



作者 | Pirate Jack 来源 | Vehicle
原文链接:Waymo自动驾驶最新探索实践:世界模型、长尾问题、最重要的东西
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
辅助驾驶/自动驾驶产业应该最终都会交叉,因为他们算法软件的底层逻辑是一样的。我们之前文章《IAA 2025 慕尼黑车展:中国汽车军团们,从“贸易出口”到“势不可挡”》也分享到了,中国在辅助驾驶开拓算法的公司不管Momenta、元戎、大疆都也和其他专做L4的公司一样在欧洲和中东各地掘金L4。
本文是基于Waymo 感知算法负责人 Wu Chen女士在今年CVPR上演讲内容总结,再根据自身经验分析自动驾驶算法、发展现状以及对于自动驾驶到底最重要的东西是什么。
构建一个世界模型
Waymo表示,他们开发了一个名为 Waymo 基础模型的大规模 AI 模型,该模型支持车辆感知周围环境、预测道路上其他车辆的行为、模拟场景并做出驾驶决策。
这个庞大模型的功能类似于 ChatGPT 等大型语言模型 (LLM),这些模型基于海量数据集进行训练,以学习模式并进行预测。正如OpenAI 和 Google 等公司构建了更新的多模态模型来整合不同类型的数据(例如文本、图像、音频或视频)一样,Waymo 的 AI 能够整合来自多个来源的传感器数据来理解其周围环境。
Waymo 基础模型是一个单一的大型模型,但车端是一个较小的模型,不过这个模型是从更大的模型中“提炼”出来的——因为它需要足够紧凑才能部署在车端。
大型模型被用作“教师”模型,将其知识和能力传授给较小的“学生”模型——这一过程在生成式人工智能领域被广泛使用。小型模型针对速度和效率进行了优化,并在每辆车上实时运行,同时仍保留驾驶汽车所需的关键决策能力。
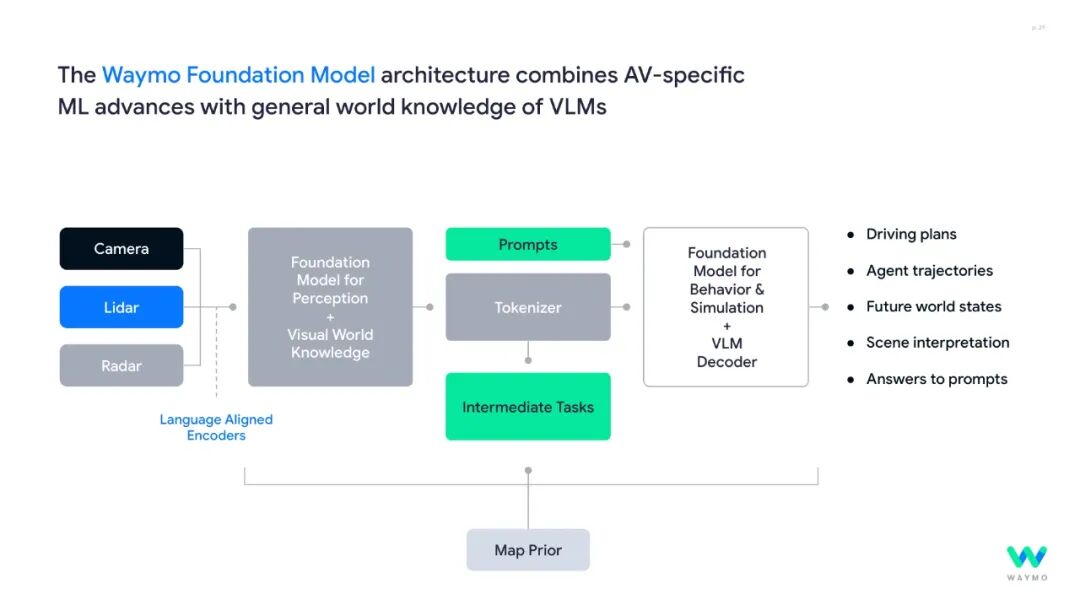
因此,感知和行为任务(包括感知物体、预测其他道路使用者的行为以及规划汽车的下一步行动)都可以在车上实时进行。
云端的更大的模型还可以模拟真实的驾驶环境,在部署到 Waymo 车辆之前,进行虚拟测试和验证其决策。

所以,Waymo的世界模型可以、编码所有传感器数据(摄像头、雷达、激光雷达)并内置世界知识,解码所有驾驶相关任务(蒸馏缩小放在车端做感知、控制,可以在云端做虚拟仿真),这样可以实现强大的泛化能力和快速适应不同平台。
有了这个世界模型的算法,基本上解决了自动驾驶日常问题
接下来的任务-解决长尾问题
自动驾驶的长尾问题,无非就是天气、能见度低、遮挡、施工等复杂场景。虽然字面上很容易,但对于自动驾驶就是难解之题。
天气:
例如:雨后的路况的水坑,以及不常发生的洪水,自动驾驶算法需要判断水深和大量上下文信息,精确度和召回率要求极高,大量的空间信息。
Waymo的解法是采用VLM,但是前提条件是大量此类语料库。

雪地驾驶,这对车辆硬件要求高,传感器需要加热和清洁功能以应对堵塞。雪地驾驶的挑战还包括:如何决定行驶路线(地图是否仍然重要)、识别车辙,以及估计摩擦力。
低能见度与遮挡:
在极端低能见度下,如夜间高速公路上的行人或车辆,单个传感器可能无法检测,需要多模态传感器的协同。
凤凰城特有的沙尘暴(哈布)也对传感器识别构成挑战,激光雷达可以在尘暴中清晰看到行人

遮挡推理(Occlusion Reasoning):
最常见的就是视线不好的地方,到底有没有鬼探头,有没有加塞等。这类看不见区域中物体的存在和状态,对驾驶安全至关重要。
挑战包括:定义不明确、非确定性、缺乏真值(ground truth)以建立基准、主观性、交通参与者多样性以及高度依赖上下文。
人类常常对这种场景采取的方式是防御性驾驶
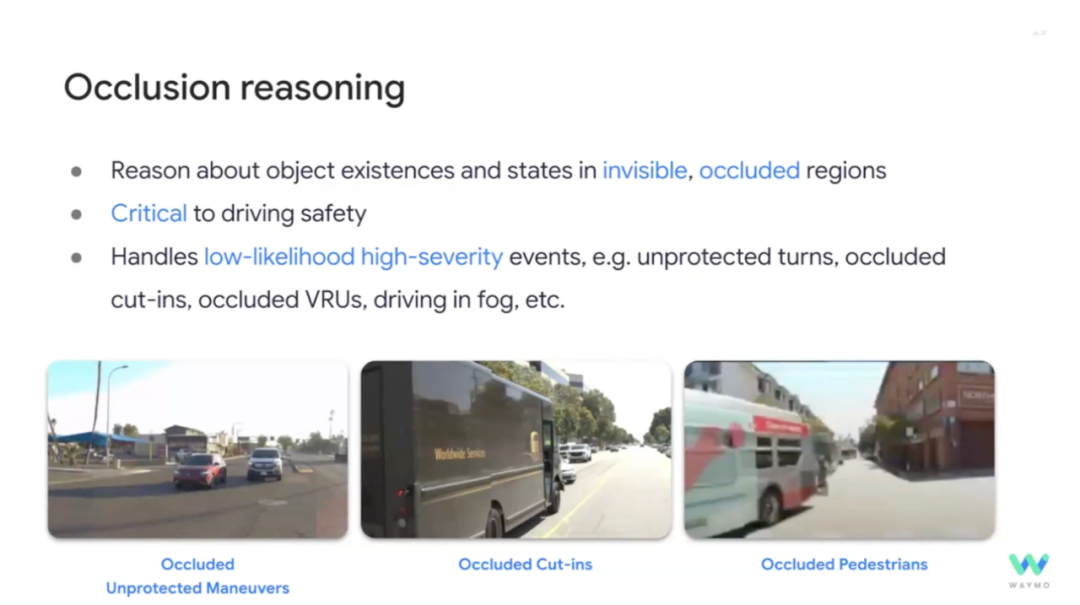
Waymo的解决方案包括:估计不确定的物体的先验信息(通过学习驾驶数据统计信息和利用微弱的传感器线索,其实也就是原有数据)以及准确估计自车速度先验(在不确定性高的路口,速度估计过低或过高都会导致问题)。

复杂场景理解:
施工场景:需要识别标志、推理驾驶几何形状,并根据锥筒等物体调整路线。
动态场景:如交通警官的手势,需要实时响应动态信号。
活跃事故现场:涉及大量应急车辆和路况堵塞,需要整体场景理解来推理,并决定最佳行动路线,而不仅仅是识别单个物体(如警戒线)。
总的来讲,对于复杂场景,不仅仅是识别特征元素那么简单,需要使用LLM大语言模型理解场景,然后根据场景内容做出决策。对于复杂场景Waymo表示他们也在探索。
自动驾驶开发到底什么最重要?
自动驾驶时人工智能落地的场景,所以自动驾驶最重要的东西也就是人工智能的三大件:数据、算法、算力。
但Waymo自动驾驶对这三大件却只提了数据,Waymo表示基础是拥有大量数据很重要,但数据筛选和整理更为关键,高效高质的数据才能确保模型专注于解决正确的问题。
Waymo使用语言搜索、基于嵌入的搜索(适用于外观和行为)、少样本学习和主动学习等技术

对于自动驾驶,数据里面肯定海量视频,如何数据挖矿出高质的视频,那么视频搜索能力中对于理解事件(如汽车碰撞、漂移、翘头)的含义至关重要。
快速的实时决策,天下武功唯快不破,自动驾驶也一样,Waymo表示谁能让算法到执行的链路用时越短,那么谁的自动驾驶就能做的更安全,更丝滑。
怎么理解这个自动驾驶的响应快,这个得拆解自动驾驶从摄像头等传感器的输入响应,然后就是算法的运算结论交给底盘等执行机构。
传感器的输入响应,基本上就是看摄像头的fps和激光雷达等帧率,目前摄像头帧率都大于24Hz。
算法的响应,基本上就是算法能够处理多块的帧率,然后按照多快的帧率比如10Hz和20Hz输送给底盘执行机构。
底盘机构响应,这就是为什么这个时代油液的发动机和底盘已经不适应了,电机电控的控制频率已经非常高了,例如底盘刹车ESP的响应都是上百Hz。
所以,当前快速响应决策基本上都是卡在各家算法的处理输出响应频率。
最后,Waymo认为他的Depots运营停车场,改装工厂是最重要的,因为Waymo是做L4的,这些设备能够帮助L4顺利快速的运营。
Waymo的Depots运营停车场,目前车辆能够自己进入停车场,找充电的空位,充完电只要拔完枪,车子就自动开出去运营。
Waymo的改装车间,自动驾驶车辆,只要装完了传感器,车辆就能够自动驶出生产线,自己驶入运输卡车或者就直接开始运营。
写在最后
当然,Waymo这个在CVPR上的讨论,更多的是算法和开发以及少量运营。但对于辅助驾驶/自动驾驶批量生产和运营犹如汽车制造一样,还有更大的是工程落地的很多dirty work,可能Waymo还没有走到那一步。
工程落地是自动驾驶行业一个较大的壁垒,需要协同汽车开发,协同测试运营,听说行业内做的好的自动驾驶公司基本上都是挖角当年传统汽车工程师来做,例如博世等的工程师。
辅助驾驶/自动驾驶产业应该最终都会交叉,因为他们算法软件的底层逻辑是一样的。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









