




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享华科最新的工作!ReCogDrive:结合强化学习的三阶段VLA训练框架!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『VLA』技术交流群
论文作者 | Yongkang Li等
编辑 | 自动驾驶之心
1. 引言
尽管当前基于端到端(End-to-End)的自动驾驶模型(如UniAD、VAD)在NuScenes等开环基准测试中表现优异,但这些方法在面对现实世界自动驾驶中的长尾场景时,其性能往往显著下降。为了应对这一挑战,近期涌现出大量研究工作尝试引入视觉-语言大模型(Vision-Language Models, VLMs),旨在利用其丰富的世界知识和强大的泛化能力来解决长尾问题。例如,DriveVLM、Senna、DiffVLA、AsyncDriver等双系统架构将VLMs与传统端到端模型相结合;而EMMA、Omnidrive、Orion、GPT-Driver、LMDrive 、Sce2DriveX、Atlas、WiseAD等单系统框架则直接利用VLMs进行轨迹预测。
论文题目:ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2506.08052
代码链接:https://github.com/xiaomi-research/recogdrive(将陆续开源模型、代码、权重)
然而,当前基于VLMs的自动驾驶规划模型主要存在以下关键缺陷:
VLMs通常在大规模的互联网图文数据上进行预训练,缺乏驾驶相关场景和关键的驾驶相关知识,限制了其在复杂多变真实驾驶环境中的应用。
VLMs输出的离散文本空间与自动驾驶所需的连续轨迹空间之间存在巨大鸿沟。同时,VLMs的自回归解码过程可能产生不符合预定格式的轨迹或错误的轨迹,这对于安全性要求极高的自动驾驶任务构成了不可接受的风险。
现有方法大多主要依赖模仿学习,导致模型往往最终学到次优的轨迹,模型只进行了记忆不会泛化。
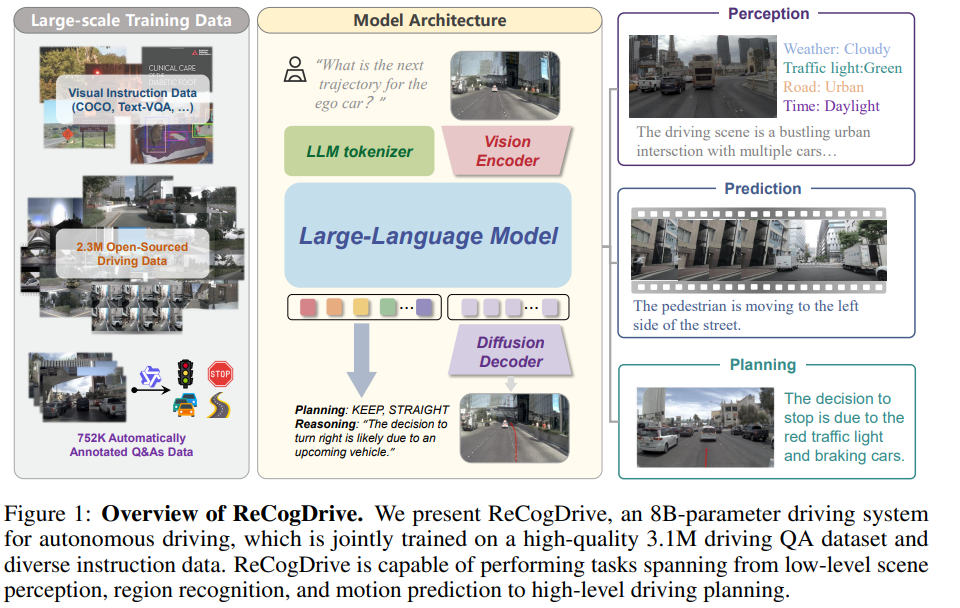
我们提出了 ReCogDrive,一个端到端的自动驾驶系统。其核心创新在于将视觉-语言大模型(VLMs)的认知能力与强化学习增强的扩散规划器(diffusion planner)融合。不同于以往的单系统方法,ReCogDrive 结合了 VLMs 的泛化能力 与 扩散模型的轨迹生成能力,以预测平滑、舒适、安全的驾驶轨迹。具体而言,我们首先精心构建了一个包含 310 万条高质量驾驶问答对 的数据集(包括处理开源的驾驶数据集以及通过搭建的自动标注流水线进行生成),用于对 VLMs 进行驾驶领域预训练,使其深度理解真实驾驶场景。随后,我们引入一个基于扩散模型的规划器,它作为桥梁有效弥合了 VLMs 语言空间与车辆连续动作空间之间的鸿沟,将高层次的语义表征映射为连续的轨迹,同时保留了 VLMs 原有的泛化性。为进一步提升轨迹质量,我们创新性地通过 模拟器辅助的强化学习(NAVSIM) 对扩散模型进行强化微调。与仅能复制专家行为的模仿学习不同,强化学习使模型能够主动探索驾驶行为,在模拟器的反馈循环中迭代优化,最终生成更安全、更稳定、更舒适的驾驶轨迹。通过在 NAVSIM 基准上进行实验,我们验证了 ReCogDrive 的有效性,其达到了 89.6 PDMS 分数,超过之前纯视觉的方案 5.6 PDMS,充分证明了该系统的优越性能和现实可行性。
2. 相关工作
视觉语言模型在自动驾驶中的应用
最近许多研究探索将视觉语言模型(VLMs)的世界知识应用到自动驾驶场景中,解决现有模型的泛化性问题,当前现有方法可分为双系统与单系统两类架构:双系统方案(如 DriveVLM 和 Senna)将 VLMs 与端到端驾驶系统结合,通过 VLMs 生成低频轨迹或高层指令并由端到端模型输出最终轨迹;单系统方案中,GPT-Driver、EMMA 和 OpenEMMA 将轨迹规划任务重构为语言建模任务并引入思维链推理增强可解释性,Agent-Driver 集成工具库与认知记忆模块扩展大语言模型的感知-决策能力,OmniDrive、Orion 和 Atlas 通过引入 3D 视觉特征提取器提升模型 3D 感知能力,LMDrive 与 WiseAD 在闭环中验证 VLMs 的驾驶能力,Sce2DriveX 采用多模态联合学习优化 3D 感知。而我们的 ReCogDrive 融合 VLMs 与扩散模型,实现预测稳定、安全的轨迹。
扩散模型在具身智能和自动驾驶应用
扩散模型在具身智能与自动驾驶领域展现出独特优势。Diffusion Policy 将扩散模型扩展至机器人领域,有效处理多模态动作分布问题,π0、π0.5、GR00T-N1 等工作将 VLMs 与 Flow Matching 结合,保留 VLMs 泛化性的同时精准地预测未来工作轨迹;RDT-1B 提出首个面向双手操作的扩散基础模型,通过统一物理可解释动作空间解决异构机器人数据兼容性问题;DiffusionDrive、TrackVLA 等工作引入截断扩散策略,有效缓解模态坍塌并降低计算开销;Diffusion Planner 创新性地将规划任务重构为多轨迹生成问题,同时预测自车轨迹和其他车辆轨迹。我们也将扩散模型与多模态大模型结合,同时不同于以往方法只采用模仿学习训练,我们还引入强化学习对扩散模型进行训练,提升模型泛化性。
强化学习在自动驾驶中应用
强化学习(RL)作为一种关键技术,已在大型语言模型和游戏智能体中验证其有效性,并应用于自动驾驶特定场景。现有方法多在非真实感模拟器(如 CARLA)中直接学习控制空间策略。为弥合仿真与现实差距,RAD 在 3DGS 环境中训练端到端驾驶模型;CarPlanner 提出自回归多模态轨迹规划器,其 RL 策略在 nuPlan 数据集上超越模仿学习方法;最近由于 Deepseek-R1 的成功,GRPO 算法被引入规划领域——AlphaDrive 首次集成 GRPO 强化学习与驾驶多模态大模型,通过引入思考更准确地预测高阶指令;TrajHF 则构建人类反馈驱动的微调框架,实现生成轨迹与多样化驾驶偏好的对齐。而我们 ReCogDrive 通过仿真器协助的强化学习来让模型预测更安全、舒适的轨迹。
3.方法
ReCogDrive的结构主要由驾驶多模态大模型和基于扩散模型的规划器组成,推理时,将前视图以及导航指令,历史轨迹,任务指令输入给多模态大模型,多模态大模型输出隐藏特征作为Diffusion的Condition,Diffusion从噪声中逐步去噪生成最终轨迹。训练采用三阶段训练方式,首先,我们收集了一个包含310万条高质量问答对的驾驶数据集,用于训练视觉语言模型(VLMs),将驾驶特定的认知知识注入模型中。接着,我们将预训练的视觉语言模型与基于扩散的轨迹规划器结合,实现稳定的语言到动作映射,将潜在的语言空间转化为连续动作空间。最后,我们引入仿真辅助的强化学习,将通过多轨迹探索获得的泛化驾驶认知整合进扩散规划器中。
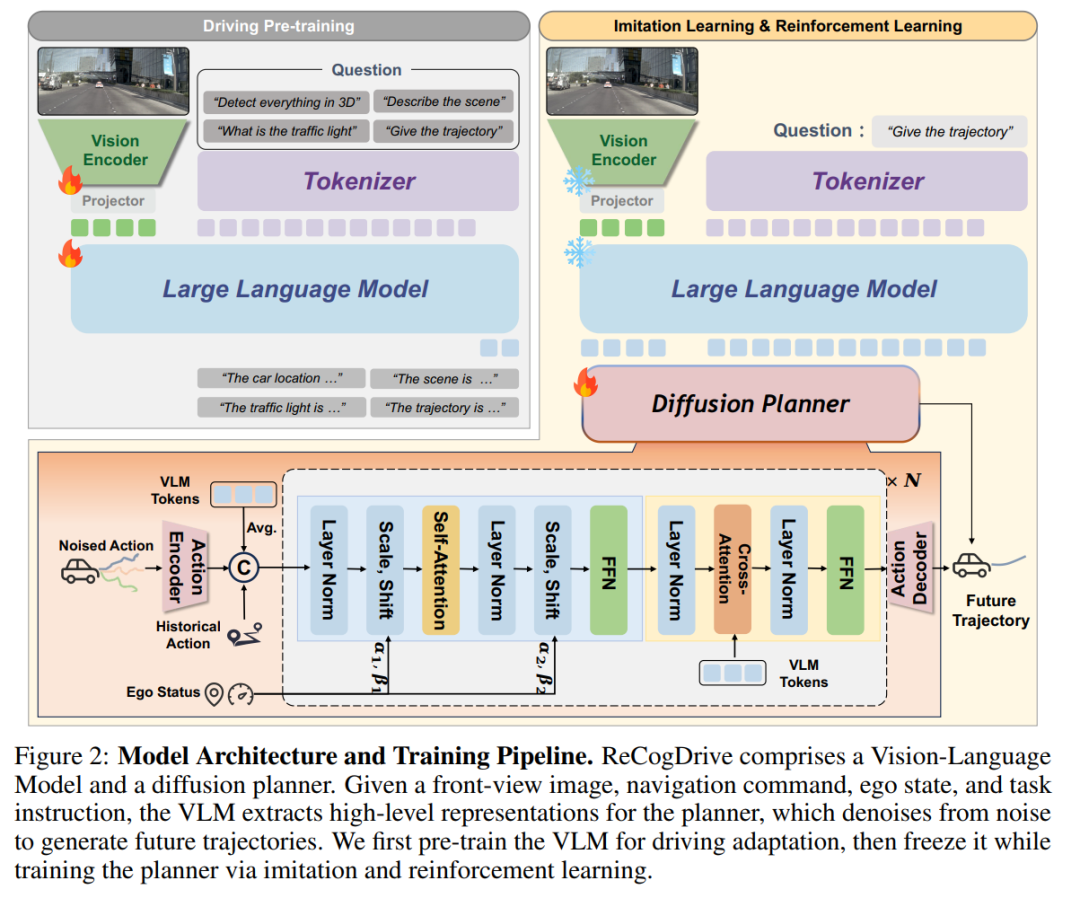
3.1 驾驶场景多模态大模型训练
由于通用大模型通常在互联网图像文本数据集上进行预训练,直接将多模态大模型应用于驾驶轨迹预测很困难,我们首先使用310万高质量驾驶数据集来让大模型适应驾驶场景。具体而言,我们从12个开源驾驶数据集收集数据,进行归一化处理,统一格式,重新标注回答,打分过滤低质量数据,最终得到230万条高质量驾驶问答对,我们还构建了一个自动标注流水线,结合 Qwen2.5-VL 和数据集标签,生成高质量的问答数据,涵盖场景描述、关键物体描述、规划解释等任务,此外,还融合 LLaVA 指令调优数据,以保持视觉语言模型的指令遵循能力。
我们采用 InternVL3-8B 作为基础模型,该模型采用“原生多模态预训练”范式,在多个基准测试中表现优异。每张图像被切分为 448×448 的图块及一个 448×448 的缩略图,并由经过 InternViT 编码。通过 pixel shuffle,将图像特征压缩为每个图块 256 个 Token,这些 Token 与文本 Token 拼接后输入大语言模型(LLM)。经过在310万条高质量驾驶问答对和指令遵循数据的混合数据集上微调后,模型能够以文本的形式生成轨迹 、驾驶解释 以及场景描述 等:
其中 和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









