







一、摘要
本文介绍来自ICLR 2022的论文《LoRA: Low-Rank Adaptation of Large Language Models》,这篇论文提出了一种高效的大模型微调策略,时至今日仍然是大模型微调的主流技术之一。

译文:
自然语言处理的一个重要范式是在通用域数据上进行大规模预训练,并适应特定任务或领域。随着我们预训练更大的模型,重新训练所有模型参数的完全微调变得不太可行。以 GPT-3 175B 为例,部署独立的微调模型实例(每个实例有 175B 参数)极其昂贵。我们提出低秩适应(LoRA)方法,它冻结预训练模型权重,并在 Transformer 架构的每一层注入可训练的秩分解矩阵,极大地减少了下游任务的可训练参数数量。与使用 Adam 进行微调的 GPT-3 175B 相比,LoRA 可将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。尽管 LoRA 的可训练参数更少、训练吞吐量更高,且与适配器不同,它没有额外的推理延迟,但在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量与微调相当或更好。我们还对语言模型适应中的秩亏缺进行了实证研究,这有助于解释 LoRA 的有效性。我们发布了一个便于将 LoRA 与 PyTorch 模型集成的包,并在 https://github.com/microsoft/LoRA 上提供了 RoBERTa、DeBERTa 和 GPT-2 的实现及模型检查点。
二、核心创新点
论文中,作者描述了低秩适应(LoRA)方法的设计原理,并指出该方法适用于深度学习模型中的任何Dense层。相比起其他方法,LoRA具有如下的几个优势:
- 通过为不同的任务构建许多小型的LoRA模块,预训练好的模型可以被共享和便捷使用,只需要替换矩阵A和B即可高效地切换任务。
- LoRA使得预训练模型中的大多数参数都不需要计算梯度,只需要优化低秩矩阵即可,因此训练效率大大提高。
- 简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,从结构上来说这并不会导致推理延迟。
1、低秩参数化更新矩阵
作者认为,神经网络包含了许多执行矩阵乘法的Dense层,而这些层中的权重矩阵通常都具有满秩的特点。根据前人经验,作者假设在适应特定任务的过程中,神经网络权重的更新具有较低的“内在秩”(intrinsic rank)。对于预训练的权重矩阵,可以通过用低秩分解
来约束其更新,其中,
,
,并且秩
。在训练期间,
被冻结并且不接收梯度更新,而A和B包含可训练的参数。此外,
和
都与相同的输入相乘,并且它们各自的输出向量按照坐标求和。对于
,修改后的前向传播得到:
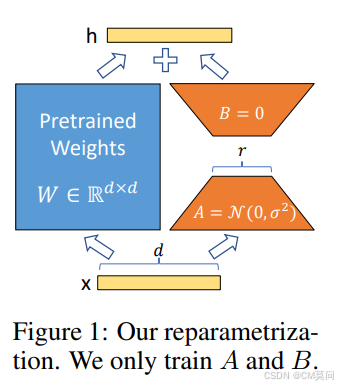
参数的初始化如下图,对A使用随机高斯初始化,对B则初始化为零矩阵。因此,训练开始时的为0。然后,将
按照
进行缩放,而这里的 α 是 r 中的一个常数。根据经验,作者将 α 简单地设置为第一个 r 并且不再进行调整。这种缩放有助于在改变 r 的时候减小重新调整超参数的需要。
2、推理速度优化
在实际的生产部署中,我们可以显式地计算并存储,并像正常流程一样进行推理。由于
和BA都在
中,当我们需要切换到另一个下游任务时,可以通过减去BA并加上不同的
来恢复
。



















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









