



作者 | IPIU智能感知与图像理解
点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
近日,第20届ICCV国际计算机视觉大会(The 20th IEEE/CVF International Conference on Computer Vision (ICCV 2025))公布了论文接收结果,实验室共有10篇论文被ICCV 2025录用,第一作者分别是何佩博士(导师:焦李成教授),吴兆阳博士生(导师:刘芳教授),缑雪健硕士生(导师:刘芳教授),王鑫硕士生(导师:缑水平教授),闵聿宽博士生(导师:邓成教授),朱宜航博士生(导师:邓成教授),慕晨宇硕士生(导师:邓成教授,杨二昆副教授),石光辉博士生(导师:梁雪峰教授),杜瑞琦博士生(导师:唐旭教授)及冯明涛副教授。论文简要介绍如下:
01
论文1
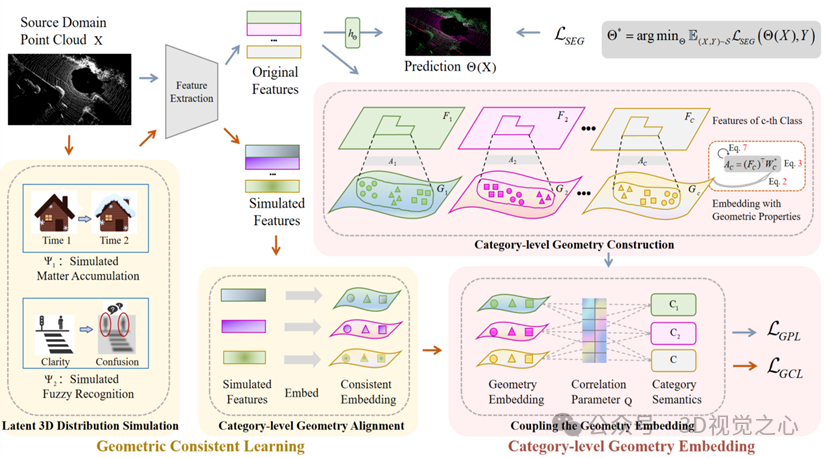
论文题目:Domain-aware Category-level Geometry Learning Segmentation for 3D Point Clouds
论文作者:何佩,李玲玲,焦李成,尚荣华,刘芳,王爽,刘旭,马文萍
作者单位:西安电子科技大学
论文概述:三维场景分割中的域泛化是将模型部署到未知环境的关键挑战。当前的方法通过增强点云的数据分布来缓解领域偏移。然而,模型学习点云中的全局几何模式,忽略了类别级的分布和对齐。本文提出了一个类别级几何学习框架,用于探索领域不变的几何特征,以实现域泛化的三维语义分割。具体而言,提出类别级几何嵌入感知点云特征的细粒度几何属性,构建每个类别的几何属性,并将几何嵌入与语义学习耦合。其次,提出几何一致性学习模拟潜在的三维分布并对齐类别级几何嵌入,使模型关注几何不变信息,从而提高泛化能力。实验结果验证了所提出方法的有效性,与现有的域泛化三维场景分割方法相比,该方法具有竞争力的分割精度。
02
论文2
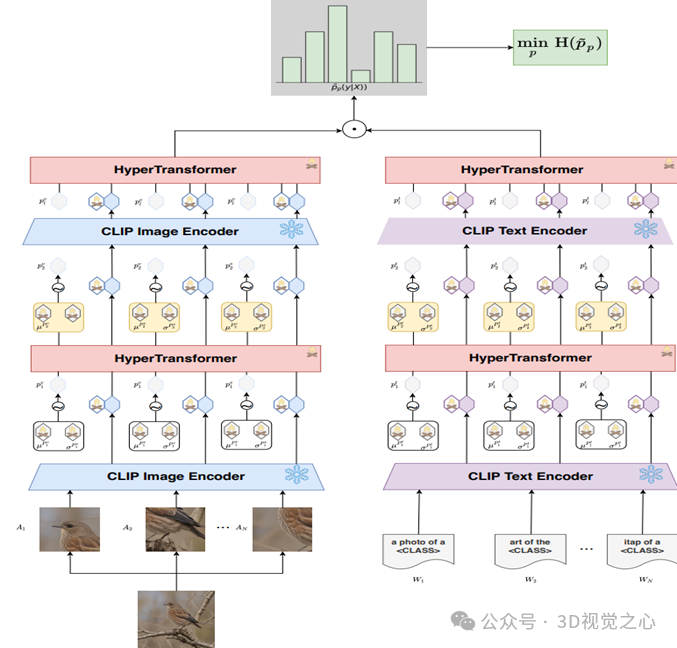
论文题目:Hierarchical Variational Test-Time Prompt Generation for Zero-Shot Generalization
论文作者:吴兆阳,刘芳,焦李成,李硕,李玲玲,刘旭,陈璞华,马文萍
作者单位:西安电子科技大学
论文概述:现有的如 CLIP 这样的视觉语言模型已经展现出强大的零样本泛化能力,这使得它们能够通过提示学习在各种下游任务中发挥作用。然而,现有的测试时提示调整方法(例如熵最小化)将文本和视觉提示视为固定的可学习参数,限制了它们对未知领域的适应性。为此,我们提出了分层变分测试时提示生成方法,其中文本和视觉提示均通过 Hyper Transformer 在推理时动态生成。这使得模型能够为每种模态生成特定于数据的提示,从而显著提升泛化能力。为了进一步解决模板敏感性和分布偏移问题,我们引入了变分提示生成方法,利用变分推理来减轻不同提示模板和数据增强引入的偏差。此外,我们的分层变分提示生成方法在每一层上都对来自前一层的提示进行条件提示,从而使模型能够捕捉更深层次的上下文依赖关系,并优化提示交互以实现稳健的自适应。在领域泛化基准上进行的大量实验表明,我们的方法明显优于现有的即时学习技术,在保持效率的同时实现了最先进的零样本准确率。
03
论文3
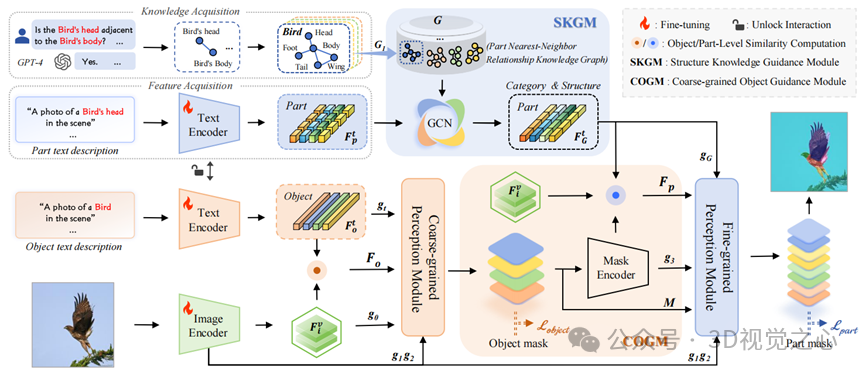
论文题目:Knowledge-Guided Part Segmentation
论文作者:缑雪健,刘芳,焦李成,李硕,李玲玲,王浩,刘旭,陈璞花,马文萍
作者单位:西安电子科技大学
论文概述:在现实世界中,物体及其各个组成部分不仅存在明显的整体差异,还具有复杂而精细的结构关系。如何让计算机像人类一样理解和分割这些细粒度的部件,是计算机视觉领域的重要挑战。传统的语义分割方法大多关注于物体整体的粗粒度信息,能够较好地区分大范围的物体区域,但在需要识别和分割物体内部具体部件时,常常表现出不足。现有方法往往将每个部件视为独立的类别,忽视了部件之间的结构性联系以及与物体整体的关系,导致对复杂结构的理解不够深入,无法满足实际应用中对精细识别的需求。
针对这一问题,我们提出了一种知识引导的部件分割(KPS)新框架。该方法的核心思想是:像人类认知一样,先整体把握物体类别,再深入分析其内部各部件之间的结构关系。具体来说,我们首先利用大语言模型自动抽取物体部件之间的结构知识,并将这些关系构建成知识图谱。然后,通过结构知识引导模块,将知识图谱中的结构信息嵌入到分割模型的特征表达中,从而为部件分割提供结构性指导。同时,我们还设计了粗粒度物体引导模块,用于捕捉和利用物体层面的整体区分特征,进一步增强分割模型对不同物体类别的感知能力。通过将结构性知识与视觉特征有机结合,我们的方法能够更好地理解部件之间的关联和物体的整体特征,在复杂场景下实现更加准确和细致的部件分割。
04
论文4
论文题目:TopicGeo: An Efficient Unified Framework for Geolocation
论文作者:王鑫,王新林,缑水平
作者单位:西安电子科技大学
论文概述:在小尺度的查询图像与大量大尺度的地理参考图像之间建立空间对应关系的视觉地理定位技术已受到广泛关注。现有方法通常采用“先检索再匹配”的分离范式,但该范式存在计算效率低或精度受限的问题。为此,我们提出了一个统一的检索匹配框架TopicGeo,通过三项关键创新实现查询图像与参考图像的直接且精确匹配。首先我们将通过CLIP提示学习和语义蒸馏提取的文本对象语义(称为Topic即主题)嵌入地理定位框架,以消除多时相遥感图像中类内与类间的分布差异,同时提升处理效率。然后基于中心自适应标签分配与离群点剔除机制作为联合“检索-匹配”优化策略,确保了任务一致的特征学习与精确的空间对应关系。我们还引入了多层次的精细匹配流程,以进一步提升匹配的质量和数量。在大规模的合成与真实数据集上的评估表明,TopicGeo在检索召回率和匹配精度方面均具有较好的性能,同时保持了良好的计算效率。
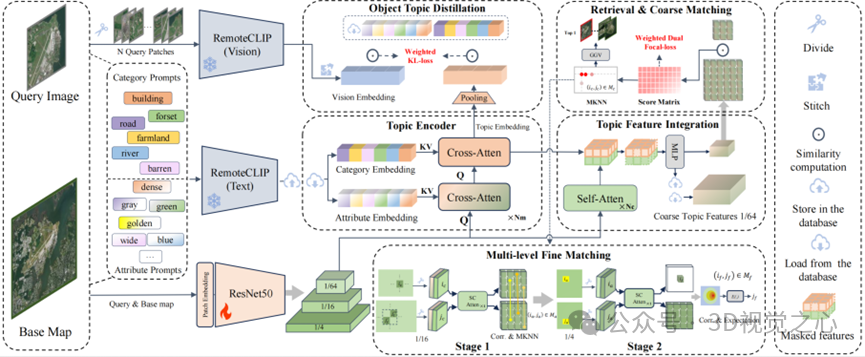
05
论文5
论文题目:Vision-Language Interactive Relation Mining for Open-Vocabulary Scene Graph Generation
论文作者:闵聿宽,杨木李,张瑾皓,王宇宣, 武阿明,邓成
作者单位:西安电子科技大学
论文概述:为了促进场景理解在现实世界中的应用,开放词汇场景图生成(OV-SGG)近年来备受关注,旨在突破训练过程中标注的有限关系类别的限制,并在推理过程中发现那些未知的关系。针对开放词汇场景图生成,一个可行的解决方案是利用包含丰富类别级内容的大规模预训练视觉语言模型(VLM)来捕捉图像与文本之间的精确对应关系。然而,由于VLM缺乏二次关系感知知识,直接使用基础数据集中的类别级对应关系无法充分表征开放世界中的广义关系。因此,设计一个有效的开放词汇关系挖掘框架极具挑战性且意义重大。为此,我们提出了一种基于OV-SGG的视觉语言交互关系挖掘模型(VL-IRM),该模型探索通过多模态交互学习广义关系感知知识。具体来说,首先,为了增强关系文本与视觉内容的泛化能力,我们提出了一个关系生成模型,使文本模态能够探索基于视觉内容的开放式关系。然后,我们利用视觉模态引导关系文本进行空间和语义扩展。该方法成功地将现有VLM应用于场景图生成任务,并适应广泛的关系类别。在多个数据集上的实验表明,我们的方法具有较好的性能和实际应用价值。
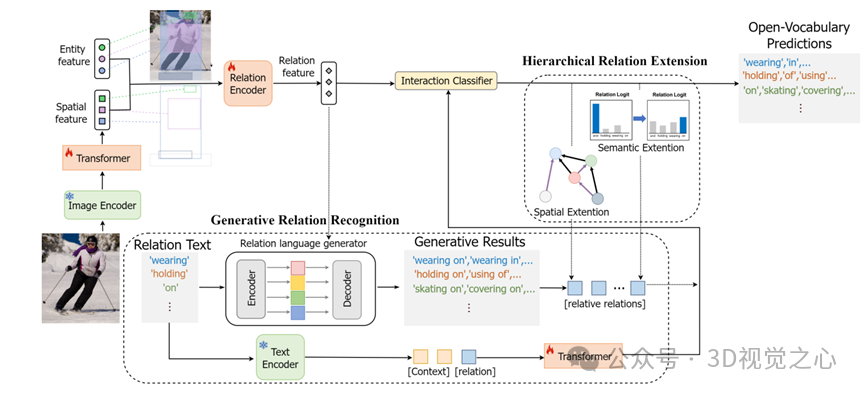
06
论文6
论文题目:VGMamba: Attribute-to-Location Clue Reasoning for Quantity-Agnostic 3D Visual Grounding
论文作者:朱宜航,张瑾皓,王宇宣,武阿明,邓成
作者单位:西安电子科技大学
论文概述:作为具身智能的重要方向,三维视觉定位任务近年来广受关注,其旨在识别与给定语言描述相匹配的三维物体。现有大多数方法采用两阶段流程,即先生成候选物体框,然后再根据与语言查询的相关性筛选出目标物体。然而,当查询语义复杂时,仅凭抽象的语言特征难以精准定位对应物体,导致定位性能下降。通常,人类在定位特定物体时,往往会综合利用物体属性和空间位置信息两类线索。受此启发,本文提出一种新颖的属性到位置线索推理机制,以提升三维视觉定位任务的精度。具体来说,我们设计了 VGMamba 网络,其由基于奇异值分解的属性 Mamba、位置 Mamba 以及多模态融合 Mamba 三部分组成。该网络以三维点云场景与语言查询为输入,首先对提取到的特征进行 SVD 分解,然后通过滑动窗口操作捕获物体的属性特征;接着利用位置 Mamba 提取空间位置信息;最后通过多模态 Mamba 实现特征融合,精准定位与查询描述相符的目标物体。在多个公开数据集上的实验证明,我们的方法具有较好的性能和实际应用价值。
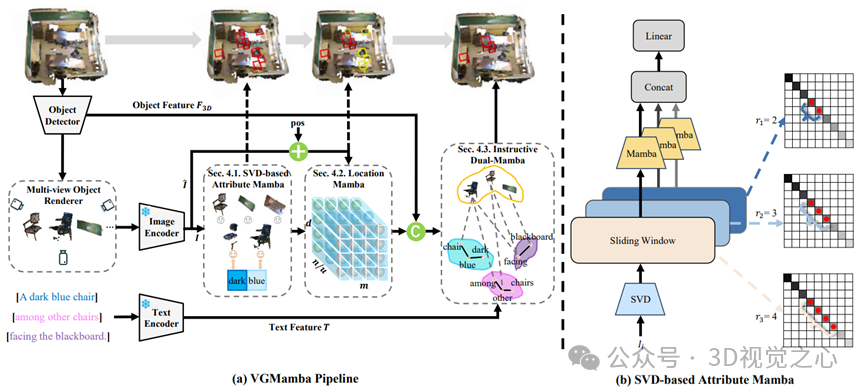
07
论文7
论文题目:Meta-Learning Dynamic Center Distance: Hard Sample Mining for Learning with Noisy Labels
论文作者:慕晨宇,瞿依俊,闫杰熹,杨二昆,邓成
作者单位:西安电子科技大学
论文概述:样本选择方法是一种广泛采用的带有噪声标签的学习策略,其中损失较小的样本在训练过程中被有效地视为干净的。然而,这个干净的集合经常被简单的例子所主导,限制了模型对更具挑战性的案例的有意义的暴露,并降低了它的表达能力。为了克服这一限制,我们引入了一种称为动态中心距离(DCD)的新度量,它可以量化样本难度,并提供关键补充损失值的信息。与依赖于预测的方法不同,DCD是在特征空间中作为样本特征和动态更新中心之间的距离计算的,通过提出的元学习框架建立。在捕获基本数据模式的初步半监督训练的基础上,我们结合DCD来进一步细化分类损失,降低分类良好的示例的权重,并战略性地将训练集中在一组稀疏的硬实例上。这种策略防止简单的例子支配分类器,从而导致更健壮的学习。跨多个基准数据集的广泛实验,包括合成和真实世界的噪声设置,以及自然和医学图像,一致地证明了我们的方法的有效性。
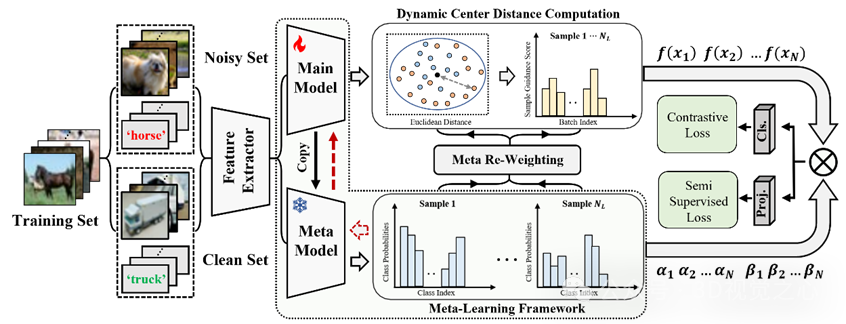
08
论文8
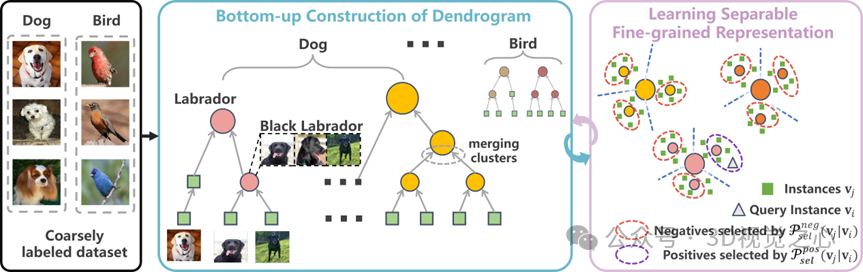
论文题目:Learning Separable Fine-Grained Representation via Dendrogram Construction from Coarse Labels for Fine-grained Visual Recognition
论文作者:石光辉,梁雪峰,李文杰,林笑宇
作者单位:西安电子科技大学
论文概述:在生物多样性监测、物种保护等关键领域,细粒度视觉识别(FGVR)对区分高度相似的物种至关重要,但其广泛应用却受限于昂贵且耗时的精细标注。因此,从粗标签中学习细粒度表征以实现FGVR是一项具有挑战性与价值的任务。早期的方法主要关注最小化细粒度类别类内方差,但忽视了细粒度类别之间的可分性,致使FGVR性能受限。后续研究采用自上而下的范式,通过深度聚类增强可分性,但这些方法需要预定义细粒度类别的数量,无法适应类别动态变化的现实场景(如新物种发现)。据此,我们提出一种自下而上的学习范式,通过迭代地合并相似的实例/聚类簇,构建层次化的树状图,从最低级的实例中推断出更高层次的语义,无需预定义类别数量。我们提出了BuCSFR方法,其包含自底向上构建(BuC)模块,该模块基于最小信息损失准则构建树状图;以及可分细粒度表征(SFR)模块,该模块将树状图节点视为伪标签,来确保细粒度表征的可分性。两个模块基于期望最大化(EM)框架,相互促进,协同工作。该方法使模型能自适应动态变化的语义结构(如物种演化),在仅使用粗标签条件下,实现无需先验类别数量的可分离细粒度表征学习,并在五个基准数据集上验证了方法的有效性。
09
论文9
论文题目:Category-Specific Selective Feature Enhancement for Long-Tailed Multi-Label Image Classification
论文作者:杜瑞琦,唐旭,张向荣,马晶晶
作者单位:西安电子科技大学
论文概述:由于现实世界中的多标签数据普遍存在严重的标签不平衡问题,长尾多标签图像分类已成为计算机视觉领域的一个研究热点。传统观点认为,深度神经网络的分类器更容易受到长尾分布的影响,而特征提取的主干网络相对更为稳健。然而,我们从特征学习的角度出发,发现主干网络在应对样本稀缺类别时虽然仍具备较强的区域定位能力,但丧失了相应类别的敏感性。基于这一观察,我们提出了一种用于长尾多标签图像分类的类别特异选择性特征增强模型。该方法首先利用主干网络所保留的定位能力生成标签相关的类激活图;随后,引入一种渐进式注意力增强机制,按从头部类别到中部类别再到尾部类别的顺序逐步增强低置信度类别的响应;最后,基于优化后的类激活图提取判别性视觉特征,并融合语义信息完成分类任务。在两个基准数据集上进行的大量实验证明了我们方法在长尾多标签场景下良好的泛化能力和分类表现。
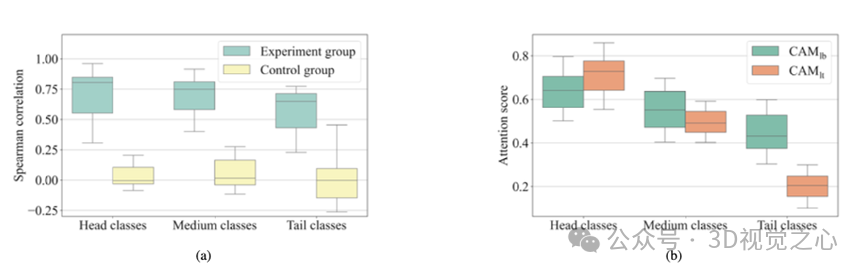
特征学习分析结果
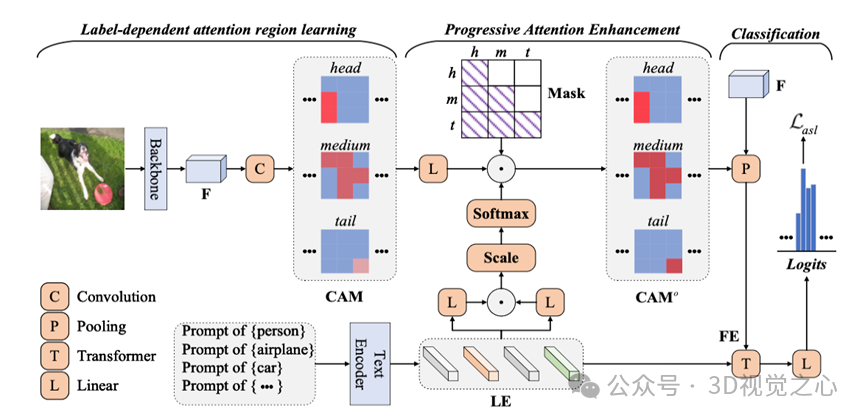
方法流程图
10
论文10
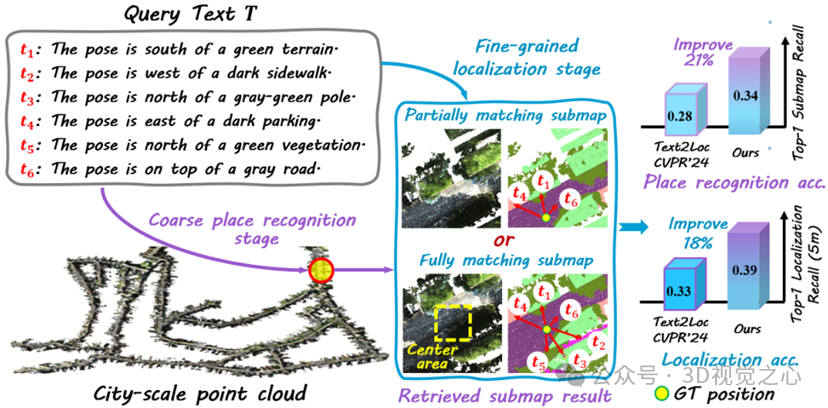
论文题目:Partially Matching Submap Helps: Uncertainty Modeling and Propagation for Text to Point Cloud Localization
论文作者:冯明涛,梅龙龙,武子杰,罗建桥,田丰豪,冯婕,董伟生,王耀南
作者单位:西安电子科技大学,湖南大学
论文概述:基于任务指令到城市级别的大规模点云跨模态定位是未来人机协作中的关键视觉-语言任务。现有框架通常假设每个指令文本严格对应于区域三维地图的中心区域,这限制了其在真实场景中的适用性。本研究针对现实噪声场景的假设重新定义该任务,通过允许指令文本与区域三维地图形成部分空间匹配对,放宽了一对一对齐的限制。为此,我们在精细位置回归中建模跨模态歧义性,通过引入表征为高斯分布的不确定性分数来缓解困难样本的影响。此外,我们提出不确定性感知相似性度量函数,将不确定性传播至区域三维场景识别阶段,从而提升指令文本与区域三维场景地图的相似性评估质量,该方法不仅能促使模型学习三维场景判别性特征,还能有效处理真实场景部分对齐样本并增强任务协同性。在多个数据集上的实验表明,我们的方法具有较好的性能和实际应用价值。

ICCV是计算机领域的著名国际会议,和CVPR、ECCV统称CV三大顶会(与ECCV轮流召开,两年一次),也是计算机学会推荐的A类会议。数据显示,今年大会共收到了11239份有效投稿,最终录用率为24%。ICCV 2025 将于10月19日至25日在美国夏威夷举行。
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、Diffusion Policy、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、各类学习路线等,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;


















 5822
5822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









