



点击下方卡片,关注“自动驾驶之心”公众号
最近有小朋友去投大模型和vla相关的岗位,来咨询峰哥。询问两者有什么差异,vla和端到端有什么区别?这里也和大家做个分享。
首先,所有依赖大模型的方案,都可以叫大模型岗位,包括VLM、VLA这类。自驾领域经常采用qwen这类大模型做微调,适配自驾场景的理解或者预测。关键技术:微调、轻量化、量化、部署等;
其次VLA的概念还有执行(action,vision+language+action=VLA),VLA可以是属于“端到端”这一概念!从数据源到执行。业内目前有两种VLA方案,两阶段:基于大模型+Diffusion(比如理想,信息提取+轨迹输出),单阶段完全基于大模型的方案比如OpenDriveVLA(输出轨迹)。
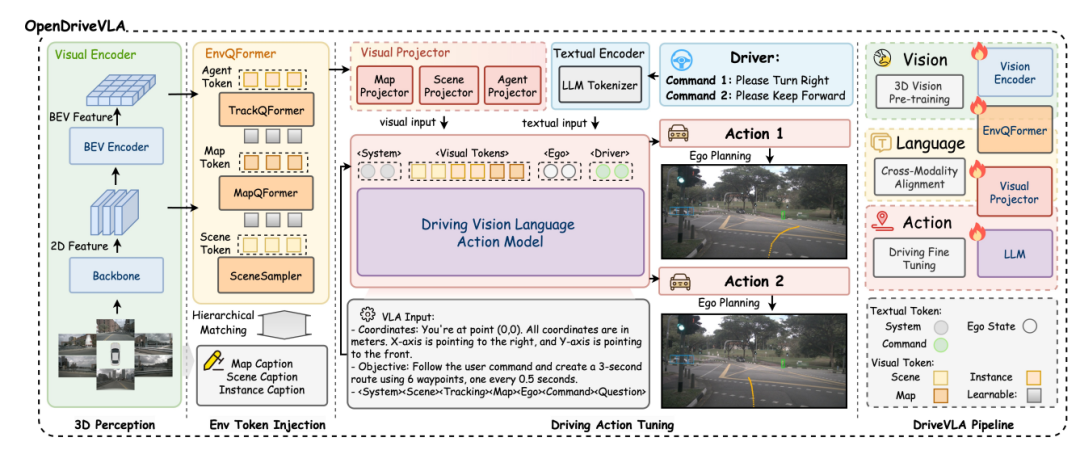
这样描述我想大家应该都能理解了,对应岗位的技术基本围绕大模型、diffusion还有数据生成等,是一个值得投入的研发方向。自动驾驶之心也为大家推荐一些岗位,希望有一定经验的大佬投递。详细公司与级别欢迎底部咨询我们!!!!
1)大模型研发工程师
base:深圳/上海;
待遇:30k-80k/月
岗位描述:
熟悉多模态大语言模型,基于现有的大模型进行微调,优化模型在垂直业务场景(自动驾驶、机器人中的reasoning/knowledge)的性能。
深度参与视觉大模型VLM、VLA等前沿方向在自动驾驶中的应用,包含不仅限于数据pipeline搭建、模型微调、模型性能评估,探索数据配比、数据合成相关的前沿技术。
岗位要求:
熟悉Transformer、图文多模态、LLM、大模型预训练方法,并且有相关模型训练实际经验;
在CVPR/ICCV/ECCV/NeurPS/ICLR/ACL/EMNLP等学术顶会有相关论文发表,或在相关国际竞赛中取得优异成绩者优先。
有ACM/IOI/NOI/Top Coder等算法竞赛获奖经历优先。
2)端到端/VLA工程师
base:深圳/上海
待遇:30k-80k/月
职位描述:
End-to-end driving system研发与落地,负责端到端/VLA模型结构搭建与调优,高质量大规模训练数据集构建,设计路径规划评估,闭环评测系统研发。持续关注并跟踪自动驾驶及人工智能领域的最新技术进展,进行新技术的调研和探索。
职位要求:
计算机视觉基础扎实,熟悉主流技术路线,熟练使用pytorch等训练框架;
有轨迹预测相关研究经验的优先;
有LLM/MLLM/VLM研发经验的优先;
在CVPR/ICCV/ECCV/NeurPS/ICLR/ACL/EMNLP等学术顶会有相关论文发表,或在相关国际竞赛中取得优异成绩者优先。
有ACM/IOI/NOI/Top Coder等算法竞赛获奖经历优先。
3)VLA/VLM大模型算法
base:北京/上海/杭州
待遇:40k-100k/月
岗位职责:
负责自动驾驶领域VLA/VLM核心算法研发,推动视觉-语言-驾驶行为的多模态决策系统落地
设计端到端驾驶策略学习框架,融合模仿学习、强化学习等技术优化驾驶决策生成
开发基于多模态大模型的场景理解与行为预测系统,支持复杂交通场景的认知与推理
探索大模型(LLM/VLM)、生成式模型(Diffusion Policy)在自动驾驶的创新应用
协同感知、预测、控制模块团队,实现算法在量产系统的工程化部署
岗位要求:
硕士及以上学历,计算机/人工智能相关专业,3-5年自动驾驶或AI算法经验
精通VLA/VLM架构,具备多模态大模型(Transformer-based)训练调优经验,熟悉PyTorch/DeepSpeed/FSDP框架
熟悉自动驾驶技术栈(轨迹预测、决策规划),有模仿学习/强化学习项目落地经验
具备以下至少两项能力:
1)千亿参数级大模型训练与优化
2)驾驶场景生成式模型(Diffusion/LLM)开发
3)多模态数据挖掘与驾驶策略预训练
4)世界模型与仿真场景构建
熟悉主流自动驾驶数据集(如nuScenes/Waymo),有量产项目经验者优先
顶会论文(CVPR/ICCV/CoRL等)或专利成果者优先
欢迎咨询
更多信息,欢迎添加小助理微信:Remix-clover做进一步咨询!



















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









