




前言
本文对语音识别的全链路技术栈进行入门级解读,旨在让读者理解从声音的产生到最终的文本输出,技术层面是一条怎样的链路。在后续该专题的篇章中,再针对每个概念进行更加具体地解读。
语音识别技术链路全景图
主要包含三大站点:
声学前端处理 (Acoustic Front-End):声音的“净化与预处理”车间。
核心识别引擎 (Recognition Engine):传统 or 端到端模型
后处理与理解 (Post-Processing & Understanding):从文本到“意图”的最后一公里。
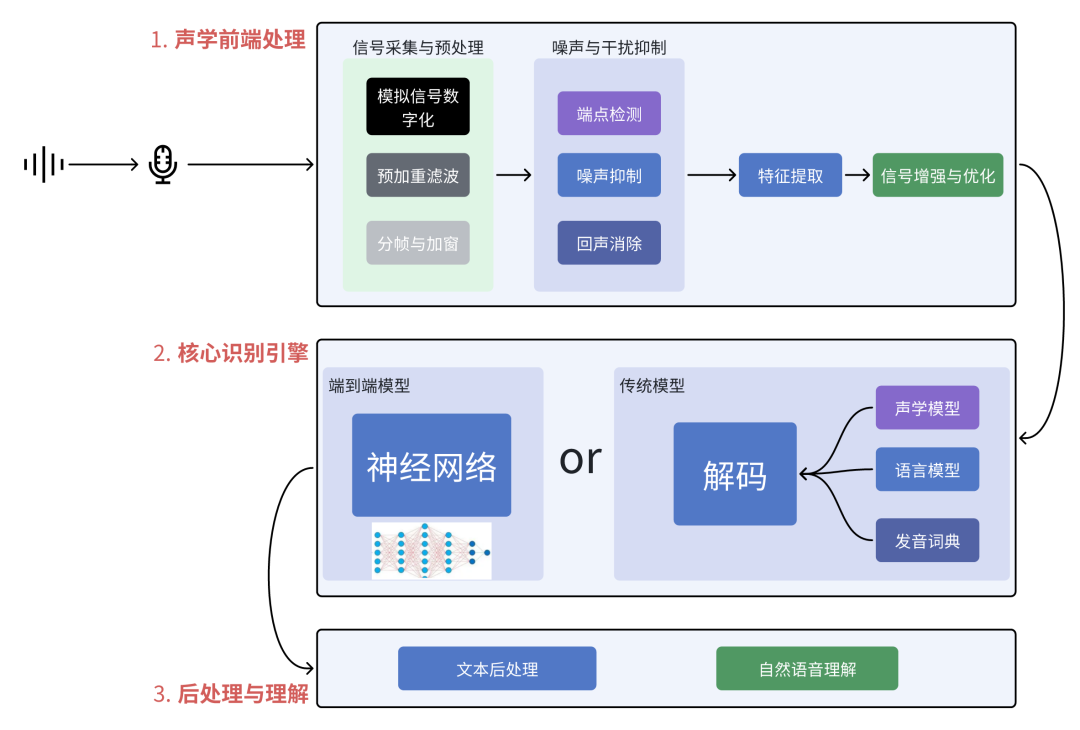
第1站:声学前端处理 —— 声音的“净化与预处理”
这是所有工作的起点,也是决定识别上限的关键。它的目标是“从嘈杂的真实环境中提取出最清晰、最纯净、最适合机器分析的语音信号”。
一、信号采集与预处理
模拟信号数字化:通过模数转换器(ADC)将麦克风采集的模拟语音信号转换为数字信号,并遵循奈奎斯特采样定理(采样频率需大于信号最高频率的两倍)
预加重滤波:使用高通滤波器(如FIR或IIR滤波器)提升语音高频分量,补偿声道滚降效应,增强高频细节(如辅音),同时减少传输噪声
分帧与加窗
分帧:将连续语音切分为短时帧(通常20-40ms),因语音信号具有短时平稳性。
加窗:应用汉明窗、汉宁窗等减少频谱泄漏,平滑帧边界。
二、噪声
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1497
1497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









