



点击下方卡片,关注“自动驾驶之心”公众号
扩散模型作为生成式AI的重要技术,近年来在自动驾驶领域展现出广泛的应用前景。该模型凭借其强大的多模态建模能力,能够从复杂数据分布中生成多样性强、符合物理约束的结果,为自动驾驶系统提供新的解决方案。
在感知层面,基于扩散模型的三维占用预测方法显著优于传统判别方法,尤其在处理遮挡或低可见度区域时表现突出,生成的占用特征能有效支持下游规划任务。 同时,条件扩散模型被应用于驾驶场景的精准图像翻译,帮助系统更好地理解和适应各种道路环境。
在预测与决策方面,稳定扩散模型可高效完成车辆轨迹预测任务,生成高精度的其他车辆运动轨迹预测结果,显著提升自动驾驶系统的预测能力。DiffusionDrive框架则利用扩散模型对多模态动作分布的建模能力,实现了端到端自动驾驶的创新应用,通过多模态锚点和截断的扩散机制处理驾驶决策中的不确定性。
数据生成是扩散模型另一重要应用方向,有效解决了自然驾驶数据集多样性不足、真实性与可控性受限的难题,为自动驾驶验证提供高质量合成数据。这类可控生成技术对解决3D数据标注挑战尤为重要,未来还将探索视频生成以进一步提升数据质量。
总结来说,扩散模型在自动驾驶领域可显著提升数据多样性、增强感知系统鲁棒性,并有效辅助决策模块处理各类不确定性,为下一代自动驾驶技术发展提供重要支撑。可以说扩散模型已经成为自动驾驶基础模型重要的一环,今天自动驾驶之心就为大家总结一下扩散模型在自动驾驶基础模型中的相关工作,本文全部文章已汇总至『自动驾驶之心知识星球』,欢迎加入和我们一起打造自动驾驶的未来~

论文标题:Dual-Conditioned Temporal Diffusion Modeling for Driving Scene Generation
主页链接:https://zzzura-secure.duckdns.org/dctdm
代码链接:https://github.com/PeteBai/DcTDM
工作单位:东北大学
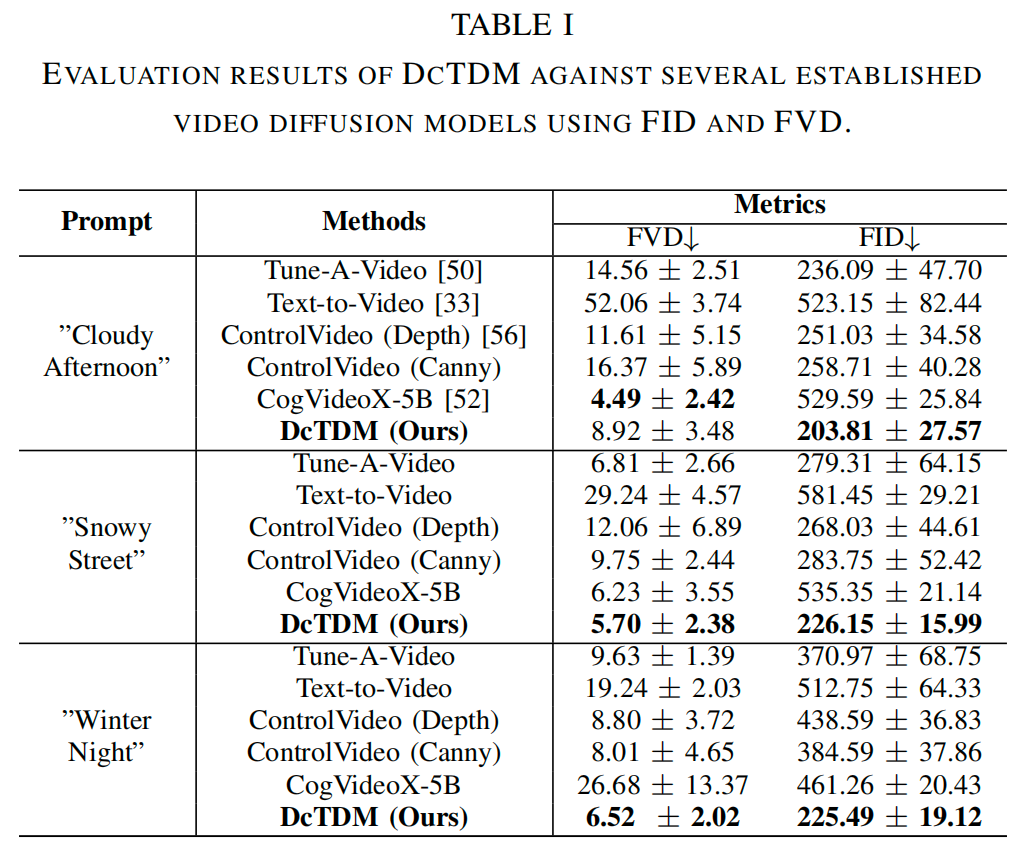
ICRA2025美国东北大学中稿的最新工作!扩散模型已被证明在从学习到的分布中生成高质量图像方面非常有效,但其在时间域的应用,尤其是在驾驶场景中的应用,仍未得到充分探索。本文的工作通过扩展扩散模型来生成逼真的长时间驾驶视频,解决了现有仿真中的关键挑战,如数据质量有限、多样性和高成本。本文提出了双条件时间扩散模型(DcTDM),这是一种开源方法,通过引导帧转换来结合双条件来增强时间一致性。除了DcTDM,本文还推出了DriveSceneDDM,这是一个全面的驾驶视频数据集,包含文本场景描述、密集深度图和坎尼边缘数据。本文使用常见的视频质量指标对DcTDM进行了评估,结果表明,通过生成长达40秒、节奏一致且连贯的驾驶视频,DcTDM的性能优于其他视频扩散模型,在一致性和帧质量方面提高了25%以上!
算法概览:
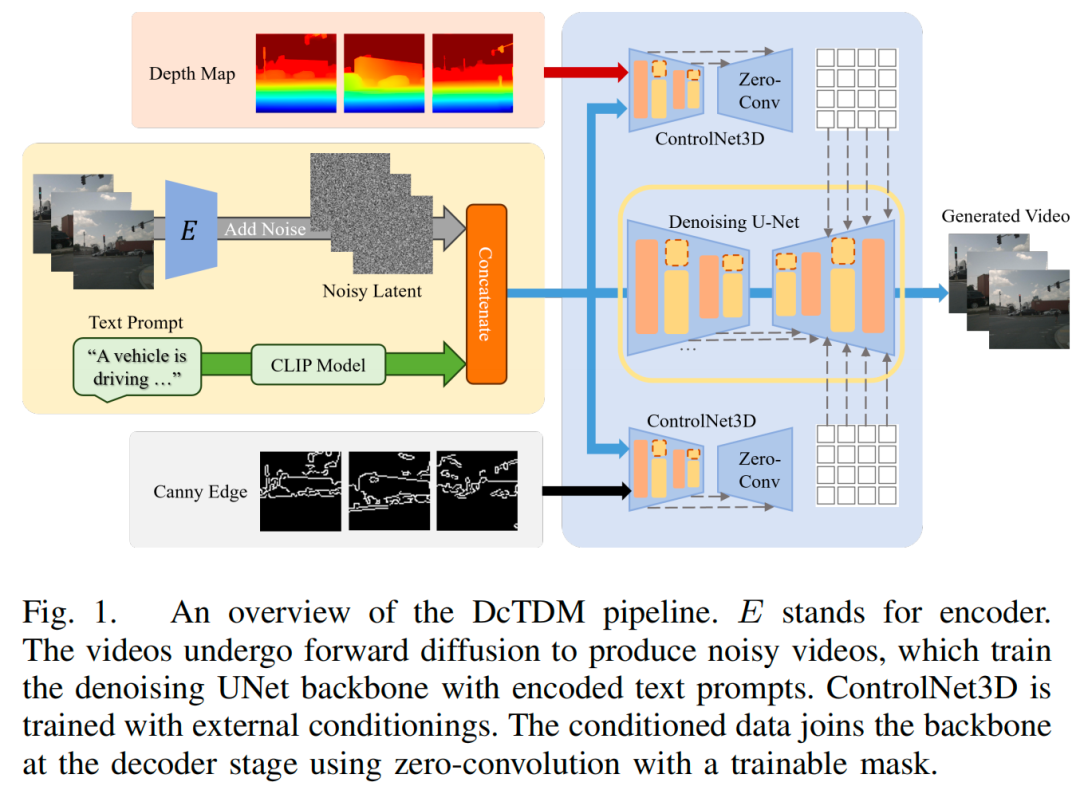
主要实验结果:
标题:LD-Scene: LLM-Guided Diffusion for Controllable Generation of Adversarial Safety-Critical Driving Scenarios
链接:https://arxiv.org/abs/2505.11247
作者单位:香港科技大学(广州),中山大学
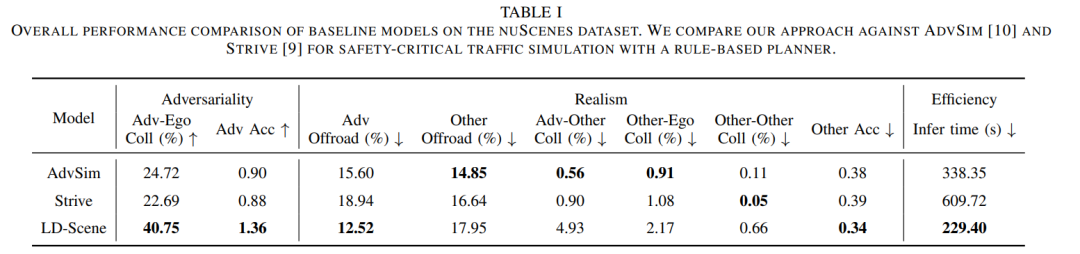
为确保自动驾驶系统的安全性与鲁棒性,需在安全关键场景下进行全面评估。然而,此类场景在真实驾驶数据中稀缺且难以收集,对自动驾驶车辆的性能评估构成重大挑战。现有方法通常因可控性有限且依赖专家知识而缺乏用户友好性。为此,本文提出 LD-Scene——一种融合大语言模型(LLMs)与潜在扩散模型(LDMs)的新型框架,通过自然语言实现用户可控的对抗性场景生成。该框架包含一个学习真实驾驶轨迹分布的LDM,以及一个基于LLM的引导模块,后者将用户查询转化为对抗性损失函数,驱动生成符合用户需求的场景。引导模块集成基于LLM的思维链(CoT)代码生成器和代码调试器,提升了对抗场景生成的可控性、鲁棒性与稳定性。在 nuScenes 数据集上的实验表明,LD-Scene 在生成高对抗性、高真实性与多样性的场景中达到最先进性能,同时支持对对抗行为(如碰撞类型与强度)的细粒度控制,为定制化测试提供有效工具。
算法概览:
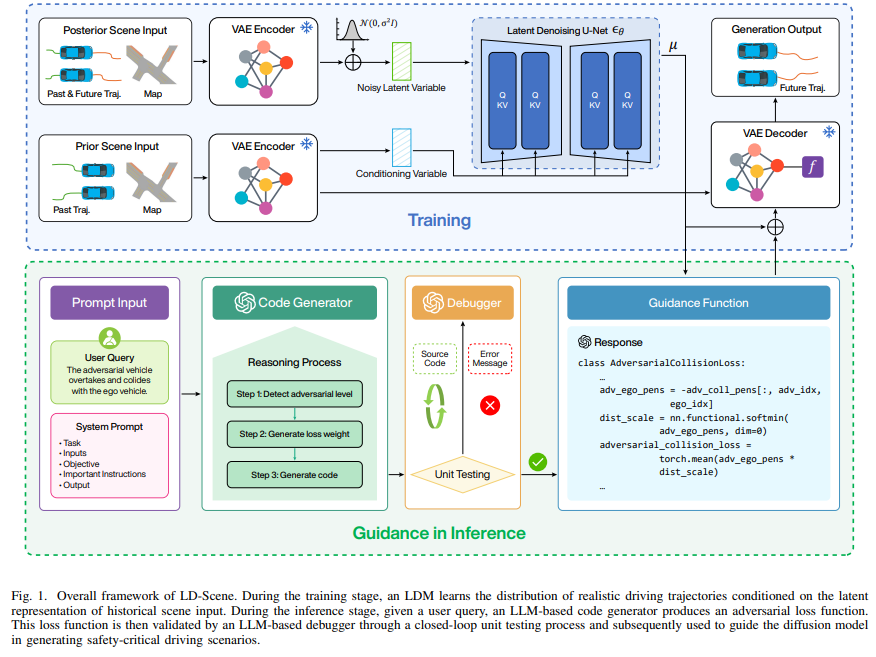
主要实验结果:
标题:DualDiff: Dual-branch Diffusion Model for Autonomous Driving with Semantic Fusion
链接:https://www.arxiv.org/abs/2505.01857
作者单位:西安交通大学,中国科学技术大学
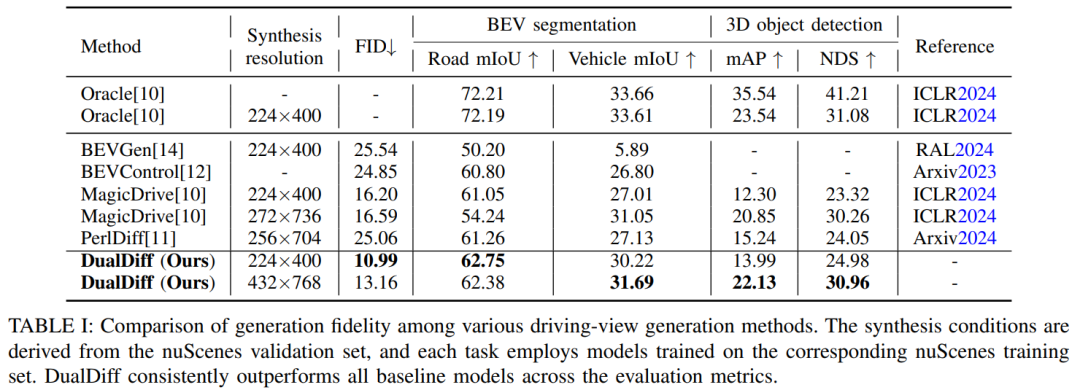
准确且高保真的驾驶场景重建依赖于充分挖掘场景信息作为条件输入。然而,现有方法主要使用3D边界框和二值图进行前景与背景控制,在捕捉场景复杂性和整合多模态信息方面存在明显不足。本文提出DualDiff,一种专为增强多视角驾驶场景生成而设计的双分支条件扩散模型。本文引入了语义丰富的3D表示——占用射线采样(Occupancy Ray Sampling, ORS),并结合数值驾驶场景表示,实现全面的前景与背景控制。为改善跨模态信息整合,本文提出了语义融合注意力(Semantic Fusion Attention, SFA)机制,用于对齐和融合跨模态特征。此外,本文设计了前景感知掩码(Foreground-aware Masked, FGM)损失函数,以增强微小目标的生成质量。DualDiff在FID分数上达到了最先进水平,并在下游的BEV分割和3D目标检测任务中始终取得更优结果。
算法概览:
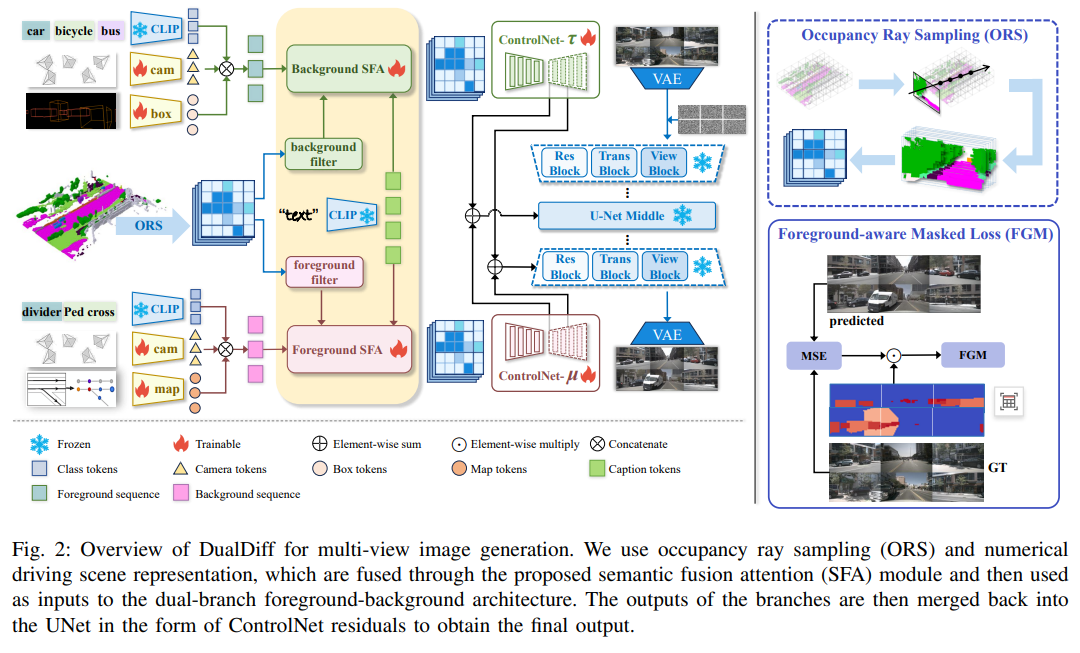
主要实验结果:
标题:DiVE: Efficient Multi-View Driving Scenes Generation Based on Video Diffusion Transformer
链接:https://arxiv.org/abs/2504.00000
作者单位:清华大学,哈尔滨工业大学,理想
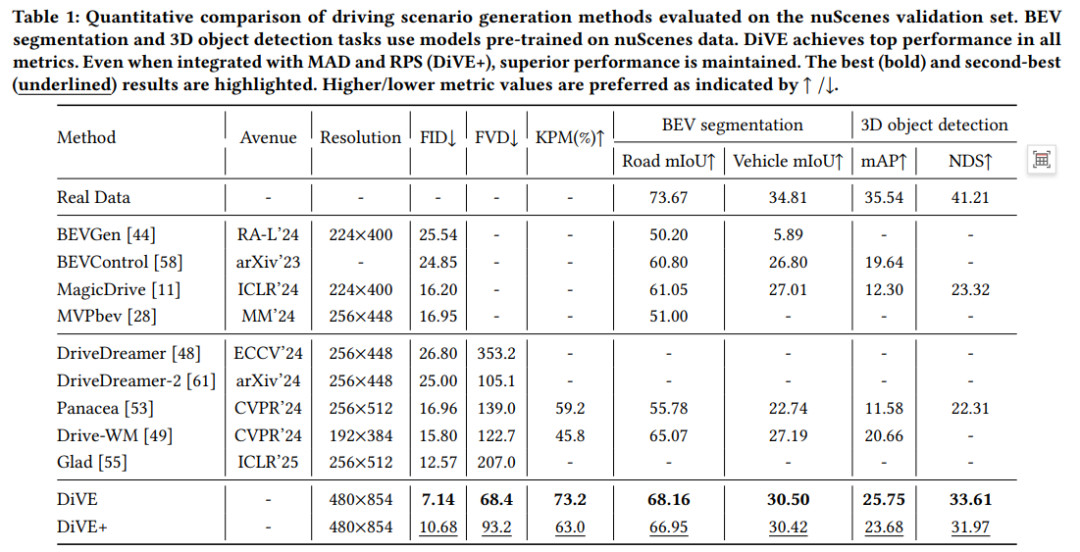
收集多视图驾驶场景视频以提升 3D 视觉感知任务的性能面临巨大挑战且成本高昂,这使得生成逼真数据的生成模型成为一种极具吸引力的替代方案。然而,现有研究生成的视频存在质量不佳和时空一致性差的问题,削弱了其在推动驾驶场景下感知任务发展中的作用。为解决这一差距,本文提出了 DiVE,这是一种基于扩散 Transformer 的生成框架,专门设计用于生成高保真、时间连贯且跨视图一致的多视图视频,能够与鸟瞰图布局和文本描述无缝对齐。具体而言,DiVE 利用统一的交叉注意力机制和 SketchFormer 对多模态数据进行精确控制,同时引入了不增加额外参数的视图膨胀注意力机制,从而保证视图间的一致性。尽管取得了这些进展,在多模态约束下合成高分辨率视频仍面临双重挑战:研究复杂多条件输入下的最优无分类器引导(CFG)配置,以及减轻高分辨率渲染中的过度计算延迟 —— 这两者在先前研究中均未得到充分探索。为解决这些局限,本文引入了两项技术创新:(1)多控制辅助分支蒸馏(MAD),它简化了多条件 CFG 选择,同时规避了高昂的计算开销;(2)分辨率渐进采样(RPS),这是一种无需训练的加速策略,通过错开分辨率缩放来减少高分辨率带来的高延迟。这些创新共同实现了 2.62 倍的速度提升,同时几乎不损失性能。在 nuScenes 数据集上的评估表明,DiVE 在多视图视频生成方面达到了最先进的性能,生成的输出具有极高的真实感、出色的时间和跨视图连贯性。通过弥合合成数据质量与真实世界感知需求之间的差距,DiVE 建立了一个强大的生成范式,有望推动 3D 感知系统的重大进步。
算法概览:
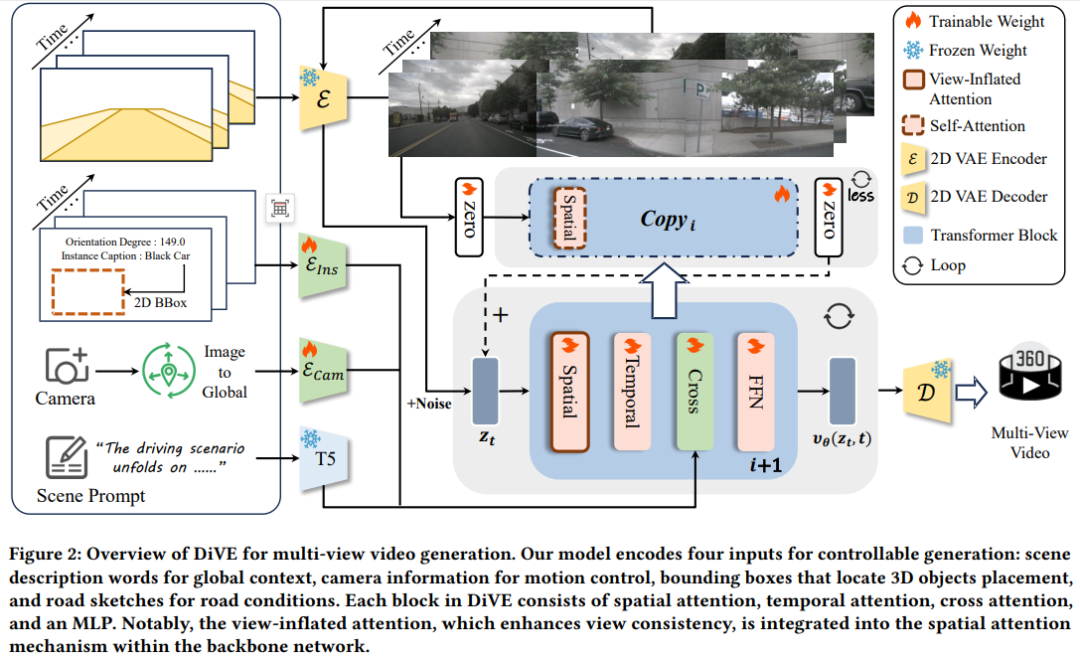
主要实验结果:
标题:DriveGen: Towards Infinite Diverse Traffic Scenarios with Large Models
链接:https://arxiv.org/abs/2503.05808
作者单位:上海交通大学,长安汽车
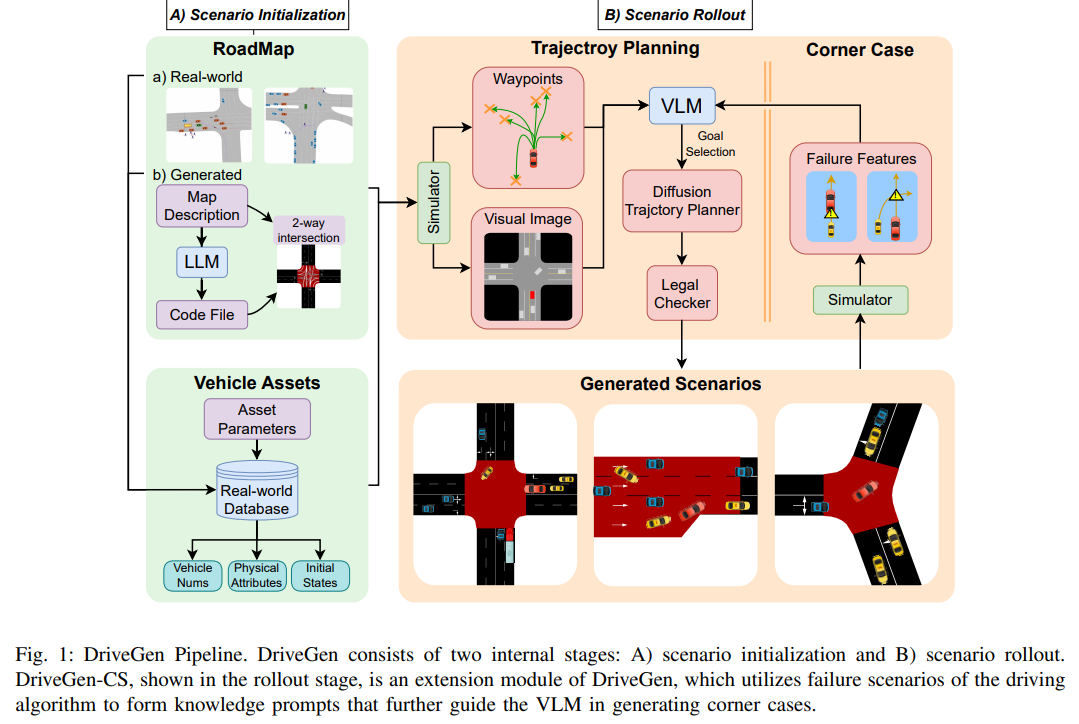
交通仿真已成为自动驾驶训练与测试的重要工具。尽管当前数据驱动方法提升了行为生成的逼真度,但其学习过程仍主要依赖单一真实数据集,限制了场景多样性,进而阻碍下游算法优化。本文提出 DriveGen——一种基于大模型的新型交通仿真框架,可生成多样化交通场景并支持定制化设计。DriveGen 包含两个核心阶段:
初始化阶段:利用大语言模型(LLM)与检索技术生成地图及车辆资产;
推理阶段:通过视觉语言模型(VLM)选取路径点目标,结合定制扩散规划器输出轨迹。
该两阶段框架充分运用大模型对驾驶行为的高层认知与推理能力,在保持高真实性的同时,实现超越数据集的多样性。为支持高效下游优化,本文进一步开发 DriveGen-CS——一种自动生成极端案例(Corner Case)的流程,其利用驾驶算法的失败案例作为大模型的提示知识,无需重新训练或微调。实验表明,生成场景与极端案例的质量均优于现有基线;下游实验进一步验证,DriveGen 合成的交通数据能更优地提升典型驾驶算法性能,证明了框架的有效性。
算法概览:
主要实验结果:
标题:Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
链接:https://arxiv.org/abs/2503.22496
项目主页:https://princeton-computational-imaging.github.io/scenario-dreamer
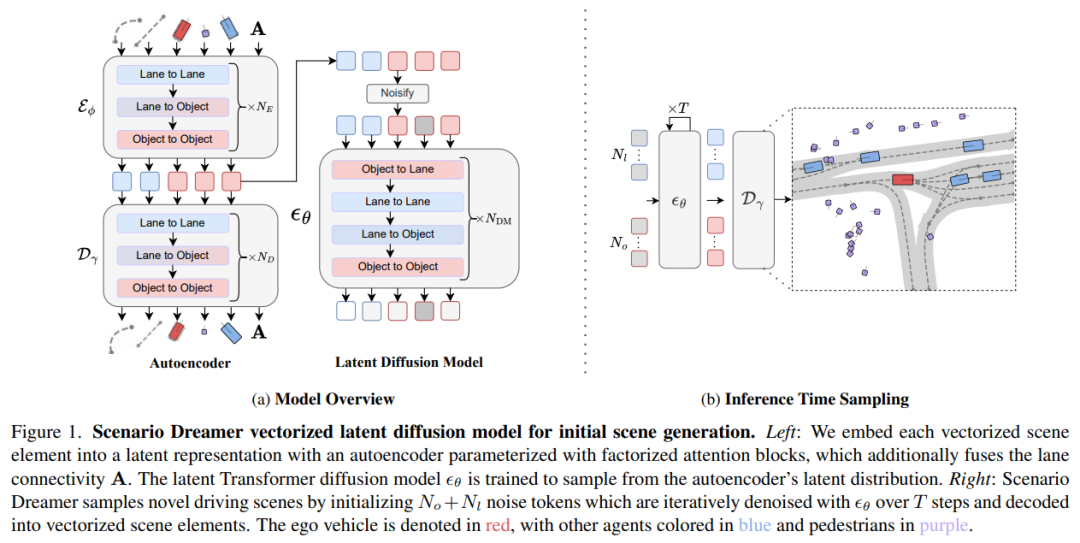
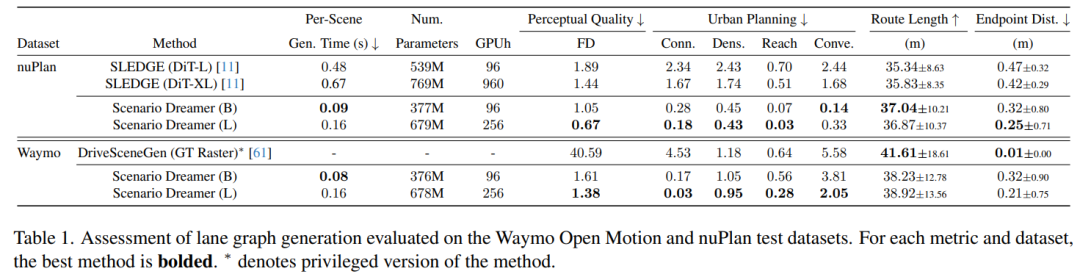
本文提出Scenario Dreamer,一种完全数据驱动的自动驾驶规划生成仿真器。Scenario Dreamer的核心是一种新颖的向量化潜在扩散模型,用于初始场景生成,相比先前采用栅格化场景编码的方法具有显著的实际优势。实验表明,Scenario Dreamer在真实性和效率方面优于现有生成仿真器:向量化场景生成基础模型以约2倍更少的参数、6倍更低的生成延迟以及10倍更少的GPU训练小时数,实现了优于最强基线的生成质量。本文通过实验证实其实际效用:强化学习规划代理在Scenario Dreamer环境中比在传统非生成仿真环境中面临更大挑战,尤其是在长距离和对抗性驾驶环境中。贡献包括:(1) 本文引入Scenario Dreamer,这是一种完全数据驱动的自动驾驶规划生成仿真器。Scenario Dreamer的核心是一种新颖的向量化潜在扩散模型,用于初始场景生成,相比先前利用栅格化场景编码的方法具有实际优势。(2) 本文证明Scenario Dreamer环境对强化学习规划器构成挑战,特别是在长距离和对抗性驾驶环境中。
算法概览:
主要实验结果:
标题:DualDiff+: Dual-Branch Diffusion for High-Fidelity Video Generation with Reward Guidance
链接:https://arxiv.org/abs/2503.03689
项目主页:https://github.com/yangzhaojason/DualDiff
作者单位:西安交通大学,浙江大学,中国科学院自动化研究所等
精确且高保真的驾驶场景重建需要有效利用全面的场景信息作为条件输入。现有方法主要依赖 3D 边界框和BEV道路图来控制前景和背景,但其无法捕捉驾驶场景的全部复杂性,也不能充分融合多模态信息。在本研究中,本文提出了 DualDiff,一种双分支条件扩散模型,旨在提升多视角和视频序列的驾驶场景生成效果。具体而言,本文引入占用率射线形状采样(ORS)作为条件输入,其提供丰富的前景和背景语义信息以及 3D 空间几何结构,以精确控制两者的生成。为改善细粒度前景目标(尤其是复杂和远处目标)的合成效果,本文提出了前景感知掩码(FGM)去噪损失函数。此外,本文开发了语义融合注意力(SFA)机制,以动态优先处理相关信息并抑制噪声,实现更有效的多模态融合。最后,为确保高质量的图像到视频生成,本文引入奖励引导扩散(RGD)框架,以维持生成视频的全局一致性和语义连贯性。大量实验表明,DualDiff 在多个数据集上实现了最先进(SOTA)的性能。在 NuScenes 数据集上,与最佳基线相比,DualDiff 将 FID 分数降低了 4.09%。在下游任务中,如 BEV 分割,本文的方法将车辆 mIoU 提升了 4.50%,道路 mIoU 提升了 1.70%;在 BEV 3D 目标检测中,前景 mAP 提高了 1.46%。
算法概览:

主要实验结果:

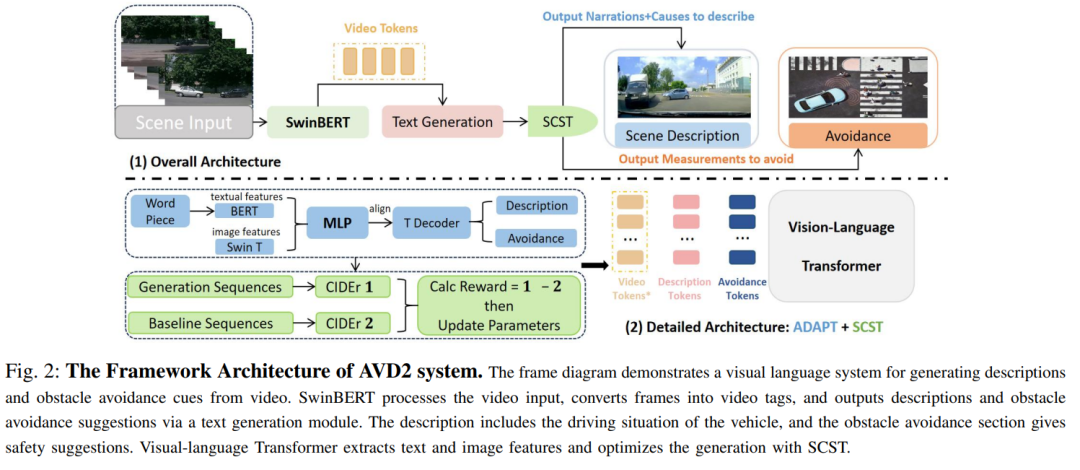
标题:AVD2: Accident Video Diffusion for Accident Video Description
链接:https://arxiv.org/pdf/2502.14801
项目主页:https://an-answer-tree.github.io/
作者单位:香港科技大学,AIR,吉林大学等
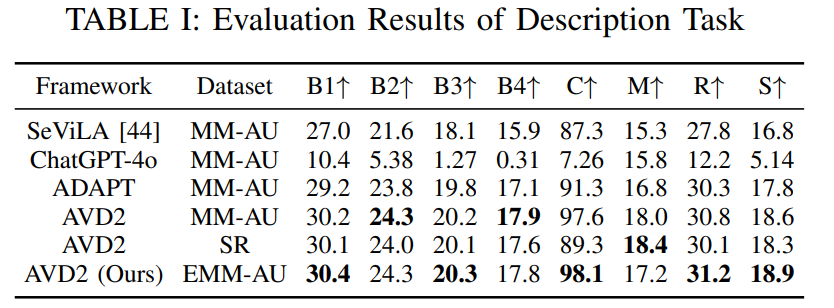
交通事故对自动驾驶系统提出了复杂挑战,其不可预测性常导致系统难以精准解析与响应。然而,由于事故场景训练数据的匮乏,现有方法难以阐明事故成因并提出预防策略。为此,本文提出 AVD2(事故视频扩散描述框架),该框架通过生成与详细自然语言描述及推理对齐的事故视频,增强事故场景理解能力,并构建 EMM-AU(增强型多模态事故视频理解)数据集。实验表明,集成 EMM-AU 数据集后,模型在自动化指标与人工评估中均达到 SOTA 性能,显著推动了事故分析与预防领域的发展。
算法概览:
主要实验结果:
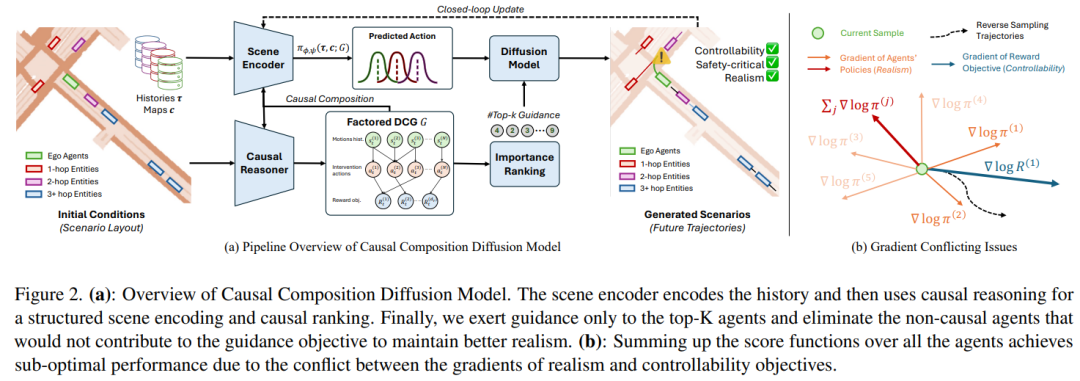
标题:Causal Composition Diffusion Model for Closed-loop Traffic Generation
链接:https://arxiv.org/abs/2412.17920
项目主页:https://sites.google.com/view/ccdiff/
作者单位:卡内基梅隆大学,伊利诺伊大学香槟分校等
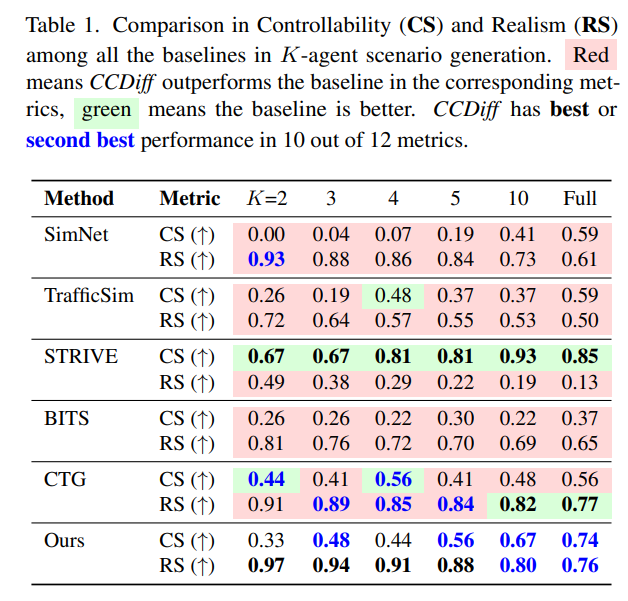
本文提出CCDiff(因果组合扩散模型),旨在提升自动驾驶领域闭环安全关键场景生成中的可控性与真实性。基于约束因子化马尔可夫决策过程(constrained factored MDP)的框架,CCDiff首先识别智能体间的潜在因果结构,然后将该结构融入场景编码器,并基于因果知识对智能体的重要性进行排序,从而提升生成场景的真实性。CCDiff同时采用因果组合场景编码与分解式引导策略,有效解决了可控性与真实性目标间的梯度冲突问题。在基准数据集和闭环仿真器中的严格评估表明,CCDiff在生成真实且符合用户偏好的轨迹方面显著优于现有最先进方法。实验结果证实CCDiff在提取和利用因果结构方面的有效性,基于碰撞率、偏离道路率、最终位移误差和舒适距离等关键指标,展示了改进的闭环性能。
算法概览:
主要实验结果:
标题:Direct Preference Optimization-Enhanced Multi-Guided Diffusion Model for Traffic Scenario Generation
链接:https://arxiv.org/abs/2502.12178
作者单位:浦项科技大学,NAVER LABS
基于扩散的模型在利用真实世界驾驶数据生成真实且多样的交通场景方面的有效性已得到认可。这些模型采用引导采样来整合特定的交通偏好并增强场景真实性。然而,引导采样过程以符合交通规则和偏好可能导致偏离真实世界交通先验,进而可能产生不真实的行为。为解决这一挑战,本文提出了一种多引导扩散模型,该模型采用新颖的训练策略,即使在使用多种引导组合时也能紧密贴合交通先验。该模型采用多任务学习框架,使单个扩散模型能够处理各种引导输入。为提高引导采样精度,本文使用直接偏好优化(DPO)算法对模型进行微调。该算法基于引导分数优化偏好,有效应对引导采样微调过程中昂贵且常不可微分的梯度计算所带来的复杂性和挑战。在 nuScenes 数据集上的评估表明,本文的模型为平衡交通场景生成中的真实性、多样性和可控性提供了强有力的基准。
算法概览:
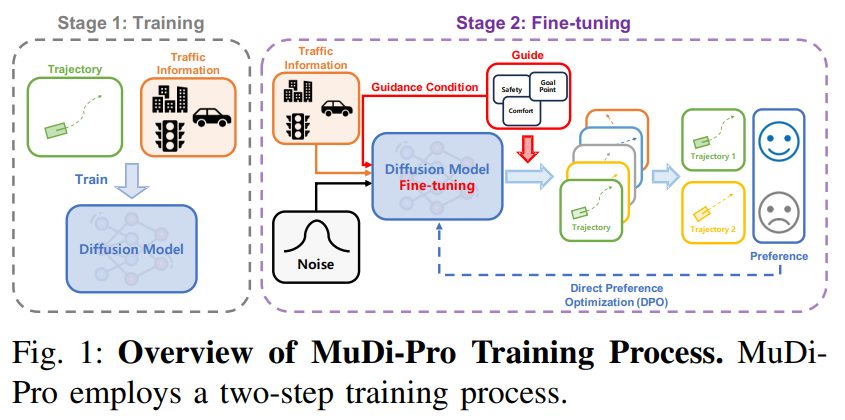
主要实验结果:
标题:SceneDiffuser: Efficient and Controllable Driving Simulation Initialization and Rollout
链接:https://arxiv.org/pdf/2412.12129
项目主页:https://sjyu001.github.io/MuDi-Pro/
作者单位:Waymo LLC
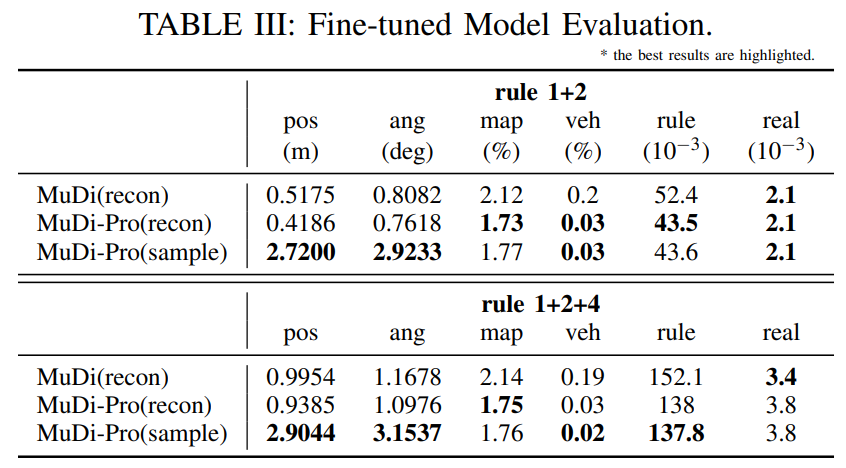
逼真且交互式的场景仿真是自动驾驶开发的关键前提。本文提出 SceneDiffuser,一种面向交通仿真的场景级扩散先验模型。该模型提供统一框架,解决仿真的两个核心阶段:场景初始化(生成初始交通布局)与场景推演(智能体行为的闭环仿真)。尽管扩散模型已被证明能有效学习逼真且多模态的智能体分布,但仍存在可控性、闭环仿真真实性及推理效率等挑战。为此,本文引入分摊扩散仿真技术。这一新型扩散去噪范式将去噪计算成本分摊至未来仿真步骤中,显著降低单步推演成本(推理步数减少16倍),同时缓解闭环误差。本文进一步通过广义硬约束(一种高效推理时约束机制)及基于大语言模型(LLM)少样本提示的约束化场景生成提升可控性。模型扩展研究表明,增加计算资源可显著提升整体仿真真实性。在Waymo开放仿真智能体挑战赛(WOSAC)中,本文的方法在开环性能上达到最优,并在扩散模型中取得最佳闭环性能。
算法概览:

主要实验结果:
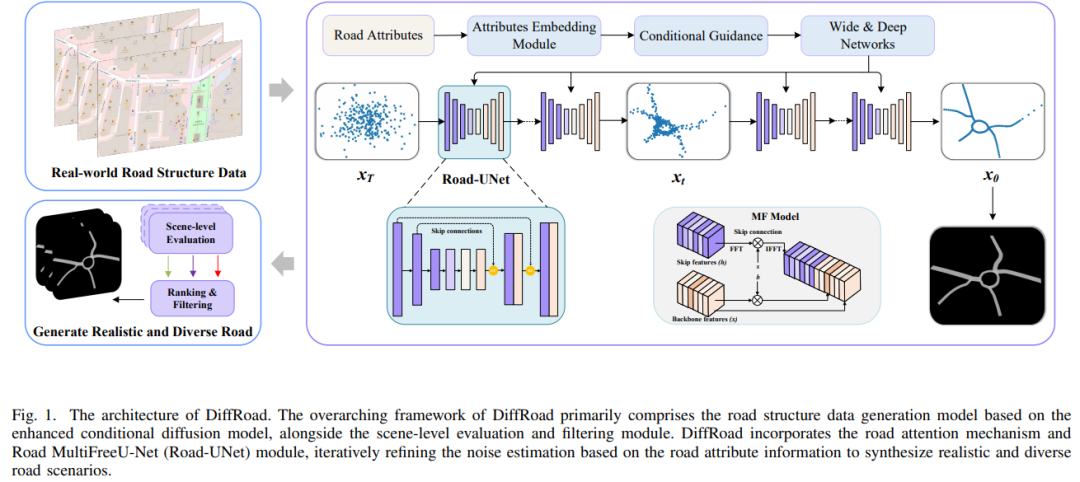
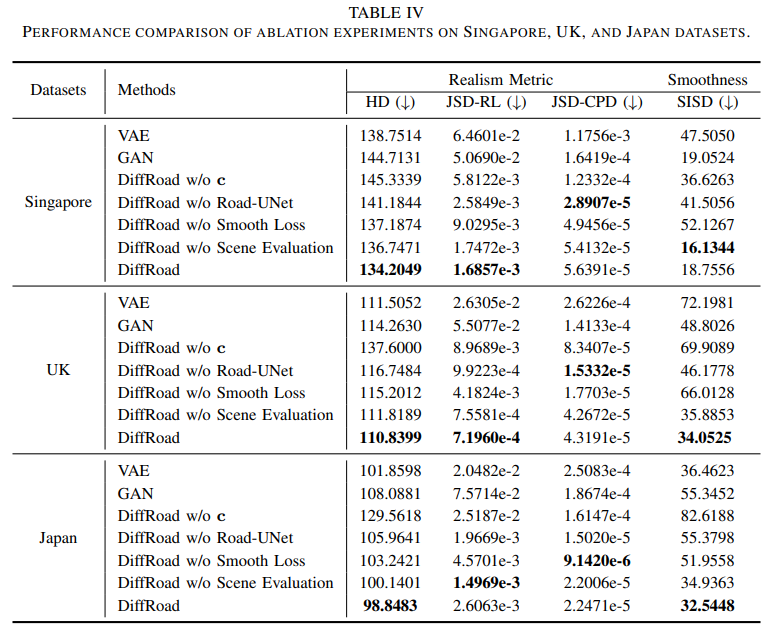
标题:DiffRoad: Realistic and Diverse Road Scenario Generation for Autonomous Vehicle Testing
链接:https://arxiv.org/abs/2411.09451
作者单位:上海交通大学,新加坡国立大学
生成真实且多样化的道路场景对于自动驾驶车辆的测试和验证至关重要。然而,由于真实世界道路环境的复杂性和多变性,为智能驾驶测试创建真实且多样化的场景具有挑战性。本文提出DiffRoad,一种新型扩散模型,旨在生成可控制且高保真的3D道路场景。DiffRoad利用扩散模型的生成能力,通过逆向去噪过程从白噪声中合成道路布局,保留真实世界的空间特征。为提高生成场景的质量,本文设计了Road-UNet架构,优化主干网络和跳跃连接之间的平衡,以实现高真实感的场景生成。此外,本文引入了一个道路场景评估模块,该模块使用两个关键指标——道路连续性和道路合理性——筛选适合智能驾驶测试的充分且合理的场景。在多个真实世界数据集上的实验结果表明,DiffRoad能够生成真实且平滑的道路结构,同时保持原始分布特性。此外,生成的场景可以完全自动化转换为OpenDRIVE格式,便于通用的自动驾驶车辆仿真测试。
算法概览:
主要实验结果:
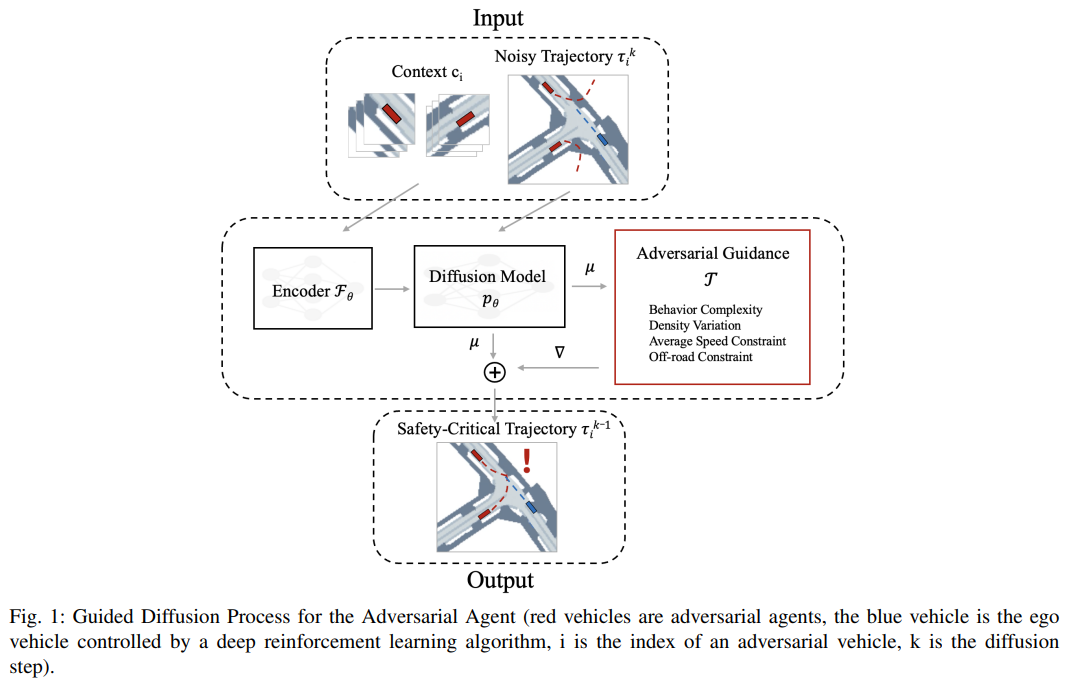
标题:Data-driven Diffusion Models for Enhancing Safety in Autonomous Vehicle Traffic Simulations
链接:https://arxiv.org/abs/2410.04809
作者单位:芬兰阿尔托大学等
安全关键交通场景是自动驾驶系统开发与验证的核心组成部分。这些场景能为车辆在现实世界中罕见的高风险条件下的响应提供关键见解。近年来,在关键场景生成领域的进展表明,与传统生成模型相比,基于扩散模型的方法在有效性和真实性方面具有显著优势。然而,当前基于扩散模型的方法未能充分解决驾驶员行为复杂性和交通密度信息的问题,而这两者均对驾驶员的决策过程有重要影响。在本研究中,本文提出了一种新颖的方法来克服这些局限性,通过为扩散模型引入融合行为复杂性和交通密度的对抗性引导函数,从而增强更有效、更真实的安全关键交通场景的生成。所提方法通过有效性和真实性两个评估指标进行评价,结果表明,与其他最先进的方法相比,该方法具有更优的效能。
算法概览:
主要实验结果:
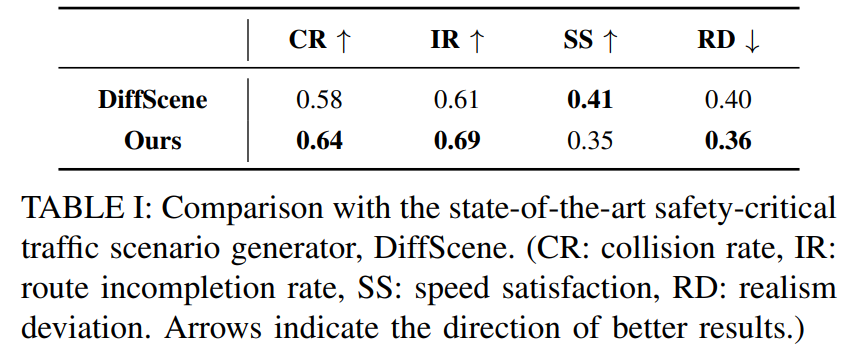
标题:AdvDiffuser: Generating Adversarial Safety-Critical Driving Scenarios via Guided Diffusion
链接:https://ieeexplore.ieee.org/abstract/document/10802408
作者单位:中山大学,武汉大学,中国科学院自动化研究所等
安全关键场景在自然驾驶环境中虽不常见,但对自动驾驶系统的训练与测试至关重要。当前主流方法通过对自然环境引入对抗性调整,在仿真中自动生成安全关键场景。然而,这些调整通常针对特定被测系统设计,缺乏跨系统的可迁移性。本文提出 AdvDiffuser——一种基于引导扩散的对抗性框架,用于生成安全关键驾驶场景。该框架结合扩散模型捕捉背景车辆的合理群体行为,并利用轻量级引导模型有效处理对抗场景,从而提升可迁移性。在 nuScenes 数据集上的实验表明:AdvDiffuser 基于离线驾驶日志训练,仅需极少量预热回合数据即可适配多种被测系统,且在真实性、多样性和对抗性表现上均优于现有方法。
算法概览:
主要实验结果:
标题:DrivingGen: Efficient Safety-Critical Driving Video Generation with Latent Diffusion Models
链接:https://ieeexplore.ieee.org/document/10688119
标题:SLEDGE: Synthesizing Driving Environments with Generative Models and Rule-Based Traffic
链接:https://arxiv.org/abs/2403.17933
项目主页:https://github.com/autonomousvision/sledge
作者单位:图宾根大学
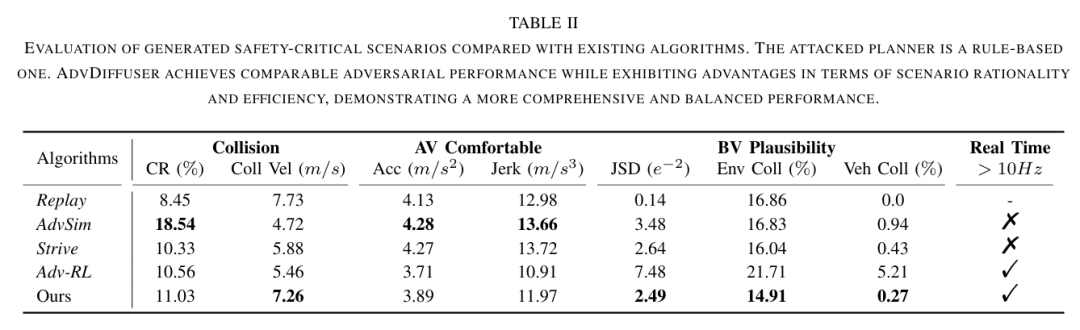
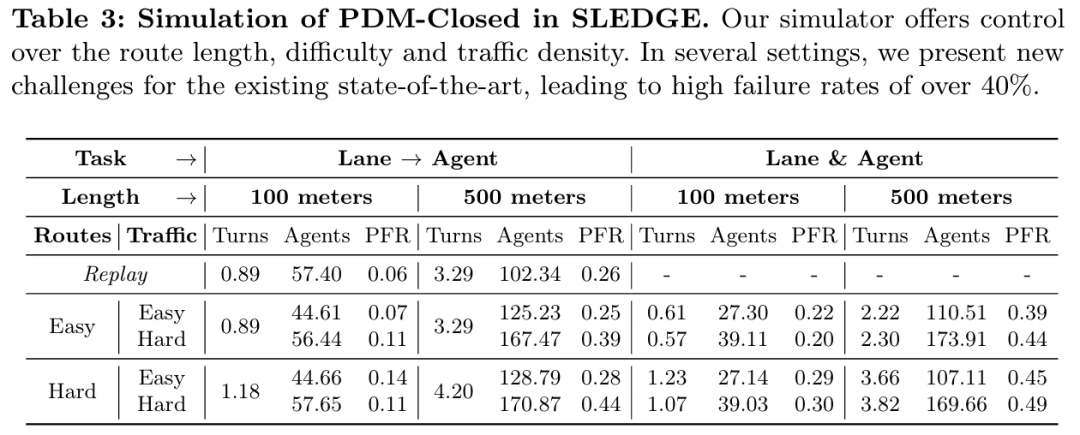
SLEDGE是首个基于真实驾驶日志训练的用于车辆运动规划的生成式仿真器。其核心组件是一个能够生成智能体边界框和车道图的可学习模型。该模型的输出作为基于规则的交通仿真的初始状态。SLEDGE需要生成的实体具有独特的属性,例如它们的连通性和每场景可变的数量,这使得直接应用大多数现代生成模型到此任务上变得非平凡。因此,结合对现有车道图表示的系统研究,本文引入了一种新颖的光栅到矢量的自编码器(raster-to-vector autoencoder)。它将智能体和车道图编码到光栅化潜在地图(rasterized latent map)中的不同通道。这促进了基于车道条件的智能体生成,以及使用扩散Transformer(Diffusion Transformer)联合生成车道和智能体。在SLEDGE中使用生成的实体可以实现对仿真的更大控制,例如对转弯进行上采样或增加交通密度。此外,SLEDGE可以支持500米长的路线,这一能力在现有的数据驱动仿真器(如nuPlan)中是不存在的。它为规划算法提出了新的挑战,当在由本文的模型生成的困难路线和密集交通上进行测试时,2023年nuPlan挑战赛的获胜者PDM的失败率超过40%。与nuPlan相比,SLEDGE的设置所需的存储空间减少了500倍(<4 GB),使其成为一个更易于访问的选择,并有助于推动该领域未来研究的普及化。
算法概览:
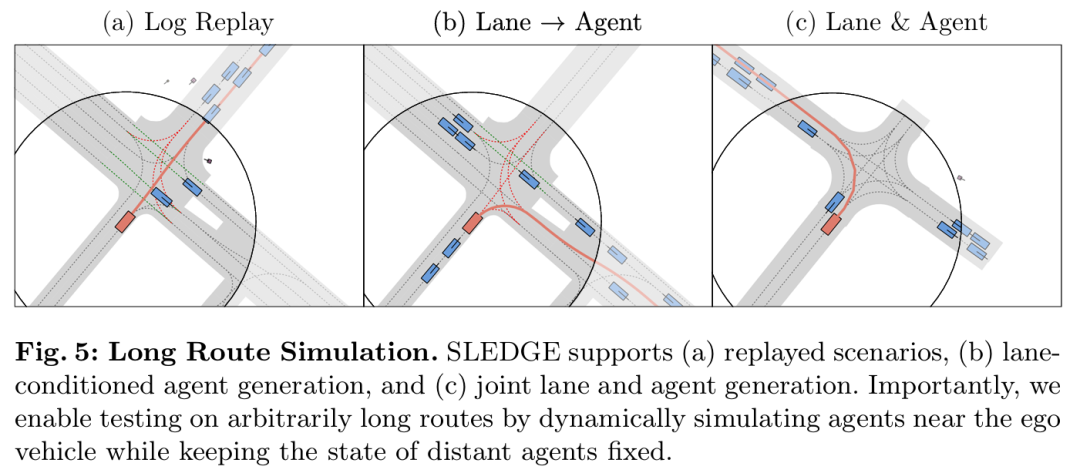
主要实验结果:
标题:SceneControl: Diffusion for Controllable Traffic Scene Generation
链接:https://waabi.ai/scenecontrol/
作者单位:wabbi
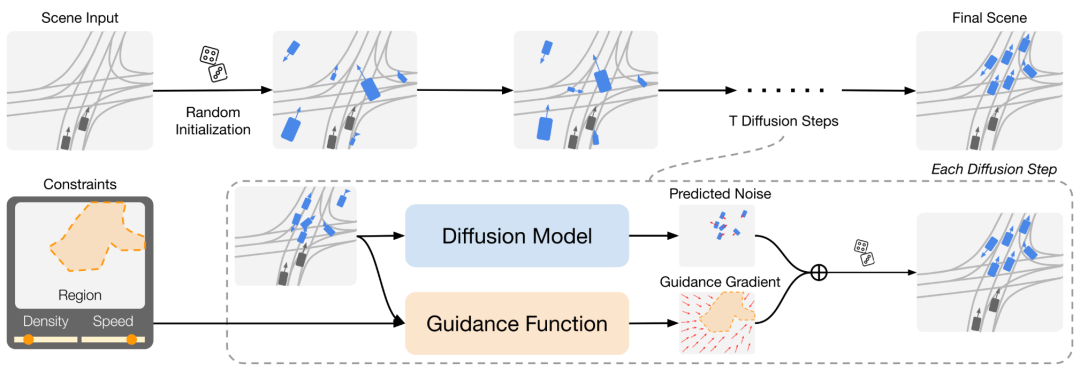
ICRA 2024中稿的工作。我们考虑了交通场景生成的任务。自动驾驶行业的一种常见方法是使用人工创建来生成具有特定特征的场景,并使用自动生成来大规模生成规范场景。然而,人工创建不可扩展,而自动生成通常使用基于规则的算法,这些算法缺乏真实感。在本文中,我们提出了SceneControl,一个用于可控交通场景生成的框架。为了捕捉真实交通的复杂性,SceneControl从数据中学习了一个表现力强的扩散模型。然后,通过引导采样,我们可以灵活地控制采样过程,以生成具有所需特征的场景。我们的实验表明,SceneControl比现有的最先进技术具有更高的真实性和可控性。我们还说明了如何将SceneControl用作交互式交通场景生成的工具。
算法概览:
标题:Versatile Behavior Diffusion for Generalized Traffic Agent Simulation
链接:https://arxiv.org/abs/2404.02524
项目主页:https://sites.google.com/view/versatile-behavior-diffusion
作者单位:南洋理工大学,普林斯顿大学,NVIDIA
现有交通仿真模型往往难以捕捉现实世界场景的复杂性,限制了对自动驾驶系统的有效评估。本文提出了通用行为扩散(VBD)框架,这是一种新颖的交通场景生成框架,它利用扩散生成模型在闭环环境中预测场景一致且可控的多智能体交互。VBD 在 Waymo 仿真智能体基准测试中实现了最先进的性能,能够在多样的环境条件下有效生成具有复杂智能体交互的真实、连贯的交通行为。此外,VBD 通过基于行为先验和模型优化目标的多步细化,支持推理时的场景编辑。这种能力支持可控的多智能体行为生成,可满足各种交通仿真应用中的广泛用户需求。尽管仅在代表典型交通条件的公开数据集上训练,本文引入的冲突先验和博弈论引导方法仍能生成交互式、长尾安全关键场景 —— 这对自动驾驶车辆的全面测试和验证至关重要。最后,本文深入探讨了基于扩散的交通场景生成模型的有效训练和推理策略,强调了最佳实践和常见陷阱。本文的工作显著提升了仿真复杂交通环境的能力,为自动驾驶技术的开发和评估提供了强大工具。
算法概览:
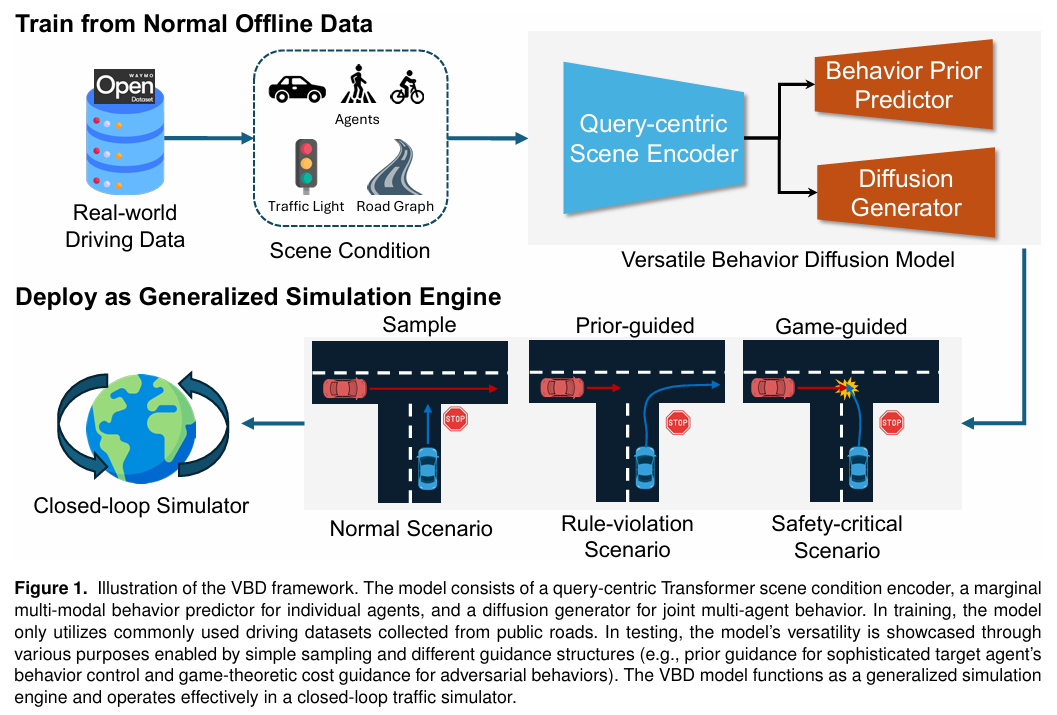
主要实验结果:
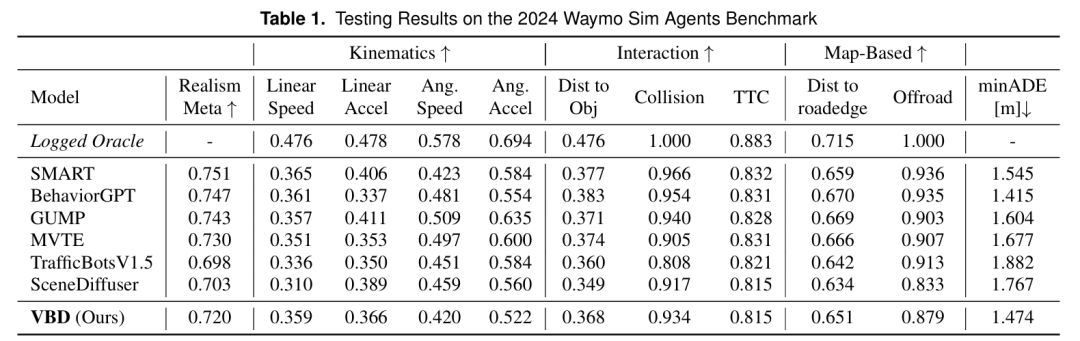
标题:GenDDS: Generating Diverse Driving Video Scenarios with Prompt-to-Video Generative Model
链接:https://arxiv.org/abs/2408.15868
作者单位:哥伦比亚大学
自动驾驶训练需涵盖多样交通状况、天气场景及道路类型的数据集。传统数据增强方法难以生成表征罕见事件的数据。为此,本文提出 GenDDS ——一种基于先进隐扩散模型 Stable Diffusion XL (SDXL) 的驾驶场景生成方法。该方法通过描述性提示(prompt)引导合成过程,生成逼真且多样化的驾驶场景。结合最新计算机视觉技术(如 ControlNet 和 Hotshot-XL),本文构建了完整的视频生成流程,并利用真实驾驶视频数据集 KITTI 训练模型。实验表明,该模型可生成高质量驾驶视频,精准复现真实驾驶场景的复杂性与多变性。本研究为自动驾驶系统提供了先进的训练数据生成方案,并为仿真验证的虚拟环境创建开辟了新途径。
算法概览:
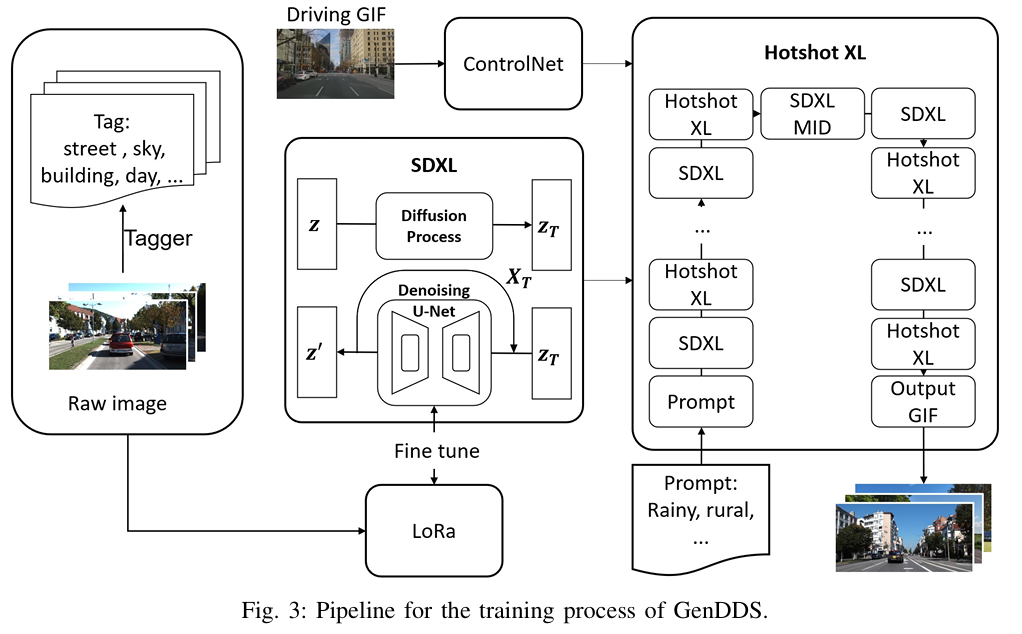
主要实验结果:

标题:GEODIFFUSION: Text-Prompted Geometric Control for Object Detection Data Generation
链接:https://arxiv.org/pdf/2306.04607
项目主页:https://kaichen1998.github.io/projects/geodiffusion/?spm=a2ty_o01.29997173.0.0.1300c921gCBBTX
作者单位:香港科技大学,华为诺亚方舟实验室,南京大学等
扩散模型因其卓越的内容生成能力而在图像分类等任务的数据生成方面引起了广泛关注。然而,利用扩散模型生成高质量的目标检测数据仍然是一个探索不足的领域,在该领域中不仅需要关注图像级的感知质量,还需满足边界框和相机视角等几何条件。
先前的研究主要采用复制粘贴合成方法或具有特定设计模块的布局到图像(L2I)生成方法来编码语义布局。本文提出了GEODIFFUSION,这是一个简单框架,能够灵活地将各种几何条件转换为文本提示,并赋能预训练的文本到图像(T2I)扩散模型进行高质量检测数据生成。
与先前的L2I方法不同,本文的GEODIFFUSION不仅能够编码边界框,还能够编码自动驾驶场景中的额外几何条件(如相机视角)。大量实验表明,GEODIFFUSION在保持训练时间快4倍的同时,性能优于先前的L2I方法。据本文所知,这是首次采用扩散模型进行具有几何条件的布局到图像生成,并证明L2I生成的图像有助于提高目标检测器性能的工作。
算法概览:
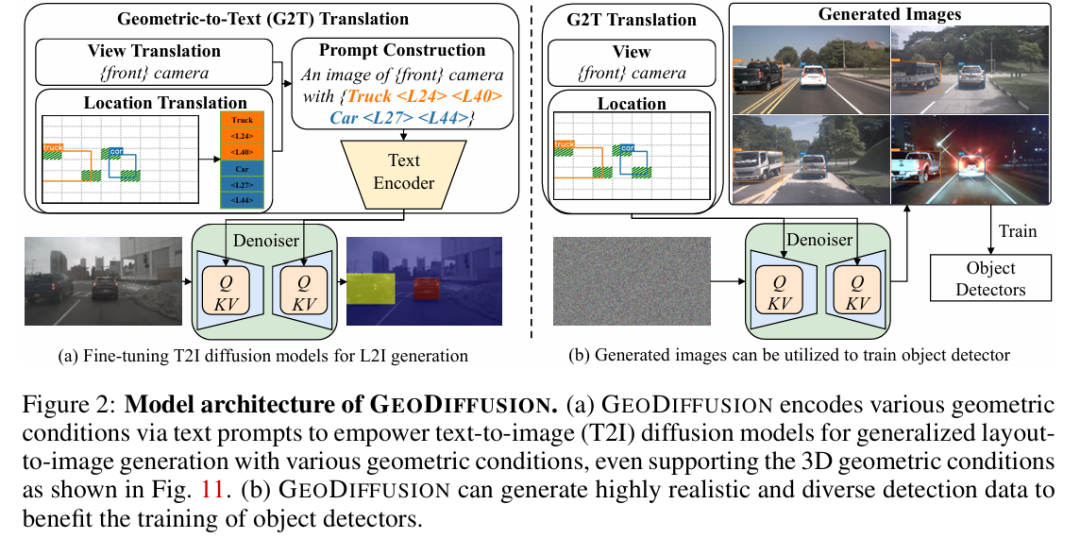
主要实验结果:
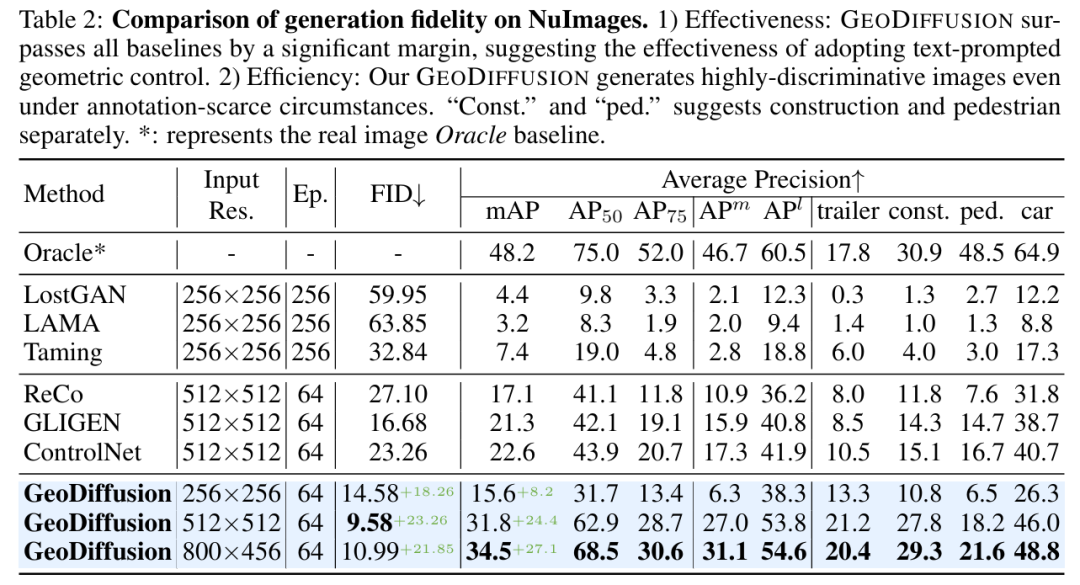
标题:Text2Street: Controllable Text-to-image Generation for Street Views
链接:https://arxiv.org/abs/2402.04504
作者单位:美团
随着扩散模型的兴起,文本到图像生成取得了显著进展。然而,基于文本生成街景图像仍是一项难题,主要挑战源于:1)复杂的道路拓扑(如交叉路口结构、符合交规的车道线数量),2)多样的交通状态(如指定数量的车辆 / 行人及其合规布局),3)多变的天气条件(如雨天、夜间光照)。传统模型因缺乏细粒度控制能力,难以同时满足上述约束(如图 1 所示,微调后的 Stable Diffusion 仍无法准确生成指定车道数和车辆数的场景)。
本文提出Text2Street 框架,通过三阶段实现可控生成:
车道感知道路拓扑生成器:结合计数适配器(Counting Adapter),将文本描述(如 “3 车道”)转化为包含精确道路结构和合规车道线的局部语义地图,解决传统模型因图像遮挡导致的道路信息缺失问题;
基于位置的目标布局生成器:通过目标级边界框扩散策略,在语义地图约束下生成符合交通规则的目标布局(如 “4 车 1 卡车” 的位置和方向),突破传统模型对数量控制的不敏感问题;
多控制图像生成器:融合投影后的道路语义掩码、目标布局和天气文本,通过 ControlNet 和位置编码实现多条件协同控制,最终生成符合交规、数量精准且场景一致的街景图像。
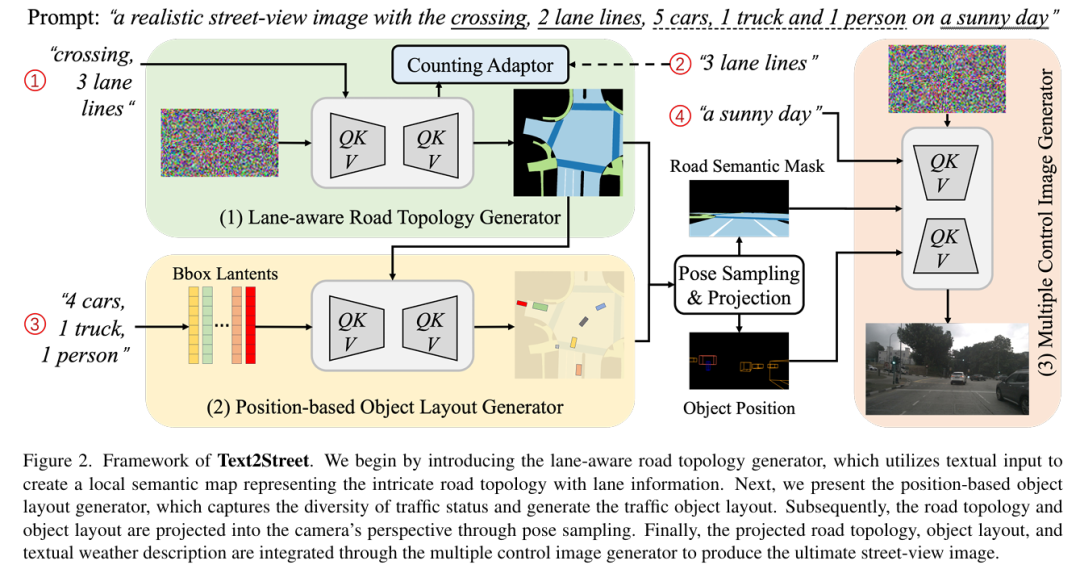
实验表明,Text2Street 在 nuScenes 数据集上显著优于 Stable Diffusion 等模型(车道计数准确率提升 14.91%,目标计数准确率提升 16.5%),验证了其在复杂街景生成中的可控性和有效性。
算法概览:
主要实验结果:
标题:SAFE-SIM: Safety-Critical Closed-Loop Traffic Simulation with Diffusion-Controllable Adversaries
PDF:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/03157-supp.pdf
标题:Panacea: Panoramic and Controllable Video Generation for Autonomous Driving
链接:https://arxiv.org/abs/2311.16813
作者单位:中国科学技术大学,旷视科技等
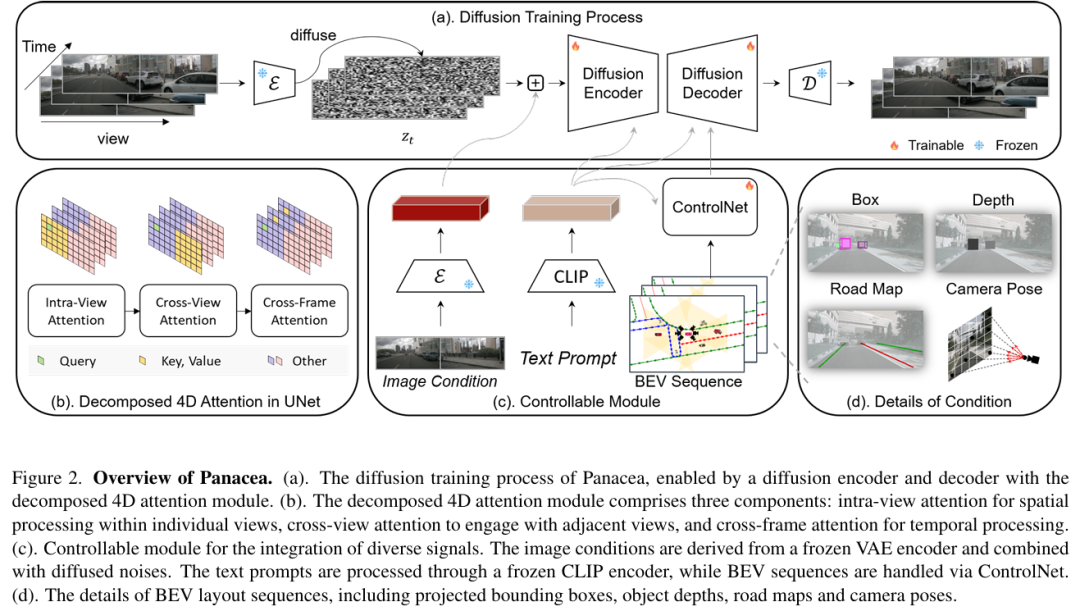
自动驾驶领域对高质量标注训练数据的需求日益增长。本文提出 Panacea——一种创新方法,用于生成驾驶场景中的全景可控视频,可产生无限量多样化的标注样本,对自动驾驶发展至关重要。Panacea 解决了两个核心挑战:
一致性:确保时间连续性与跨视角连贯性;
可控性:保证生成内容与标注(如鸟瞰图布局)精确对齐。
该方法融合了新型 4D 注意力机制 与 两阶段生成流程 以维持一致性,并通过 ControlNet 框架 实现对鸟瞰图(BEV)布局的精细化控制。在 nuScenes 数据集上的定性与定量实验表明,Panacea 能高效生成高质量多视角驾驶场景视频。本工作通过增强 BEV 感知技术的训练数据,显著推动了自动驾驶领域发展。
算法概览:
主要实验结果:
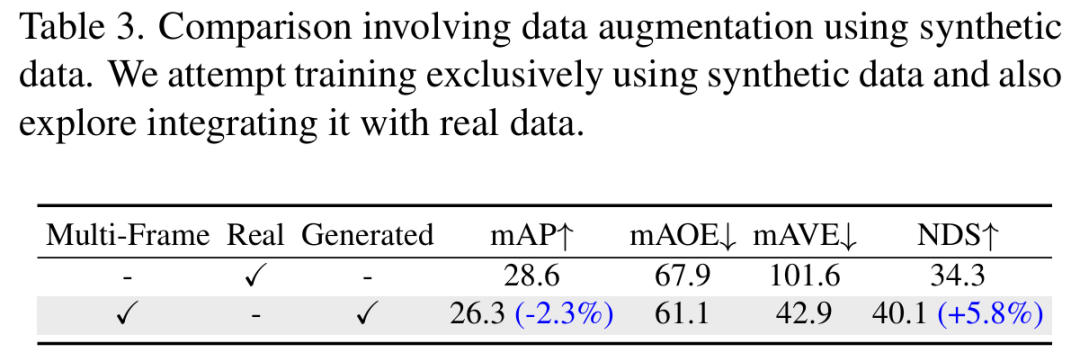
标题:Scenario Diffusion: Controllable Driving Scenario Generation With Diffusion
链接:https://neurips.cc/virtual/2023/poster/72611
作者单位:Zoox
自动生成合成交通场景是验证自动驾驶车辆(AV)安全性的关键环节。在本文中,我们提出了场景扩散(Scenario Diffusion)这一基于扩散的新架构,用于生成交通场景,并实现了场景生成的可控性。我们结合了潜在扩散、目标检测和轨迹回归,以同时生成合成智能体姿态、方向和轨迹的分布。为了对生成的场景进行额外控制,该分布以地图和描述所需场景的标记集为条件。我们证明,我们的方法具有足够的表达能力,能够模拟多种交通模式,并可推广到不同的地理区域。
算法概览:
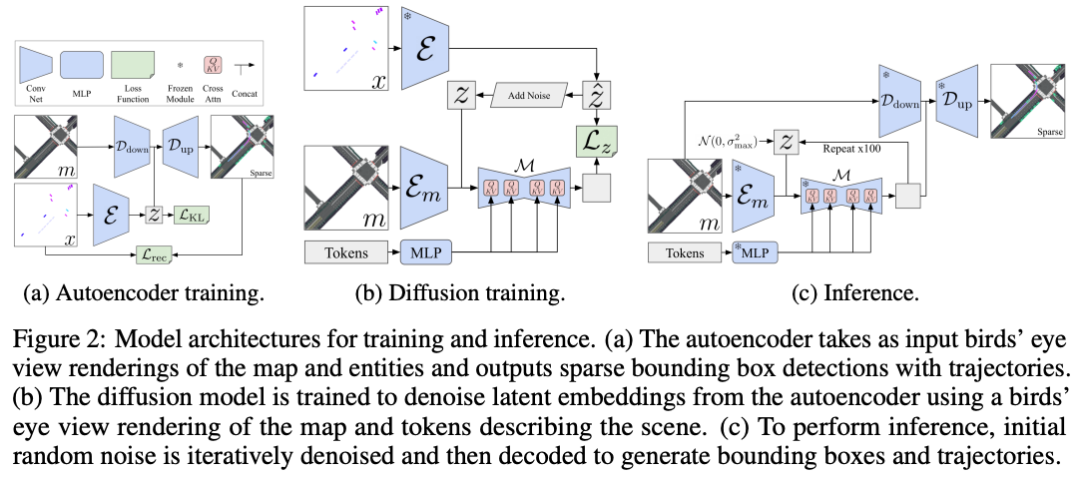
主要实验结果:
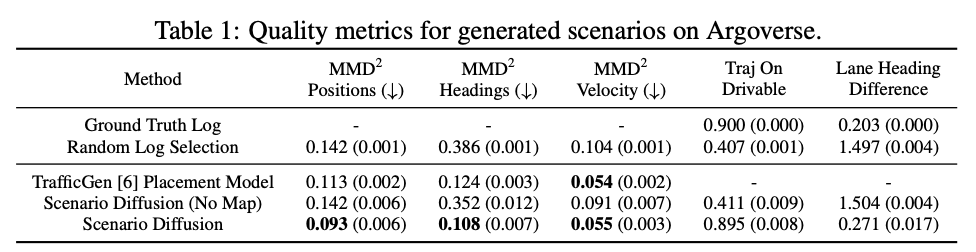
标题:Language-guided traffic simulation via scene-level diffusion
链接:https://research.nvidia.com/labs/avg/publication/zhong.rempe.etal.corl23/
作者单位:英伟达
真实且可控的交通仿真技术是加速自动驾驶车辆(AV)开发的核心能力。然而当前控制基于学习的交通模型的方法需要深厚的领域专业知识,对于从业者而言难以使用。为解决这一问题,我们提出了CTG++,这是一种场景级条件扩散模型,可通过语言指令进行引导。开发这一模型需要应对两大挑战:一是需要一个真实且可控的交通模型主干;二是需要一种有效的方法来使用语言与交通模型进行交互。为应对这些挑战,我们首先提出了一种配备时空Transformer主干的场景级扩散模型,该模型能够生成真实且可控的交通。然后,我们利用大型语言模型(LLM)将用户的查询转换为损失函数,引导扩散模型生成符合查询要求的交通。通过综合评估,我们证明了所提方法在生成真实且符合查询要求的交通仿真方面的有效性。
算法概览:
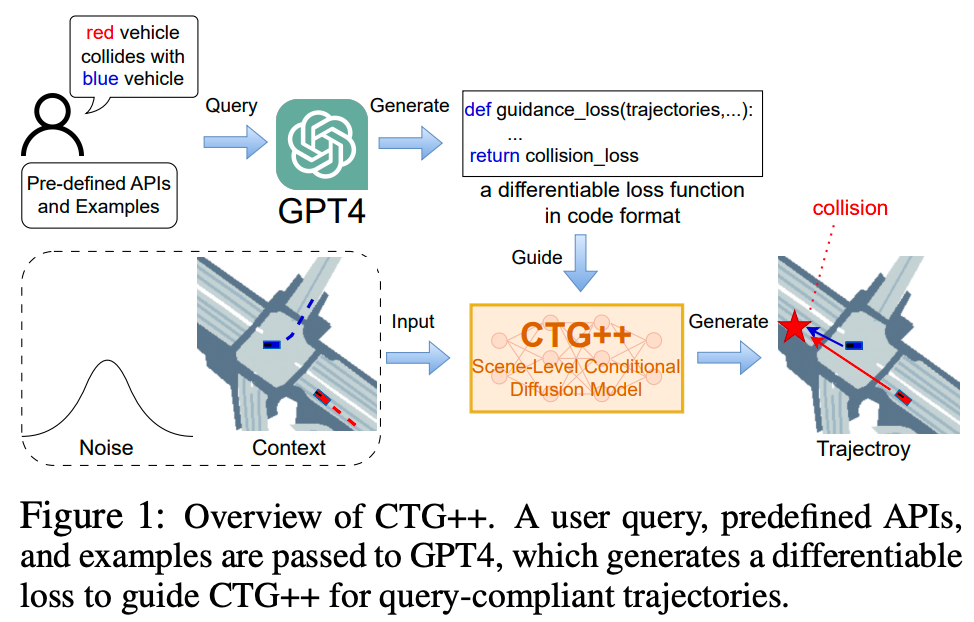
主要实验结果:
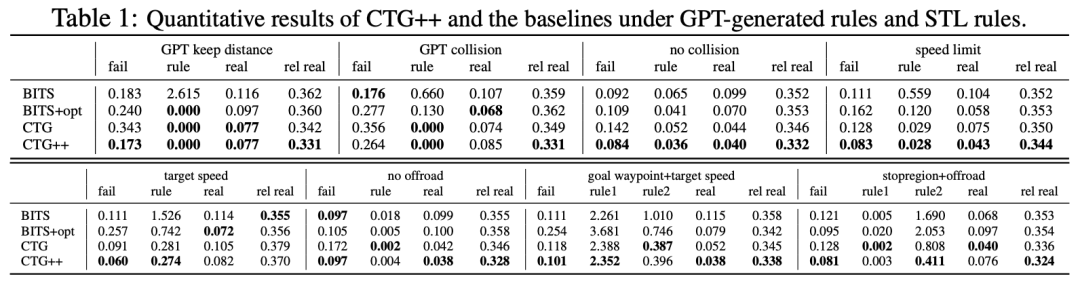
标题:DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
链接:https://arxiv.org/abs/2310.07771
项目主页:https://drivingdiffusion.github.io/
作者单位:百度
随着基于强大且统一的BEV表示的自动驾驶技术日益普及,对高质量、大规模且具有精确标注的多视角视频数据的需求变得尤为迫切。然而,由于采集和标注成本高昂,此类大规模多视角数据难以获取。 为缓解这一问题,本文提出了一种时空一致的扩散框架DrivingDiffusion,用于生成由3D布局控制的真实多视角视频。 在给定3D布局合成多视角视频时存在三个主要挑战:如何保持1)跨视角一致性;2)跨帧(时间)一致性;3)如何保证生成实例的质量?本文的DrivingDiffusion通过级联多视角单帧图像生成步骤、多摄像头共享的单视角视频生成步骤以及可处理长视频生成的后处理步骤来解决这些问题。在多视角模型中,通过相邻摄像头之间的信息交换确保多视角图像的一致性。在时序模型中,本文主要从第一帧的多视角图像中查询后续帧生成所需关注的信息。本文还引入了局部提示(local prompt)来有效提高生成实例的质量。在后处理中,本文通过采用时序滑动窗口算法进一步增强后续帧的跨视角一致性并扩展视频长度。无需额外成本,本文的模型能够在复杂城市场景中生成大规模真实多摄像头驾驶视频,为下游驾驶任务提供支持。
算法概览:
主要实验结果:

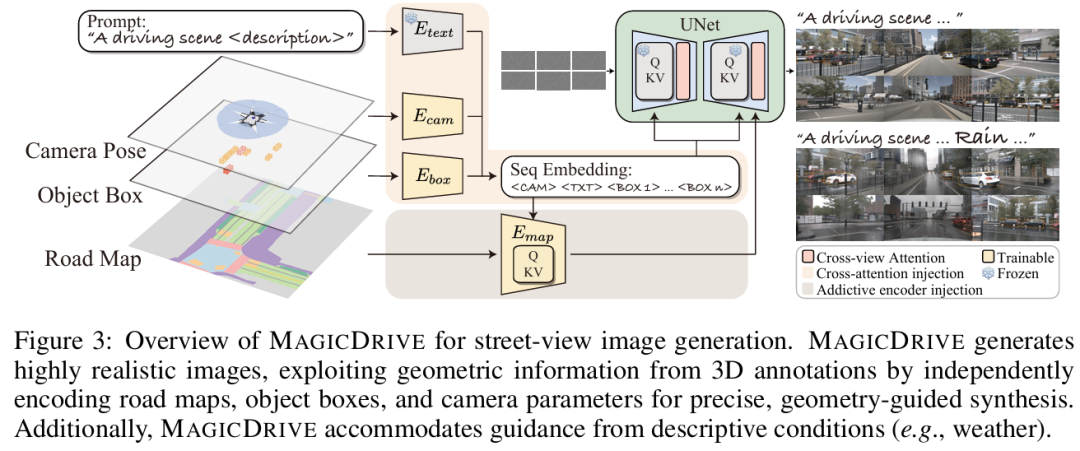
标题:MagicDrive: Street View Generation with Diverse 3D Geometry Control
链接:https://arxiv.org/abs/2310.02601
项目主页:https://flymin.github.io/magicdrive
作者单位:香港中文大学,香港科技大学,华为诺亚方舟实验室
近年来,扩散模型的进步显著提升了 2D 条件下的数据合成能力,但自动驾驶场景中至关重要的3D 几何精确控制(如高度、遮挡、路面高程)仍存在挑战。现有方法依赖鸟瞰图(BEV)作为主要条件,导致几何控制(如高度)失效,影响 3D 感知任务(如 3D 目标检测)的数据质量。
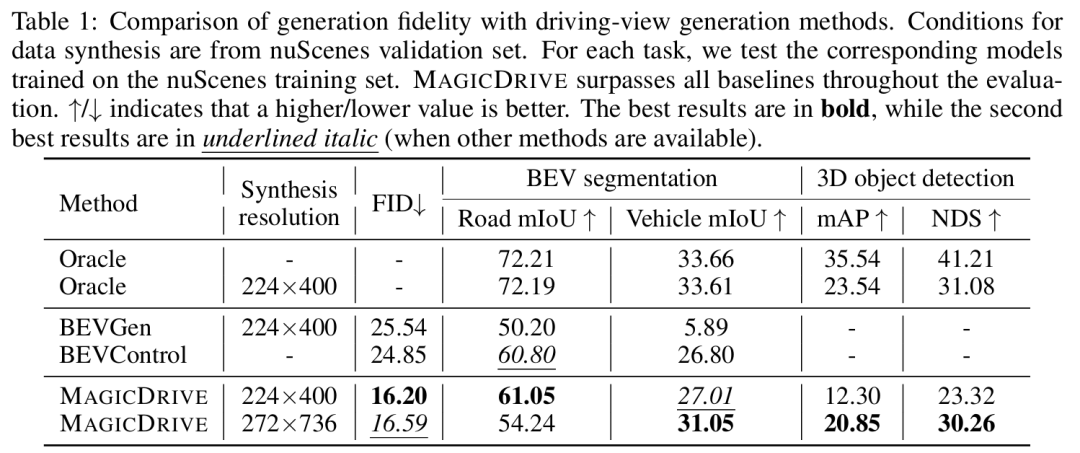
本文提出MAGICDRIVE,一种新型街景生成框架,通过定制化编码策略,融合相机位姿、道路地图、3D 包围盒及文本描述,实现多样化 3D 几何控制。框架设计了跨视图注意力模块,确保多相机视角一致性。实验表明,MAGICDRIVE 能生成高保真街景图像 / 视频,捕捉细微 3D 几何特征(如车辆高度、路面起伏),显著提升 BEV 分割和 3D 目标检测任务性能。与现有方法(如 BEVGen、BEVControl)相比,MAGICDRIVE 通过分离前景(3D 包围盒)与背景(道路地图)编码,避免了 BEV 投影导致的几何信息丢失,同时支持天气、时间等场景属性控制。
算法概览:
主要实验结果:
标题:DriveSceneGen: Generating Diverse and Realistic Driving Scenarios From Scratch
链接:https://arxiv.org/abs/2309.14685
项目主页:https://ss47816.github.io/DriveSceneGen/?spm=a2ty_o01.29997173.0.0.52b1c921UxJtUj
作者单位:新加坡国立大学
大量真实且多样化的交通场景对于自动驾驶系统的开发和验证至关重要。然而,由于数据收集过程中的诸多困难以及对密集标注的依赖,真实世界数据集缺乏足够的数量和多样性来满足日益增长的数据需求。本工作提出了DriveSceneGen,一种数据驱动的驾驶场景生成方法,该方法从真实驾驶数据集学习并从零开始生成完整的动态驾驶场景。DriveSceneGen能够以高保真度和多样性生成与真实世界数据分布一致的新型驾驶场景。在5000个生成场景上的实验结果突显了与真实世界数据集相比的生成质量、多样性和可扩展性。据本文所知,DriveSceneGen是首个从零开始生成包含静态地图元素和动态交通参与者的新型驾驶场景的方法。
算法概览:
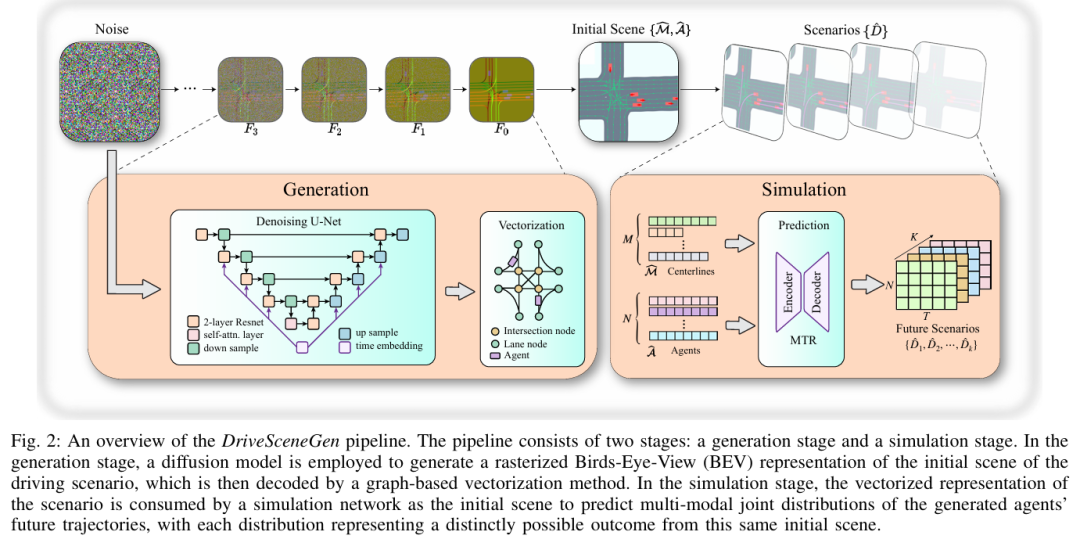
主要实验结果:

标题:BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout
链接:https://arxiv.org/abs/2308.01661
作者单位:天津大学,天津大学,西湖大学等
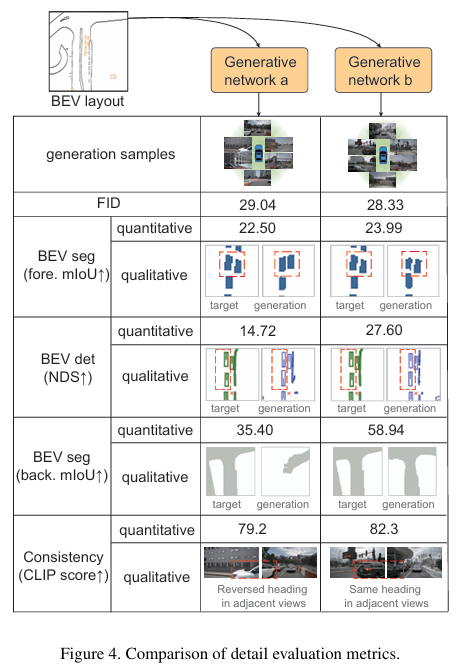
利用合成图像提升感知模型性能是计算机视觉领域的长期挑战。在以视觉为中心的多摄像头自动驾驶系统中,该问题尤为突出,因为某些长尾场景难以通过实际采集获取。现有生成网络在BEV分割布局的引导下,虽在场景级指标下能合成逼真的街景图像,但放大后常无法生成准确的前景(如车辆朝向)和背景细节。为此,本文提出一种两阶段生成方法 BEVControl,可精确控制前景与背景内容。与分割式输入不同,BEVControl支持草图式输入,更便于人工编辑。此外,本文提出一套多层级评估协议,综合衡量生成场景、前景目标及背景几何的质量。大量实验表明:BEVControl在前景分割mIoU上显著超越当前最优方法BEVGen(5.89→26.80);使用其生成图像训练下游感知模型,NDS指标平均提升1.29。
算法概览:
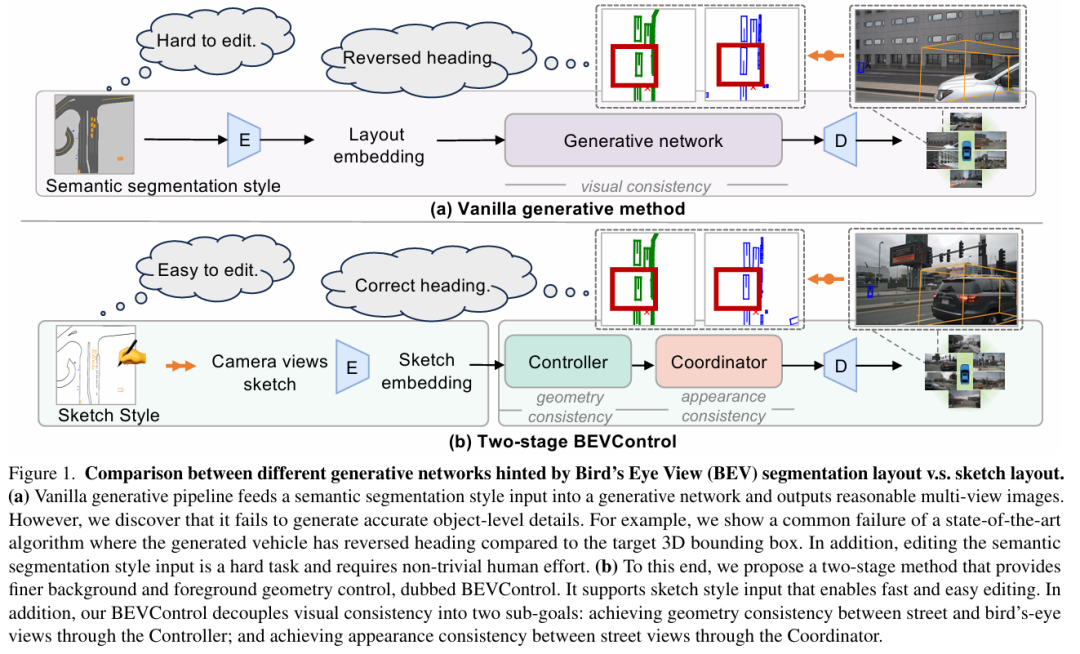
主要实验结果:
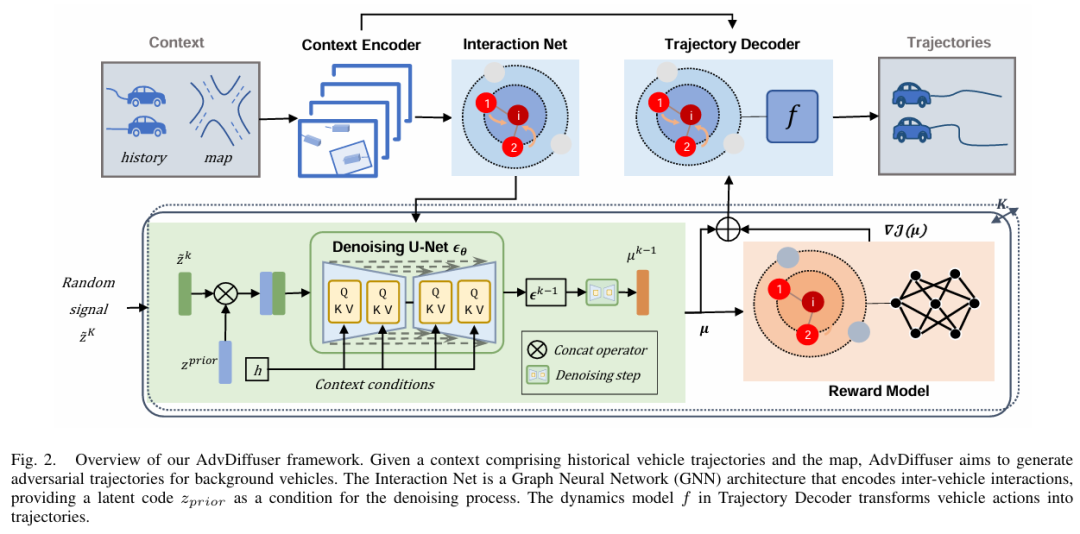
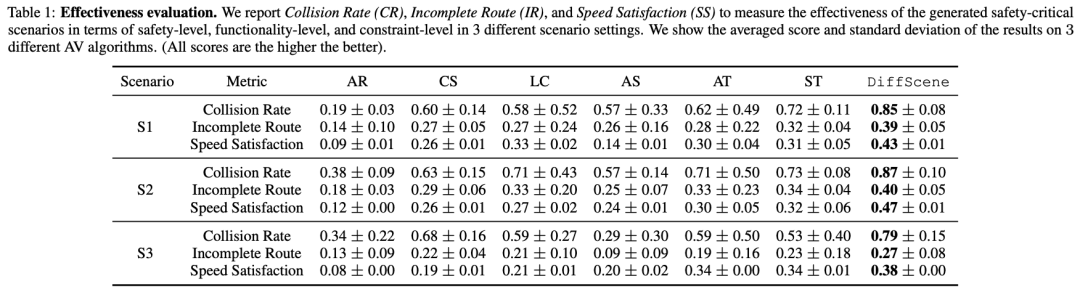
标题:DiffScene: Guided Diffusion Models for Safety-Critical Scenario Generation
链接:https://openreview.net/forum?id=hclEbdHida
作者单位:伊利诺伊大学厄巴纳-香槟分校、CMU等
自动驾驶(AD)领域近年来取得了显著进展。在所面临的各种挑战中,自动驾驶车辆(AV)的安全评估尤为关键。传统评估方法既昂贵又低效,往往需要大量的行驶里程才能遇到罕见的安全关键场景,而这些场景分布在复杂现实世界驾驶场景的长尾区域。在本文中,我们提出了一种统一的方法——基于扩散的安全关键场景生成(DiffScene),用于生成既真实又安全关键的高质量安全关键场景,以实现高效的自动驾驶评估。具体而言,我们提出了一个基于扩散的生成框架,利用扩散模型近似低密度空间分布的能力。我们设计了多个对抗性优化目标,以在预定义的对抗性预算下指导扩散生成。这些目标,如基于安全的目标、基于功能的目标和基于约束的目标,确保在遵守特定约束的同时生成安全关键场景。我们进行了大量实验来验证我们方法的有效性。与6个最先进的基线方法相比,DiffScene生成的场景(1)在3个指标上更具安全关键性,(2)在5个距离函数上更真实,(3)对不同自动驾驶算法更具可转移性。此外,我们还证明了,与基线方法相比,使用DiffScene生成的场景训练自动驾驶算法在安全关键指标方面表现显著提升。这些发现凸显了DiffScene在解决自动驾驶安全评估挑战方面的潜力,为更高效、更有效的自动驾驶开发铺平了道路。
算法概览:
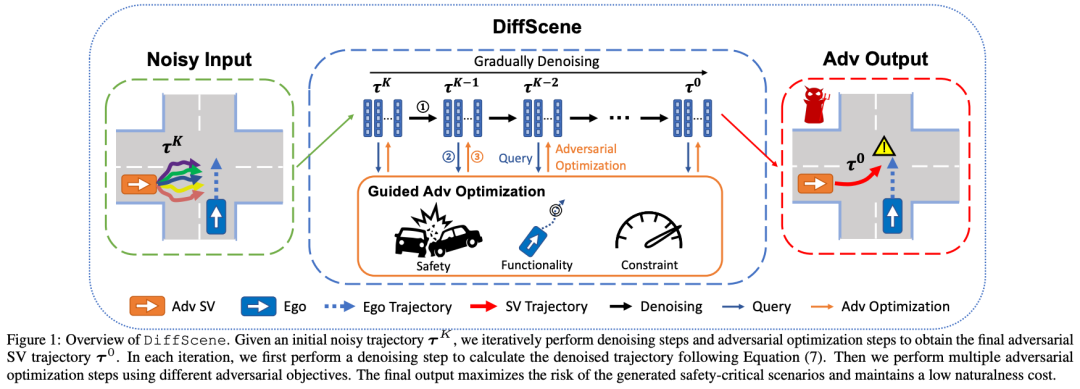
主要实验结果:
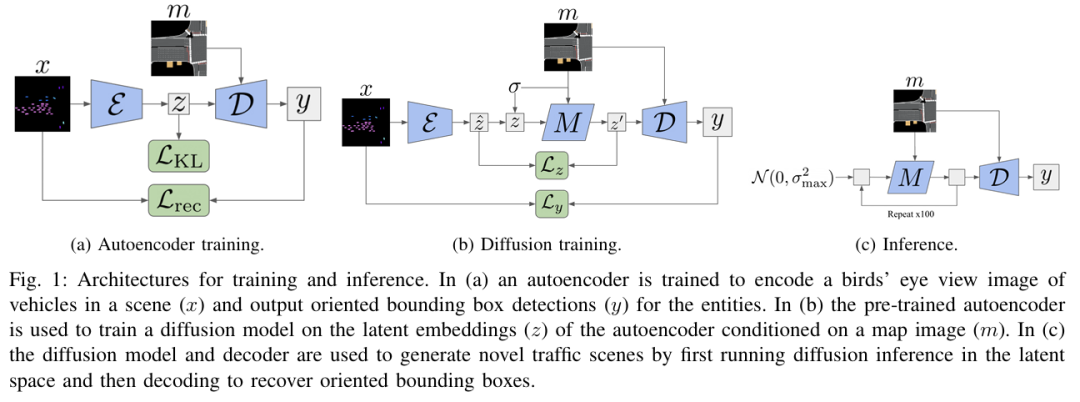
标题:Generating Driving Scenes with Diffusion
链接:https://arxiv.org/abs/2305.18452
作者单位:Zoox,麻省理工学院
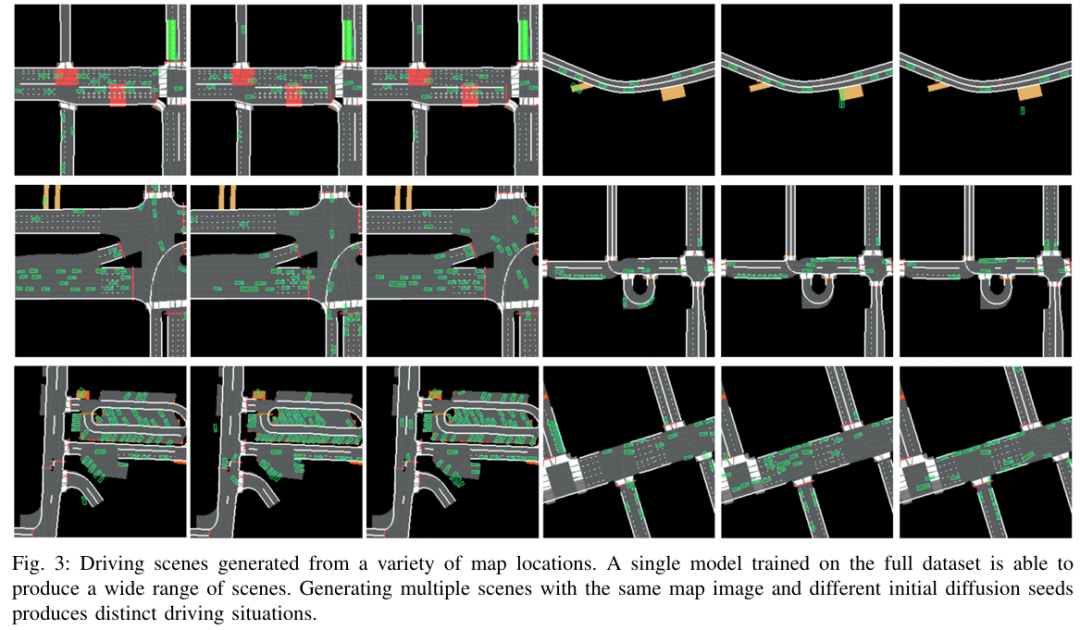
本文提出了一种交通场景生成的习得方法,旨在仿真自动驾驶汽车感知系统的输出。在本文受潜在扩散启发的 “场景扩散”(Scene Diffusion)系统中,本文创新性地结合了扩散模型与目标检测,直接生成具有现实性和物理合理性的智能体离散边界框布局。本文的场景生成模型能够适应美国不同的地区,生成的场景能够捕捉每个地区的复杂特征。
算法概览:
主要实验结果:
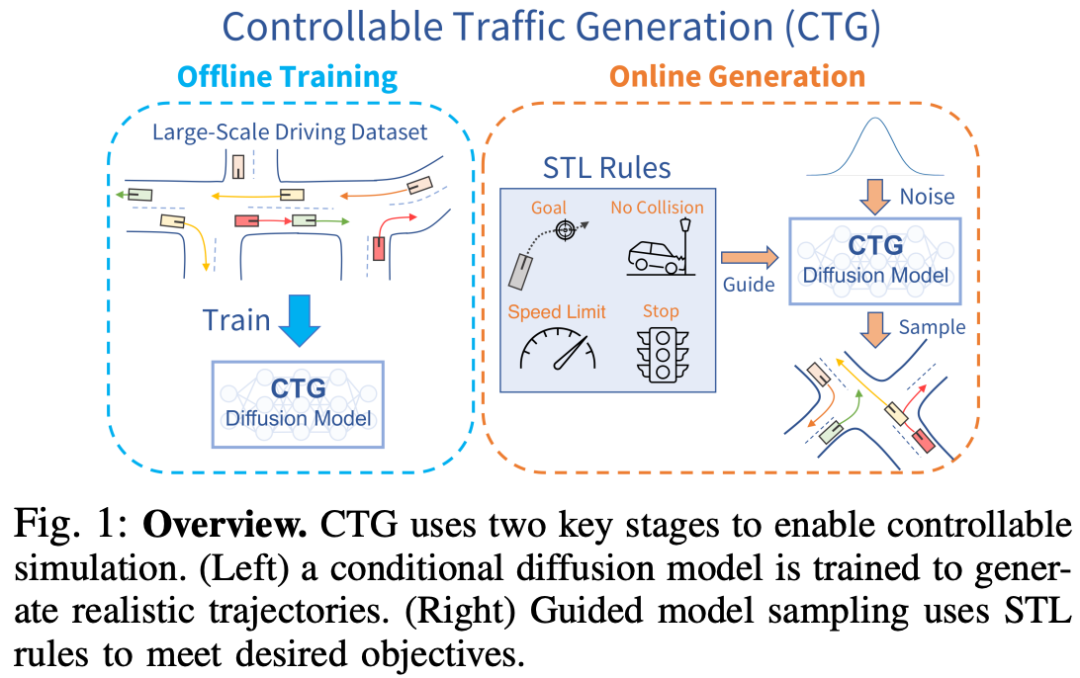
标题:Guided Conditional Diffusion for Controllable Traffic Simulation
链接:https://aiasd.github.io/ctg.github.io/
作者单位:NVIDIA、斯坦福等
ICRA2023中稿的工作!
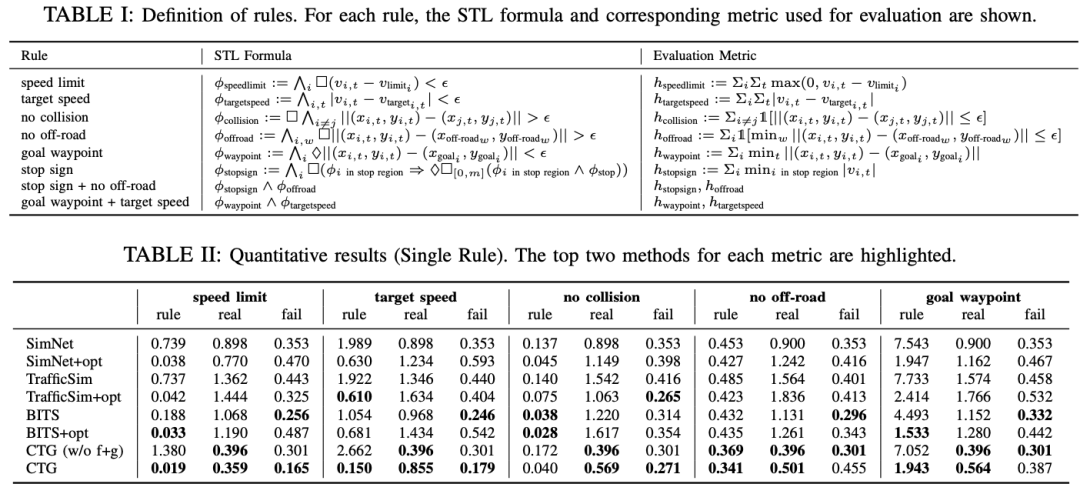
可控且逼真的交通仿真对于开发和验证自动驾驶车辆至关重要。典型的基于启发式的交通模型提供灵活的控制,使车辆能够遵循特定的轨迹和交通规则。另一方面,数据驱动的方法能够生成逼真且类似人类的行为,从而改善从仿真到真实交通的迁移。然而,据我们所知,尚无交通模型同时具备可控性和逼真性。在本文中,我们开发了一种用于可控交通生成(CTG)的条件扩散模型,该模型允许用户在测试时控制轨迹的期望属性(例如,到达目标或遵守限速),同时通过强制动力学保持逼真性和物理可行性。关键技术思想是利用扩散建模和可微逻辑的最新进展,引导生成的轨迹满足使用信号时态逻辑(STL)定义的规则。我们进一步将引导扩展到多智能体设置,并启用基于交互的规则,如避免碰撞。CTG在nuScenes数据集上针对多种复合规则进行了广泛评估,在可控性与逼真性的权衡方面,其表现优于强大的基线模型。
算法概览:
主要实验结果:
星球内部为大家梳理了近40+技术路线,无论你是咨询行业应用、还是要找最新的VLA benchmark、综述和学习入门路线,都能极大缩短检索时间。星球还为大家邀请了数十位自动驾驶领域嘉宾,都是活跃在一线产业界和工业界的大佬(经常出现的顶会和各类访谈中哦)。欢迎随时提问,他们将会为大家答疑解惑。我们是一个认真做内容的社区,一个培养未来领袖的地方。


















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









