



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Zhe Liu等
编辑 | 自动驾驶之心
空间智能,是近期人工智能的一大热词。究其本质,我们需要AI对物理世界更高维度的理解,不仅局限于图像、文本和音频。在自动驾驶中,空间理解是底层的需求。柱哥这几天看到了港大领衔的一篇工作 - DrivePI,分享给大家。这篇工作由香港大学领衔,深度联手引望(原华为车BU)、天津大学及华中科技大学共同打造,以全能的 4D 空间感知能力,重新定义了端到端自动驾驶的未来范式。
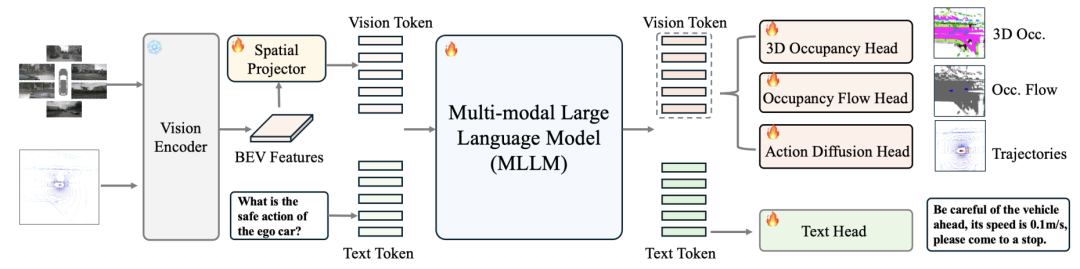
尽管多模态大语言模型(MLLMs)在各种领域展示了强大的能力,但它们在自动驾驶中生成精细化3D感知和预测输出的应用仍有待探索。本文提出了DrivePI,一种新型的空间感知4D MLLM,作为统一的视觉-语言-行为(VLA)框架,同时兼容视觉-行为(VA)模型。我们的方法通过端到端优化,并行执行空间理解、3D感知(如3D占用体素)、预测(如占用流)和规划(如动作输出)任务。为了获取精确的几何信息和丰富的视觉外观,我们的方法在统一的MLLM架构中集成了点云、多视角图像和语言指令。我们还开发了一个数据引擎,用于生成文本-占用和文本-流问答对,以实现4D空间理解。
值得注意的是,仅使用0.5B参数的Qwen2.5模型作为MLLM主干网络,DrivePI作为单一统一模型,性能已经匹配或超越了现有的VLA模型和专业的VA模型。具体而言,与VLA模型相比,DrivePI在nuScenes-QA上的平均准确率比OpenDriveVLA-7B高出2.5%,在nuScenes上的碰撞率比ORION降低了70%(从0.37%降至0.11%)。与专业VA模型相比,DrivePI在OpenOcc上的3D占用RayIoU超过FB-OCC 10.3个点,在OpenOcc上的占用流mAVE从0.591降至0.509,在nuScenes上的规划L2误差比VAD低32%(从0.72m降至0.49m)。
论文标题:DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
论文链接:https://arxiv.org/pdf/2512.12799
项目链接:https://github.com/happinesslz/DrivePI
📝 项目简介
DrivePI是一种新型的空间感知4D多模态大语言模型(MLLM),作为自动驾驶领域的统一视觉-语言-行为(VLA)框架。它能够同时执行空间理解、3D感知(如3D占用体素)、预测(如占用流)和规划(如动作输出)任务,通过联合优化实现并行处理。我们将其称为4D MLLM,因为它既输出3D占用体素,又输出流场,捕获精细的时空动态信息。
🔍 研究背景与挑战
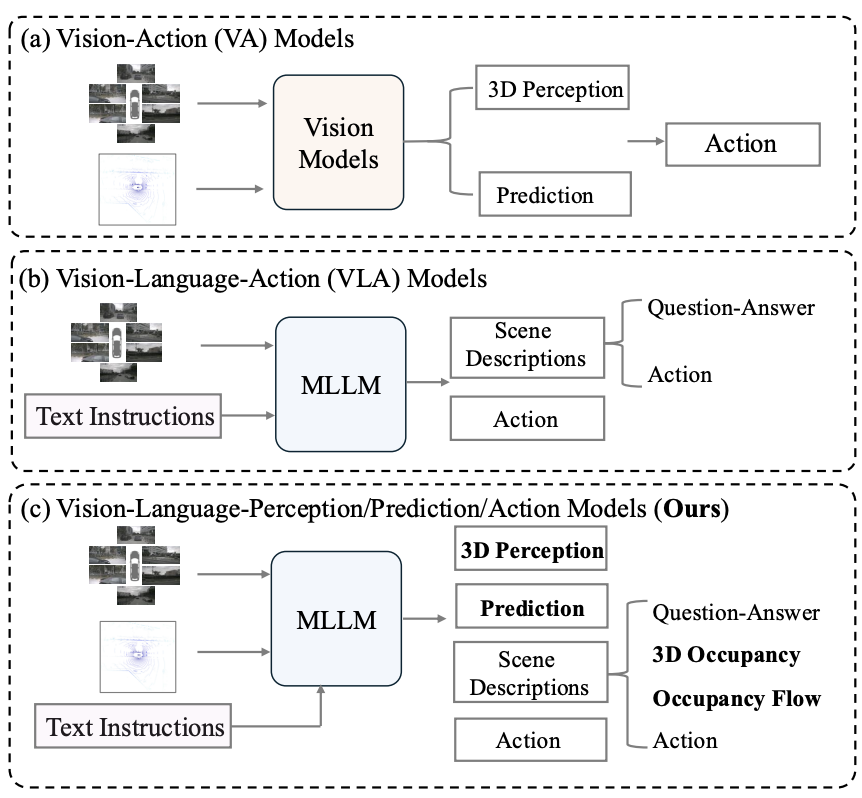
当前自动驾驶系统主要有两种范式:
基于视觉的方法:如UniAD、VAD等,采用模块化框架,从3D感知到预测,再聚合信息生成驾驶动作。这些方法虽然在空间感知方面表现出色,但在基于语言的场景交互方面存在局限性。
基于VLA的方法:如OpenDriveVLA、ORION等,利用MLLM的推理和决策能力,实现更好的用户交互。然而,这些方法由于缺乏精细的中间3D感知和预测输出,难以保证可靠性和安全性。
关键问题:我们能否开发一个统一的框架,结合基于视觉模型的精确空间感知能力和VLA方法的自然语言交互能力?
💡 DrivePI的创新点
DrivePI展现出四个显著特点:
多模态感知:不同于主流仅依赖相机图像的VLA方法,DrivePI引入激光雷达作为补充传感模态,提供精确的3D几何信息,更好地激发MLLM的空间理解能力。
精细化空间表示:生成中间的精细3D感知(如3D占用体素)和预测(如占用流)表示,确保MLLM输出特征保持可靠的空间感知能力,增强自动驾驶系统的可解释性和安全保障。
丰富的数据引擎:开发了将3D占用和占用流表示无缝集成到自然语言场景描述中的数据引擎,使模型能够通过文本理解复杂的时空动态。
统一模型设计:作为统一模型,DrivePI采用端到端联合优化,覆盖3D感知、预测、规划和场景理解等所有任务。实现用一个MLLM统一了现有的VLA和VA框架。
🛠️ 技术架构
DrivePI的架构包括以下关键组件:
多模态视觉编码器:处理多视角图像和激光雷达点云,将其转换为紧凑的潜在BEV特征表示。在DrivePI中,采用了UniLION(可以支持LiDAR,LiDAR-Camera, Temporal-LiDAR, Temporal-LiDAR-Camera作为输入的多模态视觉编码器)
空间投影器:将潜在BEV特征映射到语言空间,获取视觉标记。
MLLM主干:处理多模态视觉特征和文本特征,基于Qwen2.5-0.5B模型构建。
四个专用头部:
文本头:以自回归方式生成场景理解响应(包括caption,如occ和occ flow空间感知,轨迹规划)
3D占用头:用于精确的3D感知
占用流头:用于精细的运动预测
行为扩散头:用于精细的轨迹规划
📊 数据引擎
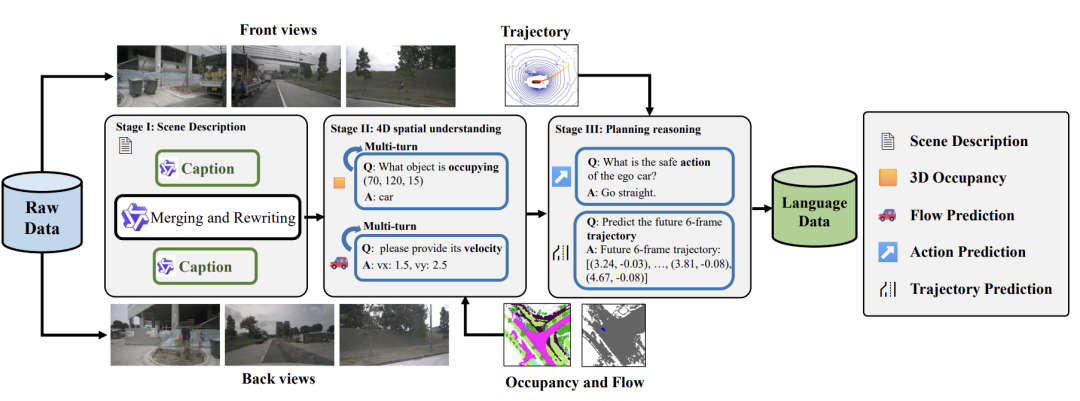
DrivePI的数据引擎分为三个主要阶段:
场景理解注释:使用InternVL3-78B分别为前视图和后视图生成场景描述,避免MLLM在区分不同视角时可能产生的混淆。
4D空间理解注释:利用地面真实占用和流数据生成多样化的问答对,专注于确定给定位置是否被占用、识别相应对象类别和预测速度信息等关键任务。
规划推理注释:基于自车未来轨迹注释生成规划问答对,要求MLLM分析周围环境并提供高级驾驶指令和建议轨迹。
🔬 实验结果与分析
我们在nuScenes数据集上进行了全面的实验评估,该数据集包含750个训练场景、150个验证场景和150个测试场景,提供了同步的多模态传感器数据,包括激光雷达点云和6个摄像头的多视角图像。我们的评估涵盖了四个关键任务:文本理解、3D占用体素感知、占用流预测和轨迹规划。
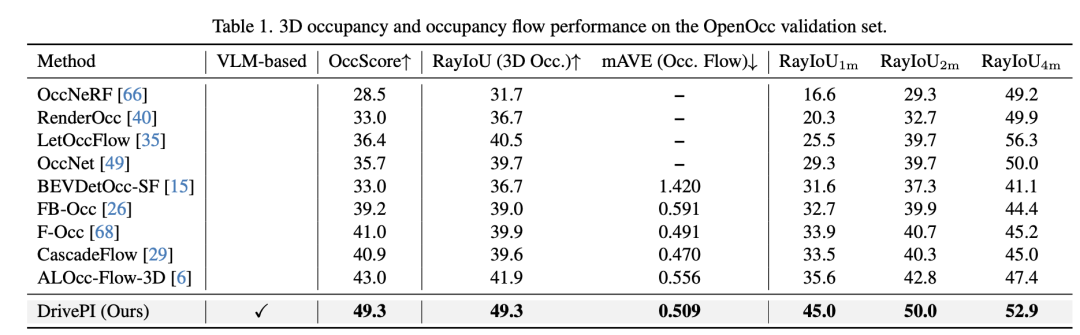
3D占用和占用流预测性能
如下表所示,DrivePI在OpenOcc基准测试上展现出了卓越的3D占用和占用流预测能力。DrivePI实现了49.3%的OccScore和49.3%的RayIoU,同时将占用流mAVE降至0.509。特别是,DrivePI超越了代表性方法FB-OCC的3D占用RayIoU达10.3个百分点,并将流mAVE从0.591降至0.509。值得注意的是,DrivePI比之前最先进的方法ALOcc-Flow-3D在OccScore上高出6.3%,在RayIoU上高出7.4%,并将mAVE降低了0.047,仅使用0.5B MLLM主干网络就建立了新的最先进结果。
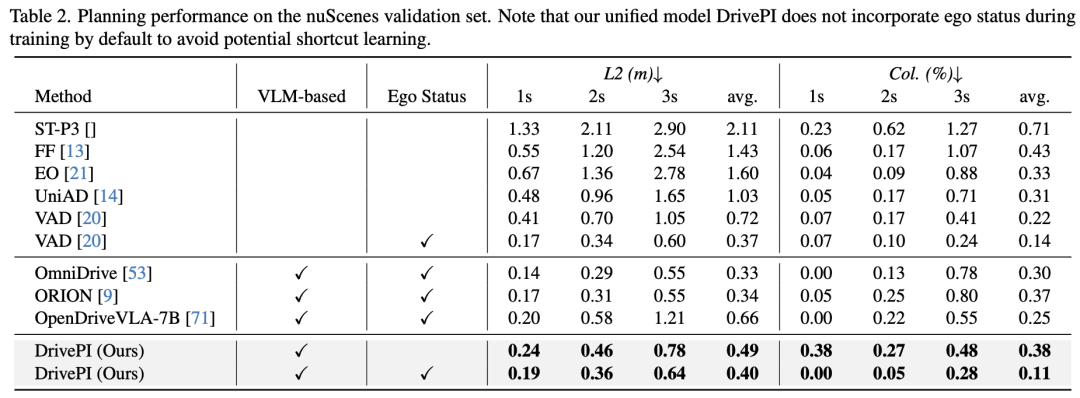
轨迹规划性能
在nuScenes基准测试上,DrivePI在轨迹规划任务中表现出色。如下表所示,当使用自车状态信息时,DrivePI实现了0.40的L2误差和0.11%的碰撞率,分别优于端到端视觉方法VAD(0.14%)和VLA方法OpenDriveVLA-7B(0.25%)。特别值得注意的是,DrivePI将碰撞率比最近的ORION降低了70%(从0.37%降至0.11%)。在不使用自车状态信息的情况下,DrivePI的L2误差比VAD低32%(从0.72m降至0.49m)。这些结果证明了DrivePI作为VLA模型在规划任务中的有效性。
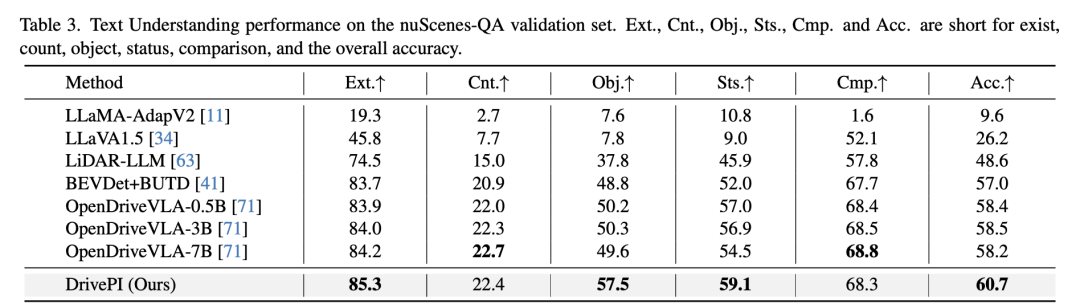
文本理解能力
文本理解能力对VLA模型至关重要,它使自动驾驶系统能够基于自然语言进行解释和推理,从而支持更类人的决策制定。如下表所示,DrivePI尽管仅使用0.5B参数模型,但在nuScenes-QA基准测试中达到了60.7%的准确率,超过了OpenDriveVLA-7B 2.5%的准确率。在各个子类别上,DrivePI在存在(Exist)、对象(Object)和状态(Status)问题上分别达到了85.3%、57.5%和59.1%的准确率,表现出色。这表明DrivePI在理解和解释自然语言方面具有很强的能力。
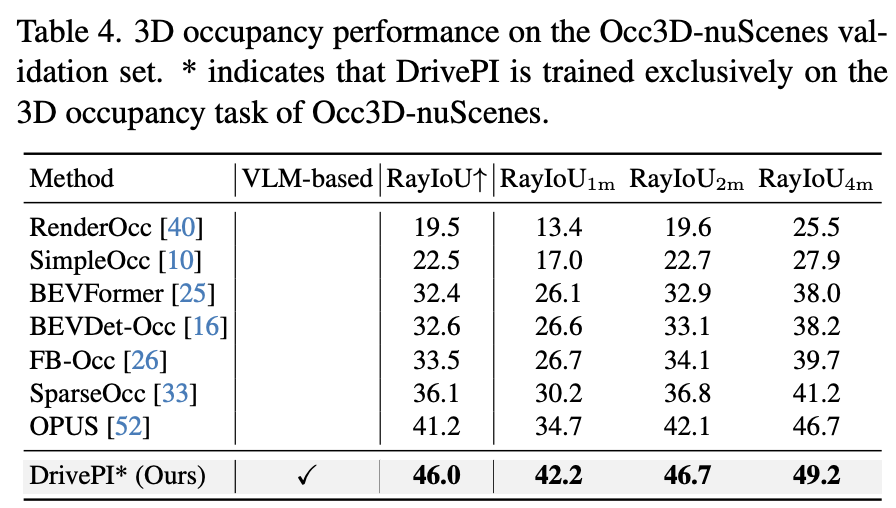
3D占用体素感知性能
除了统一模型外,我们还专门在Occ3D基准测试上评估了DrivePI的3D占用体素感知能力。如下表所示,DrivePI达到了46.0%的RayIoU,比之前最先进的OPUS方法提高了显著的4.8%。在不同距离范围内,DrivePI的性能也表现出色,在1m、2m和4m距离上分别达到了42.2%、46.7%和49.2%的RayIoU。值得注意的是,尽管DrivePI主要设计用于多模态理解,但其基于MLLM架构展现出了强大的精细3D感知能力。
文本头部与视觉头部的消融研究
为了评估各个组件的贡献,我们进行了消融研究,结果如下表所示。为简化起见,我们将精细的3D占用头、占用流头和轨迹规划头组合称为视觉头。当仅启用文本头时(I),DrivePI在文本理解任务上取得了有竞争力的性能(61.2%准确率)。当仅启用视觉头时(II),DrivePI在3D占用(47.5% RayIoU)、占用流(0.69 mAVE)和轨迹规划(1.02 L2误差,0.39碰撞率)方面仍然表现出色。当文本头和视觉头结合时(III),DrivePI在大多数任务上取得了更好的性能:与仅视觉设置相比,统一模型的RayIoU提高了1.8%,mAVE降低了0.18,L2误差降低了0.52。这主要是因为文本理解有助于更好地与视觉任务的适当特征空间对齐。同时,它保持了60.7%的文本理解准确率,接近仅文本设置。这些结果证明了在VLA框架中统一文本理解与3D感知、预测和规划的有效性。

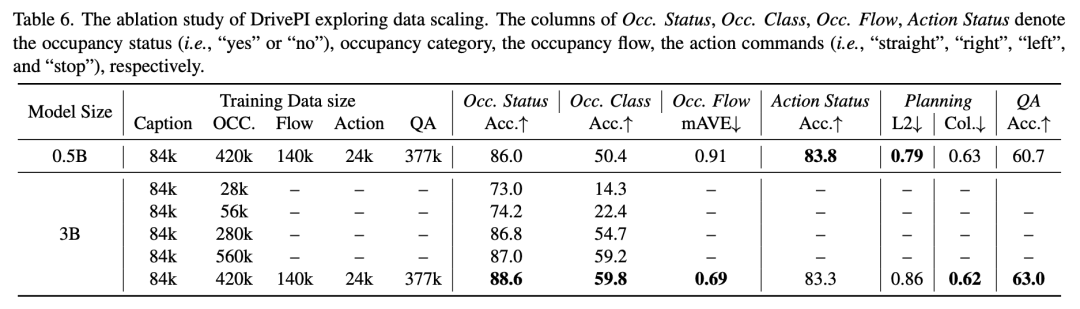
文本数据规模的影响
我们还探索了不同规模文本数据的影响。当使用Qwen-2.5 3B模型并仅启用文本头时,训练数据从较小规模(84K标题+28K占用QA对)扩展到更大规模(84K标题+560K占用QA对),模型在占用状态预测的准确率从73%提升到87%,占用类别预测的准确率从14.3%显著提升到59.2%。进一步添加占用流、动作和官方nuScenes-QA的QA对后,预测占用状态和类别的准确率分别提高了1.6%(达到88.6%)和0.6%(达到59.8%)。此外,对应的占用流、动作状态和规划性能分别为0.69 mAVE、83.3%准确率和0.62碰撞率。我们还评估了文本和视觉头联合训练的0.5B模型,发现尽管QA准确率较低,但在动作状态预测和L2误差方面表现更好,证明了DrivePI在统一文本理解、3D感知、预测和规划方面的有效性。
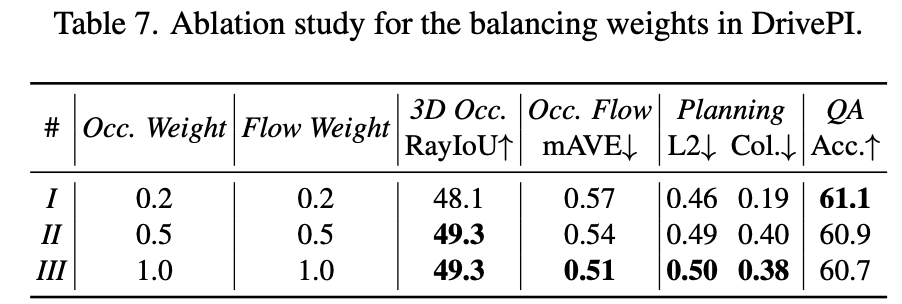
多任务学习平衡权重研究
为了探究多任务学习中不同损失平衡权重的影响,我们进行了系统性实验。通过初步分析,我们观察到3D占用和占用流损失在总损失函数中占主导地位,约占合并损失幅度的60%以上。为了缓解潜在的优化不平衡,我们系统地将3D占用和占用流任务的权重从默认值1.0降至0.5和0.2。
实验结果表明,较高的占用和流权重在3D占用和占用流任务上产生更好的性能,但在规划准确性(L2误差)和文本理解QA任务上略有降低。这表明在多任务学习中设置适当的平衡权重仍然具有挑战性。为简单起见,我们在最终实现中采用了3D占用和流损失的默认权重1.0。
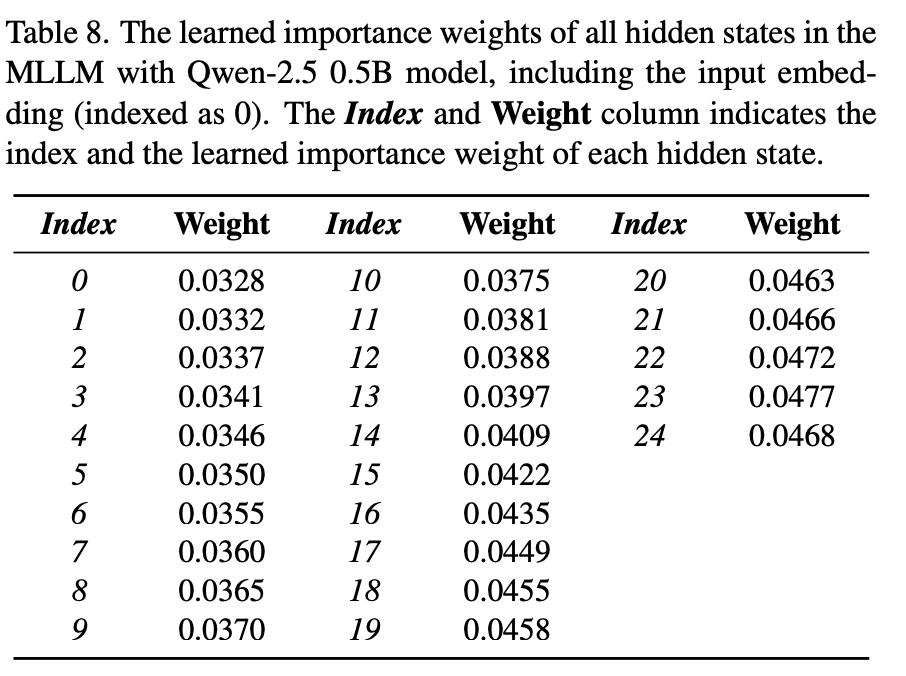
MLLM隐藏状态重要性权重分析
我们还研究了MLLM中各隐藏状态的重要性权重。具体来说,我们将默认仅使用最后隐藏状态的设置替换为加权组合:h = ∑(i=0 to l) F_i^h · w_i,其中F_i^h表示第i个隐藏状态的特征,w_i是相应的可学习重要性权重,l表示MLLM中隐藏状态的总数。
分析结果显示,更深层的网络层倾向于获得更大的权重,这表明由更深的Transformer层提取的高级特征对DrivePI的有效性更为关键。这一发现为理解MLLM在自动驾驶任务中的工作机制提供了有价值的见解。
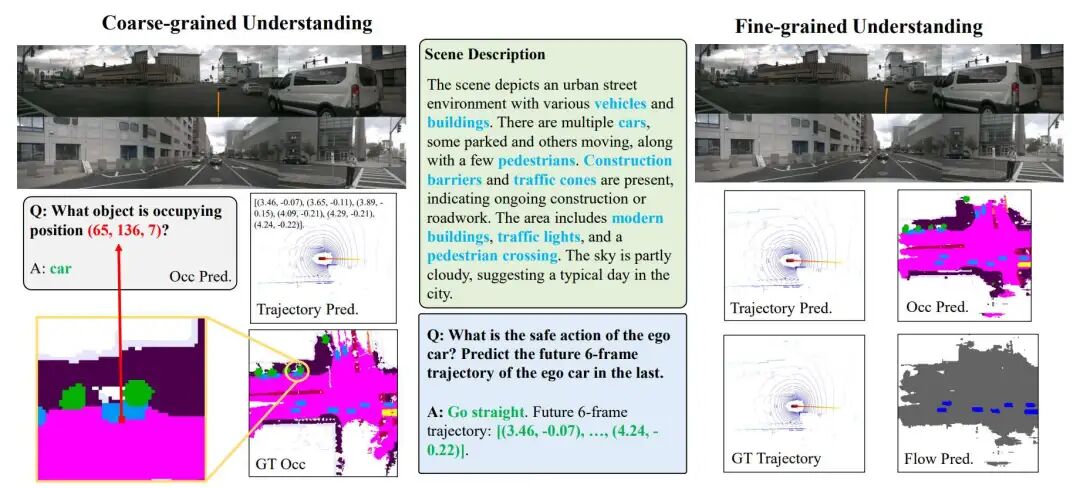
可视化结果
DrivePI能够同时生成场景描述、3D占用、占用流、动作和轨迹预测的可视化结果。在粗粒度层面,它能根据不同指令生成详细的场景描述和合理的回答;在细粒度层面,它通过专门的解码头生成精细的结果。
我们观察到两个重要现象:首先,DrivePI能够理解详细的外观信息(如"天空部分多云"),表明视觉编码器在将前视图图像转换为鸟瞰图表示时有效地保留了关键的视觉信息。其次,粗粒度和细粒度预测之间存在很强的一致性,例如,在粗粒度层面上描述的对象类别与在网格坐标(65,136,7)处的细粒度3D占用预测相对应。这种不同理解层次之间的一致性验证了DrivePI在统一粗粒度语言空间理解与细粒度3D感知能力方面的有效性,增强了自动驾驶系统的可解释性和可解释决策能力。
更多场景可视化分析
为了进一步展示DrivePI的能力,我们提供了更多场景的可视化分析:
静止等待场景:在复杂拥堵的环境中,DrivePI能够生成准确的3D占用和流预测,并成功实施适当的静止等待动作。
直行驾驶场景:在这类场景中,DrivePI展示了粗粒度和细粒度理解之间的高度一致性,能够准确预测前方道路情况并规划合适的直行轨迹。
夜间转弯场景:这类场景通常对VLA模型具有挑战性。利用多模态信息,DrivePI能够在非常暗的图像条件下准确描述环境,并生成合理的转弯轨迹,展示了其在低光照条件下的鲁棒性和有效性。
这些额外的可视化分析进一步证明了DrivePI在各种复杂驾驶场景中的卓越性能和适应能力。
📈 主要贡献
提出了DrivePI,首个统一的空间感知4D MLLM框架,无缝集成粗粒度语言空间理解与精细3D感知能力,弥合自动驾驶中基于视觉和基于VLA范式之间的差距。
将激光雷达作为相机图像的补充传感模态,提供高精度3D几何信息,更好地激发MLLM的空间理解能力。此外,DrivePI支持精确的3D感知和预测,有效增强可解释性和安全保障。
尽管仅使用紧凑的0.5B参数MLLM主干网络,DrivePI在3D占用和占用流预测方面甚至优于现有的基于视觉的模型,同时在自动驾驶中保持与现有VLA框架相当的交互能力。
🔮 未来展望
DrivePI作为一个新的VLA框架,有望启发未来研究,通过语言推理和精细的3D输出,增强自动驾驶系统的可解释性和可解释决策能力。我们期待这种统一框架能够为自动驾驶领域带来新的研究方向和应用可能。
更多关于自动驾驶前沿的技术进展,欢迎加入「自动驾驶之心知识星球」!

自动驾驶之心
3DGS理论与算法实战课程!


















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









