



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
去年年底,leader找我聊了下今年的工作方向:从感知转VLA。所以年初至今做了也差不多一年的时间,从调研、预研再到落地,也算阶段性告一段落。
这一年,从学术界的论文爆发到工业界的量产落地,前几个月的世界模型和VLA路线之争,前两周小鹏官宣VLA2.0。笔者也在琢磨如何把这一年的经验做一些总结输出,这两周把思路理了理,所以有了这篇文章分享给自动驾驶之心的小伙伴。我将从以下几个方面和大家聊聊:
到底什么是 VLA ?
为什么会出现 VLA?
VLA 架构拆解:从输入到输出
VLA 的发展编年史
笔者总结
希望可以给做相关方向的朋友提供点参考。
到底什么是 VLA ?
最近在自动驾驶的圈子里,VLA 模型可谓是炙手可热,多数主流的算法供应商和主机厂,都在宣称自己的 VLA 模型有多牛(尤其是理想和小鹏的发布会)。所以想最近借这个势头总结一下,VLA 到底是什么?到底能不能成为继端到端和 VLM 之后的下一代自动驾驶范式?
首先,要明确,这个概念并非诞生于自动驾驶的圈子,而是来源于机器人控制领域:早在 2023 年由 Google DeepMind 提出来的 RT-2 模型中就用到这样的技术来控制机器人。那为什么到 2025 年的今天,在自动驾驶圈子里炒的火热呢?这个先卖个关子,待会解释。
先来看看维基百科是如何定义 VLA 的:
In robot learning, a vision-language-action model (VLA) is a class of multimodal foundation models that integrates vision, language and actions.
Given an input image (or video) of the robot's surroundings and a text instruction, a VLA directly outputs low-level robot actions that can be executed to accomplish the requested task.
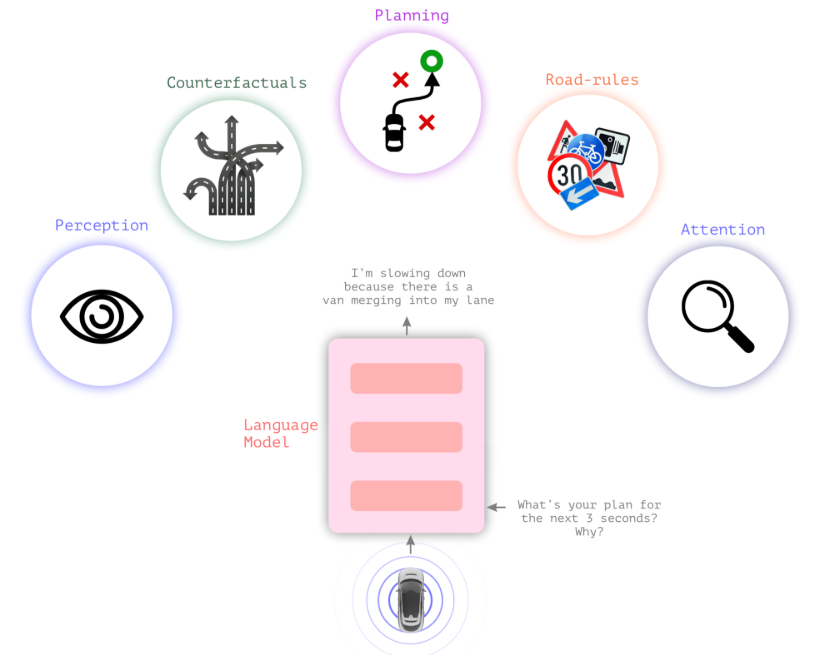
比较 high-level 地说,VLA 模型就是一个“多模态大脑”,它能看得懂画面(Vision),听得懂语言(Language),并且能直接做出行动决策(Action)。
如果从工科中输入输出的角度来定义,就是:“输入是 image 和 language, 输出是 action 的模型”。很多读者都听过这样类似的定义,但是可能理解尚浅。笔者这里写写自己的见解:
Vision 表示输入是 images 或者 videos,帮助理解场景,这是非常基础的输入。
Language 可以分为
verbal language和text language,即语音和文字输入。Action 可以理解为
action in language和output action两种。
举个简单的例子:
一辆搭载 VLA 模型的自动驾驶车辆,它不仅能自己开车,还能解释自己为什么这么开,甚至能听懂人类的指令。“解释自己为什么这么开”,其实就是 text language, 它生成了描述当前场景的便于人类理解的文本信息。“理解人类指令”就会涉及到 verbal language 和 action in language。比如司机对它说 “前面有点窄,请小心点过”,前半句其实就是 verbal language,人类提供了一个场景描述,模型需要理解人类的语言,而后半句也是人类提供的一个 action 指令,辅助模型去生成正确且有效的 action。最后模型 decode 出一个合理的轨迹或者说 action,即为最终的 output action。
为什么会出现 VLA?
在自动驾驶的发展史上,其实一路走来可以分为几个阶段:最早是(阶段一)模块化流水线,把感知、预测、规划、控制拆开,一个个子系统各司其职;后来大家觉得这样容易出错、信息割裂,于是开始尝试(阶段二)端到端,直接从传感器画面到控制信号。但很快问题来了——端到端黑箱虽然酷,但解释性差,遇到稀奇古怪的场景就容易懵。而在现实道路上,恰恰是这些长尾场景最容易要命。这也是目前自动驾驶要解决的问题。
于是大家又把目光投向了大模型。(阶段三)Vision-Language Model(VLM)的出现,让车子不光能“看”,还能“说”。比如,它能解释为什么要停车,甚至能对救护车鸣笛做出合理判断。这大大增强了可解释性和泛化能力。但问题是,VLM 还停留在“说”的层面,不能直接“做”。场景解释再漂亮,最后还是得交给传统模块去控制方向盘和油门,语言和行动之间隔着一道“行动鸿沟”。
这时,(阶段四)VLA 模型应运而生。它把视觉、语言和动作整合到一个统一框架里,既能理解人类的自然语言指令,比如“在路口礼让救护车”,也能基于视觉感知做出推理,并且直接生成具体的驾驶行为。换句话说,VLA 把“看、想、做”这三件事打通了,真正实现了从感知到推理再到控制的一体化。
更关键的是,VLA 模型继承了大模型的语义先验,能够在少见甚至未见过的场景下借助常识来“补脑”。比如,遇到被遮挡的行人、自行车突然加速冲出,VLA 模型能结合语境和视觉线索,推理出潜在风险并采取措施。这正是传统端到端模型最头疼的地方。
所以,总结一句话:VLA 的出现,是因为模块化太死板、端到端太黑箱、VLM 又停留在解释层面。只有把视觉、语言和行动真正统一,自动驾驶才能既聪明又靠谱,既能听懂人话,也能安全开车。
VLA 架构拆解:从输入到输出
输入端
和传统自动驾驶只依赖传感器不同,VLA 的输入其实更“贪心”,它要同时吸收多种模态:
视觉输入: 来自前向、环视摄像头的图像是基础,进一步还会转换为 BEV(鸟瞰图)或体素表示,用来理解空间关系。相比单纯 2D 画面,BEV 能更直观地描述“车与车、车与人”之间的相对位置。
传感器输入: LiDAR 提供精准的 3D 几何结构;RADAR 对动态物体尤其敏感;IMU 和 GPS 补充位姿与定位。它们和视觉互补,让模型能在雨雾、夜间甚至复杂天气中保持鲁棒。(当然,这里指的是 general 的方案,也是存在一些企业做纯视觉 VLA 方案,比如:小鹏)
语言输入: 这是 VLA 的核心差异点。它不仅能理解导航指令(如“在下一个路口左转”),还支持问答式交互(“现在能不能超车?”),甚至可以理解规则约束(“在校区范围内限速 30”)。我觉得,在更前沿的设计里,语言输入还可能来自车内乘客的自然对话,真正让自动驾驶系统成为“能听人话的司机”。
中间层
这一层是 VLA 的“大脑”,负责把各种输入整合并转化为合理的驾驶决策。
视觉编码器: 负责把图像、点云等转成高维特征。主流方案是用大规模预训练模型(如 DINOv2、ConvNeXt-V2、CLIP)作为 backbone。它们不仅捕捉空间结构,还能借助 BEV 投影理解三维环境。有些模型甚至会做跨模态对齐,把视觉和语言嵌入映射到同一语义空间。
语言处理器: 大多是 LLaMA、GPT 等 LLM 的变体。通过指令微调(Instruction Tuning)、参数高效适配(LoRA)、检索增强(RAG)等方法,模型能针对驾驶场景“学会交流”。它不仅能理解乘客指令,还能做语义推理:比如 Chain-of-Thought(链式思维)分解任务,“先判断路况 -> 再规划变道 -> 最后控制执行”。
动作解码器: 这是 VLA 的“执行意图生成器”,直接决定它能不能安全地“把车开好”。
序列式预测:把未来轨迹点或离散动作 token 化,然后像写句子一样逐步生成。
扩散模型解码:在连续空间里采样轨迹,更平滑,抗干扰性更强。
分层控制结构:高层用语言生成子目标(如“并道后保持 60km/h”),底层再通过 PID/MPC 做精确控制,实现策略与物理执行的结合。
输出端
VLA模型的输出形式可以大致分为低阶和高阶两种层面的输出:
低层控制指令: 直接输出油门、刹车、方向角等信号,保证车辆的即时反应速度。这类输出适合动态场景,比如应对突然出现的行人。
轨迹规划: 输出未来 2-5 秒的连续路径,让驾驶更平稳、更安全。相比瞬时控制,轨迹输出更便于与现有自动驾驶堆栈融合。
VLA 的发展编年史
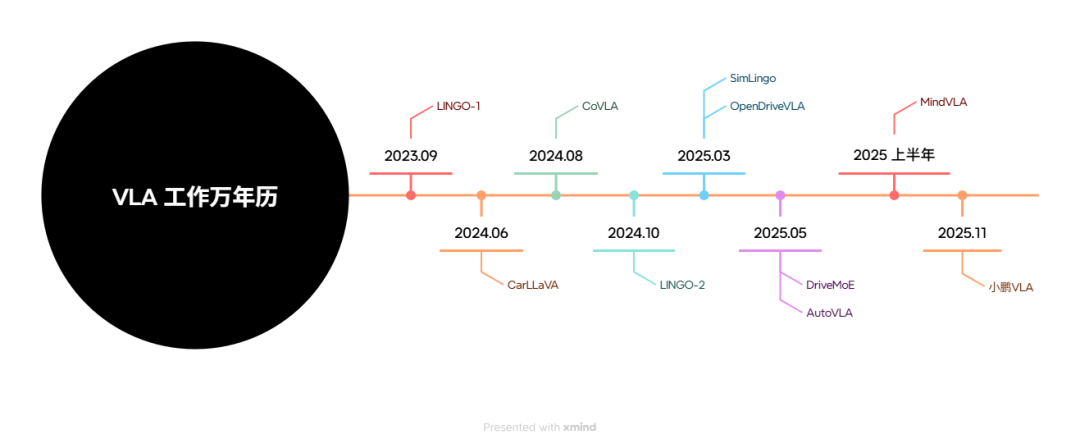
LINGO-1
提出时间:2023.09(其实初始idea还挺早的)
提出机构:Wayve
论文链接:https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/
研究背景:在此之前,自动驾驶系统都采用模块化设计,也就是把感知、预测、规划这些任务拆成几个独立的“黑箱”模块。这种架构导致系统比较复杂、不太好理解,而且各个模块之间的错误还容易层层叠加。另一方面,人类司机其实能够很轻松地用自然语言理解和解释驾驶场景和行为,这一点恰恰是传统自动驾驶系统所不具备的。所以,开始探索怎么把自然语言融入到自动驾驶里,希望构建一个更智能、更可解释、能像人一样“思考”的端到端系统。
论文内容:LINGO-1 的核心是一个基于视觉-语言-行动(VLA)的驱动模型。说的再具体一些:
从架构上说:模型建立在端到端的驾驶模型基础上,将视觉编码器、大型语言模型(LLM)和驾驶解码器相结合。它能够接收多模态输入,包括视频帧和车辆的控制动作(行动)。
从功能上说:LINGO-1 具备三种关键能力:
可解释的驾驶:它在输出驾驶动作的同时,还能用自然语言给出它的“推理过程”,解释它为什么会做这个操作,比如它会说:“因为前面那辆车在减速,所以我也轻踩了一下刹车”。这样就大大提高了系统的透明度和可信度。
视觉问答(VQA):用户可以就驾驶场景向模型提问(如“为什么你要变道?”),模型能够根据视觉信息给出准确的回答。
驾驶知识推理:通过在大规模语言模型中嵌入的常识和推理能力,LINGO-1 能够理解复杂的交通规则、社交礼仪,并处理罕见的长尾场景,这是传统 if else 方法难以实现的。
其实,总结来说,LINGO-1 探索的是把“描述”和“行动”统一起来的可能性。它不只是单纯地执行驾驶指令,而是试图构建一个能像人一样,用语言去理解世界、解释行为、并进行推理的自动驾驶智能体。这项研究也标志着,自动驾驶正在从传统的“感知-规划-行动”链条,向融合了“解释”和“交互”的更高级智能形态,迈出关键的一步。
CarLLaVA
论文标题:CarLLaVA:Vision language models for camera-only closed-loop driving (CARLA Autonomous Driving Challenge 2024)
提出时间:2024.06
提出机构:Wayve, University of Tubingen, Tubingen AI Center
论文链接:https://arxiv.org/pdf/2406.10165
研究背景:自动驾驶研究当时正转向端到端范式,但顶尖方法大多依赖昂贵的激光雷达传感器和复杂标注(如BEV语义、深度图),限制了其在真实世界的可扩展性。同时,传统的CNN视觉编码器可能无法充分理解复杂的驾驶场景。另一方面,在大规模网络数据上预训练的视觉语言模型展现出强大的视觉理解和推理能力。因此,研究如何利用VLM的强大能力,构建一个仅需摄像头输入、无需昂贵标注的高性能自动驾驶系统,成为一个极具价值的方向。
论文内容:提出了 CarLLaVA,一个基于视觉语言模型的端到端自动驾驶系统,其核心目标是仅使用摄像头输入,在不依赖昂贵传感器(如激光雷达)或复杂标注的情况下,实现最先进的闭环驾驶性能。
其主要内容与创新点包括:
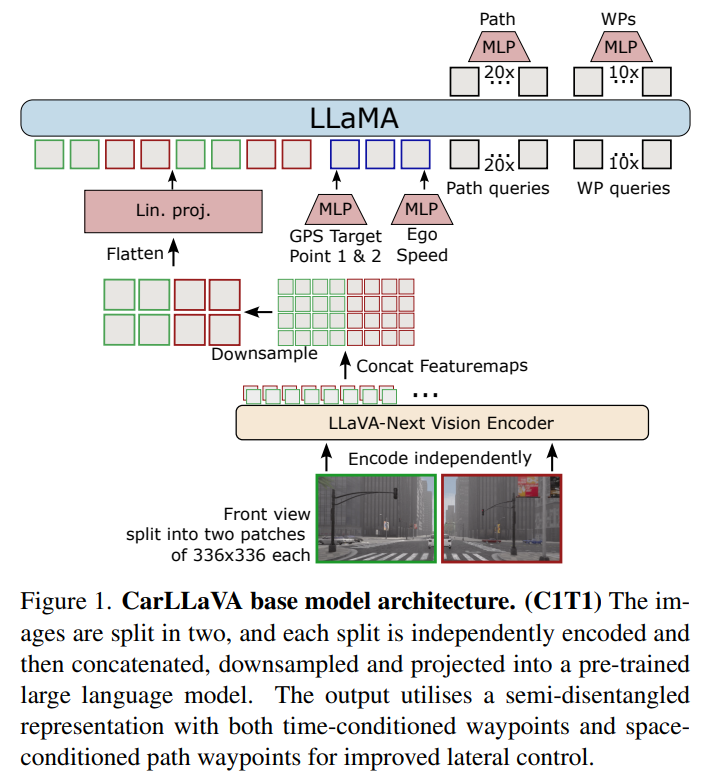
架构设计:模型采用 LLaVA-NeXT 的视觉编码器和 LLaMA 架构作为主干。为了应对驾驶任务对细节的高要求(如识别远处的交通灯),它采用了高分辨率图像输入和分块处理技术。模型输入包括前置摄像头图像、下一个目标点和自车速度。
半解耦输出表示:这是一个关键创新。模型同时预测时间条件航点(用于纵向控制,如速度调节)和空间条件路径点(用于横向控制,如转向)。这种设计结合了两种表示的优点,提供了更密集的监督信号,显著改善了转弯和绕障时的转向性能,有效减少了与静态布局的碰撞。
高效的训练方法:由于驾驶数据中大部分是简单的直线行驶,直接训练会浪费算力。为此,作者提出了一种“数据分桶”策略,在训练时侧重于对加速、减速、转向、危险场景等“有趣”的样本进行采样,从而大幅提升训练效率。
CarLLaVA在CARLA自动驾驶挑战赛2.0中取得了第一名,其驾驶分数远超之前的顶尖方法,证明了该方案的有效性。也为之后大模型在自动驾驶中的应用,奠定了基础。
(WACV) CoVLA
论文标题:CoVLA:Comprehensive Vision-Language-Action Dataset for Autonomous Driving
提出时间:2024.08
提出机构:Turing Inc
论文链接:https://arxiv.org/pdf/2408.10845
研究背景:作者认为:当时,自动驾驶技术面临的最大难题,就是怎么应对现实世界中那些复杂又少见的“长尾”驾驶场景。这就要求系统不仅要能感知环境,更要有推理和规划的能力。而视觉-语言-行动模型这条路,正好把视觉、语言理解和行动规划结合在了一起,看起来很有希望。不过,这个领域现在有个很大的瓶颈,就是缺少大规模、高质量、同时包含视觉画面、详细语言描述和精确行动轨迹的数据集,这直接限制了更可靠、更可解释的端到端自动驾驶模型的研发。
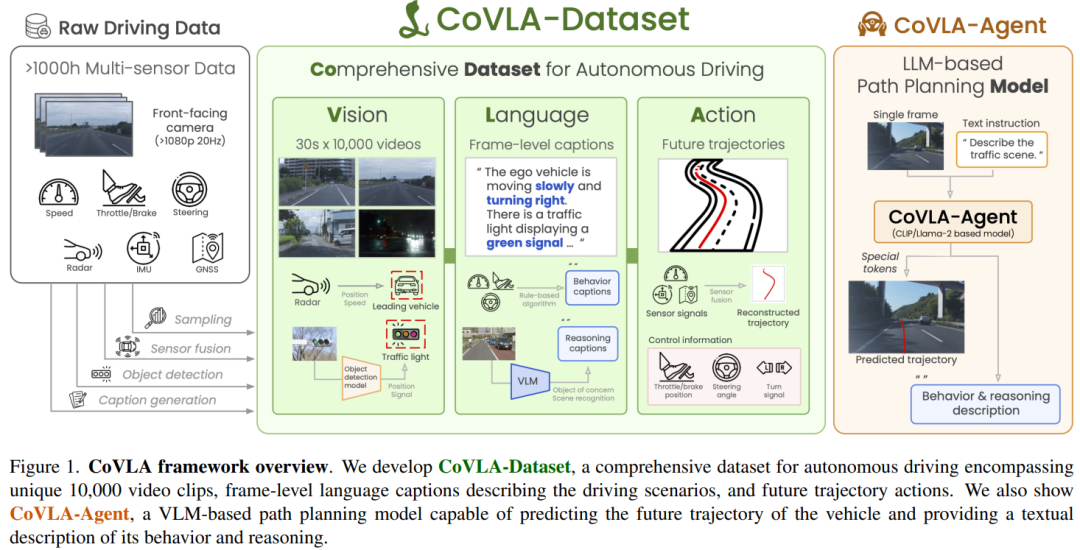
论文内容:核心贡献是提出了一个名为 CoVLA 的大规模综合视觉-语言-行动数据集,旨在解决自动驾驶研究中多模态数据稀缺的问题。
该数据集包含超过80小时、1万个真实世界的驾驶场景,并通过一种新颖、可扩展的自动化流程进行标注。其构建过程包括:
数据采集与采样:作者用装了前向摄像头、CAN总线、GNSS和IMU的车辆,在日本东京及周边地区采集了超过1000小时的原始驾驶数据。然后通过一套加权的采样策略,从中精选出1万个30秒的场景,确保覆盖各种不同的驾驶行为,比如转向、加速等等。
自动标注:作者利用传感器融合和卡尔曼滤波技术,为每一帧数据都生成了未来3秒的精确车辆轨迹。同时,还用深度学习模型自动检测交通灯的状态和前车信息。
自动描述生成:作者采用了一种两阶段的方法,结合规则生成和视觉语言模型,为每一帧画面生成详细的自然语言描述。规则部分保证了关键驾驶信息(比如速度、交通灯)的准确性,而VLM部分则补充了环境细节(像天气、道路类型),并且有效减轻了模型的“幻觉”问题。
基于CoVLA数据集,作者还开发并评估了一个叫 CoVLA-Agent 的基线VLA模型。这个模型能同时完成交通场景描述生成和轨迹预测两个任务。
实验结果显示,它生成的语言描述和预测的轨迹之间高度一致。比如说,当模型描述为“直行”时,它预测的就是直行轨迹;描述“右转”时,就预测右转轨迹。这说明CoVLA数据集确实能有效训练出可解释的端到端驾驶模型,为作者今后用VLA模型构建更可靠、更透明的自动驾驶系统打下了基础。
LINGO-2
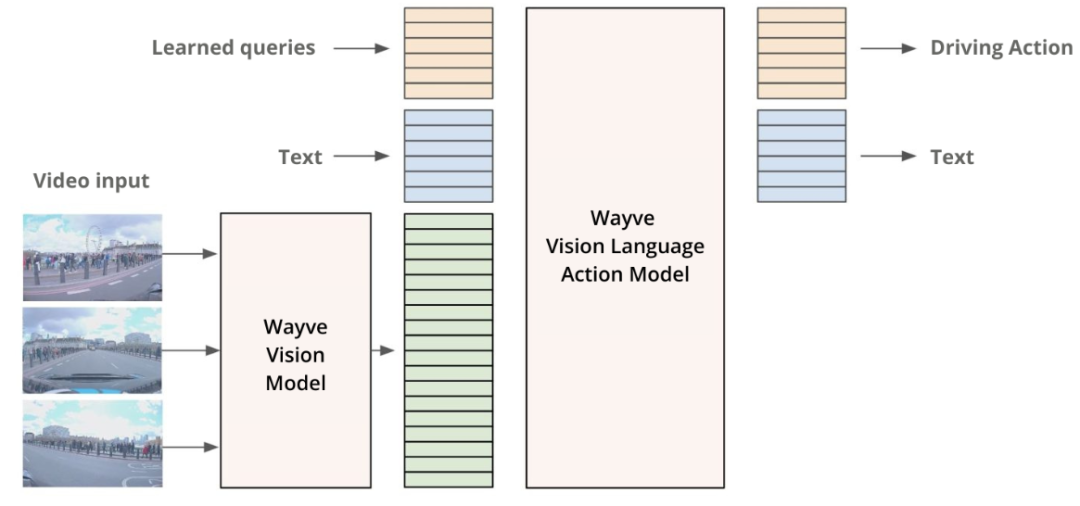
提出时间:2024.10
提出机构:Wayve
论文链接:https://wayve.ai/thinking/lingo-2-driving-with-language/
研究背景:LINGO-2 的研究建立在 LINGO-1 成功探索的基础上。LINGO-1 证明了自然语言可以为自动驾驶提供可解释性,但其功能主要局限于“评论”驾驶动作为主。为了构建真正通用、能与环境及乘客自然交互的自动驾驶系统,需要模型具备更深入、更实时的语言-驾驶融合能力。LINGO-2 就是在这样的背景下,目标在实现从“用语言解释驾驶”到“用语言交互并影响驾驶”的跨越,让车辆能像人类驾驶员一样理解和响应语言指令。
论文内容:LINGO-2 是 Wayve 在视觉-语言-行动模型领域的一次非常重大的升级,它不再仅仅是一个评论驾驶的模型,而是一个能够通过自然语言进行开放式视觉语言导航和驾驶交互的端到端系统。
其核心突破在于它实现了真实世界中的指令跟随与交互式驾驶。具体来说:
驾驶问答:与 LINGO-1 类似,它可以回答关于驾驶场景的开放式问题,但其理解能力和准确性比第一代更高。
指令跟随:这是 LINGO-2 的一个比较标志性功能。模型能够直接理解并执行乘员发出的自然语言指令,例如“在下一个路口右转”、“在前面的蓝色车后面停车”或“找个地方靠边停一下”。这标志着模型能将高级语言目标转化为具体的、安全的驾驶动作。
交互式驾驶:LINGO-2 能够处理更复杂的交互式指令,如在环岛中“跟着前面的黑色货车”,或在停车场中根据“向左转,然后在右边找个空位”的指引进行操作。这要求模型具备非常强大的动态的场景理解和持续的指令执行能力。
为实现这些功能,LINGO-2 采用了更强大的基础模型、经过精心策划的大规模多模态数据集进行训练,并引入了称为“DrivePrompt”的推理时技术,该技术将当前场景、驾驶历史和语言指令融合,以生成符合指令的安全驾驶行为。
其实,本质上,LINGO-2 将大型语言模型的推理能力与端到端驾驶模型的操控能力深度结合,证明了自然语言可以作为人车协作与控制的直接、高效接口,为实现更智能、更适应人类需求的自动驾驶系统铺平了道路。
(CVPR2025) SimLingo
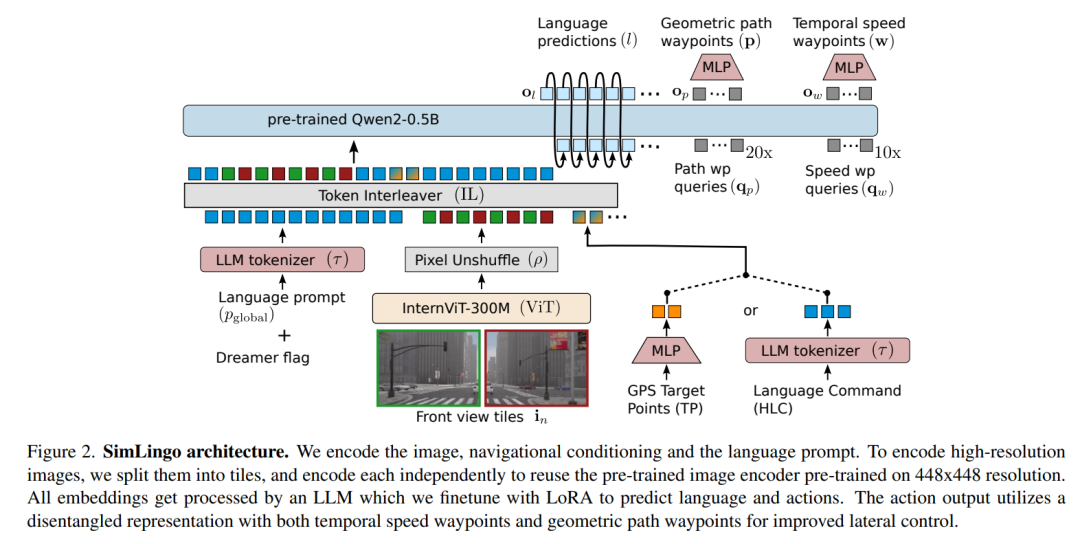
论文标题:SimLingo:Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
提出时间:2025.03
提出机构:Wayve, University of Tubingen, Tubingen AI Center论文链接:https://arxiv.org/pdf/2503.09594
研究背景:现在很多人都希望把大语言模型用到自动驾驶系统里,指望它能提升系统的适应能力和可解释性。不过,现有的研究大多只聚焦在提升驾驶性能,或者只关注视觉语言理解,很难两头都兼顾。更关键的是,现在常用的视觉问答评估方式,有时候会和模型的实际驾驶动作对不上——比如模型嘴上说“看到红灯了”,但行动上却还在加速。这种“说一套做一套”的情况,导致语言理解没法真正为驾驶决策提供可靠的依据,也限制了它的实际应用价值。
论文内容:提出了 SimLingo,它是一个视觉-语言-行动模型,目标是一次性搞定三个核心任务:闭环驾驶、视觉语言理解,以及非常关键的 语言和行动对齐。
这个模型的核心创新和内容主要包括:
统一架构与多任务学习:SimLingo 基于 InternVL2 架构,只靠摄像头输入。它在一个模型里同时处理驾驶决策(比如预测轨迹和路径点)、回答关于驾驶场景的视觉问题、生成驾驶评论,并且能根据语言指令实时调整驾驶动作。这样的设计让它成为一个真正通用的驾驶智能体。
“行动梦想”任务与数据集:为了解决语言和行动脱节这个核心问题,作者提出了一个创新的任务叫“Action Dreaming”,还配套开发了数据收集方法。具体来说,是通过离线模拟,在同一个视觉场景下生成多种可能的指令-行动组合(比如加速、变道,甚至是“驶向某物体”),这样模型就不能只依赖视觉线索,而必须认真理解语言指令才能做出反应。这有效确保了语言理解能真正影响到行动输出。
语言-行动对齐的验证:通过“Action Dreaming”任务的评估,SimLingo 展现出了非常高的指令跟随成功率。模型能够根据语言指令(比如“加速”、“向左变道”)准确地预测出对应的驾驶动作,哪怕这些指令和专家示范的“正确”行为是相反的。这为作者构建真正能听懂指令、并据此行动的可解释自动驾驶系统,打下了重要的基础。
该方案在 CARLA 仿真器和 Bench2Drive 基准测试中拿到了最优的性能,它也是 CARLA 2024 挑战赛的冠军方案。更重要的是,它在保持顶尖驾驶水平的同时,在视觉问答和评论生成这些语言任务上也表现非常出色,充分证明了它的多任务能力是真实有效的。
OpenDriveVLA
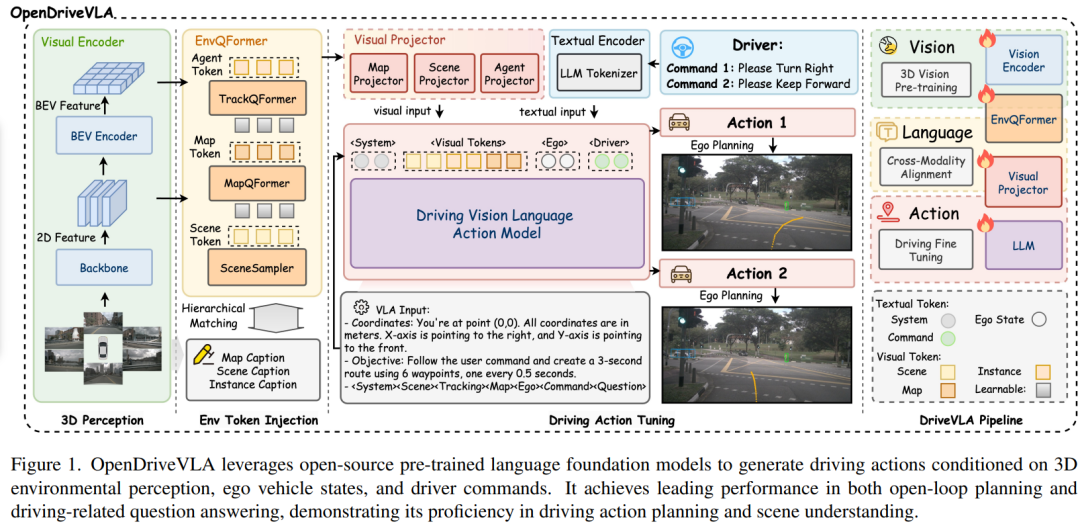
提出时间:2025.03
提出机构:慕尼黑工大、慕尼黑大学
论文链接:https://arxiv.org/pdf/2503.23463
研究背景:现在的端到端自动驾驶系统,在复杂场景下的语义理解和适应不同路况的能力还是有限。传统的视觉语言模型虽然在一般任务上表现不错,但对真实驾驶场景中的三维动态环境理解不够深,还容易“凭空想象”出一些不存在的内容,很难满足自动驾驶对安全性和可靠性的高要求。
所以,怎么用好大语言模型的推理能力,同时又能补上它在空间感知和轨迹生成方面的短板,就成了一个关键的研究难点。
论文内容:本文提出 OpenDriveVLA,这是一个基于视觉-语言-动作模型的端到端自动驾驶框架。它以开源预训练的视觉语言模型为基础,把多视角图像、3D环境信息、自车状态和驾驶指令都融合在一起,最终输出可靠的未来轨迹。模型的核心创新点有这么几个:
分层视觉-语言特征对齐:作者设计了多个投影器,把结构化的2D和3D视觉特征映射到同一个语义空间里。这样做增强了模型对驾驶场景中物体和空间结构的理解能力,也减少了模型“胡思乱想”的情况。
智能体-环境-自车交互建模:作者引入了一个自回归的交互过程,模拟自车、周围动态障碍物和静态道路元素之间的关系。这样就能让轨迹预测更合理,也更安全。
多阶段训练策略:整个训练分成四个阶段,包括视觉-语言对齐、驾驶指令调优、交互建模和轨迹预测。这样一步步来,逐步提升模型的语义推理能力和轨迹生成效果。
作者的实验是在 nuScenes 数据集上做的。结果显示,OpenDriveVLA 在开环轨迹预测和驾驶问答任务中都达到了当前最好的水平,尤其在控制空间误差和降低碰撞率方面表现突出。而且哪怕模型参数规模不大(比如只有0.5B),它也展现出了很强的场景理解和指令跟随能力,这说明它在实际自动驾驶系统中很有潜力,也具备不错的可扩展性。
DriveMoE

论文标题:DriveMoE:Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
提出时间:2025.05
提出机构:上海交通大学
论文链接:https://arxiv.org/pdf/2505.16278
研究背景:现在端到端自动驾驶面临两大难题:一个是多视角感知带来的信息冗余,另一个是复杂驾驶行为不好建模。
现有的视觉-语言-动作模型在处理多摄像头输入时,计算量特别大;而且它们通常只用单一的策略网络,很难应对各种各样的驾驶场景,尤其是那些不常见但又很关键的行为,比如紧急刹车、激进转弯等等。另外,传统方法在闭环测试中表现也不太理想,整体上缺乏对场景和行为的动态适应能力。
论文内容:本文提出 DriveMoE,这是一个基于专家混合模型的端到端自动驾驶框架,它是在视觉-语言-动作基线模型 Drive-π₀ 的基础上构建的。DriveMoE 主要包含两大核心模块:
场景专用视觉MoE:作者设计了一个轻量级的路由模块,能够根据当前驾驶场景,动态地选择最相关的摄像头视图。这样就减少了冗余的视觉信息,提升了感知效率。这个方法其实是在模拟人类驾驶员的行为——作者开车时,也不会一直盯着所有视角,而是会选择性关注最关键的画面。
技能专用动作MoE:作者在流匹配轨迹预测器中引入了多个专家网络,每个专家专门负责某一种驾驶技能,比如变道、紧急制动、转弯等等。通过路由机制,系统能自动激活相关的专家,这样就避免了不同行为模式被“平均化”,从而更好地应对罕见和复杂的场景。
实验是在 Bench2Drive 这个闭环仿真平台上做的,结果显示 DriveMoE 在驾驶评分和成功率等多个指标上都达到了当前最先进的水平,明显超过了基线模型。此外,作者还提出了一个两阶段的训练策略,先从教师强制训练开始,再逐步过渡到自适应路由,这样也进一步提升了模型的鲁棒性。
(NeurIPS 2025) AutoVLA
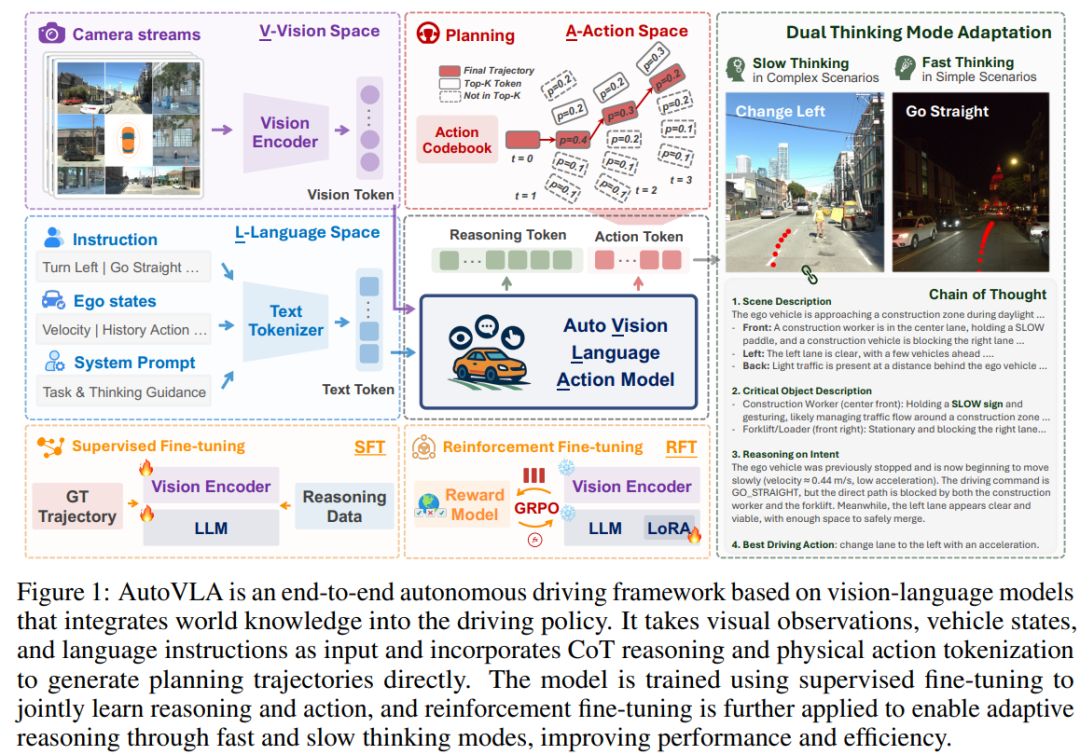
论文标题:AutoVLA:A Vision-Language-Action Model for End-to-End Autonomous Driving with Adaptive Reasoning and Reinforcement Fine-Tuning
提出时间:2025.05
提出机构:加州大学洛杉矶分校
论文链接:https://arxiv.org/pdf/2506.13757
研究背景:现在很多视觉-语言-动作模型用在自动驾驶里,还存在一些问题,比如输出的动作在物理上不太可行、模型结构太复杂,或者推理过程太冗长。传统方法很难把语义推理和物理动作这两块真正统一起来,而且在复杂场景里,也缺少自适应推理的能力。这些都限制了这类模型在端到端自动驾驶中的实际效果和落地效率。
论文内容:本文提出 AutoVLA,这是一个端到端的自动驾驶视觉-语言-动作模型。它通过自适应推理和强化微调,来实现高效的规划。主要的创新点有这么几个:
统一推理与动作生成架构:作者在预训练好的视觉语言模型里,引入了物理动作 token,把连续的车辆轨迹离散化成语言模型可以直接生成的动作序列。这样一来,语义推理和轨迹规划就可以在一个自回归建模过程中统一完成。
双模式推理机制:模型支持两种推理模式,一种是“快速思维”,一种是“慢速思维”。快速思维模式在简单场景下直接输出动作 token;而在复杂场景里,就启动慢速思维,通过链式思维先做深入推理,再生成动作。
两阶段训练策略:训练分两步走,第一步是监督微调,把轨迹数据和高品质的推理数据融合在一起训练;第二步是引入一种叫“群组相对策略优化”的强化微调方法,通过任务奖励函数来优化规划性能,同时惩罚冗余推理,从而提升整体运行效率。
作者在 nuPlan、nuScenes、Waymo 和 CARLA 等多个真实和仿真数据集上做了实验。结果显示,AutoVLA 在开环和闭环测试中都表现优秀,特别是在复杂场景下的推理能力和轨迹生成质量,明显超过了现有的其他方法。
MindAVLA (理想汽车)
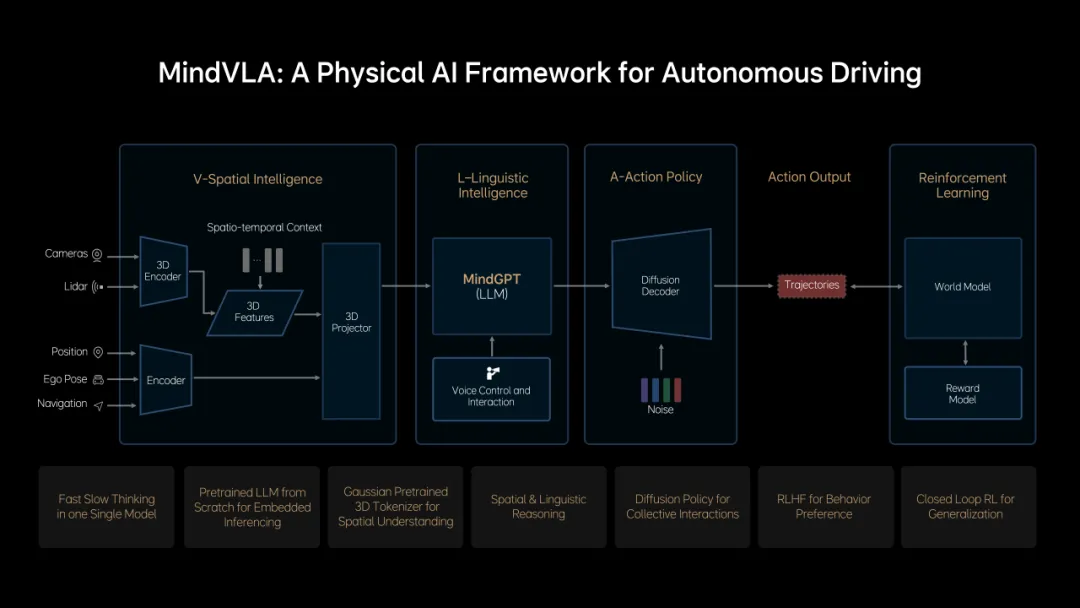
理想汽车也在2025年上半年推出了自己的 VLA 模型,并且把模型量产上车了:
整体架构方面:
模型类型:他们用的是 VLA 模型,也就是所谓的视觉-语言-行动模型。这个模型把端到端驾驶模型和视觉语言模型的能力结合在了一起。他们自研的MindVLA模型,融合了空间智能、语言智能,还有行为智能。
MoE架构:这里用了一个叫“混合专家模型”的结构,这个架构是他们自己研发的,专门为嵌入式芯片做了定制。这样做的好处是,可以在增大模型参数量的同时,还能保持不错的端侧推理效率。
核心技术这块:
3D空间理解:他们用“3D高斯”作为中间表达方式,能提供多粒度、多尺度的3D几何信息。训练中引入了大量 3D 数据,所以模型对3D空间的理解和推理能力非常强。
推理与决策:模型具备“思维链”推理能力,还引入了“快思考”和“慢思考”相结合的决策模式。它能根据不同的驾驶场景,自动切换这两种思考方式。
轨迹生成与博弈:他们用“扩散模型”来优化车辆的行驶轨迹,并且把自车行为生成和他车轨迹预测放在一起建模。这样在复杂交通环境中,车辆的博弈能力就更强了。
训练流程这块:
三阶段训练:整个过程模拟人类学车的方式,分三步走:
预训练:先用海量的2D/3D视觉数据和交通语言语料,训练出一个云端基座模型,再通过蒸馏技术把它转化成适合车端运行的版本;
后训练:这个阶段加入动作数据,让模型具备实时博弈的能力;
强化训练:通过人类反馈强化学习,再结合在世界模型里的训练,让模型在安全性和舒适性上,都尽量贴近人的偏好。
世界模型:他们还自研了一个“重建+生成”的云端统一世界模型,主要用于大规模仿真和强化学习训练。这样做能用更低的成本、更高的效率,去验证和解决现实问题。
最后是工程优化:
车端部署:他们自研了底层推理引擎,再配合INT4量化这些技术,让VLA模型能在像英伟达Thor-U这样的芯片上高效运行。
测试验证:VLA版本90%以上的测试都通过仿真来完成,这样大大提升了迭代效率,也降低了实车测试的成本。
小鹏 VLA

小鹏汽车在2025年11月的科技日上,公布了他们第二代VLA大模型,也就是视觉-语言-行动模型。这次发布的信息显示,这个模型在整体架构和核心技术上,都做了很大的升级。
作者先看看整体架构:
实现了端到端直连:他们做了一个很创新的改动,就是把传统VLA架构里那个“语言转译”的环节直接拿掉了。现在模型可以直接从看到的画面,一步到位生成驾驶动作,不再需要先转换成语言描述。
建成了统一智能基底:这个模型也是首个准备量产的“物理世界大模型”。它不光能生成驾驶动作,更重要的是能理解和推演物理世界的规律。所以它的能力可以跨界使用,能同时驱动汽车、机器人,甚至飞行汽车这些不同的智能设备。
再来说核心技术:
用了超大规模做训练:他们的训练数据非常扎实,用了接近1亿段真实驾驶视频。
有强大的算力底座:他们的模型是建立在3万张显卡组成的云端算力集群上,基础模型参数量有720亿。在这个基础上,模型迭代速度非常快,每五天就能完成一次全链路的更新。
实现了高效车端部署:他们通过自研的图灵AI芯片,再加上对“芯片-算子-模型”这条链路的全流程优化,成功把这么一个几十亿参数的大模型部署到了车端运行。
笔者总结
本文主要想聊聊笔者对于当前主流的 VLA 方案的看法,也顺便总结一下已有的一些工作。
最后想写一写随笔:几年前的我应该也想不到,几年后的我可以在写这种总结性的文章的时候,让大模型帮我快速整理一些 papers,不得不说,“大模型改变了人们的工作模式,也改变了自动驾驶的系统格局”。读书那会,遇到同做自动驾驶的朋友,还会问“你在做感知还是预测,还是规控?”;现在面试候选人,经常问的就是“你的这个大模型工作做了哪些创新?”。
时代真的变了,但好消息是在往更智能的方向改变,这就需要大家一致保持学习的热情,当然也不能忘记创新,谁也不知道 VLA 的下一代技术路线何时会到来,可能就存在在现在某高校某实验室的某同学的 codebase 当中。
最后的最后,提一个开放性的问题:在未来,VLA 中的 L 真的需要吗?或者说,描述场景的 L 还真的需要吗?语言不过是机器与人类的沟通的工具,或者说是,让人类理解机器的显示手段,当我们在谈论一辆可以完全自动驾驶的车辆时,真的还需要 Language 吗?


















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









