



作者 | SPiriT 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1888242399811175395
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
原文信息:
https://hgao-cv.github.io/RAD/
TLDR
il:imitation learning ; rl:reinforcement learning
做了什么?
第一个提出基于 3dgs 来进行 rl 用来做 e2e policy。分以下三步走:
训练一个基础的 bev 和 perception model
freeze感知,用 il 方式训练一个 planning head
基于上面的 planning head,用 3dgs 生成 sensor level 的 env,用 rl + il 混着训
有啥提升?
主要是碰撞率相比纯 il 少了 3 倍
有啥局限?
3dgs-env缺乏交互,只是log replay;3dgs 渲染非刚性行人、视野外信息、低光场景等效果不行
个人总结
总体来说,读起来不费劲,行文舒服、图文清楚、实验充分,有很实际的工程化改进。核心亮点是使用 3dgs 来构建 sensor-level 的 env,最后结果确实比 il 的方案要好一些。
工程化改进较多,比较务实,不那么纯 rl,比如辅助 task、il & rl mix training 等等。
其中对于辅助 task,rl 只贡献了 gae 作为 loss_weight,感觉像是 trajectory-level 的 loss,消融实验也显示没 ppo 那套loss也能改进指标。对于 il & rl mix + event reset,本质都是为了限制 rl 的探索,核心原因有 2 个:一个是缩小 rl的搜索空间,加速收敛;第二个是尽量保证和 expert traj 偏差不大,毕竟轨迹偏离太远 3dg-env就 G 了。不过最开始看 il 做 norm 以为是从 loss 角度,最后发现是 mix train,不知道在 loss 里面加入 kl_penalty 会不会没这么硬。最后文中说的 env-intersect 和 3dgs noisy sensor,很限制 rl 的探索上限了
论文细节
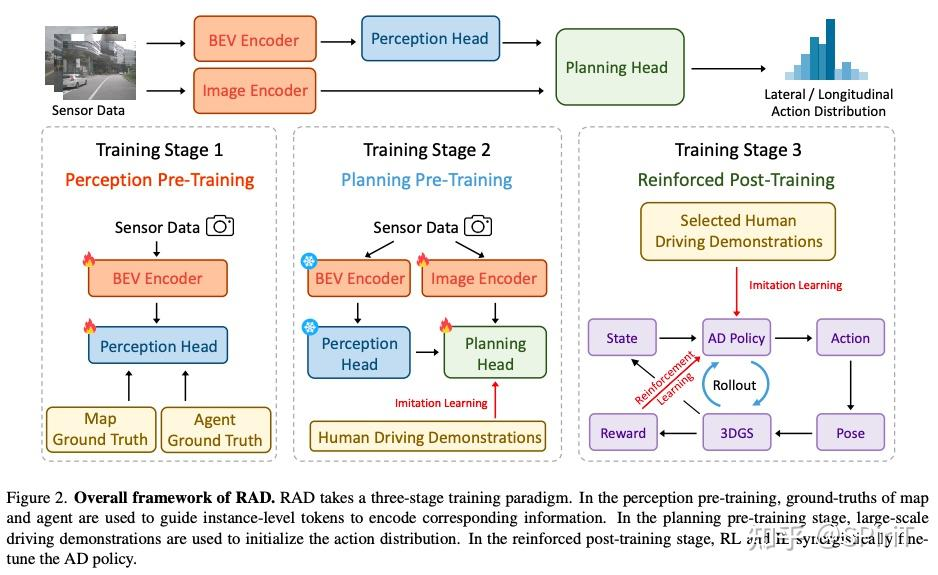
整个流程如上。RAD接受多视角图像输入,输出动作的概率分布,最后从中采样动作控制车辆。
状态空间
bev encoder:常规操作,从 multi-veiwe image学一个 instance-level bev feature
map head:从 bev map 中学静态地图元素,包括centerline、lane divideer、boundary、arrows 这些
agent head:学习交通参与者的运动信息,包括location、orientation、size、speed 这些
image encoder:和上面并行,从图像中学习 planning 相关的特征
planning head: 用 作为场景表示(包括map \ agent \ image token), 是 planning 的 embedding,用 Transformer decoder 结构,其中 作 query, 作为 key 和 value。
动作空间
0.5s 一帧,在这个期间内假定车辆的线速度和角速度不变
动作分为横向动作 和纵向动作 ,解耦横纵向。具体定义如下:
其中 , , 。横向是 -7.5m 到 7.5m 之间,离散化 61 个动作,间隔 0.25m 为一个横向移动距离;纵向是 0 到 15m 之间,同样是 61 个动作,每 0.25 一个 gap。结合状态空间和动作空间,策略和值函数可以表示为
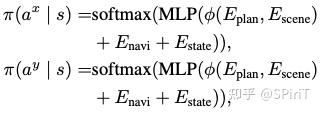
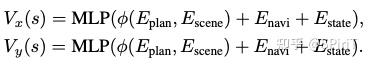
奖励函数
设计目标:惩罚不安全的动作 + 鼓励对齐专家轨迹,所以有 4 个奖励:
:dynamic_collision,动态碰撞,ego 和 动态物体的 bounding box 重合时给负。
:static_collision,静态碰撞,类似同上
:postional deviation ,位置偏差(横向偏差),计算当前位置和专家轨迹投影点的欧氏距离,大于阈值给负。论文里阈值是 2.0m
:heading deviation ,同上,当前朝向和专家匹配点的朝向 diff,大于阈值给负。论文里阈值是 40°
注意:当这些事件发生时会直接 done 掉环境,因为触发这些事件时 3dgs-env通常会产生 noisy sensor data,对 rl训练有害。(简单说就是偏差太大或者碰撞,重建数据就乱了,环境会 G)
训练流程
感知预训练:训练 agent_head 和 map_head,隐式编码高级信息,这个阶段只更新 bev encoder \ map head \ agent head 的参数
规控预训练:il方式,从大规模的人类专家数据中学习动作概率分布,冻结感知参数,只训练 image encoder 和 planning head
强化后训练:rl + il,一起 fine-tune。rl 目的是引导策略对关键风险场景更敏感,适应分布外的情况。il 作为正则项保证策略行为和人类相近。如下图
具体而言,从收集的数据中选了大量危险的交通拥堵clip,每个 clip 独立训练 3dgs model 重建场景作为 env。剩下就是 rl 的常规操作了,并行 N个 worker,随机选择一个 3dgs-env 进行 rolllout,把 transition 存在 buffer 里,结束后随机选择下一个3dgs-env。
policy 和 env交互的动作,用简单的自行车模型来计算下一步的位置:
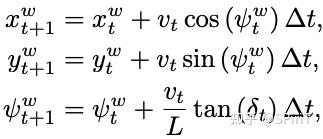
策略优化环节,分别用 ppo 算法和 il 一起优化 policy,训练一定步数后,新 policy 替换掉老 policy.
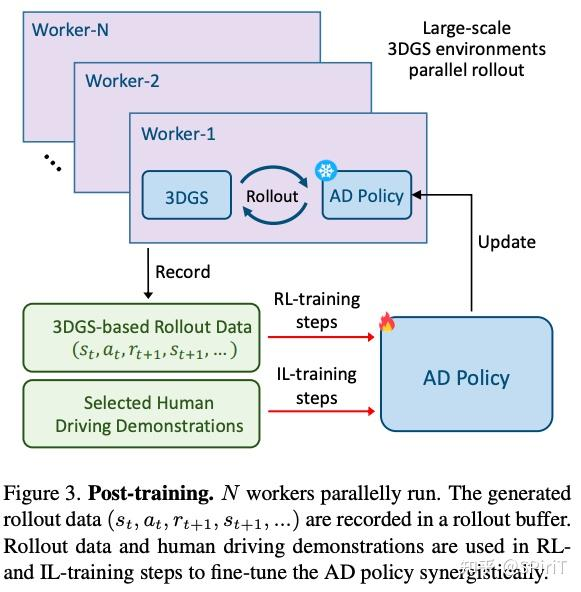
训练细节
整个训练里面都分成横向和纵向两个部分,完全两个解耦的并行任务设定。
其中 reward 也按照横纵向来分配归属,除了 dynamic_collision 是纵向的 reward,其他都属于横向 reward。
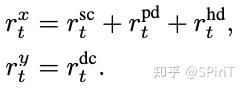
最后的优化目标也是 2 个部分,如下:
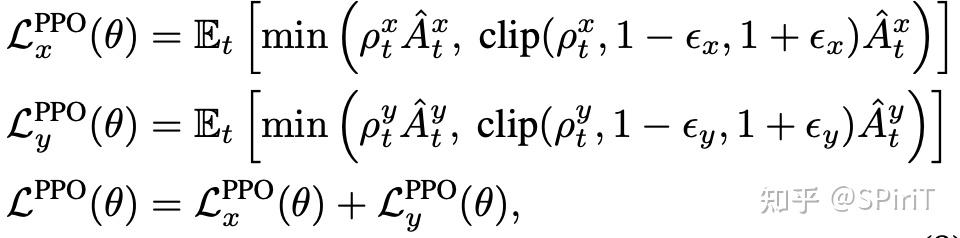
辅助任务
为了稳定训练加速收敛,文章设置了一些辅助目标引导整个动作分布,结合特定的奖励来惩罚不好的行为。这里有分为“减速“ 、 “加速“、“左转“、“右转“这 4 个部分。
这里拿“减速“这个行为来举例,它在动作上和纵向 有关,在奖励上和前面的“动态碰撞“[dc]有关。引入了如下的一个定义。
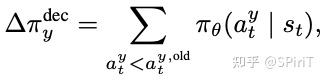
定义为时序上纵向 比旧的纵向 小的概率之和。
比如一条轨迹上有 5 个 timestamp,旧的纵向输出是 ,新的纵向输出 。从第 3 帧开始,新的纵向移动要比老的小【也就是刹车减速更厉害了】。
同时,假设新策略每一步的决策概率分别是 【也就说越来越确定】。根据前面的定义,我们可以得到 。
同理,对于 “加速” 行为,上面的例子里面,只有第 2 帧时新的>老的,所以
那下一步,对于这些减速、加速行为怎么定义偏好或者 loss呢?答案就在前面的 reward 设计里。如果在第 t 时刻发现车辆前面要发生动态碰撞,那么在 t 时刻应该鼓励“减速“行为。相反,车辆后面要发生碰撞,则鼓励“加速“行为。文章用下面的公式形式化表达这个偏好:

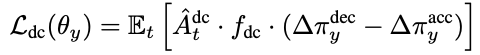
其中 就是 对应的 gae.
按照上面的逻辑,纵向有 2 个分别是“减速”和“加速”,横向也有 2 个: 、 ,分别用来计算“横向位置偏差的辅助目标”和“纵向朝向偏差的辅助目标”。
综上所述,辅助任务目标和所有的优化目标,分别如下:
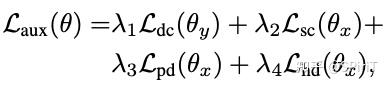
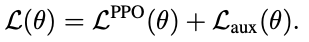
以上基本上就是大部分的技术细节了,下面来看看数据和实验指标。
数据情况
第一阶段:收集 2000h 真实人类驾驶数据,用低成本的自动化标注获取 gt
第二阶段:用里程计数据作为第二阶段监督学习的 gt
第三阶段:选择4305个关键场景用 3dgs重建 env,3968个训练,337个评测
指标设计:
动态碰撞率 DCR + 静态碰撞率 SCR = 碰撞率 CR
位置偏离率 PDR + 朝向偏移率 HDR = 偏移率 DR
平均偏移距离 ADD:描述碰撞和偏差发生时,和专家轨迹最近点的距离
实验结论
reward 设计:合适调参,所有的 reward 都有用;尤其 dc_reward 对减少碰撞有效
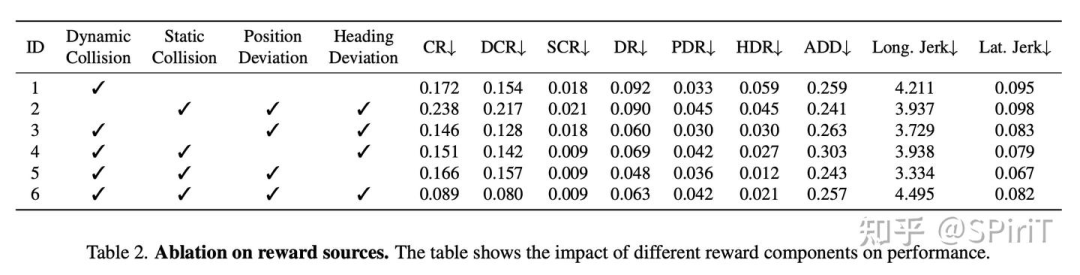
辅助任务设计:所有的都有用,结合 ppo后 cr可以更低。

训练配比:rl 和 il 数据比是 4:1 时最优
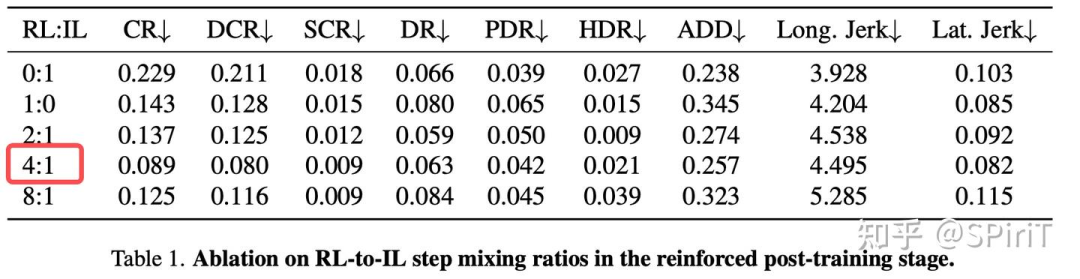
rl 必要性研究:和其他 il-based 算法比,指标都更好。说明了闭环训练的优势在于能更好处理动态环境

其他细节
对于 planning 的预训练,设置了一些 anchors: ,用最近邻匹配去匹配 gt: 。最后优化 loss 就是 dual focal loss
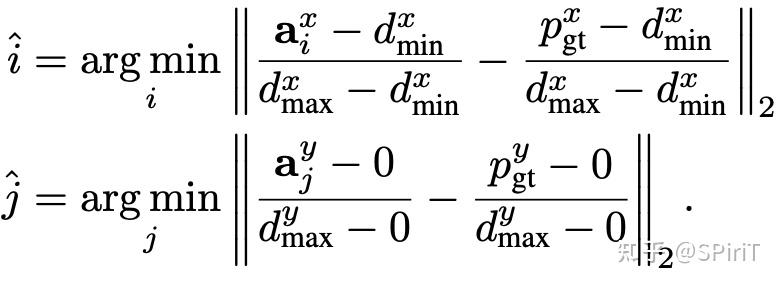
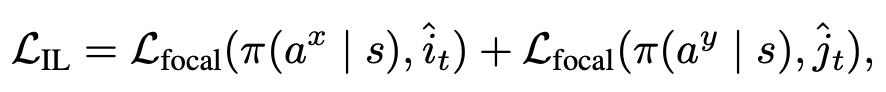
以上。
最后也推荐下自动驾驶之心打造的「3DGS理论与算法实战教程」,课程全面复盘了3DGS各个子领域的发展,从2DGS/3DGS/4DGS再到自动驾驶领域应用,以及最新的前馈GS。课程即将开课,欢迎大家加入学习!



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









