 高频连续动作VLA模型:训练快、泛化好
高频连续动作VLA模型:训练快、泛化好




点击下方卡片,关注“具身智能之心”公众号
作者丨xiumius
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

出发点与解决方案
VLA模型通过端到端学习与网络规模视觉-语言模型(VLM)预训练语义知识迁移的结合,为机器人等物理系统的控制策略训练提供了强大方法。但实时控制约束与VLM设计常存在矛盾:最强VLM有数百亿参数,阻碍实时推理,且其基于离散token运行,而非控制机器人所需的连续值输出。为应对这一挑战,近期VLA模型使用动作专家或连续输出Head等专门模块实现高效连续控制,这通常需向预训练VLM主干添加未经训练的新参数。虽这些模块提升了实时性和控制能力,但它们是保留还是降低了预训练VLM中包含的语义知识,以及对VLA训练动态有何影响,仍是未解决问题。这项工作在包含连续扩散或流匹配动作专家的VLA背景下研究该问题,表明简单包含此类专家会显著损害训练速度和知识迁移。我们对各种设计选择及其对性能和知识迁移的影响进行了广泛分析,并提出了一种在VLA训练期间隔离VLM主干的技术来缓解此问题。
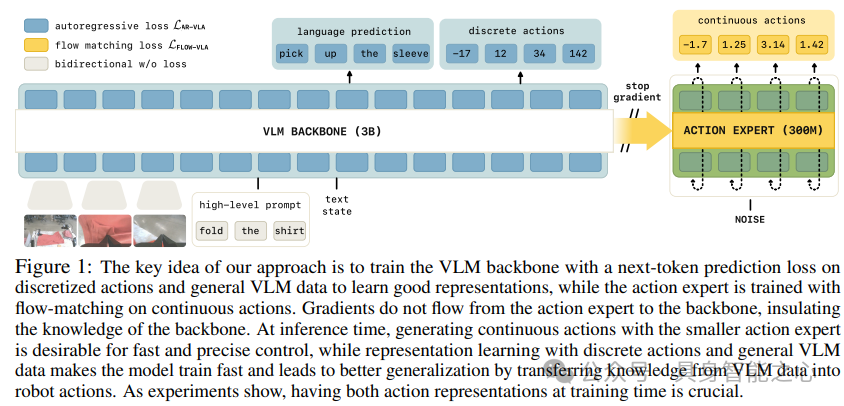
背景介绍
大型语言模型(LLM)的成功源于大规模数据集与强大模型架构(如Transformer)的结合,其可通过提示解决各类任务,扩展至多模态编码器后可生成视觉-语言模型(VLM)以解决视觉推理问题。将LLM能力带入物理世界的自然下一步是进一步扩展其采取物理动作,形成视觉-语言-动作(VLA)模型,以控制机器人执行语言命令,结合端到端机器人学习能力与从网络规模视觉-语言预训练中提取的语义知识。然而,使LLM和VLM适应现实世界控制需解决诸多新挑战:大多数物理系统需要高频实时的连续精确命令,自回归解码离散token不适于此类高频连续控制,且物理系统产生的观测通常比VLM训练数据更复杂,这需要修改原始VLM架构以适应机器人控制。
机器人社区已开发出特别适合实时连续控制需求的架构,常见做法是用连续输入和输出适配器增强Transformer或VLM主干,这使模型能表示复杂连续动作分布、选择精确动作并捕捉灵巧高频技能。但将这些额外模块添加到预训练VLM以创建VLA时,它们通常需从头初始化,VLA训练过程必须将其“嫁接”到VLM主干上,这引发重要问题:增强了这些连续状态和动作适配器的VLA实际上从网络规模预训练中继承和受益多少?
我们观察到,用连续输出微调VLM的先前方法会导致显著更差的训练动态,这或许并不令人意外,因为它们依赖来自连续适配器(如扩散Head)的梯度作为训练信号,这会降低其解释语言命令的能力和所得VLA策略的整体性能。为应对这一挑战,这里提出了一种称为知识隔离的训练方法,其核心思想是用离散动作微调VLM主干,同时调整动作专家以产生连续动作(如通过流匹配或扩散),而不将其梯度传播回VLM主干。此方法有额外优势:首先,使用下一个token预测使模型学习更快更稳定;其次,使用动作专家仍能实现快速推理;第三,该方法使模型能在通用视觉-语言数据上共同训练。实验评估在π₀模型架构基础上,对连续动作VLA中的各种建模选择进行了广泛分析,在复杂长时程机器人操作任务(包括移动双手机器人)以及DROID和LIBERO等开源基准上进行了评估。
相关工作
多模态大型语言模型
我们研究如何将机器人动作作为新模态集成到预训练VLM中。常见技术是将新输入模态嵌入为离散或连续“软”token。遵循多模态交叉注意力的早期工作,最近研究表明,对于多模态生成建模,将模态分离为特定模态“专家”网络可防止干扰并导致更高质量预测,而我们感兴趣的是使用类似架构将新模态(机器人动作)融合到预训练VLM中。
视觉-语言-动作模型(VLA)
VLA最近被提出作为可泛化机器人控制的有前途方法,其核心思想是微调预训练视觉-语言模型(VLM)进行动作预测,此类VLA可扩展到大规模机器人数据集,并已显示出从网络规模VLM预训练中迁移知识以改善策略泛化的能力。为使VLM能在动作数据上微调,VLA训练pipeline通常将连续动作映射到离散动作token序列,然后通过标准自回归下一个token预测训练VLA。虽该策略在较简单低频控制任务上有效,但有两个缺点:一是从连续到离散动作token的映射可能有损失,二是自回归解码动作导致策略推理慢,使现代自回归VLA在许多高频任务上不切实际。
VLA中的快速连续动作解码机制
为解决这些问题,多个先前工作探索了VLA的替代动作解码机制,以保留连续动作输出和快速推理,这些方法通常在VLA动作微调期间引入新权重和损失,如通过扩散预测头或基于流匹配的“动作专家”,其关注VLM主干中的特征。虽这些方法实现了快速推理,但在微调期间简单添加新权重和训练损失会带来自身问题:此类VLA训练速度通常比其自回归对应物慢得多,且网络数据迁移减少。一些工作采用两阶段过程,先使用自回归离散化训练模型,然后用连续输出微调至目标域。
π₀和π0.5模型
我们构建在π₀和π₀-FAST VLA基础上。π₀引入了连续动作专家,可捕捉动作块上的复杂连续分布,允许高效推理并实现灵巧任务的连续控制,但实验表明,π₀方法本身会导致语言跟随和训练速度方面的退化,因为来自动作专家的梯度会降低预训练VLM主干。π₀-FAST通过使用基于DCT的tokenizer解决此问题,实现了复杂动作块的高效离散化,但代价是需要昂贵的自回归推理,并降低了执行精细动态任务的能力。π0.5首先仅用FAST tokenized动作训练,然后在训练后添加随机初始化的动作专家以在移动操作数据上进行微调,我们将π0.5的方法形式化并扩展为开发单阶段训练方法,使VLM主干通过离散token适应机器人控制,同时动作专家被同时训练以产生连续动作,提供两全其美的效果,并在实验中严格消融不同的知识保留和共同训练机制,从而提出首个训练快速、保留VLM知识并支持高频连续动作输出控制的VLA方法。

标准视觉-语言-动作(VLA)模型训练方法
动作表示
机器人动作通常是实值向量,代表机器人关节角度或末端执行器坐标,常见策略是采用动作分块,即预测相对于当前机器人状态的机器人动作轨迹。为使VLM适应VLA,有多种表示这些动作块的选择:
朴素离散化:将块中每个动作的每个维度离散化,然后将每个离散化箱与特殊文本token相关联,将块映射为token,机器人动作预测被框架化为下一个token预测问题,模型可像非机器人特定VLM一样用交叉熵损失训练。
时间动作抽象:朴素离散化的缺点是对于高频高维系统,表示动作的token数量快速增长,大大增加计算成本并导致训练收敛缓慢,近期工作通过应用压缩时间信息的变换来缓解此效应,我们使用FAST编码动作,对动作块的每个维度应用离散余弦变换,然后进行量化和字节对编码以生成动作token。
扩散和流匹配:许多最近提出的VLA模型使用扩散或流匹配生成连续动作,实验遵循π₀的设计,使用流匹配“动作专家”。
状态表示
考虑机器人本体感受状态的三种不同表示:离散化后表示为文本(“文本状态”)、也使用离散化的特殊token(“特殊token状态”),以及通过学习投影直接映射到主干的连续状态(“连续状态”)。
VLA架构、训练和专家混合
大多数VLA由多模态Transformer构建,通常用预训练VLM权重初始化。我们的模型将72个多模态输入token的序列映射到72个多模态输出token的概率。对于VLA,通常输出对应动作目标,先前工作考虑联合训练一个模型用于动作预测和VLM任务。每个token可以是文本token、图像块或连续输入(如机器人状态或动作),token用不同编码器嵌入,注意力掩码指示哪些token可以相互关注。
Transformer是将n个输入嵌入映射到n个输出嵌入的函数,通过堆叠多个由注意力层、前馈层和归一化层组成的块构建。与标准Transformer相比,我们模型使用单独权重处理不同token。模型从PaliGemma初始化VLM,并为动作token使用较小权重集,显著减少生成动作时的推理时间,主干和动作token有各自的查询、键和值投影,但投影维度相同,使专家可相互交互。
大多数VLA在大型机器人行为克隆数据集上训练,对于自回归架构,标准训练过程是最小化目标token的负对数似然;当流匹配用于动作预测时,损失为预测流与实际流的均方误差。
标准VLA方法的问题
自回归VLA速度慢
自回归VLA将预测实值动作的问题视为离散下一个token预测问题,这既限制了模型可表示的值的分辨率,又导致缓慢的顺序推理,如π₀-FAST在RTX4090 GPU上预测1秒动作块的推理时间约为750ms,这可能导致动态不匹配和整体轨迹缓慢。
机器人特定架构和模态适配器从VLM预训练中受益不足
像π₀或GROOT这样的架构包含机器人特定模块以实现更快推理,如π₀架构中的动作专家参数比VLM主干少,因此π₀可实现10Hz的控制频率,比自回归VLA快得多。虽这些模型的部分从预训练VLM初始化(如视觉编码器或语言模型主干),但机器人特定模块从头初始化,实验表明,用这种随机初始化的动作专家进行朴素训练会损害模型跟随语言命令的能力(可能由于梯度干扰)。
VLM预训练没有足够的机器人表示-冻结不起作用
直观上,维护来自VLM预训练知识的最简单方法是冻结预训练权重,仅训练新添加的机器人特定权重,但当前VLM未用机器人数据预训练,因此,冻结时它们的表示不足以训练高性能策略。
用共同训练、联合训练和知识隔离改进VLA
用联合离散/连续动作预测进行共同训练和表示学习
为实现与VLM数据的有效共同训练,增强从语言到策略的知识迁移,并允许快速训练,考虑在一个模型中结合自回归语言和离散动作预测以及连续动作的流匹配建模。我们提出学习一个模型,可从中采样实值动作块和文本,使用FAST tokenizer将连续动作转换为离散token,然后用token预测和流匹配损失的组合训练模型,这种损失构造允许灵活地与来自不同模态的数据进行混合共同训练,特别是将VLM数据(仅有图像和文本注释)与仅动作数据(任务是基于图像和文本的动作预测)以及语言和动作预测组合任务相结合,这种方式混合不同模态的数据可增强所得VLA中的知识迁移。关键是设置注意力掩码,使离散FAST动作token不能关注连续动作token,反之亦然,实验表明,这种联合训练目标使模型能够结合两全其美:通过使用FAST动作token学习良好表示,在训练期间实现快速收敛,并通过流集成的几个步骤仍然获得连续动作的快速推理。
(二)知识隔离和梯度流
用流匹配训练的动作专家的梯度会不利地影响图像编码器和语言模型主干的训练动态,特别是当将新的随机初始化动作专家添加到预训练主干时。因此,提出停止从动作专家到模型中预训练权重的梯度流,这是一个合理的限制,当且仅当主干另外被训练为直接预测动作作为其语言输出的一部分时。由于建议在训练期间联合训练模型的离散动作,因此可以确保Transformer层的组合激活包含足够的信息来推断动作,预训练模型主干和动作专家仅通过注意力层交互。为停止从动作专家到主干的梯度流,需要修改注意力层,这种设计的一个额外优点是可以简单地在损失函数中设置α=1,因为现在扩散损失项应用于一组独立的权重。
实验分析
实验设置
在现实世界中的灵巧长时程操作任务上评估方法,包括清洁桌子、用双手静态机器人折叠衬衫、用单个静态机器人手臂将 household 物品放入抽屉,以及涉及双手移动操作器的多个任务,还在LIBERO模拟基准和现实世界的DROID上展示了结果。训练模型既在单个机器人实体上,也在从许多不同机器人的大量任务数据(包括非动作预测任务,如图像字幕、边界框预测和机器人规划)的混合中训练的通用模型上。

(二)实验结果
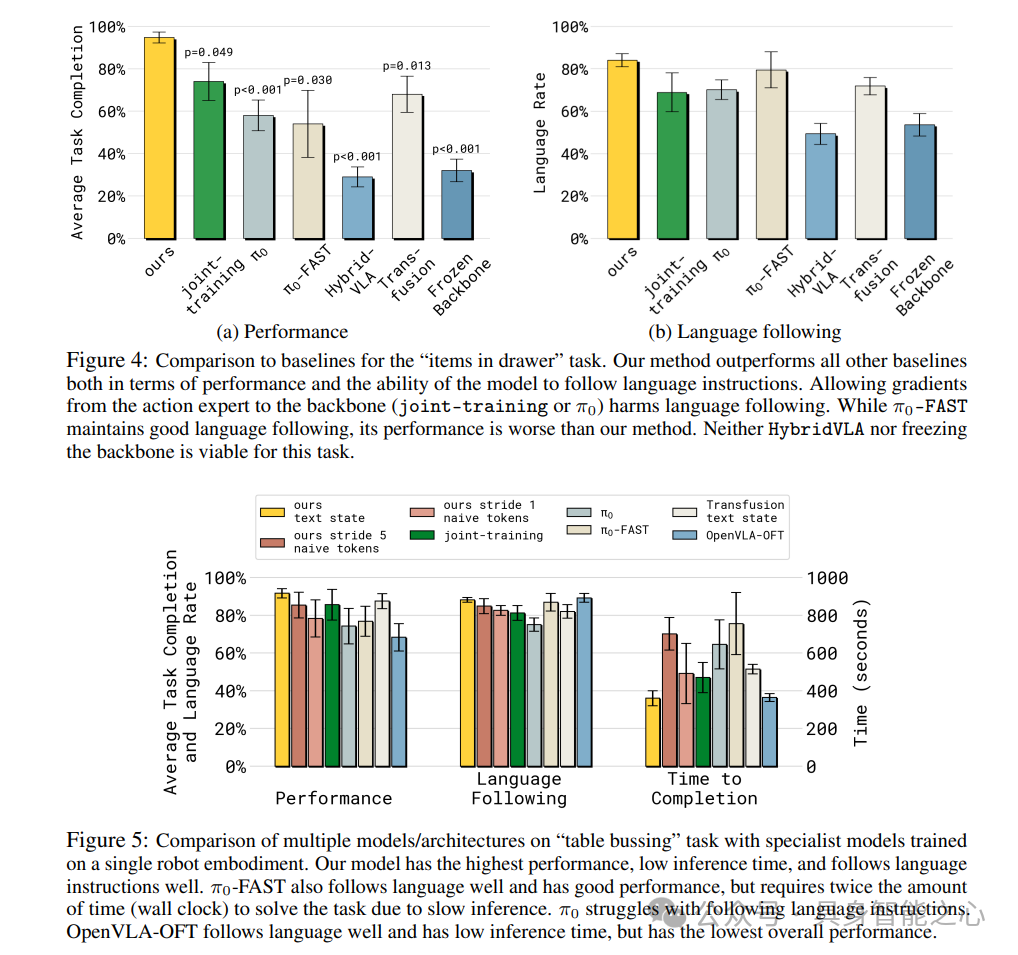
任务性能和与基线的比较:我们方法在现实世界评估中始终实现最高性能。对于“物品入抽屉”任务,所有基线表现明显比提出的方法差,共同训练基线(无停止梯度)在跟随语言方面有问题,π₀-FAST移动缓慢且在许多情况下无法精确打开抽屉,HybridVLA在方法上与我们最相似,但允许自回归token关注连续动作,这似乎在此任务上显著损害性能,按本文建议设置注意力掩码导致性能好得多。在“桌子清理”任务上,我们方法表现最佳,π₀-FAST也能很好地跟随语言且表现良好,但由于推理缓慢,解决任务需要两倍的时间,π₀在跟随语言指令方面困难,OpenVLA-OFT跟随语言良好且推理时间低,但整体性能最低。在开源基准DROID上,我们方法得分高于π₀和π₀-FAST,在LIBERO基准上,我们方法在LIBERO-90和LIBERO-Spatial上实现了新的最先进水平。
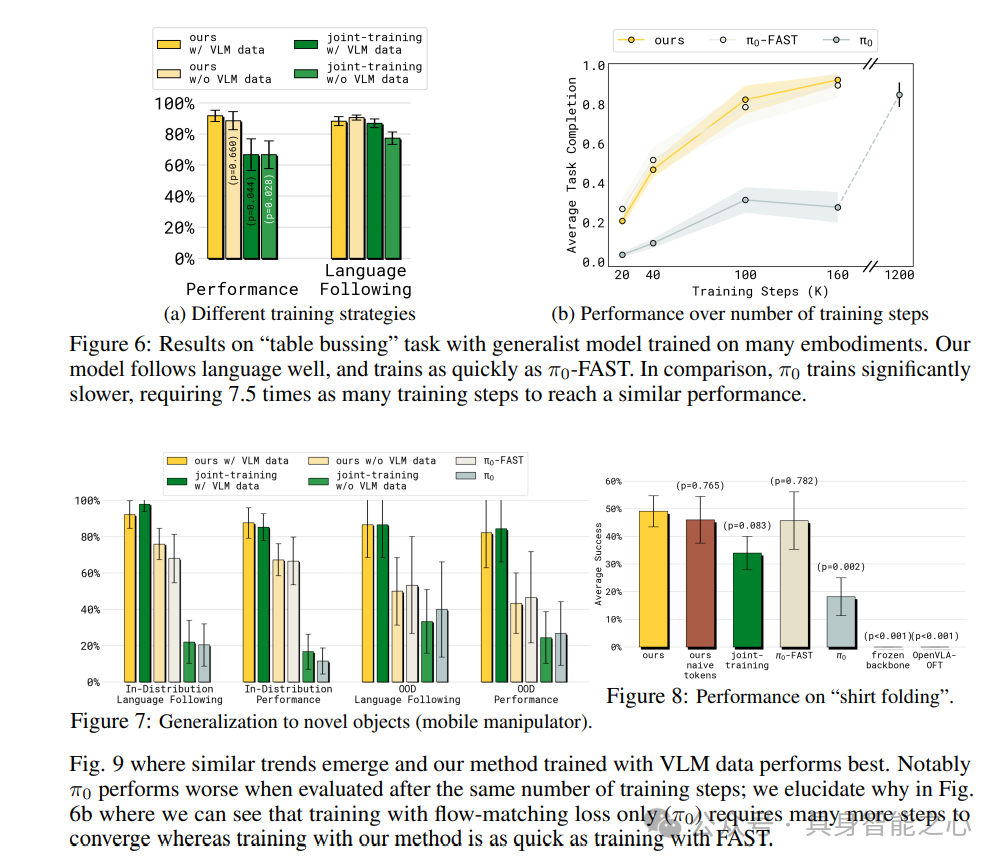
通用VLA评估:当在所有可用训练数据上联合训练时,我们的方法在“桌子清理”任务上实现了与上述特定实体结果相当的性能,共同训练在任务完成方面退化,删除VLM数据导致任务完成百分比略差,在评估四种移动操作任务时,用VLM数据训练的本文方法表现最佳。
语言跟随:停止来自动作专家的梯度流是改善语言跟随的有效方法,与没有停止梯度和没有VLM数据共同训练的π₀联合训练相比,若模型与VLM数据共同训练,没有停止梯度的联合训练也能实现良好的语言跟随, transfusio跟随语言比带有动作专家的π₀更好,这些结果强烈支持以下假设:来自随机初始化机器人特定适配器的梯度与预训练VLM权重产生不利交互,这里提出的停止梯度流和/或与VLM数据共同训练的知识隔离技术能够实现更好的语言跟随。
从VLM数据到机器人的迁移:在移动操作机器人的实验中,对VLM数据进行共同训练对于这种泛化特别重要。
其他建模选择的研究:这里主要方法使用FAST来表示离散动作作为模型主干的表示学习目标,FAST提供了比朴素离散化更好的学习信号,并有助于更快的推理,将FAST替换为朴素离散化会导致性能下降,对机器人本体感受状态的不同选择的研究发现,本文方法在文本和连续状态下都有效,而π₀在两种状态表示下都表现更差。
参考
[1] Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better.
论文辅导计划

具身智能干货社区
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、具身大脑、具身小脑、大模型、视觉语言模型、强化学习、Diffusion Policy、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近30+学习路线、40+开源项目、近60+具身智能相关数据集。

全栈技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、Diffusion Policy、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)。


















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









