



点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
自UniAD引爆端到端自动驾驶的热度以来,近两年无论是学术界还是工业界都把端到端自动驾驶作为主要发力点。2024年,理想汽车率先宣布E2E+VLM快慢双系统架构量产,今年又率先开启了VLA研发量产。各大顶会(CVPR/ICCV/ECCV)的自动驾驶端到端/VLM方向论文数量呈现指数级增长。
随着2025年将要过半,近期又涌现出很多优秀的工作。
为此,自动驾驶之心联合业内一线算法研究员/专家,整理出近期端到端/VLA最热门的10篇论文!期待和大家一起学习交流~
❝ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
论文链接:https://arxiv.org/abs/2503.19755
代码链接:https://github.com/xiaomi-mlab/Orion
核心贡献点:小米汽车的端到端VLM工作,在Bench2Drive上取得非常好的结果。
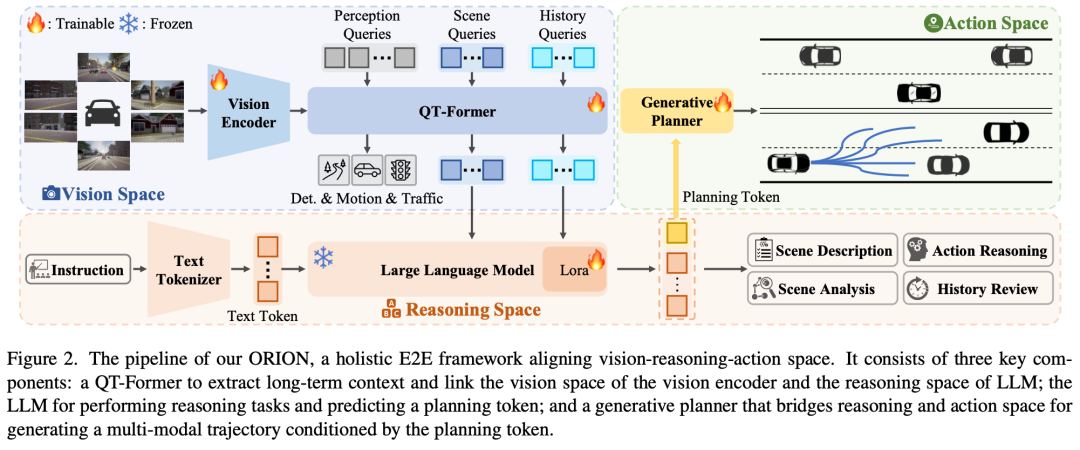
由于因果推理能力有限,端到端(E2E)自动驾驶方法在交互式闭环评估中仍难以做出正确决策。目前的方法试图利用视觉语言模型(VLMs)强大的理解和推理能力来解决这一困境。然而,由于语义推理空间和动作空间中纯数值轨迹输出之间的差距,E2E方法的VLM在闭环评估中表现良好的问题仍然存在。为了解决这个问题,我们提出了ORION,这是一个通过视觉语言指导动作生成的整体E2E自动驾驶框架。ORION独特地结合了QT Former来聚合长时序历史背景、用于驱动场景推理的大型语言模型(LLM)和用于精确轨迹预测的生成规划器。ORION进一步将推理空间和动作空间对齐,为视觉问答(VQA)和规划任务实现统一的E2E优化。我们的方法在挑战Bench2Drive数据集上实现了令人印象深刻的闭环性能,即77.74的驾驶分数(DS)和54.62%的成功率(SR),比最先进的(SOTA)方法高出14.28 DS和19.61%SR。
端午节大额新人优惠!欢迎扫码加入知识星球~

❝VLM-AD: End-to-End Driving through Vision-Language Model Supervision
论文链接:https://arxiv.org/abs/2412.14446
核心贡献点:利用VLM作为教师模型方法,且在推理过程中不需要VLM,适合实时部署。
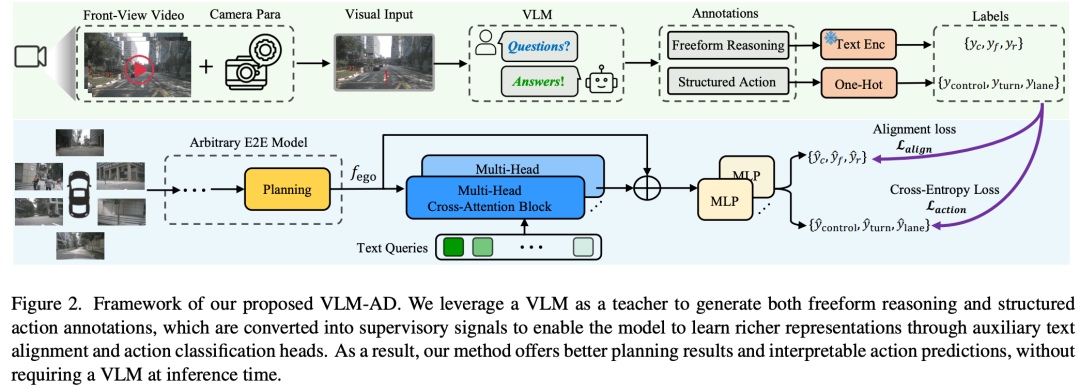
人类驾驶员依靠常识推理来驾驭多样化和动态的现实世界场景。现有的端到端(E2E)自动驾驶(AD)模型通常经过优化,以模拟数据中观察到的驾驶模式,而不捕获底层推理过程。这种限制限制了他们处理具有挑战性的驾驶场景的能力。为了缩小这一差距,我们提出了VLM-AD,这是一种利用视觉语言模型(VLM)作为教师的方法,通过提供包含非结构化推理信息和结构化动作标签的额外监督来加强培训。这种监督增强了模型学习更丰富的特征表示的能力,这些特征表示捕捉了驾驶模式背后的基本原理。重要的是,我们的方法在推理过程中不需要VLM,使其适用于实时部署。当与最先进的方法集成时,VLM-AD在nuScenes数据集上的规划精度和碰撞率方面取得了显著提高。
❝EMMA: End-to-End Multimodal Model for Autonomous Driving
论文链接:https://arxiv.org/abs/2410.23262
项目主页:https://waymo.com/blog/2024/10/introducing-emma/
核心贡献点:全局式端到端的代表,直接输入视频,没有backbone,核心就是多模态大模型。
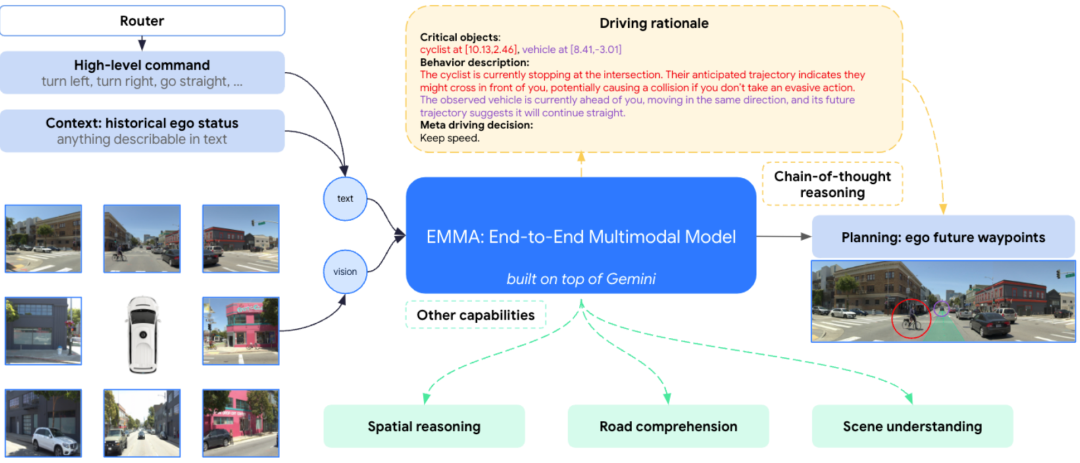
EMMA一种用于自动驾驶的端到端多模式模型。EMMA建立在多模态大型语言模型的基础上,将原始摄像头传感器数据直接映射到各种特定于驾驶的输出中,包括规划者轨迹、感知目标和道路图元素。EMMA通过将所有非传感器输入(如导航指令和自我车辆状态)和输出(如轨迹和3D位置)表示为自然语言文本,最大限度地利用了预训练的大型语言模型中的世界知识。这种方法允许EMMA在统一的语言空间中联合处理各种驾驶任务,并使用任务特定的提示为每个任务生成输出。根据经验,我们通过在nuScenes上实现最先进的运动规划性能以及在Waymo开放运动数据集(WOMD)上取得有竞争力的结果来证明EMMA的有效性。EMMA还为Waymo开放数据集(WOD)上的相机主3D对象检测提供了有竞争力的结果。我们表明,将EMMA与规划器轨迹、对象检测和道路图任务联合训练,可以在所有三个领域取得进步,突显了EMMA作为自动驾驶应用的通用模型的潜力。然而,EMMA也表现出一定的局限性:它只能处理少量的图像帧,不包含激光雷达或雷达等精确的3D传感方式,计算成本很高。我们希望我们的研究结果能够激发进一步的研究,以缓解这些问题,并进一步发展自动驾驶模型架构的最新技术。
❝DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2503.07656
核心贡献点:DriveTransformer为端到端自动驾驶提供了一种无需BEV的统一、并行和协同的方法,便于训练和扩展。
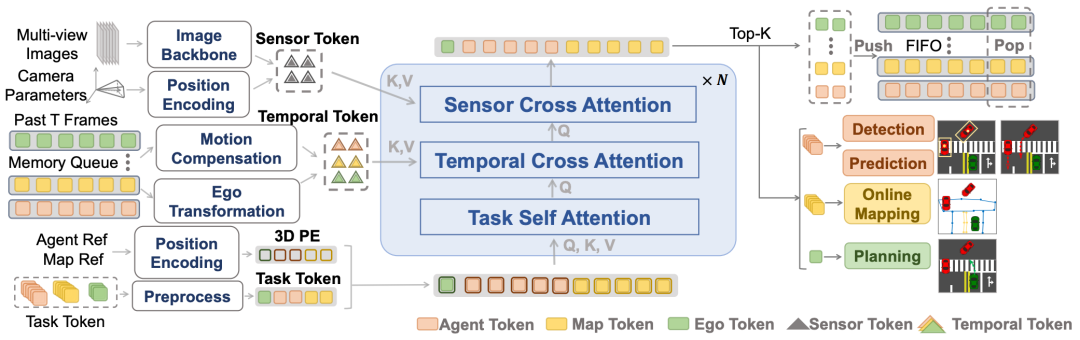
端到端自动驾驶(E2E-AD)已成为自动驾驶领域的一种趋势,有望成为一种数据驱动、可扩展的系统设计方法。然而,现有的E2E-AD方法通常采用感知预测规划的顺序范式,这会导致累积误差和训练不稳定。手动排序任务也限制了系统利用任务之间协同作用的能力(例如,规划感知和博弈论交互式预测和规划)。此外,现有方法采用的密集BEV表示给远程感知和长期时间融合带来了计算挑战。为了应对这些挑战,我们提出了DriveTransformer,这是一个简化的E2E-AD框架,便于扩展,具有三个关键特征:任务并行性(所有代理、映射和规划查询在每个块上直接相互交互)、稀疏表示(任务查询直接与原始传感器特征交互)和流处理(任务查询作为历史信息存储和传递)。因此,新框架由三个统一的操作组成:任务自我注意、传感器交叉注意、时间交叉注意,这大大降低了系统的复杂性,提高了训练的稳定性。DriveTransformer在模拟闭环基准Bench2Drive和现实世界开环基准nuScenes中都实现了最先进的性能,具有高FPS。
❝RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
论文链接:https://arxiv.org/pdf/2502.13144
项目主页:https://hgao-cv.github.io/RAD/
核心贡献点:首个基于3DGS的RL框架,用于训练端到端AD策略;也是一种基于强化学习的端到端方案。
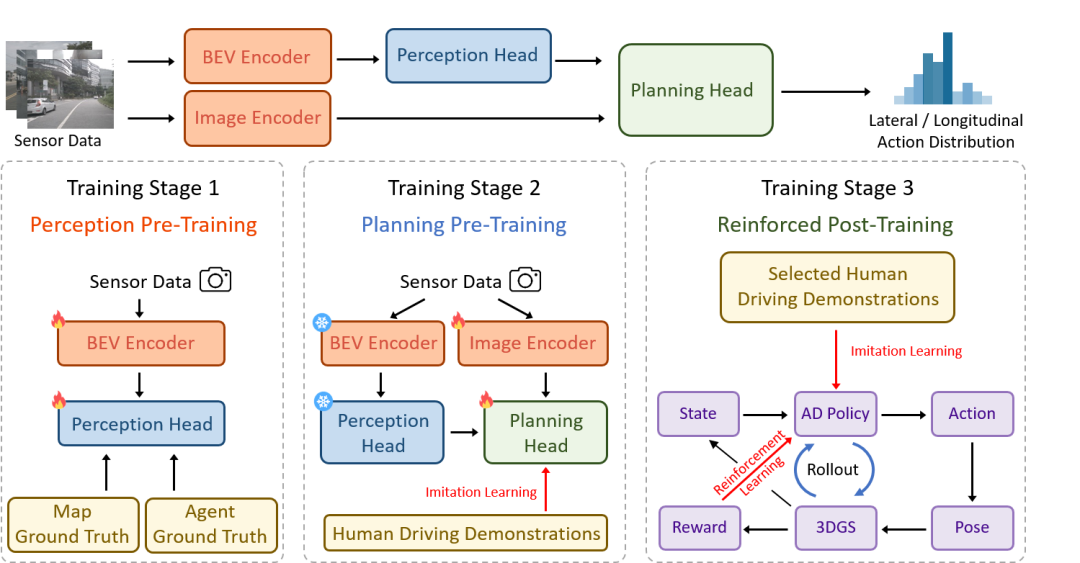
现有的端到端自动驾驶(AD)算法通常遵循模仿学习(IL)范式,这面临着因果混淆和开环差距等挑战。在这项工作中,我们建立了一个基于3DGS的闭环强化学习(RL)训练范式。通过利用3DGS技术,我们构建了真实物理世界的真实闭环仿真,使AD策略能够广泛探索状态空间,并通过大规模的试错来学习处理超出分布的场景。为了提高安全性,我们设计了专门的奖励,指导政策有效应对安全关键事件,并了解现实世界的因果关系。为了更好地与人类驾驶行为保持一致,IL作为正则化术语被纳入RL训练中。我们引入了一个闭环评估基准,由各种以前从未见过的3DGS环境组成。与基于IL的方法相比,RAD在大多数闭环度量中都取得了更强的性能,特别是碰撞率降低了3倍。
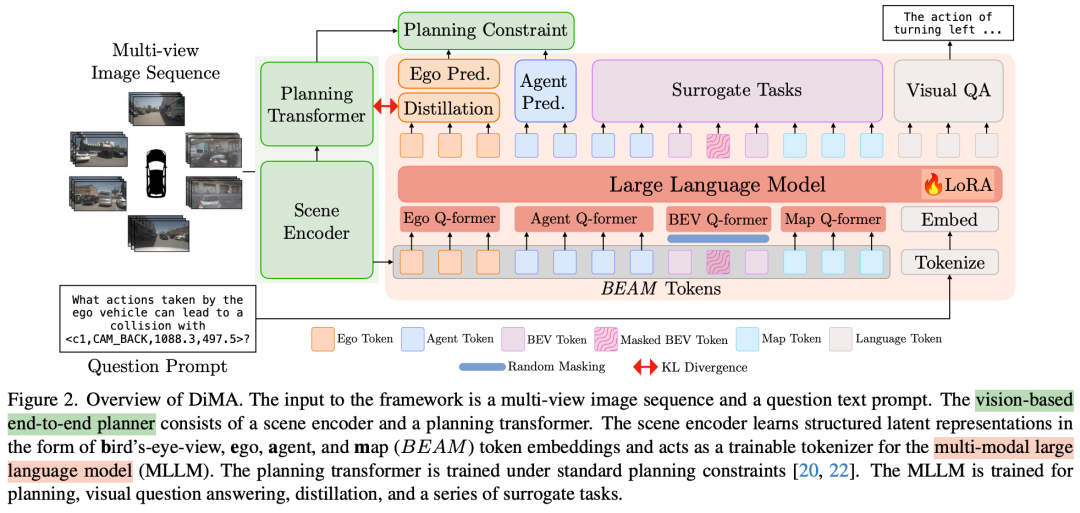
❝Distilling Multi-modal Large Language Models for Autonomous Driving
论文链接:https://arxiv.org/abs/2501.09757
核心贡献点:通过知识蒸馏将多模态大语言模型(MLLM)的知识转移到基于视觉的E2E规划器中,有助于提升模型在复杂和长尾场景下(如极端天气、罕见障碍物)的泛化能力。
自动驾驶需要安全的运动规划,特别是在关键的“长尾”场景中。最近的端到端自动驾驶系统利用大型语言模型(LLM)作为规划者,以提高对罕见事件的泛化能力。然而,在测试时使用LLM会带来高昂的计算成本。为了解决这个问题,我们提出了DiMA,这是一种端到端的自动驾驶系统,它在利用LLM的世界知识的同时,保持了无LLM(或基于视觉)规划者的效率。DiMA通过一组专门设计的代理任务,将多模态LLM中的信息提取到基于视觉的端到端规划器中。在联合训练策略下,两个网络共用的场景编码器产生结构化表示,这些表示在语义上是基础的,并且与最终的规划目标保持一致。值得注意的是,LLM在推理时是可选的,可以在不影响效率的情况下实现稳健的规划。使用DiMA进行训练可以使基于视觉的规划器的L2轨迹误差减少37%,碰撞率减少80%,在长尾场景中轨迹误差减少44%。DiMA在nuScenes规划基准上也取得了最先进的性能。
❝HiP-AD: Hierarchical and Multi-Granularity Planning with Deformable Attention for Autonomous Driving in a Single Decoder
论文链接:https://arxiv.org/abs/2503.08612
核心贡献点:旨在提升端到端自动驾驶系统在闭环评估中成功率低的问题,特别是在规划模块的查询设计与交互方面,HiP-AD在nuScenes数据集上闭环碰撞率降低至0.7%,且支持车载芯片实时部署。
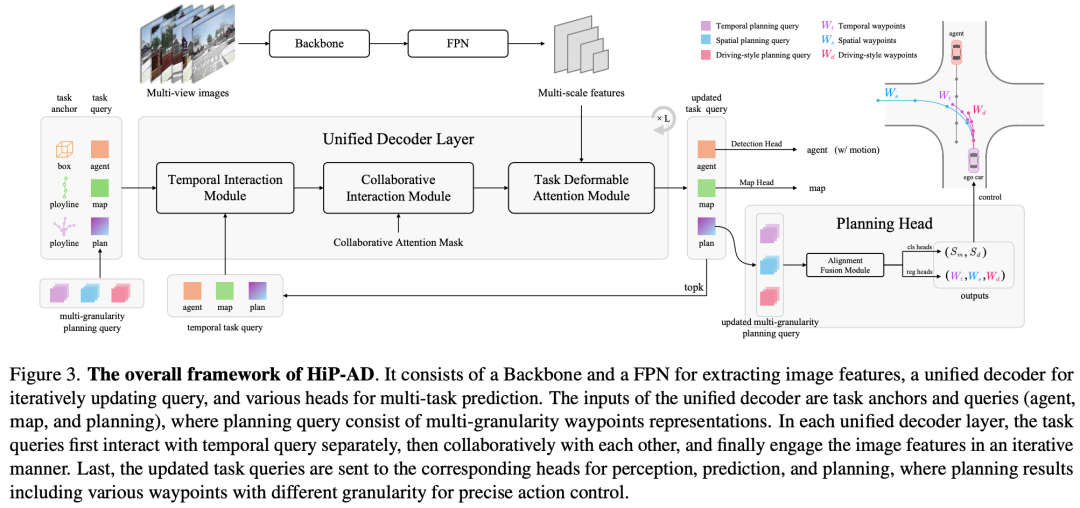
尽管端到端自动驾驶(E2E-AD)技术近年来取得了重大进展,但闭环评估的性能仍然不尽如人意。在查询设计和交互中利用规划的潜力尚未得到充分探索。本文介绍了一种多粒度规划查询表示方法,该方法集成了各种采样模式下的异构航路点,包括空间、时间和驾驶风格的航路点。它为轨迹预测提供了额外的监督,增强了自我车辆的精确闭环控制。此外,我们明确利用规划轨迹的几何特性,使用可变形注意力基于物理位置有效地检索相关图像特征。通过结合这些策略,我们提出了一种新的端到端自动驾驶框架,称为HiP AD,它在统一的解码器中同时执行感知、预测和规划。HiP AD通过允许规划查询与BEV空间中的感知查询迭代交互,同时从透视图中动态提取图像特征,实现了全面的交互。实验证明,HiP AD在闭环基准Bench2Drive上的表现优于所有现有的端到端自动驾驶方法,并在真实世界的数据集nuScenes上取得了有竞争力的性能。
❝TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
论文链接:https://arxiv.org/abs/2505.09315
核心贡献点:NAVSIM的新SOTA!自动驾驶中基于解耦多模态表示的端到端轨迹生成
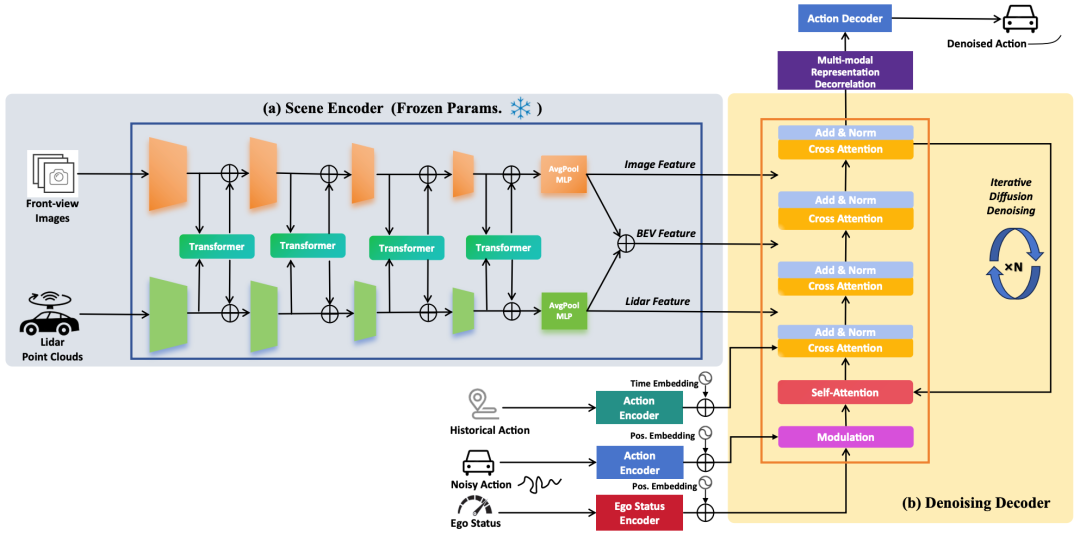
近年来,扩散模型在从视觉生成到语言建模的各个领域都显示出了它的潜力。将其功能转移到现代自动驾驶系统也已成为一种有前景的方法。在这项工作中,我们提出了TransDiffuser,这是一种基于编码器-解码器的端到端自动驾驶生成轨迹规划模型。编码的场景信息用作去噪解码器的多模态条件输入。为了解决生成高质量多样化轨迹时的模式崩溃困境,我们在训练过程中引入了一种简单而有效的多模式表示去相关优化机制。该方法在NAVSIM基准上实现了94.85的PDMS,超越了以前没有任何基于锚点的先验轨迹的最先进方法。
❝Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2501.08861
核心贡献点:该框架验证了视觉语言模型(VLM)与生成式规划结合的可能性;通过语言指令引导增强无地图场景泛化能力,为高鲁棒性自动驾驶规划提供了新范式。
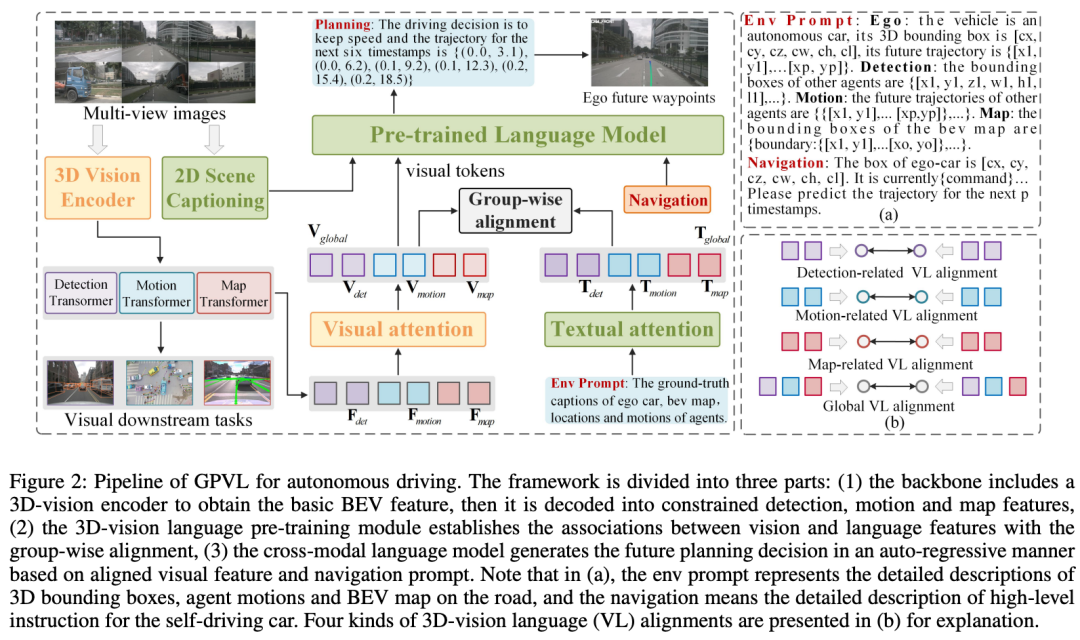
自动驾驶是一项具有挑战性的任务,需要感知和理解周围环境以进行安全的轨迹规划。虽然现有的基于视觉的端到端模型已经取得了可喜的成果,但这些方法仍然面临着视觉理解、决策推理和场景泛化的挑战。为了解决这些问题,提出了一种用于端到端自动驾驶的具有3D视觉语言预训练模型的生成式规划GPVL。所提出的范式有两个重要方面。一方面,设计了一个3D视觉语言预训练模块,以弥合鸟瞰图中视觉感知和语言理解之间的差距。另一方面,引入了一种跨模态语言模型,以自回归的方式生成具有感知和导航信息的整体驾驶决策和细粒度轨迹。在具有挑战性的nuScenes数据集上的实验表明,与最先进的方法相比,所提出的方案取得了优异的性能。此外,所提出的GPVL在处理各种场景中的高级命令时具有很强的泛化能力和实时潜力。人们相信,GPVL的有效、稳健和高效性能对于未来自动驾驶系统的实际应用至关重要。
❝DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
论文链接:https://arxiv.org/abs/2411.15139
代码链接:https://github.com/hustvl/DiffusionDrive
核心贡献点:首次在端到端自动驾驶中引入扩散模型,有效解决了扩散模型在动态开放场景中的模式坍缩(Mode Collapse)和高计算成本问题,为构建高效、鲁棒的多模态自动驾驶规划提供了新思路。
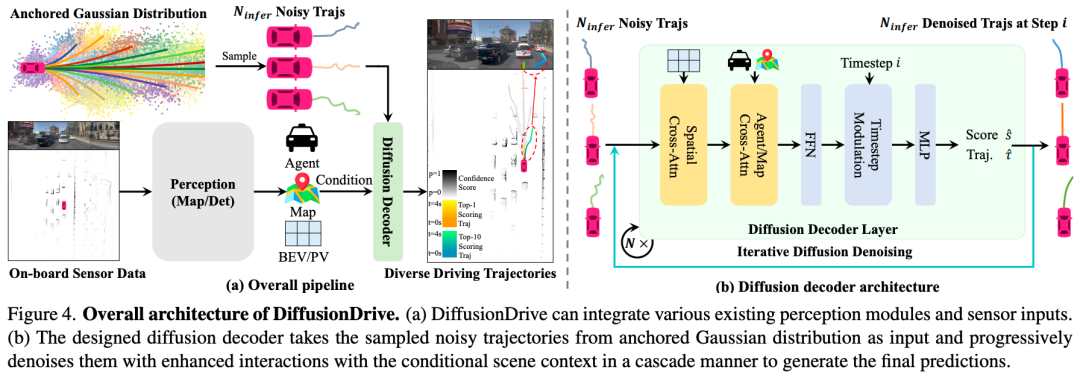
扩散模型已经成为一种强大的机器人策略学习生成技术,能够对多模式动作分布进行建模。利用其端到端自动驾驶能力是一个有前景的方向。然而,机器人扩散策略中的众多去噪步骤以及交通场景更动态、更开放的世界性质,对实时生成各种驾驶行为构成了重大挑战。为了应对这些挑战,我们提出了一种新的截断扩散策略,该策略结合了先前的多模式锚点并截断了扩散调度,使模型能够从锚定的高斯分布学习去噪到多模式驾驶动作分布。此外,我们设计了一种高效的级联扩散解码器,用于增强与条件场景上下文的交互。所提出的模型DiffusionDrive与香草扩散策略相比,降噪步骤减少了10倍,仅需2步即可提供卓越的多样性和质量。在面向规划的NAVSIM数据集上,使用对齐的ResNet-34骨干网,DiffusionDrive在NVIDIA 4090上以45 FPS的实时速度运行时,实现了88.1 PDMS的无花哨功能,创下了新纪录。对具有挑战性场景的定性结果进一步证实,DiffusionDrive可以稳健地生成各种合理的驾驶行为。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









