



来源 | 深蓝AI
原文链接: 纯视觉方案!中山大学&港科大新作:基于3DGS实现高精度轨迹视频生成
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文

「 不修图、不依赖LiDAR 」
在自动驾驶领域,多轨迹、多视角的视频数据几乎是刚需。
它不仅决定了 3D 重建的完整性,也直接影响世界模型和规划系统的泛化能力。但现实很骨感:
真实世界里,想采集同一条道路、不同横向位置、严格同步的多条驾驶视频,成本极高。要么多车协同,要么反复跑同一路段,还会带来时间、动态目标不一致的问题。于是,研究者开始尝试:
能不能只用一条真实驾驶视频,自动“生成”另一条相邻轨迹的视频?
看似简单,实际却踩了两个大坑:
一类方法先重建 3D,再“修补”新视角画面,结果一遇到复杂伪影就失效;
另一类方法用 LiDAR 来辅助相机控制,但 LiDAR 本身稀疏、不完整,远处和遮挡区域尤其容易出问题。
中山大学与香港科技大学提出了ReCamDriving,一个完全基于视觉、却能精确控制相机轨迹的新轨迹视频生成方法。
不修补、不靠 LiDAR,直接换一种相机控制思路。
标题:ReCamDriving: LiDAR-Free Camera-Controlled Novel Trajectory VideoGeneration
链接:https://arxiv.org/pdf/2512.03621
项目页面:https://recamdriving.github.io/
1
—
与其修画面,不如教模型
真正理解“相机怎么动”
作者首先指出一个关键问题:
很多“新轨迹生成”方法,本质上是在做画面修复,而不是视角变换。修复型方法通常是:
先用 NeRF 或 3D Gaussian Splatting 渲染新视角,再用扩散模型把伪影“补干净”。
问题在于,这些伪影在不同场景、不同视角下变化巨大,模型学到的只是局部修补经验,一旦分布变化就容易翻车。另一条路是相机可控的视频生成:
直接告诉模型“相机从这里动到那里”,让它生成对应视频。
但只靠相机位姿,模型很难真正对齐几何结构,于是有人引入 LiDAR 投影作为几何约束。可 LiDAR 的问题同样明显:
远处稀疏、遮挡缺失、背景不完整,反而会把模型带偏。ReCamDriving 的核心想法是一个“反直觉”的选择:
3DGS 的几何精度不如 LiDAR,但它是“密集、完整、覆盖全场景”的。
于是他们干脆放弃 LiDAR,把 新轨迹的 3DGS 渲染结果,作为相机控制和结构引导信号。
为了避免模型退化成“只会修补 3DGS 伪影”,作者设计了一套两阶段训练策略:
第一阶段,只教模型理解“相机怎么从原轨迹变到目标轨迹”;
第二阶段,在不破坏已有能力的前提下,引入 3DGS 渲染,做精细的几何与视角约束。
这套设计,决定了 ReCamDriving 不是在“修画面”,而是在重新生成一条合理的新轨迹视频。
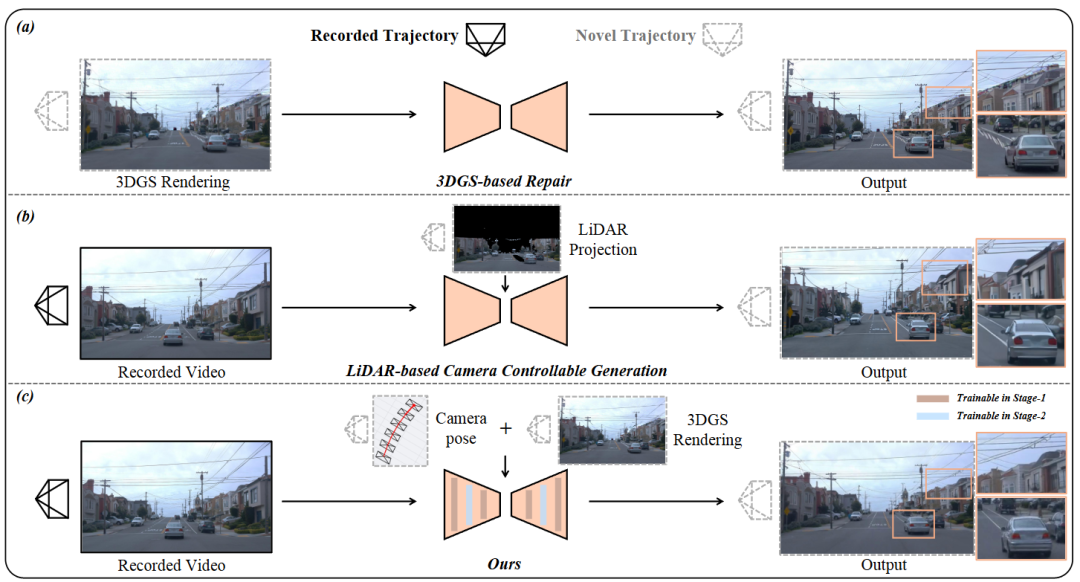
图1|基于“重建后修复”的方法(如 Difix3D+)在遇到新的相机视角时,往往会出现明显的渲染伪影,尤其在复杂场景中难以稳定修复。依赖 LiDAR 的相机可控生成方法(如 StreetCrafter)虽然引入了几何约束,但由于 LiDAR 在远处和遮挡区域本身信息稀疏、不完整,生成结果仍然容易出现几何不一致的问题。相比之下,ReCamDriving 采用由粗到细的两阶段训练策略,利用新轨迹 3D Gaussian Splatting(3DGS)渲染所提供的密集、完整的场景结构信息,实现了更精确的相机控制和更一致的三维结构生成效果
2
—
技术亮点三连
用 3DGS,替代 LiDAR 做相机控制
不同于以往依赖 LiDAR 投影的方法,ReCamDriving 选择了 3D Gaussian Splatting 渲染作为相机控制条件。
虽然单点精度不如 LiDAR,但 3DGS 提供的是密集、连续、全场景覆盖的结构信息。
这种结构信号在远处区域、遮挡位置反而更稳定,能持续为模型提供几何约束。
实验也显示,在横向偏移较大的新轨迹生成中,3DGS 条件比 LiDAR 更稳,几何一致性下降得更慢。
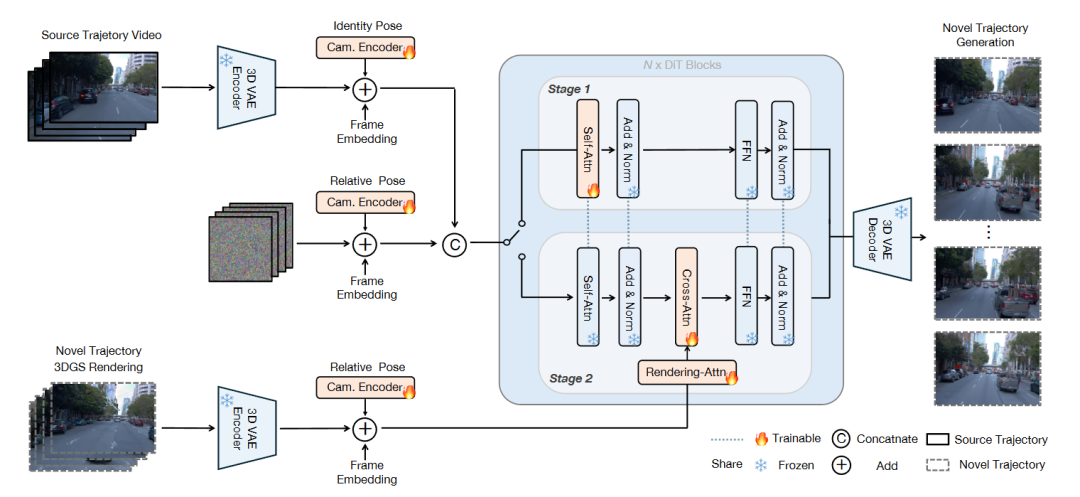
图2|ReCamDriving 的整体方法框架示意图。该方法采用两阶段训练策略,以实现精确且结构一致的新轨迹视频生成。在第一阶段,模型仅基于原始轨迹视频和相对相机位姿进行训练,重点学习基本的视角变换能力。在第二阶段,第一阶段的核心参数被冻结,并引入额外的注意力模块,将新轨迹的 3DGS 渲染结果作为结构引导信号,用于更精细的视角控制和几何约束。图中用蓝色虚线标出了在两个阶段之间共享的网络模块
两阶段训练,防止模型“学歪”
如果一开始就把 3DGS 渲染喂给模型,模型很容易退化成“伪影修复器”。
为此,作者采用了先粗后细的两阶段训练:
第一阶段只用相对相机位姿,建立基本的视角变换能力;
第二阶段冻结核心结构,引入 3DGS 特征,通过额外注意力模块进行精细引导。
这种设计让模型始终围绕“相机重定位”这个目标,而不是被 3DGS 的伪影牵着走。
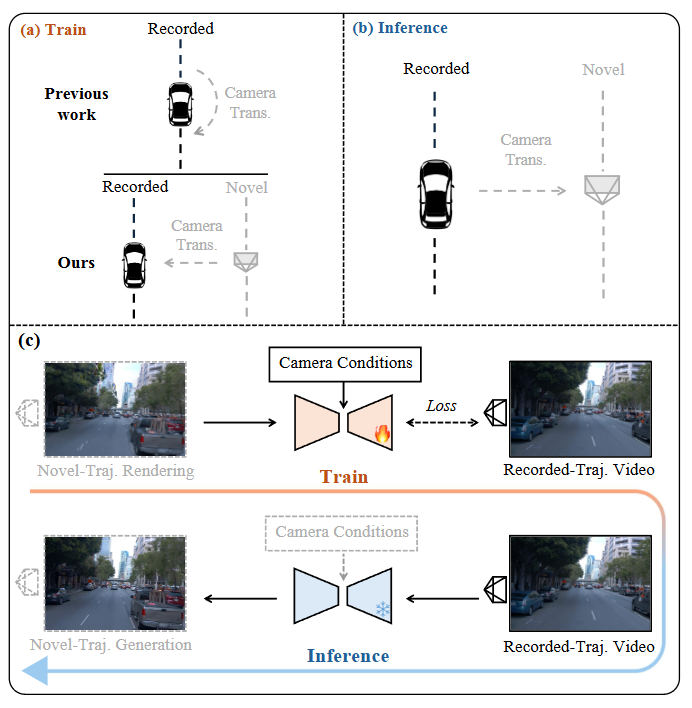
图3|训练与推理阶段相机轨迹变换方式的对比,以及本文采用的数据构造策略。(a–b) 展示了以往方法中训练阶段与推理阶段在相机轨迹变换模式上的不一致问题,这种不匹配会导致模型在生成新轨迹时表现不稳定。(c) 展示了 ReCamDriving 的训练与推理数据策略:通过 3DGS 渲染构造跨轨迹的数据对,使模型在训练阶段接触到与推理阶段一致的相机变换模式,从而提升对横向新轨迹生成的鲁棒性
跨轨迹数据构造,解决“没真值”的老问题
现实驾驶数据几乎都是单轨迹,没有真实的新轨迹视频作为监督。
作者提出了一种巧妙的 跨轨迹数据构造策略:
用 3DGS 渲染生成“横向偏移”的新轨迹视频,作为输入;
用原始真实视频作为监督信号。
这样,模型在训练时学到的相机变换模式,与推理时完全一致。
基于这一策略,作者构建了ParaDrive 数据集,包含 110K 以上的平行轨迹视频对,为后续研究提供了重要基础。

图4|训练阶段使用的数据配对方式示意图。在训练过程中,模型以新轨迹的 3D Gaussian Splatting 渲染结果(约 30,000 次迭代后)作为源输入,用来模拟需要生成的新视角视频;同时,将原始轨迹在不同训练阶段(100、500 或 1,000 次迭代)下得到的 3DGS 渲染结果作为相机控制与几何条件,引导模型学习不同精度下的视角约束;最终,以原始轨迹对应的真实拍摄视频作为监督信号,确保生成结果在结构和外观上与真实场景保持一致
3
—
实验与表现
实验部分,作者主要从三点验证方法有效性:
相机控制精度:在 Waymo 和 nuScenes 上,ReCamDriving 的相机位姿误差显著低于修复型方法和 LiDAR 条件方法。
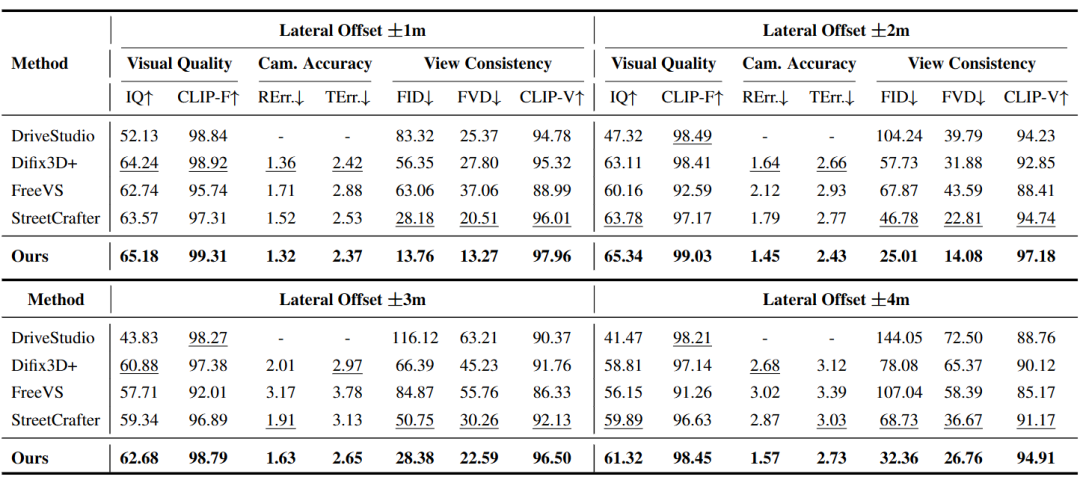
图5|在 Waymo Open Dataset(WOD)上的定量对比结果。该表从视觉质量、相机控制精度和视角一致性等多个指标,对比了不同方法在新轨迹生成任务中的表现。其中,加粗数值表示最优结果,下划线表示次优结果
视角与几何一致性:随着横向偏移增大,其他方法的结构一致性快速下降,而 ReCamDriving 下降更缓,表现更稳定。
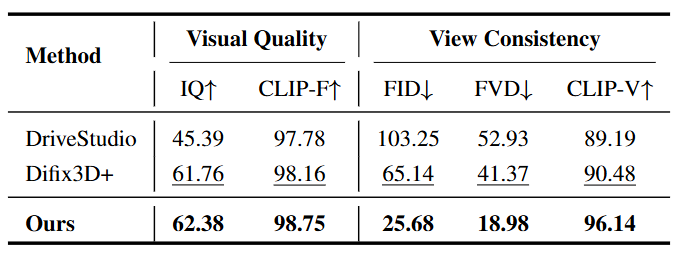
图6|在 nuScenes 数据集上的新轨迹视频生成平均性能对比。该表展示了不同方法在视觉质量和视角一致性相关指标上的整体表现,用于验证方法在不同自动驾驶数据集上的泛化能力
视觉结果:在车道线、路面标记、远处建筑等细结构区域,生成结果保持连续,不容易出现“漂移”和断裂。尤其是在大幅横向偏移时,LiDAR 方法常因投影稀疏而失败,而ReCamDriving 依然能维持整体结构。

图7|在 Waymo Open Dataset(WOD)上的定性结果对比。该图对比了不同方法在新轨迹生成任务中的视觉效果。其中,ReCamDriving 和 Difix3D+ 都使用 DriveStudio 生成的新轨迹 3DGS 渲染结果作为输入,但前者将其用于相机控制,而后者主要用于画面修复。
4
—
总结
ReCamDriving 代表了一种清晰的趋势:
新轨迹视频生成,不该只是事后修补,而应回到“相机与几何关系”的本质建模。
通过引入 3DGS 作为结构条件,并配合合理的训练策略和数据构造方式,作者在不依赖 LiDAR 的情况下,实现了稳定、可控的新轨迹生成。
这不仅对自动驾驶数据扩充有价值,也为世界模型训练、仿真数据生成提供了新的思路。
自动驾驶之心
3DGS理论与算法实战课程!


















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









