





本文字数:5671;估计阅读时间:15 分钟
作者:Dmitry Pavlov
本文在公众号【ClickHouseInc】首发

在前两篇关于构建 ClickHouse 内部数据仓库的博客中(https://clickhouse.com/blog/building-a-data-warehouse-with-clickhouse)(https://clickhouse.com/blog/building-a-data-warehouse-with-clickhouse-part-2),我们分享了从一个轻量分析系统演进为企业级数据平台的过程。目前该平台已经服务超过 300 位用户,接入数十个数据源,压缩后的数据规模达到 2.1 PB。
今天,我想分享这个演进过程中的下一阶段:我们是如何从传统的 BI 驱动转型为以 AI 为先的数据仓库系统,并让它承担起约 70% 的内部分析工作负载。
看完这篇文章,你将了解到,如何让用户在不写一行 SQL 的前提下,通过自然语言提问就能获取数据洞察。
说实话,就在不到一年前,我还是个坚定的 AI 怀疑者。作为一名从业 15 年的数据仓库工程师,我早期试用过 LLM 与数据系统集成,但结果令人失望:幻觉频发、上下文缺失、无法处理复杂业务逻辑——这些问题让我完全否定了 AI 在企业级分析中的实用性。但有时候,承认自己错了,真的很开心。
在 AI 出现前:BI 工作流中的瓶颈
要理解这个转变的意义,我们必须回顾 AI 推入前团队与数据仓库的交互方式。尽管我们依托 ClickHouse Cloud 和 Superset 打造了强大的数据基础设施,但传统分析流程依然让“提问题”与“得答案”之间充满摩擦:
-
工程团队时常需要花大量时间写复杂的 SQL,来排查服务性能问题。比如排查某客户服务为何异常,就要将控制面(Control Plane)的服务信息、数据面(Data Plane)的查询性能指标、自动扩缩日志和 Salesforce 的支持工单进行多表关联。工程师不仅要熟记数据结构,还要写出跨 4-5 张表的 JOIN,设置正确时间窗口,往往还要反复迭代。一个原本几分钟能解答的问题,常常变成半小时起步的 SQL 之旅。
-
销售团队在客户会议中也常面临即时数据查询需求。例如客户会问:“我们使用量在行业中处于哪个水平?”要回答这个问题,需要把使用数据与账户信息关联,按行业和公司规模分类、计算分位数、快速出图。销售工程师要么打断分析师时间临时求助,要么自己硬着头皮啃数据模型,严重影响与客户的互动效率。
-
产品团队的分析需求更加深入。他们需要做留存分析、功能使用研究等工作,比如分析哪些用户引导步骤与 90 天留存率高度相关。这样的研究往往涉及多个数据集市、窗口函数、复杂指标计算,有时还要先建中间表分步分析。一次有价值的产品洞察,往往要花掉资深分析师整整一天。
-
财务团队要定期向董事会和投资人提供报告,要求精确计算 MRR、流失率、生命周期价值、收入预测等指标。不仅对 SQL 技术要求高,还要理解所有业务逻辑 —— 如积分兑换方式、不同套餐的收入归属、排除特殊组织等细节。出错的容忍度为零,意味着每个数字都要反复手动验证。
-
成本优化团队则承担了最复杂的分析。他们需要将 ClickHouse Cloud 的使用数据与 AWS、GCP、Azure 的账单做关联,判断某个客户使用激增是被系统扩容合理应对,还是引发了成本溢出。这类分析既要 JOIN 多个云商账单,也要结合服务映射、资源分配策略、单位经济性模型,分析门槛极高。
最终形成了一个典型的 BI 瓶颈:要么每个团队都培养出 SQL 专家,牺牲主业效率;要么将问题排队交由少量分析师处理。即使 Superset 提供了界面简洁的分析工具,但对于大多数人而言,面对复杂数据模型与业务逻辑,自助分析仍是可望不可即的目标。
推动转型的关键因素
尽管我们已经面临明显的分析瓶颈,但数据仓库长期依然是传统 BI 驱动,并没有真正把任何工作负载交给 AI。原因并不难理解:企业级数据环境中真正阻碍 AI 落地的难题非常顽固——模型输出不够可靠、缺乏统一的数据源连接方式、无法在复杂分析链路中保持业务上下文。在 2024 年之前,试图用大语言模型承担严肃的数据仓库分析,往往带来的不是洞察,而是更多困惑。直到 2024 年末,几项关键技术的集中突破,彻底改变了 AI 与数据结合的可能性。
模型能力的飞跃
Anthropic 发布的 Claude 3.5 Sonnet,以及之后的 Claude 3.7 和 4.0,使大语言模型在处理技术任务方面迈入了全新的阶段。与过往模型不同,新一代 Claude 在许多核心能力上表现突出,例如:
-
能够编写包含 JOIN、窗口函数及数据库特定语法的复杂 SQL
-
能够根据数据库的错误反馈自动修正查询
-
理解表的规模,进而生成带有合理过滤条件的高效 SQL
-
可以即时生成交互式图表和可视化
-
可以整合来自多个数据源的大量业务上下文
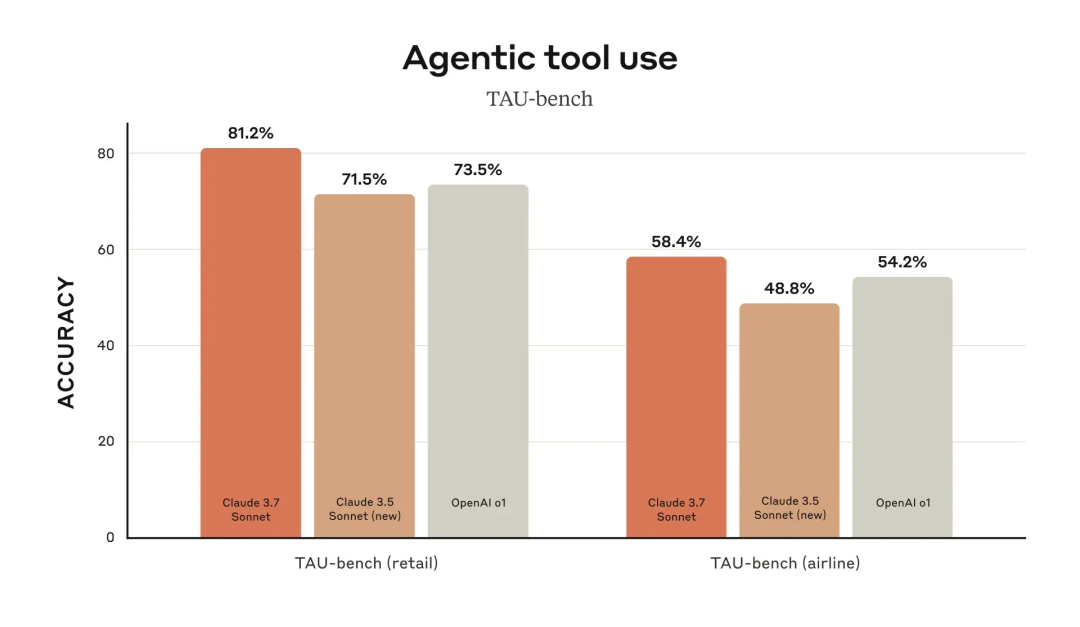
图片来自 Claude 3.7 发布文章(https://www.anthropic.com/news/claude-3-7-sonnet)
MCP:关键的集成层出现了
2024 年 11 月,Anthropic 推出了 Model Context Protocol(MCP)(https://github.com/modelcontextprotocol),这是一个让大语言模型能安全、统一地连接外部数据源和工具的开源标准。它恰好解决了我们长期以来的难题:如何在避免厂商绑定的前提下,为多个数据源提供结构化、可靠的访问方式。
MCP 发布后短短数周内,社区就涌现出数百个 MCP 服务器,覆盖数据库、文件系统、API 等各种资源。看到它的潜力后,我们很快开发了自己的 ClickHouse MCP 服务器,让组织可以更轻松、更标准化地将 ClickHouse 实例接入 LLM。
打好基础:不仅仅是把数据库接通
将大语言模型(LLM)接入数据仓库只是第一步。要真正构建一个可靠、可规模化的企业级 AI 优先分析平台,还需要打好一系列基础,解决多个关键问题:
构建全面的业务术语体系
数据如果缺乏上下文支持,就难以真正发挥价值。对于 LLM 而言,这一问题更为严重。我们早已搭建了一套内部的数据知识库,使用 MDBook 构建,系统记录了各数据集市中关键字段的元信息,涵盖:
-
字段定义及其业务含义
-
字段可能的取值范围和数据区间
-
数据背后的业务流程
-
跨系统实体之间的关联关系
真正的突破在于,我们通过 GitHub 和文件系统 MCP 服务器集成,让这套业务术语体系可以被 LLM 实时访问,使 AI 助手能够在处理分析任务时准确获取相关背景文档。
强化数据质量管理
人类分析师在面对数据异常时往往具备一定的判断与容错能力,而 LLM 的行为却高度依赖数据的准确性。比如,缺失一个 customer_id 字段,分析师可能会察觉异常,但 LLM 却可能基于错误数据得出完全错误的结论。为此,我们在 AI 之前就已建立起成熟的数据质量保障机制,包括:
-
自动化的数据校验规则
-
完整的数据血缘追踪体系
-
实时的数据质量监控系统
-
明确的数据新鲜度(时效性)指标
这些质量控制流程大多在构建 DBT 模型时自动完成,无需额外操作。
企业级自托管 LLM 接入层
我们始终坚持避免厂商绑定,因此希望搭建一个企业级、可自托管的 AI 交互平台。它必须具备以下能力:
-
支持对接多个 LLM 提供商
-
原生集成 MCP 服务器协议
-
提供如 SSO、审计日志等企业特性
-
支持生成可视化图表并嵌入展示
-
实现对话共享与团队协作能力
在评估了多个方案之后,我们最终选择了 LibreChat —— 一个开源的 ChatGPT 替代方案,不仅满足了所有功能需求,还保留了根据实际需要灵活切换 LLM 后端的自由。
架构揭秘:DWAINE 的诞生
我们构建了 DWAINE(Data Warehouse AI Natural Expert)—— 一位内部 AI 助手,正在重塑我们与数据仓库之间的交互方式。
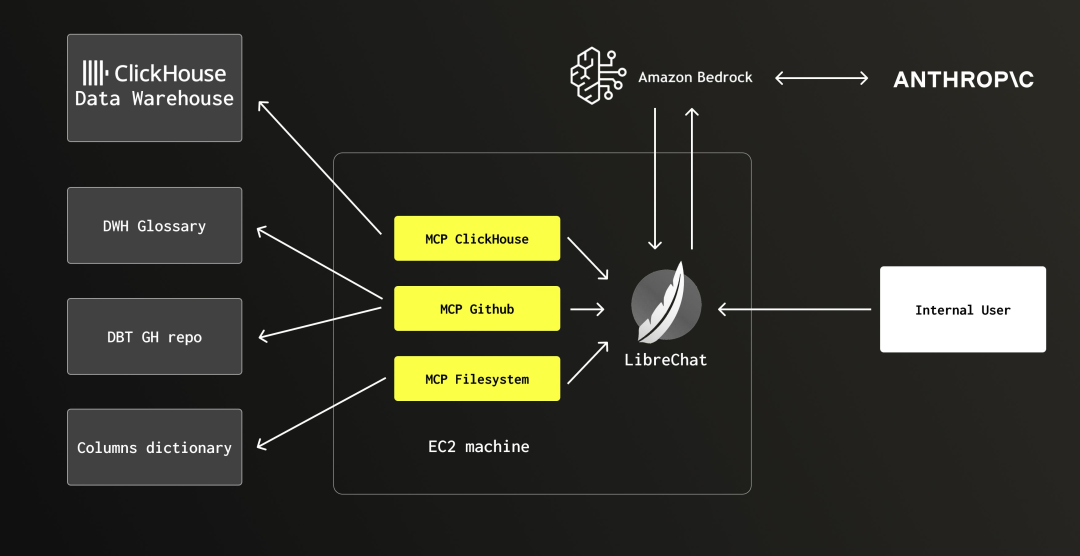
图 1:DWAINE 系统架构
整体架构由以下几个关键部分组成:
|
组件 |
技术 |
用途 |
|
UI Layer |
LibreChat |
用户界面、聊天管理、可视化产物渲染 |
|
LLM Provider |
Anthropic Claude 4.0 |
自然语言处理、SQL 生成与分析。我们通过 AWS Bedrock 使用 LLM,以实现账单整合、跨区域推理等功能。 |
|
Integration Layer |
MCP Servers |
ClickHouse MCP 服务器:访问数据仓库 ;GitHub MCP 服务器:获取 DBT 模型与业务术语表中的上下文;文件系统 MCP 服务器:获取动态字段字典 |
|
Data Warehouse |
ClickHouse Cloud |
主分析数据库 |
|
Documentation |
GitHub + filesystem |
业务术语表、字段定义、业务流程文档 |
安全与隐私保障
DWAINE 的设计充分考虑了企业级安全需求,访问权限严格限制在特定的核心数据集市,包括:
-
已匿名化的服务使用指标
-
账单与积分消耗数据
-
内部销售与运营相关指标
特别需要强调的是,DWAINE 完全不会访问:
-
客户个人信息(如姓名、邮箱、地址等)
-
客户数据本身(ClickHouse Cloud 中所有客户数据均默认加密)
-
内部敏感通信内容或公司战略资料
这一安全架构延续了我们一贯的数据仓库治理策略:仅收集元数据,从不触及实际客户数据。
运行效果:数据助理的“真实力”
上线仅 6 个月,DWAINE 的使用数据已非常可观,更重要的是它带来的“质变”。通过自然语言问答方式,它让销售、财务、运营等非技术岗位也能自主获得关键业务数据,无需 SQL,无需理解底层数据结构或复杂图表,大幅提升了整体数据获取效率。
数据访问的普及化,让我们的 3 人数据仓库团队工单压力减少了 50%-70%,分析师得以将更多时间投入到高价值、策略性更强的分析任务中。尤其是 Sales 与 Support 团队,他们经常需要快速响应简单却紧急的问题,从中获得了最大的效率红利。
目前,已有超过 250 名内部员工使用 DWAINE,每天产生 50-70 场对话,总消息量超过 200 条。
DWAINE 擅长回答的问题类型
以下是我们团队日常向 DWAINE 提出的真实问题示例:
-
“展示 2025 年 2 月内存使用率最高的前五个服务”
-
“基于过去三个月的数据,为 AWS us-east-1 区域中的存储量生成月度预测,考虑季节性趋势”
-
“展示过去五个月的 MRR 曲线,按销售人员堆叠显示,展示前五名销售,其余归为‘其他’,并排除 EMEA 区域”
-
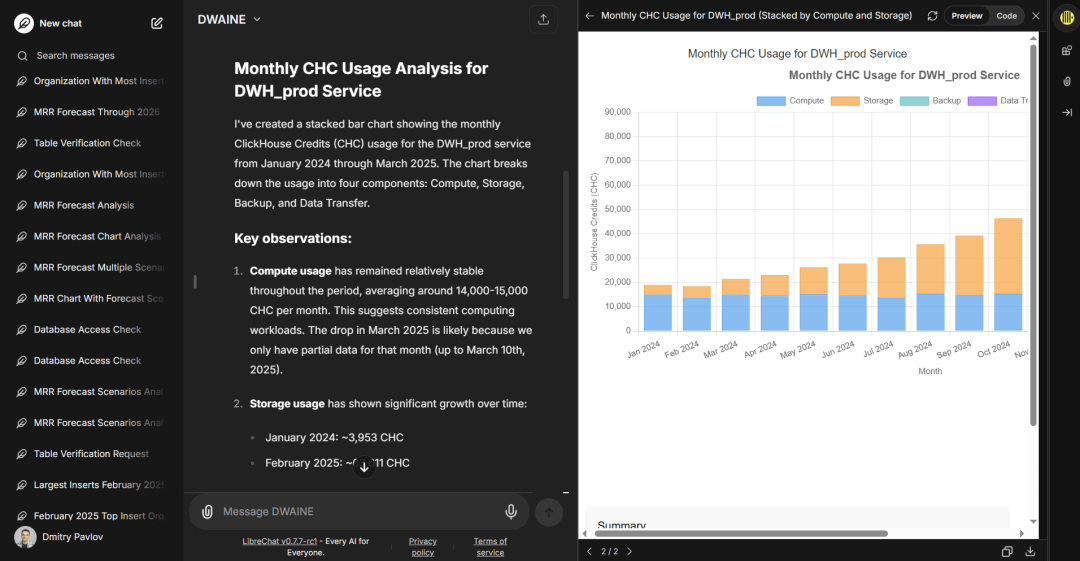
“找出 2025 年插入查询最多的客户,并为其绘制柱状图,按服务名称堆叠展示每月 SELECT 查询次数”
这些查询的背后,往往需要多张表的 JOIN 操作、复杂的聚合逻辑,以及特定的业务规则。如果手动编写,分析师通常需要花费 15 到 30 分钟来构建并验证逻辑。
图 2:示例回答与图表展示
AI vs BI:功能分界的 70/30 原则
虽然 DWAINE 已覆盖约 70% 的内部分析请求,但仍有约 30% 的使用场景保留在 Superset 等传统 BI 工具中,主要集中在以下几类:
标准化指标与重复性报表
这类需求高度稳定,数据查询方式和展示形式固定,用户可通过预设的仪表盘反复查看,无需每次都通过 AI 生成相同结果。相比 AI,书签仪表盘在响应速度和一致性上更具优势,同时也不会造成数据团队负担。
正式认证的财务指标
包括需提交董事会审议的核心 KPI、面向监管机构的合规报表、以及需跨团队确认的复杂指标。此类指标需严格的数据验证和审批流程,仍依赖传统 BI 的精确性与可控性。
复杂的运维可视化
如 SRE 团队使用的实时监控仪表盘、系统健康视图、多维度性能监控等。这些要求秒级响应与持续可视,仍以定制化 BI 工具为主。
高度专业化的技术分析
包括使用高级统计图表库的探索性分析、基于内部数据的交互式工具开发、与外部模型或可视化平台的深度集成等。
同时,我们也明确提醒内部用户:不要将 DWAINE 的分析作为重大决策的唯一依据。如遇关键场景,应让 DWAINE 生成带注释的 SQL 查询,再借助传统 SQL 工具验证其分析逻辑与结论。
实践经验与最佳策略
哪些做法效果很好?
-
ClickHouse Cloud 性能稳定:亚秒级查询响应,让人感觉像在和真人分析师对话
-
结构化文档价值巨大:我们使用 MDBook 构建的知识库显著降低了 AI 误判率
-
使用开放标准(MCP):避免厂商绑定,未来扩展与接入其他系统更加灵活
-
分阶段推广:先从技术骨干用户试点,再基于反馈逐步扩展,提高了接受度与稳定性
我们遇到的挑战
-
上下文窗口控制:复杂 schema 结构需精细构建提示,确保 LLM 获取到关键上下文信息
-
错误处理机制:当模型输出失败或出现偏差时,系统应支持优雅降级,并提醒用户不要盲目信任 AI 结果
结语
从 BI 为主到 AI 驱动的转变,是 ClickHouse 数据文化的一次重大飞跃。DWAINE 不仅重塑了我们提问数据的方式,更进一步改变了我们与数据互动的思维方式 —— 让数据分析变得自然、对话式,并真正融入每个人的日常决策中。
对那些仍主要依赖传统 BI 工具的企业来说,问题已不是“AI 是否会改变分析方式”,而是你是否能及时响应这一变革。今天,技术基础已然成熟,工具生态不断完善,AI-first 的价值早已不再只是概念。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









