



作者 | 深蓝学院 来源 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文

「小米交出了一份全景AI答卷」
今年的 AAAI 2026,国产科技公司里最亮眼的名字之一,就是小米。
小米共有 7 篇最新研究成果成功入选 AAAI 2026!
这些论文覆盖的方向几乎能串起 AI 的完整能力链条:
从 音效编辑到语音问答,从3D具身智能 Agent到视觉语言导航(VLN),从检索模型与推断解码策略再到 自动驾驶……
你能想到的小米 AI 研究热点,这次几乎都有代表作入选。这既是小米在大模型与具身智能上的阶段性成果,也是对其科技战略——“深耕底层技术、长期持续投入”——的最好注脚。
图1|小米创始人雷军微博发文祝贺小米研究团队七篇论文入选AAAI
1
—
论文盘点
AutoLink: Autonomous Schema Exploration and Expansion for Scalable Schema Linking in Text-to-SQL at Scale
主要内容:
做大规模 text-to-SQL 最大的难题之一,就是数据库太大。工业场景动不动就是上千张表、几千个字段,把整个 schema 全塞进 LLM 不现实——不仅超出上下文窗口,还会给模型制造大量无关噪声。而 schema linking(从海量 schema 中找出与问题相关的部分)又非常关键,却在传统方法中昂贵、吃资源、且一旦数据库规模上去就容易失效。
小米提出的 AutoLink 给出了一个更聪明的解法:他们把 schema linking 从“给模型一整套表格让它挑”改造成“让模型像代理一样逐步探索”。AutoLink 的核心是一个 自主式 Agent 框架:
它不会一次性加载所有表,而是让 LLM 带着任务目标迭代式探索数据库结构;
只把“当前真正需要的 schema 部分”加入上下文;
并在必要时逐步扩展,直到找到所有可能影响 SQL 生成的字段或表。
结果非常亮眼:
在 Bird-Dev 上 strict recall 达到 97.4%(SOTA)
在 Spider-2.0-Lite 上 recall 91.2%,执行准确率全球排名第二
面对超过 3000 列的大型数据库也依旧保持高召回、低 token 开销和稳健表现
AutoLink 让 LLM 不再“死记全库”,而是像智能助手一样主动探索需要的 schema,实现真正可规模化的 text-to-SQL。
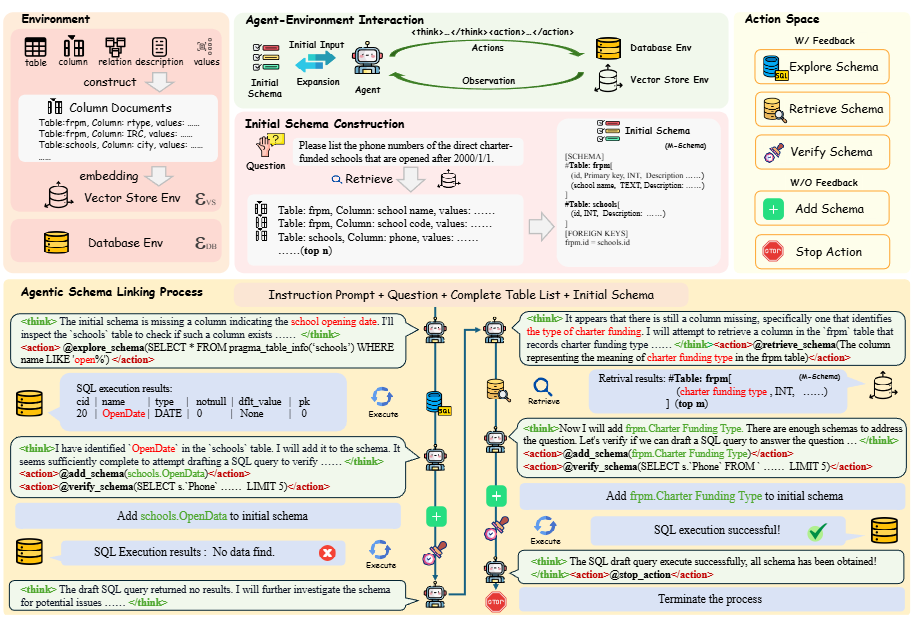
图2|AutoLink 框架示意:让模型像“智能代理”一样逐步探索数据库结构:这张图展示了 AutoLink 的核心思路:模型不再一次性接收整个数据库结构,而是以“交互式探索”的方式,逐步筛选、扩展与任务相关的表和字段。通过这样的迭代过程,AutoLink 能在海量 schema 中精准找到生成 SQL 所需的部分,实现高效且可规模化的 schema linking
Scaling LLM Speculative Decoding: Non-Autoregressive Forecasting in Large-Batch Scenarios
主要内容:
在大模型推理中,speculative decoding 曾被视为提升速度的一大利器——它利用显卡在传输数据时的空闲算力,让一个“小模型”提前生成Draft,再由大模型快速验证。然而在真正的工业场景里,这种方法逐渐遇到瓶颈:小模型很耗算力、Draft树复杂、调度成本高,尤其在大批量请求(batch)条件下几乎没有优势。
小米提出的 SpecFormer 重新定义了Draft模型的角色。他们认为,与其挤出计算资源给小模型生成复杂Draft树,不如让“Draft模型本身就更聪明、更适合并行”。于是 SpecFormer 引入了一种非常特别的架构设计:结合单向注意力 + 双向注意力:保留自回归模型对输入全局信息的理解能力,同时具备非自回归模型的“并行生成”优势。
SpecFormer 既能“看懂上下文”,又能“不等着逐字生成”,实现天然的高速解码。实验结果显示:
无需巨大Draft树,即可保持稳定加速
甚至在 大 batch 推理场景也能持续提升速度
训练成本更低、硬件要求更友好,适合真正规模化部署
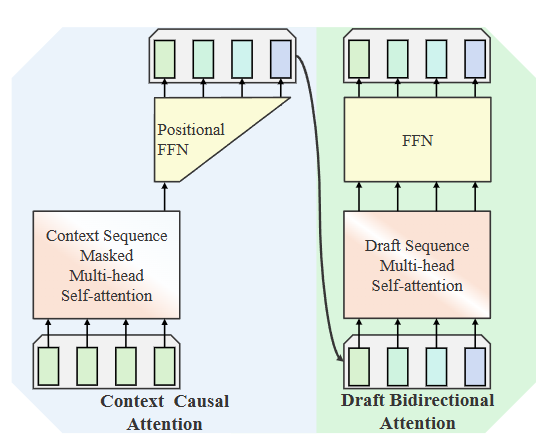
图3|SpecFormer 架构示意:融合双向与单向注意力,实现并行Draft生成的高速解码。该图展示了 SpecFormer 的核心创新结构——通过将自回归与非自回归的注意力机制融合,Draft模型不仅能理解输入序列的完整语义,还能并行生成多个预测,从而在无需大型Draft树的情况下实现稳定加速
End-to-end Contrastive Language-Speech Pretraining Model For Long-form
Spoken Question Answering
主要内容:
近年来,语音问答(SQA)技术进步飞快,但一个老大难问题始终存在:
长语音太难处理了。
无论是传统模型,还是大型音频语言模型,一旦语音录音时间过长,信息稀疏、无关片段多、计算成本高等问题都会让模型“脑子打结”。
于是研究者们引入了类似 RAG(检索增强生成)的思路——先从长语音里找出跟问题相关的部分,再让模型回答。但可惜的是,现有的语音检索器表现并不理想,处理不准、跨模态对齐弱,效果不稳定。
小米提出的CLSR(Contrastive Language-Speech Retriever)就是为了解决这一难题。
CLSR 的亮点有三:
它是端到端 retriever,直接从长语音中抽取最相关的片段,不再依赖庞大的 ASR(语音转文本)流水线。
引入“文本化中间表征”:先把语音特征转换成类似文本的结构,再与问题语句对齐,使跨模态对齐更加自然、准确。
在四个跨模态检索数据集上均取得显著优势,超越传统语音检索器以及“ASR + 文本检索”的组合方案。
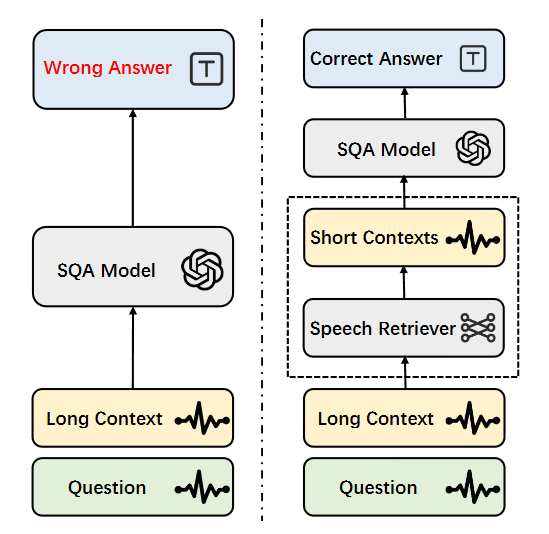
图4|通过语音检索器把长语音“浓缩成重点”,让大模型更容易听懂问题。这张图展示了 CLSR 的基本作用:先用语音检索模型从冗长的语音录音中找出与问题高度相关的关键片段,再将这些精简后的内容交给大模型处理。这样不仅减少无关信息干扰,也显著提升了语音问答的准确性与效率
V-Edit: Multimodal Generative Sound Effect Editing via Audio-Visual Semantic Joint Control
主要内容:
给视频“换声音”听起来简单,但真正做起来却很难——传统音效编辑方法要么依赖底层信号处理(效果粗糙),要么依赖简单的文本指令(控制力有限),很难实现 精细、自然、与画面一致 的声效修改。
小米提出的 AV-Edit 则从根本上改变了音效编辑的方式。
它的核心理念很直接:
编辑声音不应该只听声音,而是要“看”和“理解”画面。
为此,AV-Edit 引入了一个三模态的生成式框架,结合视觉、音频、文本三种语义,共同完成精细化的声效编辑:
首先使用 对比式音频–视觉 Masking Autoencoder(CAV-MAE-Edit) 做多模态预训练,让模型真正学会跨模态对齐。
再基于这一表征训练 多模态扩散 Transformer(MM-DiT),能够:
自动移除与画面不相关的噪声、自动补全缺失的声音、自动生成符合视频语境的声效
为了客观评测,他们还构建了一个新的视频音效编辑数据集。实验结果显示:
AV-Edit 能精准“按画面编辑声音”,音质自然、修改准确
在音效编辑任务中达到SOTA
在更广泛的音频生成领域也展现出强竞争力
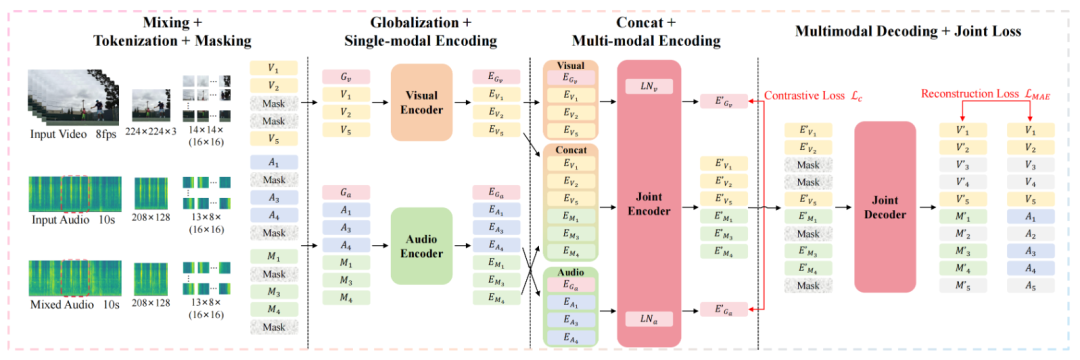
图5|这张图展示了 CAV-MAE-Edit 的整体结构。模型首先分别用独立的编码器处理视频画面和原始音频;随后通过多模态编码器与解码器,将两种信息融合为统一的语义表征。这样的设计让模型能够同时“看懂画面”和“听懂声音”,为后续精准的音效编辑打下基础
Cook and Clean Together: Teaching Embodied Agents for Parallel Task Execution
主要内容:
在真实世界里执行指令,机器人不仅要听懂人话、理解场景、找到物体,还要学会怎么安排任务才最高效。
比如:“去清洁厨房”——是不是可以一边让微波炉加热,一边顺手把水槽刷掉?
这种“任务调度”正是现有具身 AI 最欠缺的能力。现有数据集通常忽略两件关键事:任务之间的可并行性、指令在三维环境中的真实落地
为了解决这个空白,小米提出了一个全新的任务定义——ORS3D:融合运筹学知识的 3D 任务调度。该任务要求智能体同时做到三件事:
1. 理解语言
2. 在真实 3D 场景中定位相关对象
3. 根据可并行的子任务设计最优时间安排
也就是说,机器人不再是简单完成任务,而是要学会“更快、更聪明地完成”。为了推动研究,他们构建了一个规模巨大的数据集:ORS3D-60K:覆盖 4000 个真实场景、6 万个复合任务。
这些任务均包含可并行的子目标,让模型必须兼具策略性与空间理解能力。在方法上,他们提出了:GRANT——具备任务调度意识的多模态大模型。
GRANT 的特点是加入了一个非常简单但有效的机制:
Scheduling Token(调度标记):让模型能明确地规划哪些任务可以并行、哪些必须按序执行,从而输出更高效率的任务执行方案。实验结果显示,在语言理解、3D grounding、调度效率三方面,GRANT 在 ORS3D-60K 上都取得强竞争力表现。
ORS3D + GRANT 让具身智能第一次具备了“会安排时间”“懂并行优化”的真实世界工作能力。
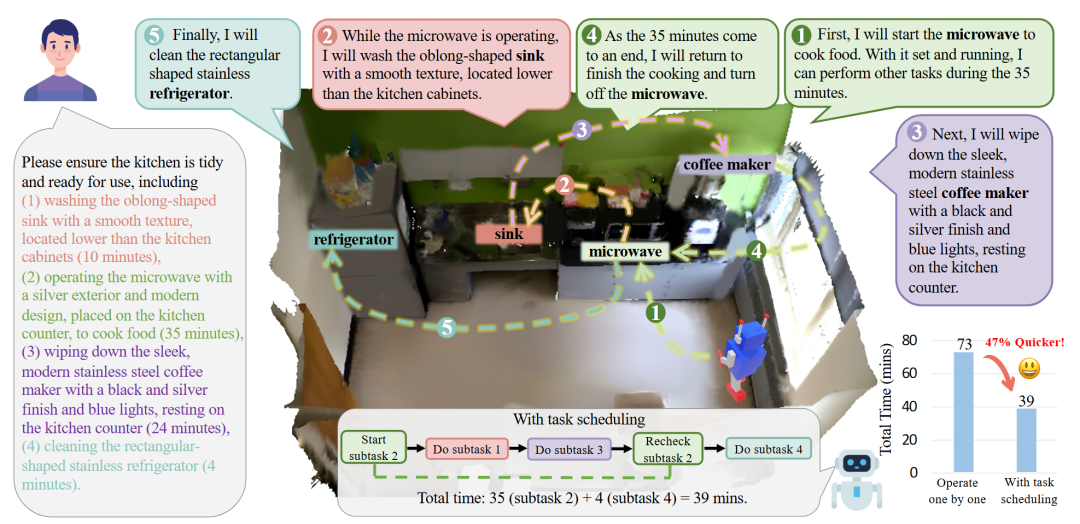
图6|ORS3D 任务示意:机器人不仅要“做对”,还要“做得更快”:这张图展示了 ORS3D 的核心概念:当人类给出一个包含多个步骤的复杂任务时,具身智能体需要像运筹学专家一样合理安排任务顺序,找出哪些步骤可以并行、哪些必须依次完成。同时,它还要在三维环境中准确找到相关物体,才能顺利完成导航和操作,实现高效率的任务执行
What You See is What You Reach: Towards Spatial Navigation with High-Level Human Instructions
主要内容:
这项工作关注具身智能导航中一个长期存在的缺口——如何让机器人在复杂三维环境中,将人类的自然语言指令与空间理解结合起来。现有导航任务往往只能处理简单目标,例如“去某个物体”,但缺乏对空间关系、区域定位等更贴近真实场景的表达能力。
为解决这一问题,作者提出了一个新的任务设定Spatial Navigation,包含两个子任务:
SpON(Spatial Object Navigation):利用空间关系和上下文,引导智能体前往特定物体;
SpAN(Spatial Area Navigation):根据指令导航到环境中的某一个区域,而非单个目标点。
为支持该任务,作者构建了包含 10,000 条轨迹的空间导航数据集,涵盖高层语言指令、逐步观测与行动序列,能够系统地训练智能体理解空间描述并生成相应行动。
在方法上,作者提出了 SpNav框架,结合视觉语言模型解析指令,从当前观察中识别目标物体或区域,并通过地图执行精确的导航规划。整体目标强调“所见即所得”,即智能体应能根据观察内容和语言信息直接行动。
实验表明,SpNav 在模拟与真实场景中均取得了领先表现,显著提升了模型对空间表达的理解与导航能力,为更真实的具身智能应用提供了基础。
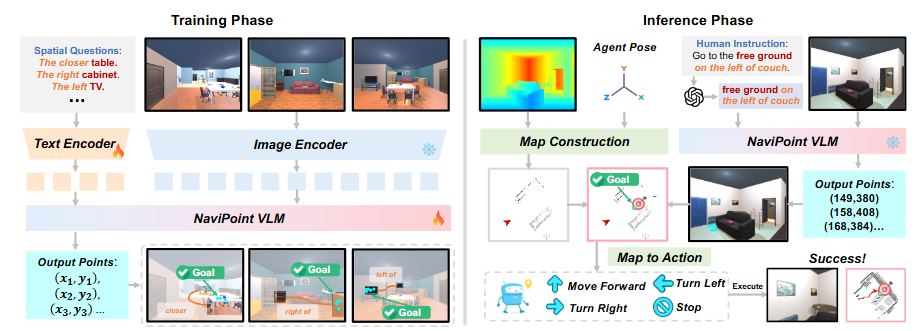
图7|SpNav 框架概览:本图展示了 SpNav 的整体流程。在训练阶段,作者利用空间问答数据训练 NaviPoint 模型,使其具备准确指示目标位置的能力。在推理阶段,系统首先通过视觉语言模型解析人类指令,再由 NaviPoint 输出自我中心坐标系下的目标位置;随后根据 RGB-D 观测和位姿信息构建局部地图,并通过点到点导航模块引导智能体到达目标位置
VILTA:A VLA-in-the-Loop Adversary for Enhancing Driving Policy Robustness
主要内容:
自动驾驶系统在常规道路条件下的策略学习已相对成熟,但在罕见、复杂的长尾场景中仍缺乏可靠的数据与有效的训练方式。现有数据集难以覆盖足够多的极端情况,而传统的轨迹生成方法在多样性与物理合理性方面也存在局限。
为此,作者提出 VILTA(VLA-in-the-Loop Trajectory Adversary),一种面向长尾场景的对抗性轨迹生成方法。核心思想是将视觉语言模型直接引入训练闭环,形成“视觉–语言–编辑”的一体化生成框架。借助 VLM 的强感知与语义理解能力,VILTA 能够对周围车辆的未来轨迹进行精细编辑,摆脱传统两阶段生成流程带来的限制。
此外,方法中引入了运动学后处理机制,确保生成的轨迹不仅具有多样性和对抗性,同时满足车辆动力学约束,能够真实反映潜在的危险或极端情况。
在 CARLA 仿真中的实验表明,使用 VILTA 生成的长尾场景进行强化学习优化,可显著降低自动驾驶策略的碰撞率,提高系统在复杂情形下的稳定性。整体上,该方法为提升端到端自动驾驶策略的长尾表现提供了一种可行且高效的途径。
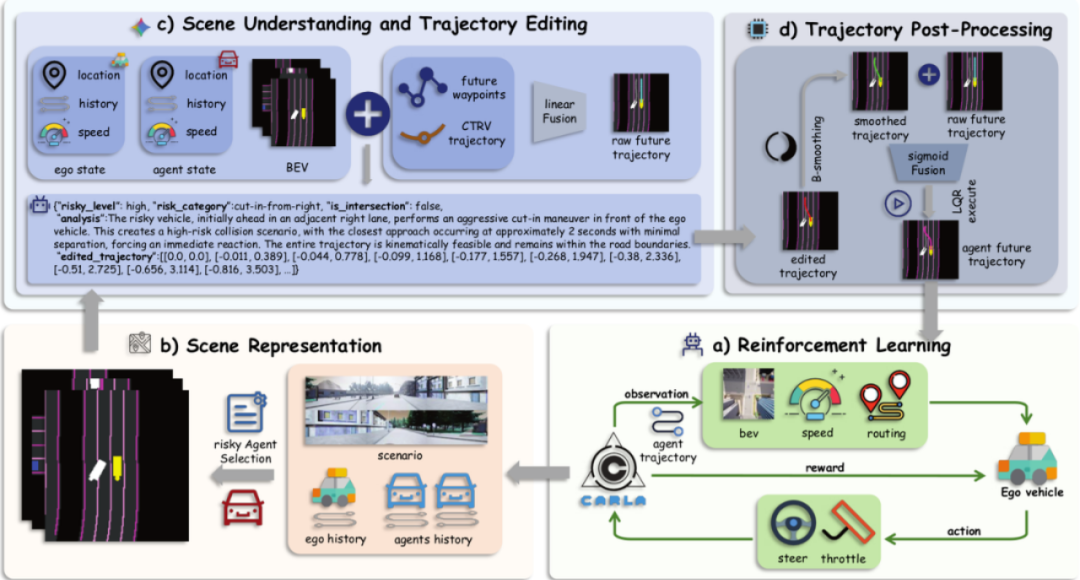
图8|本图展示了 VILTA 在自动驾驶长尾场景生成与策略优化中的完整工作流程。首先,系统从 CARLA 环境中获取场景信息,包括自车与周围车辆的历史轨迹、速度和位置等(b)。随后,依托视觉语言模型进行场景理解,对潜在高风险车辆进行识别,并对其未来轨迹进行对抗性编辑(c),生成更加具有挑战性的驾驶场景。编辑后的轨迹经过运动学约束与平滑处理(d),确保其物理可行性。最终,这些构造出的复杂场景被用于强化学习训练(a),显著提升自动驾驶策略在极端情况中的安全性与鲁棒性
2
—
总结
在 AAAI 这样的国际顶级舞台上集中展示这些成果,不仅体现了小米对“深耕底层技术、长期持续投入”的落地实践,也为行业带来了一批具有前瞻性的研究方向。未来,随着大模型和具身智能技术的持续演进,我们也期待这些工作能够进一步推动智能设备、机器人与自动驾驶等领域的实际应用。
自动驾驶之心
端到端与VLA自动驾驶小班课!


















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









