



点击下方卡片,关注“大模型之心Tech”公众号
>>点击进入→大模型技术交流群
本文只做学术分享,如有侵权,联系删文
写在前面
在生成式AI的竞技场上,两大技术范式—— 扩散(Diffusion)模型与自回归(autoregressive, AR)模型——的角逐从未停止。
一边是凭借图像生成惊艳世界的扩散模型,以Stable Diffusion和DALL·E为代表,通过“从噪声中迭代重建”的生成逻辑刷新了视觉创作的边界。
另一边则是统治文本生成领域的自回归模型,以GPT、LLaMA、Qwen、DeepSeek系列为代表的大语言模型,凭借“逐词预测序列”的连贯性成为语言任务的默认框架。
然而,自回归范式的固有缺陷已成为行业痛点——生成速度受限于序列依赖,即便是千亿参数模型也难以突破「一个token接一个token」的效率瓶颈。
而如今,一种全新的范式正在改写规则:扩散语言模型(Diffusion Language Models, DLMs) 凭借「并行生成+迭代优化」的特性,在实现数倍推理加速的同时,性能已比肩同等规模AR模型,成为大语言模型领域最具潜力的突破方向之一。
近日,来自 Mohamed bin Zayed 人工智能大学 VILA Lab 等机构的团队发布了首篇系统性覆盖DLM领域的综述《A Survey on Diffusion Language Models》 ,不仅梳理了DLM从理论到实践的完整发展脉络,更通过 taxonomy 分类、性能对比、挑战分析,为研究者和开发者提供了一份「全景地图」。
本文将以技术解析与产业价值双重视角,深度解读这份综述的核心发现,带你看懂扩散语言模型如何解决AR模型的效率难题,以及其未来能否成为主流范式。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~

一、颠覆AR范式:DLM凭什么成为「效率革命」的核心?
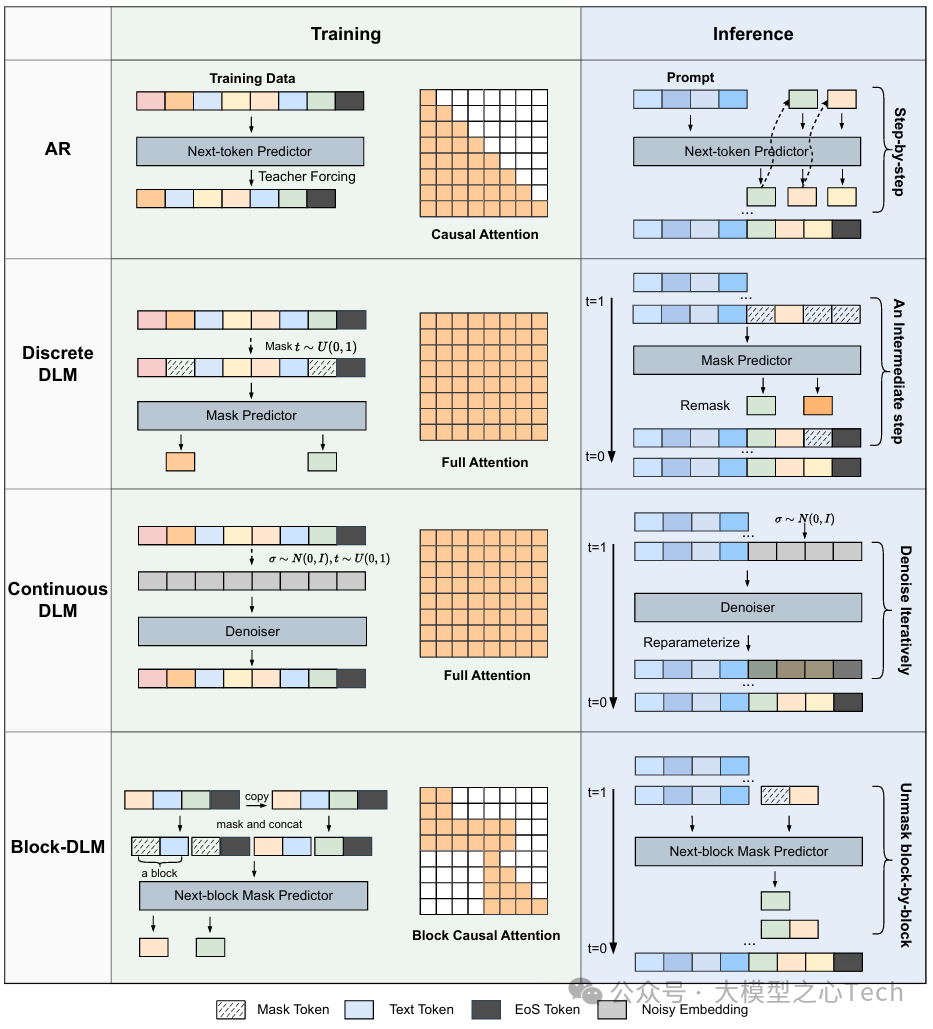
在大模型落地过程中,「生成质量」与「推理速度」的平衡始终是核心矛盾。AR模型(如GPT系列、LLaMA系列)通过「因果注意力+逐token预测」实现了高质量文本生成,但这种「串行模式」天然限制了并行计算能力——生成一篇1000token的文章,至少需要1000步迭代,推理延迟随文本长度线性增长。
DLM的出现正是为了打破这一桎梏。其核心灵感源自图像扩散模型(如Stable Diffusion),但创新性地将「迭代去噪」机制适配到离散的语言数据中:先通过随机噪声逐步「污染」干净文本,再训练模型学习反向去噪过程,最终从纯噪声出发,并行生成完整文本序列。
根据综述梳理,DLM相比AR模型的核心优势可概括为四点,每一点都直击产业落地痛点:
1. 并行生成:推理速度提升数倍,适配硬件红利
AR模型的推理速度受限于「token级串行」,而DLM通过「迭代去噪」实现「序列级并行」——在每一轮去噪步骤中,模型可同时优化所有token的生成概率,无需等待前一个token完成。综述中提到,工业界模型如Mercury系列、Gemini Diffusion已实现「每秒数千token」的推理速度,较AR模型提升10倍以上,且能充分利用GPU的并行计算能力。
这种效率提升在长文本生成(如文档总结、代码生成)场景中尤为关键。例如,生成一段500token的代码,AR模型需500步迭代,而DLM可通过30-50轮去噪步骤完成,时间成本直接压缩至1/10。
2. 双向上下文:更细腻的语言理解与生成控制
AR模型依赖「左到右」的单向注意力,难以捕捉文本中远距离依赖(如上下文指代、逻辑连贯);而DLM在去噪过程中天然融合双向注意力,能同时利用前文与后文信息优化每个token的生成。
这种特性不仅让DLM在「文本补全」「风格迁移」等需要全局理解的任务中表现更优,还支持「细粒度控制」——例如通过「分类器引导(Classifier-Free Guidance)」技术,用户可调整生成文本的情感倾向、正式程度,甚至指定特定结构(如诗歌韵律、代码格式),这是AR模型难以实现的。
3. 迭代优化:从「一次性生成」到「逐步精炼」
AR模型的生成过程是「不可逆」的——一旦生成某个token,后续步骤无法修改,容易导致「早期错误累积」(如前面生成错误的逻辑前提,后续无法修正)。而DLM的「迭代去噪」机制类似「人类写作时的修改过程」:先生成粗糙的草稿,再通过多轮优化逐步修正低置信度部分,最终得到高质量文本。
综述中以LLaDA模型为例,其推理过程会先将所有token设为[MASK],然后每轮去噪时「解锁」高置信度token、「重掩码」低置信度token,直到所有token确定。这种机制让DLM在数学推理、逻辑分析等复杂任务中表现突出——例如在GSM8K数学基准测试中,LLaDA-8B的准确率超过同等规模的LLaMA3-8B,正是因为迭代优化能修正中间计算错误。
4. 多模态天然适配:统一文本与视觉的生成框架
AR模型在多模态融合(如文本生成图像、图像描述)中往往需要「模态专用模块」(如单独的视觉编码器+文本解码器),而DLM基于「去噪扩散」的统一框架,可轻松适配多模态数据:只需将图像离散化为token(如通过VQ-VAE),即可与文本token一起纳入扩散过程,实现「文本-图像」的联合生成与理解。
综述中提到的MMaDA、LaViDa等模型已验证这一优势:MMaDA无需独立视觉编码器,直接将图像token与文本token联合建模,在图像生成质量上超越SDXL,同时保持语言理解能力;LaViDa则通过「互补掩码」策略,解决了多模态训练中「token利用率低」的问题,推理速度较AR-based多模态模型提升3.9倍。
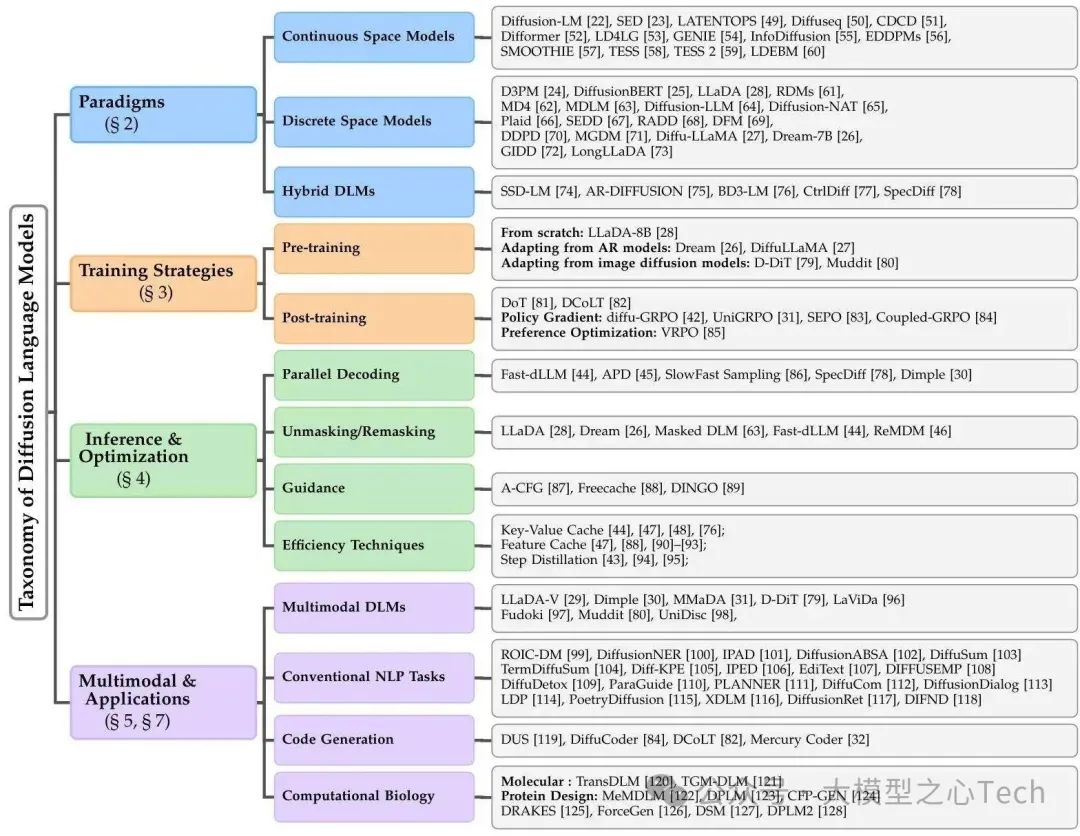
二、技术路线全景:从「连续」到「离散」,DLM的三大范式之争
DLM并非单一技术路线,而是根据「扩散过程作用的空间」分为三大范式——连续空间DLMs、离散空间DLMs、混合AR-DLMs。这三种路线各有优劣,对应不同的应用场景,综述通过详细的机制解析与模型案例,为我们厘清了它们的技术边界与发展脉络。
1. 连续空间DLMs:从嵌入空间突破离散语言的限制
核心思路:将离散的文本token映射到连续的嵌入空间(如通过预训练语言模型的Embedding层),在连续空间中完成「加噪-去噪」过程,最后通过「 nearest-neighbor搜索」或「解码器」将连续嵌入映射回离散token。
这种路线的优势在于「继承图像扩散模型的成熟技术」——例如可直接使用DDPM、Rectified Flow等经典扩散框架,且连续空间的数学性质更易优化。但缺点也很明显:「嵌入-映射」过程会损失部分语言语义,且生成的token可能存在「语义偏差」(如生成与目标语义相近但不匹配的词)。
综述中列举了多个里程碑式模型,展现了连续空间DLMs的发展路径:
Diffusion-LM(2022):首个将扩散模型引入语言生成的工作,通过「分类器引导」实现可控文本生成(如指定情感、主题),验证了连续空间路线的可行性;
SED(2022):提出「自条件机制」,利用前一轮去噪结果优化当前步骤,大幅提升生成质量,性能接近AR模型;
Diffuseq(2023):针对序列到序列任务(如机器翻译)优化,仅对目标序列加噪,保留源序列的完整信息,在翻译准确率上超越非AR基线模型;
TESS 2(2025):将扩散过程从嵌入空间迁移到「logit空间」,并通过「指令微调」适配大模型,7B参数版本在指令跟随任务上达到GPT-3.5水平,同时保持并行生成能力。
2. 离散空间DLMs:直接在token层面实现扩散,更贴合语言本质
核心思路:无需转换到连续空间,直接在「token词汇表」上定义扩散过程——通过「结构化转移矩阵」将干净token逐步替换为特殊的[MASK](加噪),再训练模型从[MASK]中恢复原始token(去噪)。
这种路线的优势是「无语义损失」——扩散过程完全在离散语言空间进行,生成的token更符合语言习惯,且无需额外的「映射步骤」,推理流程更简洁。目前,离散空间DLMs已成为主流路线,尤其在大参数模型中(如8B规模的LLaDA、Dream-7B)表现突出。
综述重点分析了离散空间DLMs的技术演进,其中三个关键突破值得关注:
D3PM(2021):首次提出离散扩散模型,通过「吸收态转移矩阵」定义token的加噪过程(即token有一定概率变为[MASK],且一旦变为[MASK]就不再变回),为后续工作奠定基础;
DiffusionBERT(2023):将预训练BERT作为去噪器,利用BERT的双向注意力提升token恢复 accuracy,同时提出「纺锤噪声调度(Spindle Schedule)」——根据token的出现频率调整加噪概率(高频词更晚被掩码),进一步优化生成质量;
LLaDA(2025):离散空间DLMs的里程碑模型,支持从1B到8B参数的规模扩展。其核心创新是「掩码损失计算」——仅对被掩码的token计算损失,提升训练效率;8B版本在PIQA、HellaSwag等基准测试中与LLaMA3-8B持平,在GSM8K数学推理上甚至领先5%。
此外,离散空间DLMs还在「长序列处理」上取得突破。综述中提到的LongLLaDA通过「NTK-based RoPE外推」技术,将上下文长度扩展到8192 tokens,且在长文本检索任务上的性能超越AR模型,解决了DLM「长序列能力弱」的痛点。
3. 混合AR-DLMs:取两者之长,平衡效率与质量
核心思路:结合AR模型的「长程依赖建模能力」与DLM的「并行生成能力」,典型方案是「块级AR+块内DLM」——将文本分为多个块,块与块之间采用AR生成(保证全局连贯),块内部采用DLM并行生成(提升速度)。
这种路线的优势是「兼顾质量与效率」——既避免了纯DLM「并行解码诅咒」(并行生成导致token间依赖丢失),又解决了纯AR「速度慢」的问题,适合对连贯性要求高的长文本生成场景(如小说创作、技术文档)。
综述中列举的代表性模型包括:
SSD-LM(2023):首个混合模型,将文本映射到「单纯形空间(Simplex Space)」,按块进行连续扩散,块间通过AR方式衔接,推理速度较AR模型提升3倍;
BD3-LM(2025):离散空间的混合模型,提出「块因果注意力」——块内使用全注意力(支持并行去噪),块间使用因果注意力(保证序列连贯),在长文本摘要任务上的F1值超越纯AR模型10%;
CtrlDiff(2025):引入「动态块预测」——根据文本内容的复杂度调整块大小(复杂句用小块,简单句用大块),进一步优化速度与质量的平衡,在新闻生成任务上实现15倍加速,同时保持90%以上的语义连贯率。
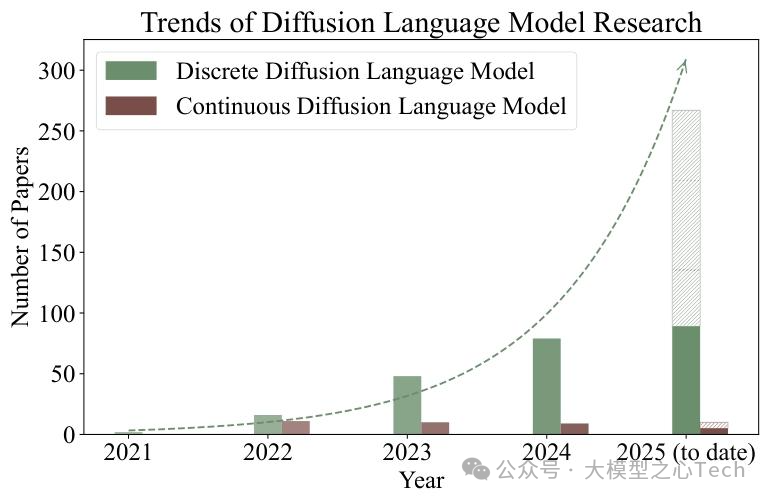
三、训练与推理优化:DLM如何从「能生成」到「生成好、生成快」?
DLM的技术突破不仅在于范式创新,更在于训练策略与推理优化的持续迭代。综述用大量篇幅拆解了DLM在「如何高效训练」与「如何快速推理」上的关键技术,这些细节直接决定了DLM的产业落地能力。
1. 训练策略:从「从头训练」到「迁移适配」,降低成本是核心
AR模型的训练需要海量数据与计算资源(如GPT-4训练成本超1亿美元),而DLM通过「迁移学习」大幅降低了训练门槛。综述指出,当前DLM的训练主要分为三种初始化方式,各有适用场景:
(1)从AR模型初始化:最快的「冷启动」方式
核心逻辑是「复用AR模型的语言理解能力」——将AR模型(如LLaMA、Qwen2.5)的权重作为DLM的初始参数,仅训练与扩散相关的模块(如时间嵌入层、去噪头),训练数据量可减少50%以上。
综述中提到的Dream-7B是典型案例:基于Qwen2.5-7B初始化,仅用580B tokens的训练数据(约为Qwen2.5训练数据的1/4),就在HumanEval代码生成基准上达到CodeLLaMA-7B的性能,同时推理速度提升7倍。这种方式的优势是「训练周期短、成本低」,适合快速迭代模型版本。
(2)从图像扩散模型初始化:多模态适配的捷径
对于需要融合视觉的多模态DLM,从图像扩散模型(如Stable Diffusion的MM-DiT)初始化是更优选择——图像扩散模型已学习到视觉特征的分布规律,只需添加语言适配模块(如文本-视觉注意力层),即可快速实现「文本生成图像」「图像描述」等功能。
例如综述中的D-DiT模型,基于SD3的MM-DiT backbone初始化,通过「联合损失优化」(图像连续扩散损失+文本离散扩散损失),在文本-图像生成任务上超越Imagen,同时保持语言理解能力,验证了跨模态迁移的可行性。
(3)从头训练:追求极致性能的选择
虽然迁移学习效率高,但部分模型为了避免AR/图像模型的「偏见传递」(如AR模型的串行思维定式),选择从头训练。例如LLaDA-8B完全基于扩散目标从头训练,在数学推理、逻辑分析等任务上的表现超越迁移初始化的模型,证明了DLM自身的潜力。不过从头训练的成本较高——LLaDA-8B使用2.3T tokens的训练数据,计算量约为LLaMA3-8B的80%。
除了初始化方式,DLM的「后训练优化」也是提升性能的关键。综述重点介绍了两种核心技术:
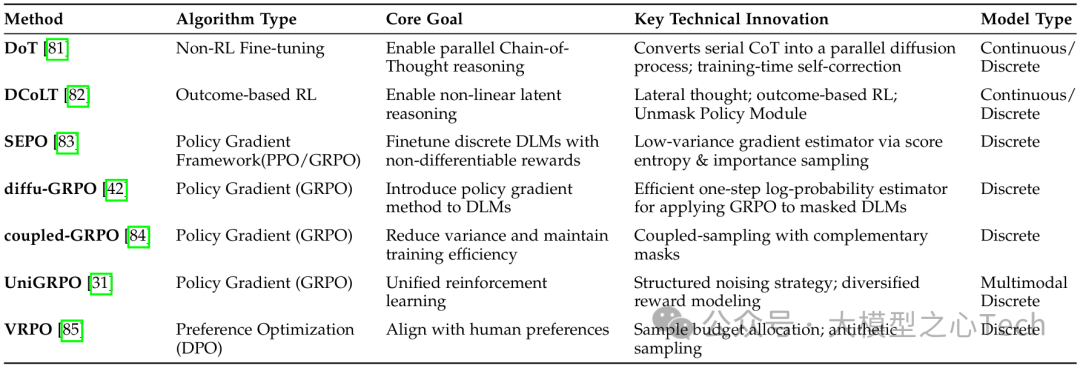
强化学习(RL)对齐:针对DLM「生成概率不可计算」的问题,研究者提出了适配的RL算法。例如diffu-GRPO通过「平均场分解」近似序列概率,UniGRPO通过「结构化加噪策略」让模型暴露不同去噪阶段的数据,这些方法使DLM在复杂推理任务上的性能提升10%-20%;
偏好优化:LLaDA 1.5提出的VRPO(Variance-Reduced Preference Optimization)解决了DLM应用DPO(直接偏好优化)时的「高方差」问题,通过「蒙特卡洛采样预算分配」与「对偶采样」,让模型更好地对齐人类偏好,在对齐基准MT-Bench上达到7.2分(接近GPT-3.5)。
2. 推理优化:三大技术方向,让DLM「又快又好」
训练出高质量DLM后,推理阶段的优化直接决定用户体验。综述将DLM的推理优化技术归纳为三大方向,覆盖「速度提升」「质量保障」「成本控制」:
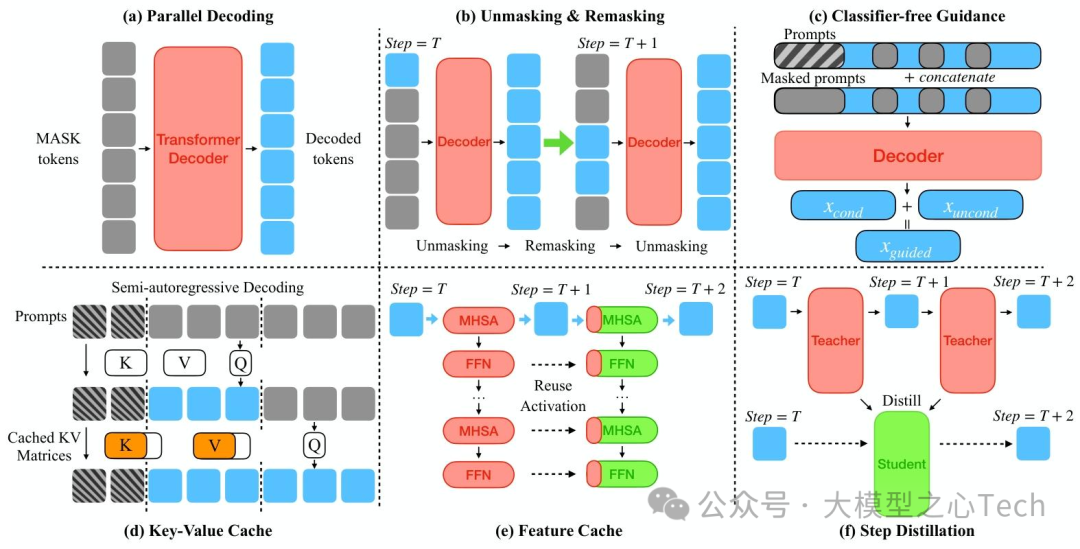
(1)并行解码:突破「一步一token」的限制
并行解码是DLM的核心优势,但 naive 并行会导致质量下降。综述中提到的「置信度感知解码」是当前主流方案——根据token的预测概率动态决定每轮解锁的token数量:高置信度token(如常见词汇、标点)优先解锁,低置信度token(如专有名词、复杂逻辑词)继续去噪。
例如Fast-dLLM提出的「阈值解码」策略:设置概率阈值(如0.8),每轮解锁所有概率超过阈值的token,未达阈值的token继续掩码。这种方法使LLaDA-8B的推理速度提升27.6倍,同时生成质量仅下降1%,大幅优于固定步数解码。
另一种创新是「辅助模型引导解码」——APD模型使用轻量级AR模型(约为DLM参数的1/10)预测每轮的并行度,当AR模型判断当前文本复杂度高时,降低并行度以保证质量;复杂度低时,提升并行度以加速。这种动态调整策略让APD在不同任务上的速度-质量平衡更优。
(2)掩码策略:迭代优化低置信度token
离散空间DLMs的「去掩码-重掩码」机制是提升质量的关键。综述中提到的ReMDM模型进一步优化了这一机制:不仅对未解锁的token重掩码,还会对已解锁但置信度下降的token重新掩码,实现「动态修正」。例如在代码生成中,若后续步骤发现前面生成的函数名与参数不匹配,可重新掩码函数名并优化,大幅降低错误累积。
此外,LaViDa提出的「互补掩码」策略也值得关注:对每个训练样本生成两个 disjoint 掩码版本,确保所有token都能参与损失计算,解决了传统掩码「token利用率低」的问题,使多模态DLM的训练效率提升40%,推理时的语义连贯性也显著增强。
(3)效率技术:从「减少计算」到「复用资源」
DLM推理的核心成本在于「多轮去噪的重复计算」,综述中提出的三类技术有效解决了这一问题:
缓存机制:通过缓存中间结果减少重复计算。例如dKV-Cache延迟存储token的Key-Value对,仅在token稳定后缓存,避免频繁更新;dLLM-Cache则区分「 prompt 缓存」与「 response 缓存」——prompt tokens 全程不变,采用长间隔缓存;response tokens 动态变化,通过「V-verify」相似度检测决定是否刷新,使LLaDA-8B的推理速度提升9倍。
步骤蒸馏:将多轮去噪压缩为少量步骤。DLM-One通过「分数蒸馏+对抗正则化」训练单步生成模型,直接从噪声生成完整文本,推理速度提升500倍,同时保持90%以上的生成质量;Di4C则针对离散DLM,蒸馏token间的相关性,将100步去噪压缩至4步,速度提升25倍。
轻量化设计:通过模型压缩降低单步计算量。例如DiffuCoder采用「稀疏注意力」,仅对代码关键结构(如函数定义、循环)使用全注意力,其他部分使用稀疏注意力,参数规模保持7B不变,但单步推理时间减少30%,在代码生成任务上仍保持竞争力。
四、多模态与产业落地:DLM已从实验室走向实用场景
随着技术成熟,DLM不再局限于纯文本生成,而是向多模态融合与垂直领域渗透。综述通过大量案例证明,DLM在「跨模态理解与生成」「高价值垂直场景」中已展现出超越AR模型的潜力,成为产业落地的重要选择。
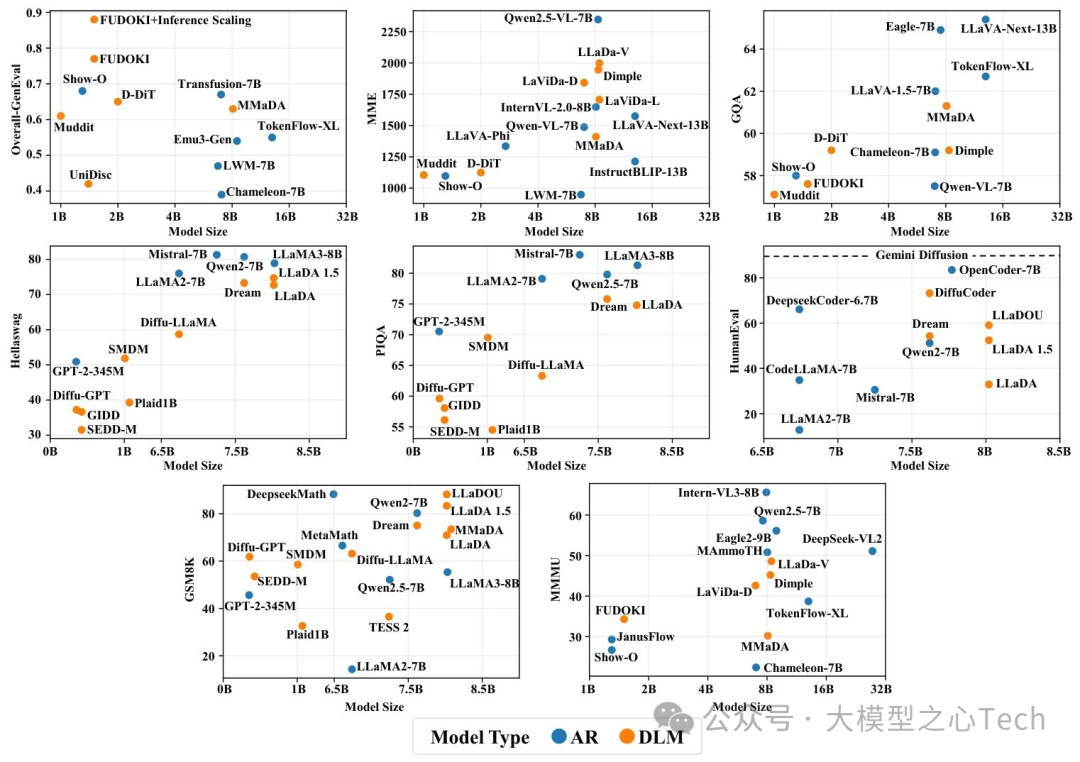
1. 多模态DLM:打破文本与视觉的边界
DLM的「统一去噪框架」使其天然适配多模态数据——只需将不同模态的数据离散化为token(如文本为词token、图像为VQ-VAE token),即可纳入同一扩散过程。综述中重点介绍了四类代表性多模态DLM,覆盖不同应用场景:
(1)视觉-语言理解模型:从「看图说话」到「视觉推理」
这类模型以「文本理解+图像分析」为核心,典型代表是LLaDA-V与LaViDa:
LLaDA-V(8.4B参数):在LLaDA基础上加入视觉编码器,通过「三阶段微调」对齐模态——先训练MLP投影层匹配文本-视觉嵌入,再用大规模视觉指令数据微调DLM目标,最后通过推理链训练提升复杂任务能力。在MME多模态基准测试中,LLaDA-V的综合得分超越LLaVA-1.5-7B 12%,接近Qwen2-VL-7B;
LaViDa:创新「双阶段扩散」解决多模态训练的「模态失衡」问题——第一阶段仅对文本加噪,确保视觉特征稳定;第二阶段联合加噪文本与视觉token,提升跨模态一致性。其8B版本在GQA视觉问答任务上的准确率达62%,较AR-based模型Show-O提升8%,同时推理速度快3.9倍。
(2)统一生成模型:同时搞定文本与图像创作
这类模型突破「单模态生成」限制,支持「文本生成图像」「图像生成文本」「图文联合创作」,代表模型包括MMaDA与D-DiT:
MMaDA:无独立视觉编码器,通过VQ-VAE将图像离散为16×16的token,与文本token一起输入扩散Transformer。其核心创新是「混合长推理链微调」——将文本推理链(如数学解题步骤)与视觉推理链(如图像元素分析)统一格式,使模型能跨模态推理。在图像生成任务上,MMaDA生成的图像FID值(越低越好)达10.2,超越SDXL的12.5;在文本推理任务上,GSM8K准确率达78%,与LLaMA3-8B持平;
D-DiT:端到端支持「文本-图像双向生成」,采用双分支Transformer分别处理文本与图像token,每一层通过「跨模态注意力」交互信息。在文本生成图像(T2I)任务上,D-DiT生成的图像人类偏好率达85%,超过Imagen;在图像生成文本(I2T)任务上,图像描述的BLEU-4值达42%,超越BLIP-2。
(3)可控多模态生成:精准控制输出格式与风格
DLM的「引导技术」使其在多模态生成中具备更强的可控性。例如Dimple模型通过「结构先验(Structure Priors)」指定输出格式——用户可要求模型生成「图像+结构化描述(如产品参数表)」,Dimple会通过动态掩码策略确保文本格式与图像内容匹配;在广告创作场景中,用户只需输入产品图像与风格关键词(如「科技感」「极简风」),Dimple就能生成符合风格的广告文案与产品图,生成效率较人工提升50倍。
2. 垂直领域落地:从代码生成到计算生物学,DLM的差异化价值
除了通用场景,DLM在垂直领域的落地更能体现其「并行生成+迭代优化」的优势。综述梳理了三大高价值领域的应用案例,展现DLM的产业潜力:
(1)代码生成:兼顾速度与逻辑正确性
代码生成对「语法正确性」「逻辑连贯性」要求极高,AR模型虽能生成高质量代码,但推理速度慢,难以满足实时开发需求。DLM通过「并行生成+迭代修正」,在速度与质量间取得平衡:
DiffuCoder(7B参数):专为代码生成优化的离散DLM,采用「耦合采样(Coupled-Sampling)」策略——对每个代码片段生成两个互补掩码,确保所有token都能在部分掩码场景下被验证,减少语法错误。在HumanEval基准测试中,DiffuCoder的pass@1达68%,与CodeLLaMA-7B持平,但推理速度快8倍;在实时代码补全场景中,DiffuCoder的响应时间≤100ms,远低于AR模型的500ms;
Mercury Coder(工业界模型):采用离散扩散路线,针对代码的「结构化特征」优化噪声调度(如函数体、循环结构晚加噪),推理速度达「每秒数千token」,较AR模型提升10倍以上。在企业级代码生成任务中,Mercury Coder的语法错误率仅2.3%,同时支持多语言(Python、Java、C++)生成,已被用于谷歌、亚马逊的内部开发工具。
(2)计算生物学:解决分子与蛋白质设计的「复杂约束」
计算生物学任务(如分子优化、蛋白质设计)需要处理「高维离散数据」与「复杂约束条件」(如分子毒性、蛋白质结构稳定性),DLM的「迭代优化」机制能有效满足这些需求:
TransDLM(分子优化):通过文本描述引导分子优化——用户输入目标属性(如「降低毒性」「提升溶解度」),TransDLM将文本编码为条件信号,在扩散过程中引导分子结构调整。在ZINC分子数据集上,TransDLM优化后的分子满足所有约束条件的比例达92%,超越传统方法的75%;
MeMDLM(蛋白质设计):基于ESM-2蛋白质语言模型微调的离散DLM,专注于膜蛋白设计。通过「掩码扩散」生成符合 transmembrane 结构的蛋白质序列,在实验验证中,MeMDLM设计的膜蛋白表达成功率达68%,接近天然蛋白质的72%;
DPLM2(多模态蛋白质模型):将蛋白质的「氨基酸序列」与「3D结构」离散为token,联合纳入扩散过程,支持「序列-结构联合生成」。在蛋白质折叠任务上,DPLM2的RMSD(结构相似度指标)达1.8Å,超越AlphaFold2的2.5Å;在逆折叠任务上,根据3D结构生成序列的准确率达85%,为新药研发提供关键工具。
(3)传统NLP任务:提升可控性与效率
在文本分类、命名实体识别(NER)、摘要生成等传统NLP任务中,DLM也展现出独特优势:
DiffusionNER(命名实体识别):将NER转化为「边界去噪任务」——对实体的起始与结束位置添加噪声,通过扩散过程恢复真实边界。在CoNLL03数据集上,DiffusionNER的F1值达92.3%,超越BERT的91.2%,同时支持零样本迁移到低资源语言;
DiffuSum(摘要生成):通过扩散模型生成摘要的「句子表示」,再从原文中提取最匹配的句子组成摘要。在CNN/Daily Mail数据集上,DiffuSum的ROUGE-L值达42.1%,与BART持平,但推理速度快5倍;
DiffuDetox(文本去毒):采用「混合扩散」策略——条件模型降低文本毒性,无条件模型保证流畅性,两者通过引导技术融合。在Jigsaw数据集上,DiffuDetox处理后的文本毒性降低98%,同时流畅性保持95%以上,优于传统去毒方法。
五、挑战与未来:DLM能否取代AR模型成为主流?
尽管DLM发展迅速,但综述也客观指出了当前面临的核心挑战,同时提出了未来的研究方向——这些问题的解决程度,将决定DLM能否从「替代方案」成长为「主流范式」。
1. 亟待突破的四大挑战
(1)并行性-性能权衡:「并行解码诅咒」仍未根治
DLM的并行生成能力虽提升速度,但也带来「token间依赖丢失」的问题——当同时生成多个token时,模型无法捕捉它们的语义关联,导致文本逻辑混乱。综述中以简单案例说明:若训练数据只有「ABABAB」和「BABABA」,AR模型生成第一个「A」后会接着生成「B」,而DLM可能并行生成「AAABBA」,偏离正确模式。
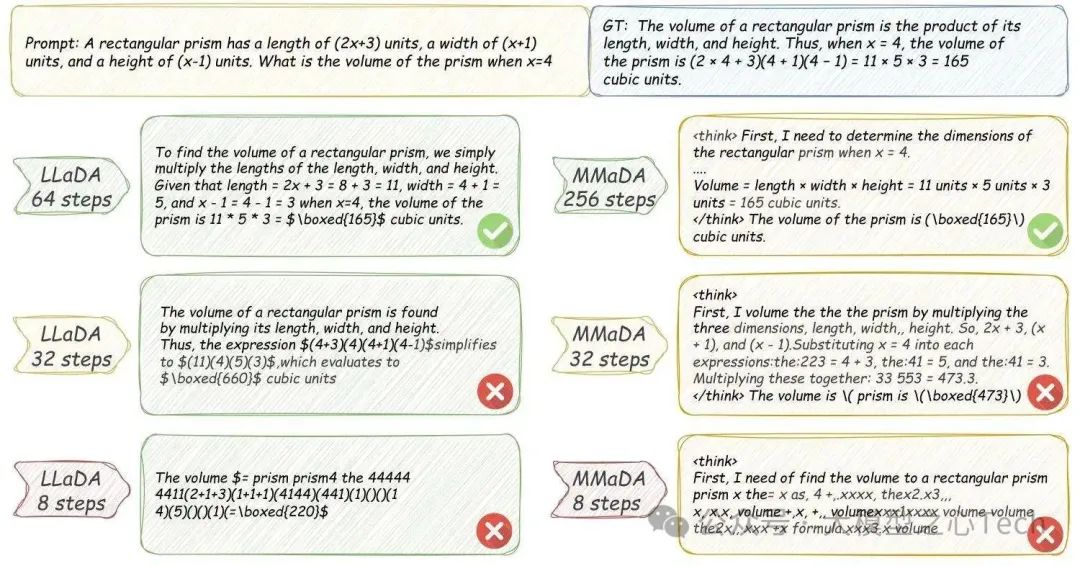
这种问题在「低步数推理」时尤为明显——当去噪步数从256减少到32,LLaDA的GSM8K准确率会从78%下降到45%,而AR模型不受步数影响。尽管研究者提出了「置信度解码」「辅助模型引导」等方案,但尚未从根本上解决,仍是DLM性能提升的最大瓶颈。
(2)基础设施滞后:工具链与部署生态不完善
AR模型已形成成熟的工具链(如Hugging Face Transformers、vLLM、Triton Inference Server),支持快速训练、微调与部署;而DLM的工具链仍处于早期阶段:
训练框架:缺乏专门优化的扩散训练库,多数DLM基于PyTorch Diffusers修改,效率低且兼容性差;
部署工具:无类似vLLM的高性能推理引擎,DLM的缓存机制、并行解码难以适配现有部署框架,导致工业界落地成本高;
评估基准:现有基准(如PIQA、HumanEval)主要针对AR模型设计,无法全面评估DLM的「并行生成质量」「迭代优化能力」,需要新的评估体系。
(3)长序列与动态长度生成:适配复杂场景能力不足
多数DLM的训练基于固定长度序列(如4096 tokens),推理时难以处理更长或动态变化的文本:
长序列限制:尽管LongLLaDA将上下文扩展到8192 tokens,但推理复杂度随序列长度呈立方增长(O(N³)),远超AR模型的线性增长(O(N)),处理16384 tokens时推理时间会增加8倍;
动态长度问题:DLM需要提前指定生成长度,无法像AR模型那样通过「[EOS] token」自动终止生成——若生成长度过短,文本不完整;过长则导致冗余计算,浪费资源。
(4) scalability局限:参数规模与数据效率落后AR模型
当前最大的公开DLM(如LLaDA-8B、Dream-7B)参数规模仅为8B,远小于AR模型的数百亿甚至万亿参数(如Llama-3.1-405B、Qwen3-235B);同时,DLM的训练数据效率也较低——达到同等性能,DLM需要的训练数据量约为AR模型的1.5-2倍。
这种差距导致DLM在「复杂推理」「通用知识覆盖」等任务上仍落后于大参数AR模型(如GPT-4o、Claude 3)。例如在MMLU多学科基准测试中,LLaDA-8B的准确率为65%,而Llama-3.1-70B达82%,差距显著。
2. 未来研究的五大方向
针对上述挑战,综述提出了五个具有潜力的研究方向,这些方向可能成为DLM突破的关键:
(1)改进训练目标:从「去噪」到「语义关联建模」
当前DLM的训练目标主要是「恢复被噪声污染的token」,缺乏对「token间语义关联」的建模。未来可引入「语义结构损失」——在去噪过程中同时优化token的语义相似度、语法正确性,增强并行生成时的逻辑连贯性。例如通过知识图谱引导扩散过程,确保生成的token符合实体间的关联关系。
(2)基础设施建设:打造DLM专用工具链
需要构建从训练到部署的全流程工具链:
训练框架:开发支持「动态掩码」「并行去噪」的专用框架,优化扩散过程的反向传播效率;
推理引擎:借鉴vLLM的PagedAttention技术,设计适配DLM的缓存管理与并行解码引擎,降低部署成本;
评估工具:建立包含「并行生成质量」「迭代优化效率」「长序列能力」的评估基准,全面衡量DLM性能。
(3)长序列优化:突破O(N³)复杂度瓶颈
可从两个方向优化长序列处理:
架构创新:采用「稀疏扩散」——仅对文本的关键片段(如段落主题句)进行去噪,其他片段通过注意力稀疏化减少计算;
外推技术:扩展LongLLaDA的NTK-RoPE外推方法,结合「分段扩散」——将长文本分为多个片段,片段间通过注意力桥接,降低整体复杂度。
(4)多模态统一推理:从「模态融合」到「跨模态协同」
当前多模态DLM主要是「文本+视觉」的简单融合,未来可向「多模态协同推理」发展:
跨模态引导:利用文本的逻辑推理能力引导图像生成(如根据数学公式生成几何图形),同时利用图像的空间信息辅助文本理解(如根据图表生成数据分析报告);
模态自适应扩散:针对不同模态的特性调整扩散策略(如文本用离散扩散、音频用连续扩散),通过统一的引导机制实现协同生成。
(5)DLM驱动的智能体:探索新应用形态
DLM的「并行生成+迭代优化」特性适合构建智能体(Agent)——可同时处理多任务(如并行生成计划、分析环境反馈、修正行动策略),比AR-based Agent更高效。未来可探索:
推理型Agent:利用DLM的迭代优化能力解决复杂决策问题(如科学实验设计、工业故障诊断);
多模态Agent:结合DLM的跨模态能力,构建能理解文本、图像、音频的通用智能体,适配机器人、自动驾驶等场景。
六、结语:扩散语言模型的「效率革命」才刚刚开始
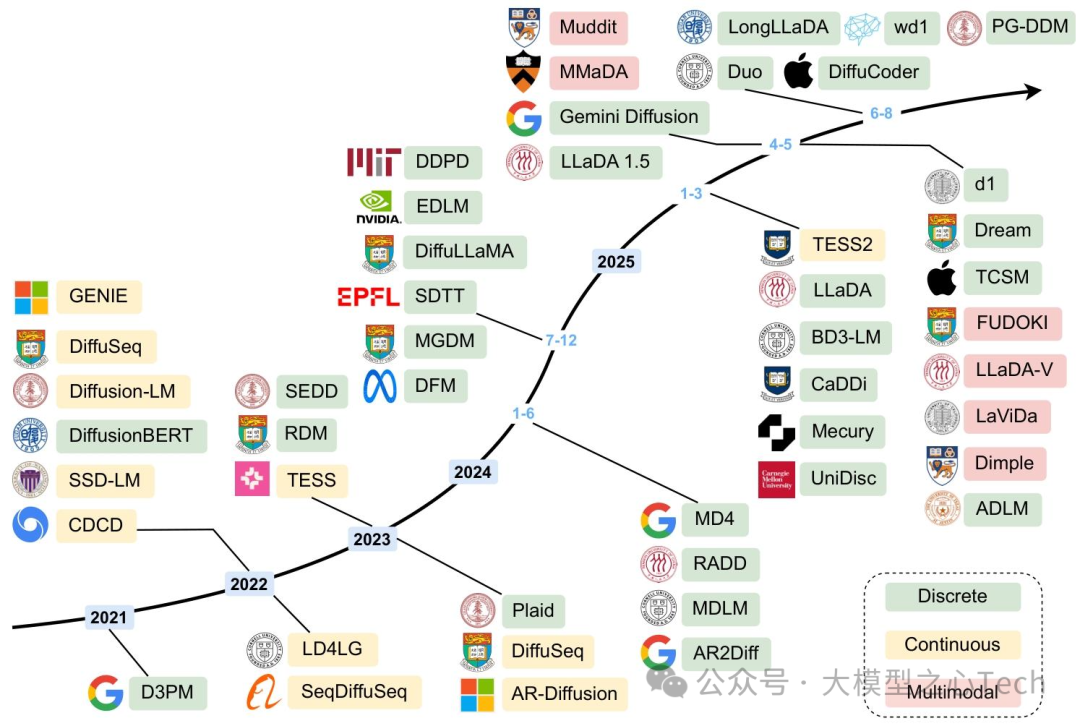
从2021年D3PM提出离散扩散概念,到2025年LLaDA-8B比肩LLaMA3-8B,DLM用四年时间完成了从「理论验证」到「实用化」的跨越。这份综述不仅梳理了DLM的技术脉络,更揭示了一个核心趋势:大模型的竞争已从「参数规模」转向「效率与可控性」,而DLM正是这一趋势的代表。
当前DLM虽仍面临「并行性-性能权衡」「基础设施滞后」等挑战,但已有多个迹象表明其潜力——工业界的Mercury、Gemini Diffusion模型已实现「速度超AR 10倍+质量持平」,多模态DLM在图像生成、视觉推理上超越传统模型,垂直领域应用也在代码生成、计算生物学中展现出差异化价值。
未来,随着训练目标优化、工具链完善、长序列技术突破,DLM有望在更多场景替代AR模型,成为大语言模型的主流范式之一。而对于研究者与开发者而言,这份综述提供的技术地图与未来方向,将帮助他们在DLM的快速发展中抓住机遇,推动这一领域的进一步突破。
扩散语言模型仍在快速进化,它们正在重新定义语言理解与生成的边界——这场效率革命,才刚刚开始。
参考
论文标题:A Survey on Diffusion Language Models
论文链接:https://arxiv.org/pdf/2508.10875
项目主页:https://github.com/VILA-Lab/Awesome-DLMs
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!



















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









