



点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Xiaoxue Chen等
编辑 | 自动驾驶之心
清华大学与小米汽车联合推出 DGGT(Driving Gaussian Grounded Transformer):一个pose-free、feed-forward的4D动态驾驶场景重建框架。
DGGT 只需未标定的稀疏图像,单次前向即可同时输出相机位姿、深度、动态实例与基于 3D Gaussian 的可编辑场景表示。模型在 Waymo 上训练,却能在 nuScenes 与 Argoverse2 上实现强劲的零样本泛化——在关键感知指标上相比STORM提升超过 50%。此外,系统通过lifespan head建模场景随时间的外观演变,并配合单步扩散精修,有效抑制运动插值伪影,提升时空一致性与渲染自然度。
论文标题:DGGT: Feedforward 4D Reconstruction of Dynamic Driving Scenes using Unposed Images
开源链接:https://github.com/xiaomi-research/dggt
项目主页:https://xiaomi-research.github.io/dggt/
亮点速览
无需外参(Pose-Free): 将相机位姿从输入转为模型输出,端到端预测内外参并融入场景表示,打破跨数据集部署的校准壁垒。
Feed-forward 4D表示: 采用多头联合预测结构(相机、4D Gaussian、lifespan、动态/运动、天空等),一次前向即可得到时空一致的可编辑表示。
跨数据集零样本泛化: 仅在 Waymo 训练,无需在目标数据集上微调即可在 nuScenes 与 Argoverse2 上获得优于SOTA的定量与定性结果(LPIPS 降幅 52%–61%)。
可编辑性强: 支持直接在 Gaussian 层面添加/删除/移动车辆、行人等实例,扩散精修自动补洞,输出可用于仿真与数据合成。
速度与质量兼顾:在Waymo上20 帧/视角,单场景约 0.39 s;PSNR 27.41 / SSIM 0.846,与优化类方法相比显著加速,与前向方法相比更高保真。
DGGT详解
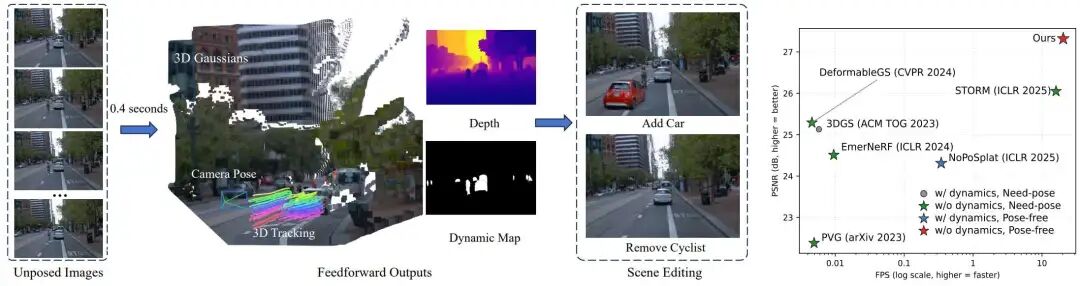
DGGT 的核心思想是:一次前向就预测出“完整的4D场景状态”,并把相机位姿从前提变成结果。这使得系统无需外参标定即可从稀疏、未标定图像里恢复动态场景,而且能自然跨数据集部署。图1展示了DGGT 的整体能力与速度-精度位置:在0.4 秒量级完成重建的同时,DGGT 在重建质量上超越一系列前向与优化方法,并将相机姿态、深度、动态分割、3D Gaussian、追踪等输出一并给出,便于后续实例级场景编辑。
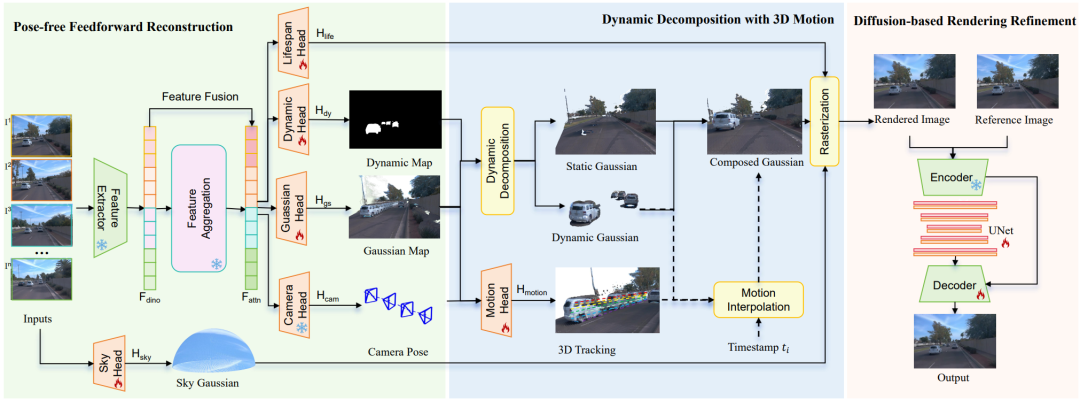
在系统结构上(图2),DGGT 采用 ViT 编码器融合 DINO 先验,通过交替注意力得到共享特征,再由多个预测头并行输出:
(1)相机头估计各帧内外参;
(2)Gaussian 头给出逐像素 Gaussian 参数(颜色/位置/旋转/尺度/不透明度);
(3)lifespan 头用寿命参数调制时间维度可见性,精确刻画静态区域在不同时间的外观变化;
(4)动态头+运动头显式估计动态区域与 3D 运动轨迹,支持任意时间点的运动插值;
(5)天空头稳定建模远景背景。渲染后,再通过单步扩散精修抑制遮挡/插值产生的伪影与细节缺失。
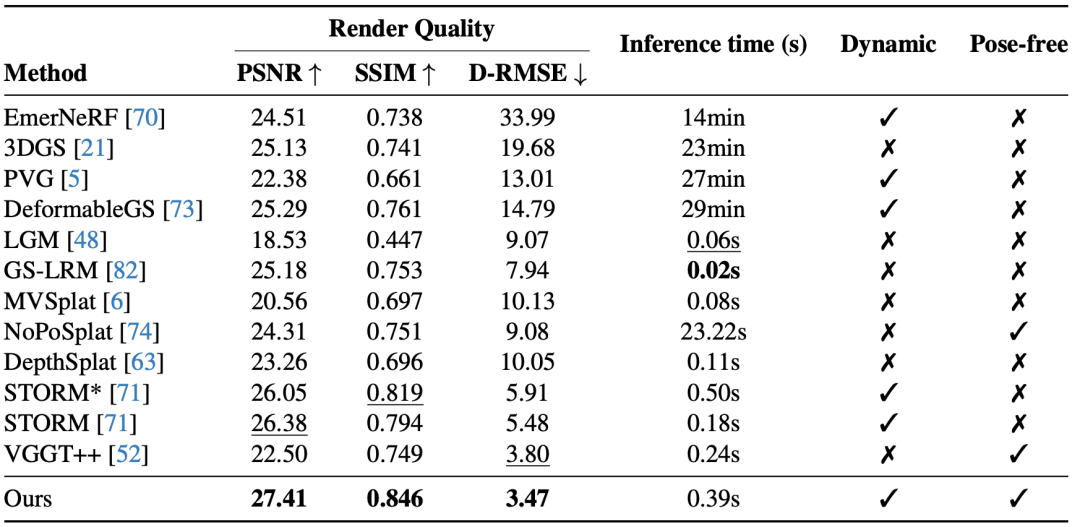

在Waymo数据集上的定性与定量评估(见表1)表明:以往的前馈式静态重建方法(如 MVSplat、NoPoSplat、DepthSplat)在存在大范围运动目标的场景中难以维持时间一致性,且会产生明显的错配与伪影;而STORM虽然通过前馈式建模缓解了对逐场景优化的依赖,但在处理更长的时序跨度或更复杂的动态行为时仍可能出现性能退化。相比之下,DGGT能够在渲染级别上实现对静态与动态成分的有效分离,保持帧间外观与几何的一致性,从而显著提升整体视觉质量与重建稳定性。在定量指标上(表2),DGGT 在场景流估计上的EPE_3D为0.183 m,明显优于多种既有方法,证明了通过渲染监督学得的稠密三维对应具有良好的可靠性与精度。
跨数据集的零样本泛化能力是 DGGT 的另一项核心优势。模型仅在Waymo上训练,但在未做任何微调的情况下,在nuScenes与Argoverse2上均取得超越现有SOTA的结果(见表3):如在nuScenes上 LPIPS从0.394 降至0.152(下降 61.4%);在 Argoverse2上从0.326降至 0.155(下降52.5%)。这种跨域鲁棒性主要得益于DGGT 的pose-free 设计:将位姿从输入转为模型输出,减少了对固定拍摄轨迹与相机配置的依赖,从而降低了对特定数据采集设置的过拟合风险,使模型在不同传感器布置与行驶路径下仍能维持良好性能。
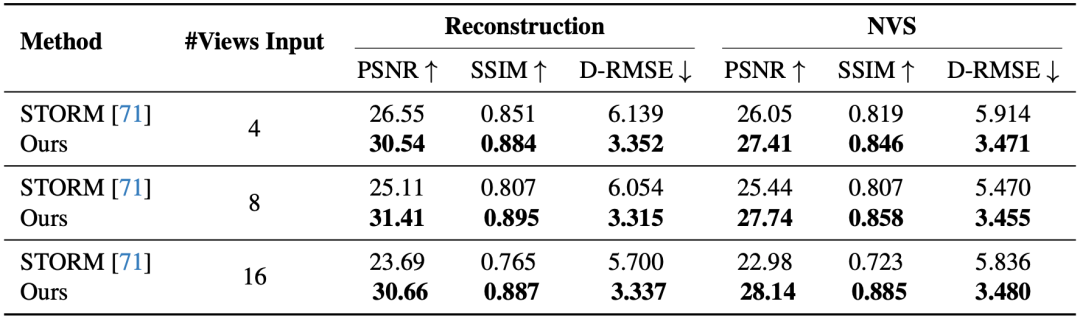
在可扩展性方面,DGGT 能自然支持任意数量的输入视角与长序列。从表4可以看到,当输入视角从 4 → 8 → 16 扩增时,DGGT 的重建与新视角插值(NVS)指标基本不变,而对比方法会明显下滑。这意味着 DGGT 不仅适合研究场景,更适合在大规模输入中做工程级预处理与批量重建,视角变多时不需要额外改模型或调参数。

Lifespan head 的作用在图3中的消融对比非常直接:去掉 lifespan 后,PSNR 从 27.41 降至 24.21,原因在于系统失去了对静态区域在时间维度上的细微变化(如亮度、反射、阴影过渡等)的建模能力。世界坐标静态的地方一旦无法随时间正确更新,就会破坏渲染的时空一致性与真实感,从而显著拉低最终画面质量。

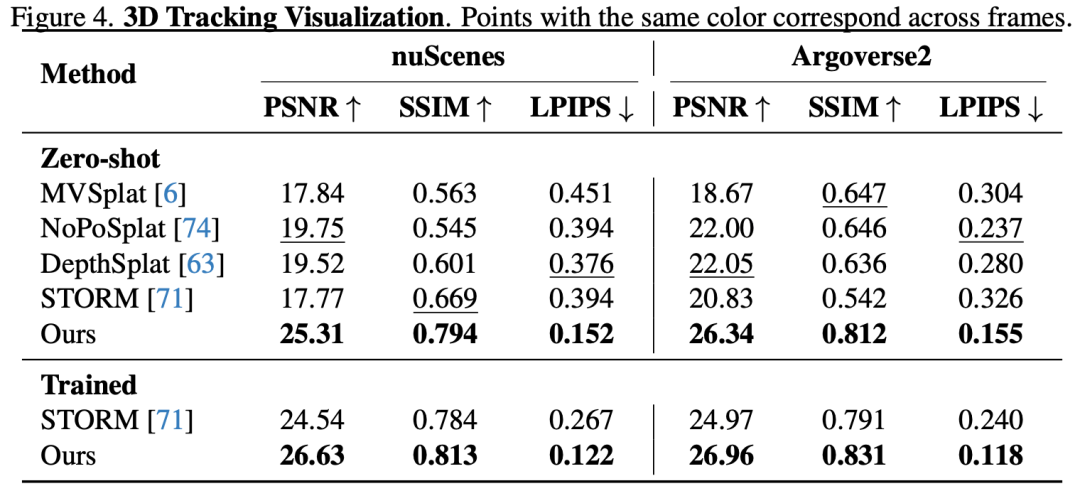
Motion head负责把动态像素在时间上对齐(图4):它直接预测像素级的 3D 位移,用于将同一物体在相邻帧中对齐并做插值。也就是说,模型不只是预测静态形状,而是学会了像素到像素的时序对应,从而在生成中间帧或执行编辑时显著减少错配与拖影,保证运动物体在时间上的连续性与视觉自然度。

在场景编辑与扩散精修方面(图5),DGGT 直接在 3D Gaussian 表示层面支持实例级操作——可以对单个高斯体执行“新增/删除/平移/替换”等编辑;随后引入的扩散精修模块会自动填补因遮挡产生的空洞、弱化边缘锯齿并修复纹理缝隙。经过这两步处理,合成结果在几何与外观上都保持高度一致且自然可信。
这意味着 DGGT 不只是“重建器”,更是“可编辑的 4D 场景资产生成器”,非常契合自动驾驶仿真、评测与数据合成等下游需求。
自动驾驶之心
3DGS理论与算法教程!

添加助理咨询课程!

知识星球交流社区


















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









