丢失了原始日志内容,这对于排查和审计场景来说并不理想。好在 ClickHouse 支持一个叫做 ALIAS 的功能,可以很好地解决这个问题。
别名列(Alias Column)允许我们定义一个只在查询时计算的表达式。它不会占用磁盘空间,仅在需要时动态生成结果。
我们可以借助这一特性,在查询时根据已知的日志模板,还原出原始的日志内容。
具体做法是,在 logs_structured 表中添加一个别名列,用来拼接还原日志内容。
ALTER TABLE logs_structured
ADD COLUMN Body String ALIAS multiIf(
TemplateNumber=1,
format('{0} {1} INFO [main] [recommendation_server.py:47] resource.service.name={2} trace_sampled={3}] - Receive ListRecommendations for product {4} {5} {6} {7} {8}',Extracted['date'],Extracted['time'],Extracted['service_name'],Extracted['trace_sampled'],Extracted['prod_1'],Extracted['prod_2'],Extracted['prod_3'],Extracted['prod_4'],Extracted['prod_5']),
TemplateNumber=2,
format('Receive ListRecommendations for product {0} {1} {2} {3} {4}',Extracted['prod_1'],Extracted['prod_2'],Extracted['prod_3'],Extracted['prod_4'],Extracted['prod_5']),
TemplateNumber=3,
format('GetCartAsync called with userId={0}',Extracted['user_id']),
TemplateNumber=4,
'info: cart.cartstore.ValkeyCartStore[0]',
TemplateNumber=5,
format('AddItemAsync called with userId={0}, productId={1}, quantity={2}', Extracted['user_id'], Extracted['product_id'], Extracted['quantity']),
TemplateNumber=6,
format('EmptyCartAsync called with userId={0}',Extracted['user_id']),
TemplateNumber=7,
format('{0} - {1} [{2}] "{3} {4} {5}" {6} {7} "{8}" "{9}"', Extracted['remote_addr'], Extracted['remote_user'], Extracted['time_local'], Extracted['request_type'], Extracted['request_path'], Extracted['request_protocol'], Extracted['status'], Extracted['size'], Extracted['referer'], Extracted['user_agent']),
'')这样一来,我们就可以像最初那样查询日志,并得到接近原始格式的输出。
SELECT Body
FROM logs_structured
WHERE ServiceName = 'nginx'
LIMIT 1
FORMAT verticalRow 1:
──────
Body: 66.249.66.92 - - [2019-02-10 03:10:02] "GET /static/images/amp/third-party/footer-mobile.png HTTP/1.1" 200 62894 "-" "Googlebot-Image/1.0"
接着将此与原始裸日志进行比较。
SELECT Body
FROM raw_logs
WHERE Body = '66.249.66.92 - - [2019-02-10 03:10:02] "GET /static/images/amp/third-party/footer-mobile.png HTTP/1.1" 200 62894 "-" "Googlebot-Image/1.0"'
LIMIT 1
FORMAT verticalRow 1:
──────
Body: 66.249.66.92 - - [2019-02-10 03:10:02] "GET /static/images/amp/third-party/footer-mobile.png HTTP/1.1" 200 62894 "-" "Googlebot-Image/1.0"压缩效果评估
我们已经跑通了从原始日志到结构化数据的完整流程,并且可以在查询时无损还原出原始日志。那么,这一流程对压缩效果的实际影响如何呢?
我们对 logs_structured 表和 raw_logs 表进行对比,以评估结构化处理带来的实际收益。
在此次实验中,仅约 0.03% 的日志未能被成功解析,因此对整体压缩效果几乎没有影响。
SELECT
`table`,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size
FROM system.parts
WHERE ((`table` = 'raw_logs') OR (`table` = 'logs_structured')) AND active
GROUP BY `table`
FORMAT VERTICALRow 1:
──────
table: raw_logs
compressed_size: 2.00 GiB
uncompressed_size: 37.67 GiB
Row 2:
──────
table: logs_structured
compressed_size: 1.71 GiB
uncompressed_size: 29.95 GiB不过,初步结果略显平淡:虽然数据已经以列式格式存储,压缩率的提升却不明显。
Uncompressed original size: 37.67 GiB
Compressed size on raw logs: 2.00 GiB - (18x compression ratio)
Compressed size on structured logs: 1.71 GiB - (22x compression ratio)实际计算结果显示,压缩比约为 3 倍。虽然距离目标还有差距,但这一现象也在预料之中——我们在上一篇文章中提到,压缩效率的提升主要依赖于为字段选择合适的数据类型,以及对数据进行合理排序。
按服务分表存储
接下来我们进一步深入实验,应用之前总结的优化策略。我们将结构化后的日志按服务拆分存储,每个服务对应一张独立的表。这样我们就能按需定制每张表的数据类型和排序规则。
实现方式与原先的“统一存表”类似,只是现在改为每个服务分别建立一张数据表和一个物化视图。这种拆分方式还提升了处理效率——每条日志只会与本服务相关的模板进行匹配,而无需遍历全部模板,系统可扩展性显著增强。
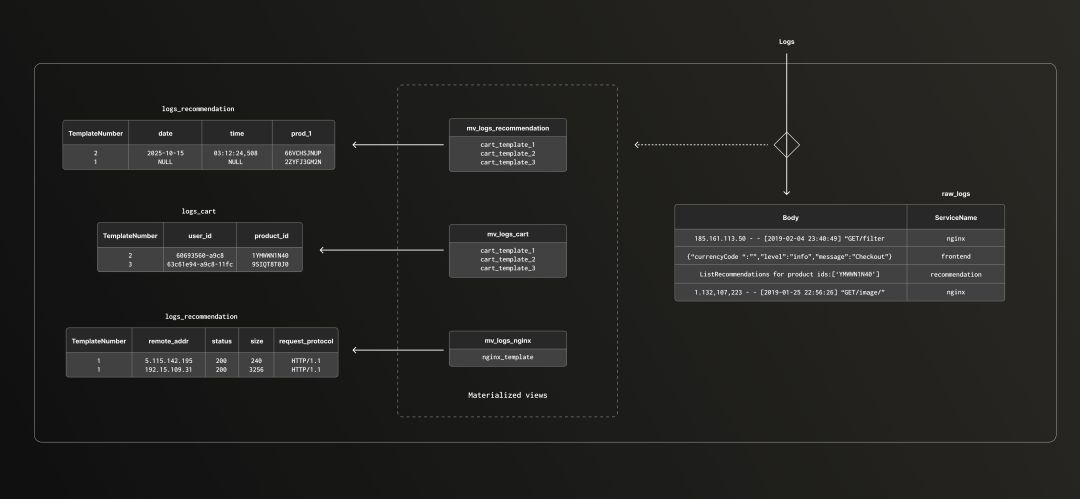
我们以 cart 服务为例,查看其表结构和对应的物化视图。
-- Create table for cart service logs
CREATE TABLE logs_service_cart
(
TemplateNumber UInt8,
`user_id` Nullable(UUID),
`product_id` String,
`quantity` String,
Body ALIAS multiIf(
TemplateNumber=1, format('GetCartAsync called with userId={0}',user_id),
TemplateNumber=2, 'info: cart.cartstore.ValkeyCartStore[0]',
TemplateNumber=3, format('AddItemAsync called with userId={0}, productId={1}, quantity={2}', user_id, product_id, quantity),
TemplateNumber=4, format('EmptyCartAsync called with userId={0}',user_id),
'')
)
ORDER BY (TemplateNumber, product_id, quantity)
-- Create materialized view for cart service logs
CREATE MATERIALIZED VIEW IF NOT EXISTS mv_logs_cart
TO logs_service_cart
AS
SELECT
multiIf(m1, 1, m2, 2, m3, 3, 0) AS TemplateNumber,
multiIf(m1, g1_1, m2, Null, m3, g3_1, m4, g4_1, Null) AS user_id,
multiIf(m1, '', m2, '', m3, g3_2, '') AS product_id,
multiIf(m1, '', m2, '', m3, g3_3, '') AS quantity
FROM
(
WITH
'^[\\s]*GetCartAsync called with userId=([^\\s]*)$' AS pattern1,
'^info\: cart.cartstore.ValkeyCartStore\[0\]$' AS pattern2,
'^[\\s]*AddItemAsync called with userId=([^\\s]+), productId=([^\\s]+), quantity=([^\\s]+)$' AS pattern3,
'^[\\s]*EmptyCartAsync called with userId=([^\\s]*)$' AS pattern4
SELECT
*,
match(Body, pattern1) AS m1,
match(Body, pattern2) AS m2,
match(Body, pattern3) AS m3,
match(Body, pattern4) AS m4,
extractAllGroups(Body, pattern1) AS g1,
extractAllGroups(Body, pattern2) AS g2,
extractAllGroups(Body, pattern3) AS g3,
extractAllGroups(Body, pattern4) AS g4,
arrayElement(arrayElement(g1, 1), 1) AS g1_1,
arrayElement(arrayElement(g3, 1), 1) AS g3_1,
arrayElement(arrayElement(g3, 1), 2) AS g3_2,
arrayElement(arrayElement(g3, 1), 3) AS g3_3,
arrayElement(arrayElement(g4, 1), 1) AS g4_1
FROM raw_logs where ServiceName='cart'
);针对不同类型的日志内容,我们可以自定义字段类型和排序键。对于包含多个日志模板的服务,排序键的第一列通常是模板编号(Template Number),这样可以将结构相似的日志行分组,有利于压缩算法进一步发挥效能。
你可以在此链接中查看每个服务独立建表和视图的完整实现方式(https://raw.githubusercontent.com/ClickHouse/examples/refs/heads/main/blog-examples/log_clustering/one_table_service.sql)。
当所有结构化日志都分别存入对应服务的独立表中后,我们重新评估压缩比。
WITH (
SELECT sum(data_uncompressed_bytes)
FROM system.parts
WHERE (`table` = 'raw_logs') AND active
) AS raw_uncompressed
SELECT
label AS `table`,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_bytes,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_bytes,
sum(rows) AS nb_of_rows,
toUInt32(round(raw_uncompressed / sum(data_compressed_bytes))) AS compression_from_raw
FROM
(
SELECT
if(match(`table`, '^logs_service_'), 'logs_service_*', `table`) AS label,
data_uncompressed_bytes,
data_compressed_bytes,
rows
FROM system.parts
WHERE active AND ((`table` IN ('raw_logs', 'logs_structured')) OR match(`table`, '^logs_service_'))
)
GROUP BY label
ORDER BY label ASC┌─table───────────┬─uncompressed─┬─compressed─┬─nb_of_rows─┬─compression_from_raw─┐
│ logs_service_* │ 16.58 GiB │ 865.16 MiB │ 269448454 │ 45 │
│ logs_structured │ 29.95 GiB │ 1.71 GiB │ 269448470 │ 22 │
│ raw_logs │ 37.71 GiB │ 2.01 GiB │ 269448470 │ 19 │ └─────────────────┴──────────────┴────────────┴────────────┴──────────────────────┘这一次,压缩效果显著提升。在当前配置下,我们实现了最高可达 45 倍的压缩率。
此外,ClickHouse 还支持使用 merge 函数对多张表进行透明查询。
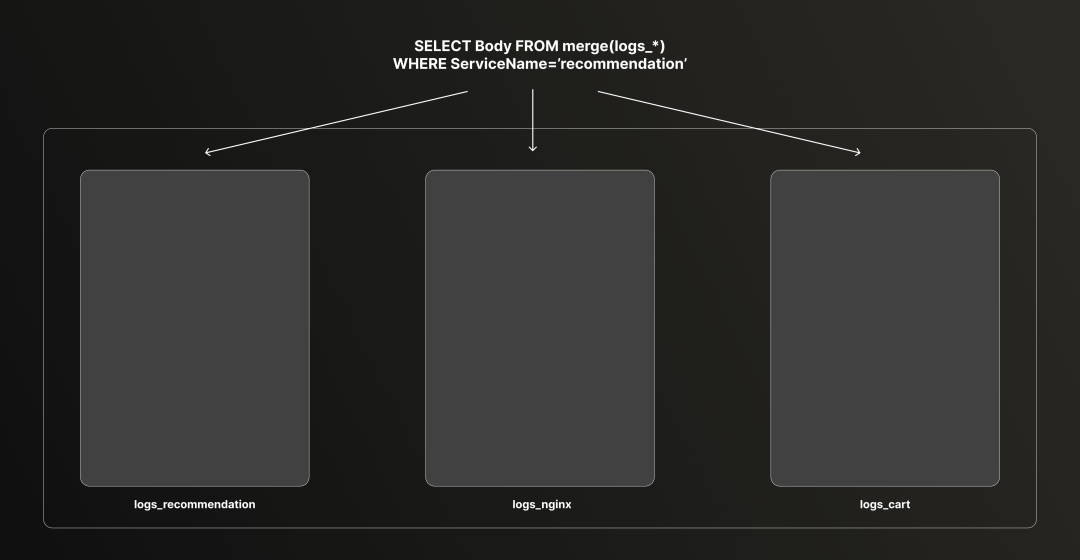
下面是相应的 SQL 查询语句。每张表都包含自身的日志正文字段(Body),因此可以轻松获取任何服务的原始日志内容。
SELECT Body
FROM merge(currentDatabase(), '^logs_service_')
ORDER BY rand() ASC
LIMIT 10
FORMAT TSVinfo: cart.cartstore.ValkeyCartStore[0]
AddItemAsync called with userId={userId}, productId={productId}, quantity={quantity}
AddItemAsync called with userId=6dd06afe-a9da-11f0-8754-96b7632aa52f, productId=L9ECAV7KIM, quantity=4
info: cart.cartstore.ValkeyCartStore[0]
GetCartAsync called with userId=c6a2e0fc-a9e5-11f0-a910-e6976c512022
info: cart.cartstore.ValkeyCartStore[0]
GetCartAsync called with userId=0745841e-a970-11f0-ae33-92666e0294bc
info: cart.cartstore.ValkeyCartStore[0]
84.47.202.242 - - [2019-02-21 05:01:17] "GET /image/32964?name=bl1189-13.jpg&wh=300x300 HTTP/1.1" 200 8914 "https://www.zanbil.ir/product/32964/63521/%D9%85%D8%AE%D9%84%D9%88%D8%B7-%DA%A9%D9%86-%D9%85%DB%8C%D8%AF%DB%8C%D8%A7-%D9%85%D8%AF%D9%84-BL1189" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0"
GetCartAsync called with userId={userId}总结
通过日志聚类将原始日志自动转化为结构化数据,有效提升了日志的压缩效率。虽然还未达到上一篇文章中对 Nginx 日志实现的 178 倍压缩比,但考虑到应用日志格式不统一的现实情况,能实现这一结果已相当不易。
更重要的是,在不牺牲任何数据精度的前提下,我们通过提取关键字段为列,不仅实现了接近 50 倍的压缩效果,还大幅提升了日志的查询灵活性。这证明结构化日志处理既能提升性能,也有助于数据保真。
Drain3 在日志模板识别方面表现出色,配合 ClickHouse 的 UDF 功能,可以构建出从日志采集到结构化入库的全自动处理链路。
不过,这一流程目前尚未完全自动化。比如,对于那些未能成功解析的“长尾”日志,我们还未进行处理。后续可以考虑将它们单独存入其他表中,既保留可观测性,又不影响结构化数据的整洁性。
尽管本次工作仍处于探索阶段,但它为未来在大规模日志系统中实现自动化聚类与压缩优化,打下了坚实的基础。它也有望成为 ClickStack 下一代日志处理组件的重要组成部分。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









