



作者 | 伊风 编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
太震撼了。阿里直接扔了一个王炸!
QwQ-32B,一个参数量如此小的小模型,居然追平了671B的DeepSeek-R1??!
这也太卷了,看看他们给的数据,真的给人看麻了:
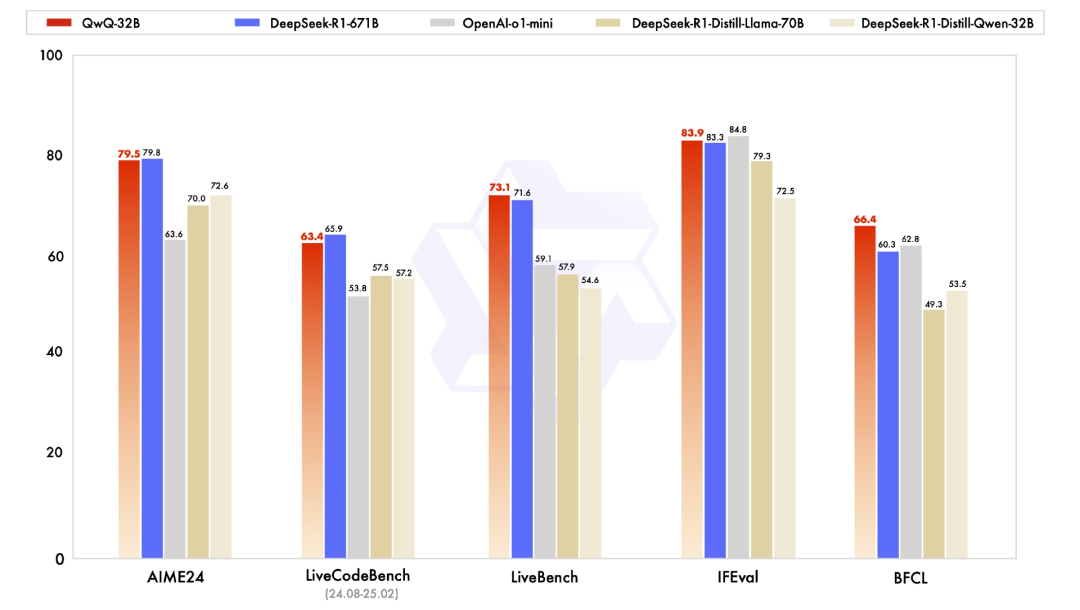
这个模型到底小到什么概念呢?评论区网友在用了一台配置M4 Max芯片的苹果电脑就跑起来了。
网友本人直呼震撼的程度!
这里也推荐下自动驾驶之心打磨的《多模态大模型与自动驾驶实战课程》,通用大模型训练(算法原理&微调&强化学习RLHF)、自动驾驶多模态大模型一栈式全搞定!
拼团大额优惠!欢迎加入学习~

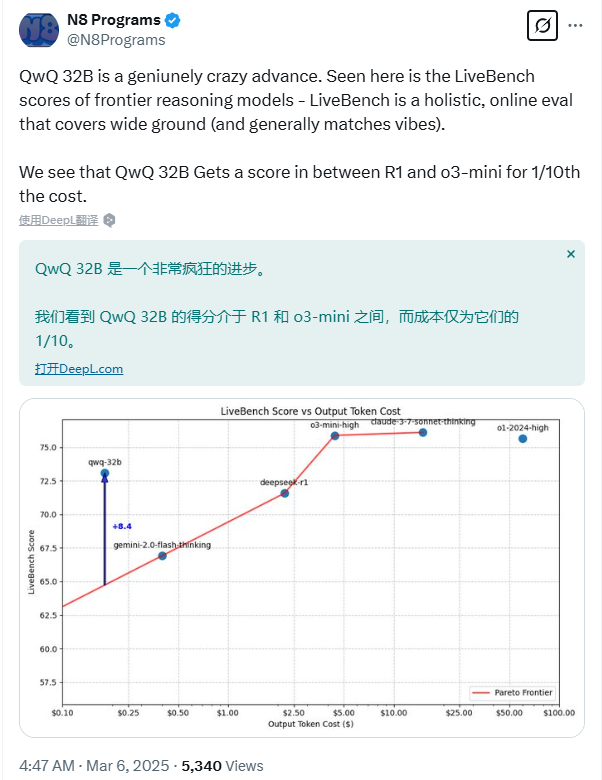
小模型还有个震撼而实用的优点,价格真的低。API成本才R1的十分之一!
一向大方的通义这次又是上线即开源,评论区一看到是Apache 2.0许可证,就开始感谢大自然的馈赠了。这是官方给的一系列链接:
博客:
https://qwenlm.github.io/blog/qwq-32b
HF:
https://huggingface.co/Qwen/QwQ-32B
Qwen 聊天室(网页试用):
https://chat.qwen.ai
模型部署工具ollama也是连夜更新,紧急上线了QwQ-32B,还艾特了通义的两位大佬表示感谢。
有趣的是,追踪到Binyuan Hui的推特,发现他的置顶是一张梗图“Goodbye ChatGPT,Hello Qwen Chat”。

国产大模型完全有底气对ChatGPT说一声再见了。还记得GPT-4.5推出时,那种普遍觉得乏味、失望的氛围,人们越来越认识到,传统的那套训练技术玩的“大力出奇迹”似乎已经走向了尽头。
读了QwQ-32B的博客,我们发现:这次又是强化学习(RL)立大功了!

QwQ-32B的炼成:强化学习还有多少惊喜?
从阿里的技术博客我们能了解到两点:1.强化学习扩展依然是这次性能飞跃的重中之重 2.这个方向还有很长的路能走!
在具体的训练上,通义团队分了两个阶段去做RL训练。
第一阶段,是从冷启动检查点(指模型已经过了冷启动训练阶段,检查点相当于“存档”)开始,实施了一种基于结果奖励的强化学习(RL)扩展方法。
这里有两个突破值得关注:首先,在初期阶段,有特别针对数学和编程任务进行了RL扩展,相当于对强推理比较重要的领域专门“补课”;其次,不同于传统的奖励模型,通义团队采用了一个数学问题的准确性验证器来确保最终解答的正确性,并使用代码执行服务器来评估生成的代码是否能成功通过预定义的测试用例。
然后就看到随着训练的持续,模型性能在数学和编程领域稳定拉升。
第二阶段,是旨在提升通用能力的RL训练。他们在这个过程中,采取的是通用奖励模型的奖励和一些基于规则的验证器。
通义团队说,他们发现:“通过少量步骤的训练,其他一般能力(如指令跟随、人类偏好对齐、智能体性能等)得到了提升,同时数学和编程能力并未出现显著下降。”这句话的分量大家都能懂……大模型训练经常是只能顾一头,没有明显的性能折损大大验证了这个策略的有效性。
通义也在博客写了未来方向:通过这一历程,我们不仅见证了扩展强化学习(RL)的巨大潜力,也认识到了预训练语言模型尚未开发的可能性。
看来新的Scaling Law真的会在后训练阶段了!
 网友实测:本地人工智能时代来临!
网友实测:本地人工智能时代来临!
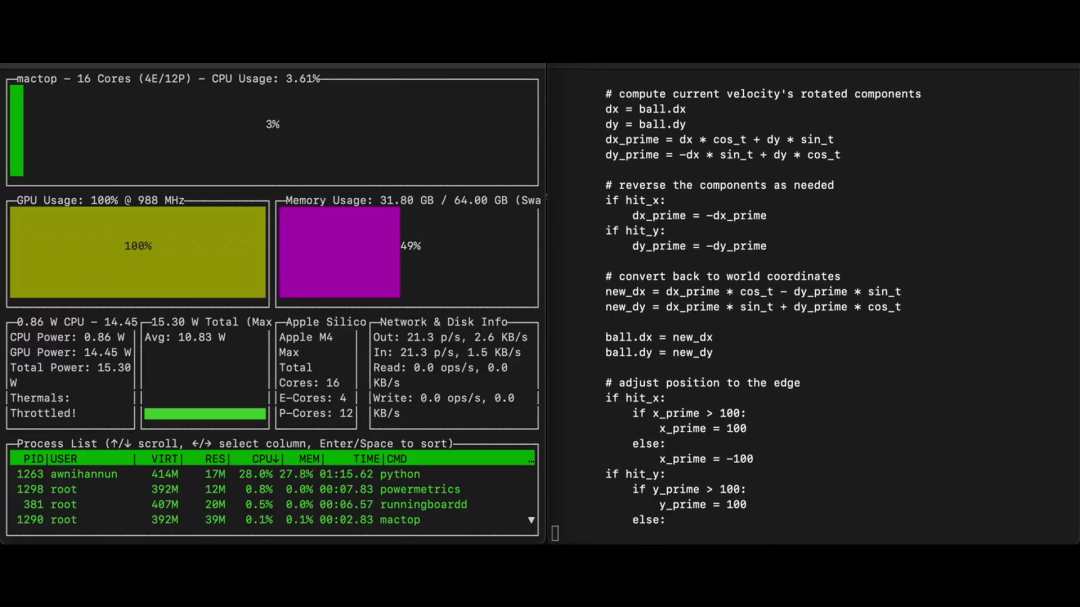
一位进行了实测,发现QwQ-32B 在笔记本电脑上运行得相当丝滑。
在这里,它在装有 MLX 的 M4 Max 上运行良好。它的 8k 代币长思考过程的一个片段:
另一位网友采用本地部署,推断了一个比较复杂的推理题目:
有两座房子,从左到右依次编号为1到2。 每间房子都住着不同的人。 每所房子都有一个独特的属性,分别代表以下特征:每个人都有一个独特的名字:Arnold, Eric;每个人都拥有独特的汽车型号:ford f150, tesla model 3;人们饲养独特的动物:猫、马。
线索:1. 埃里克在拥有特斯拉 Model 3 的人的正前方左边。养马的人在第一间房子里。
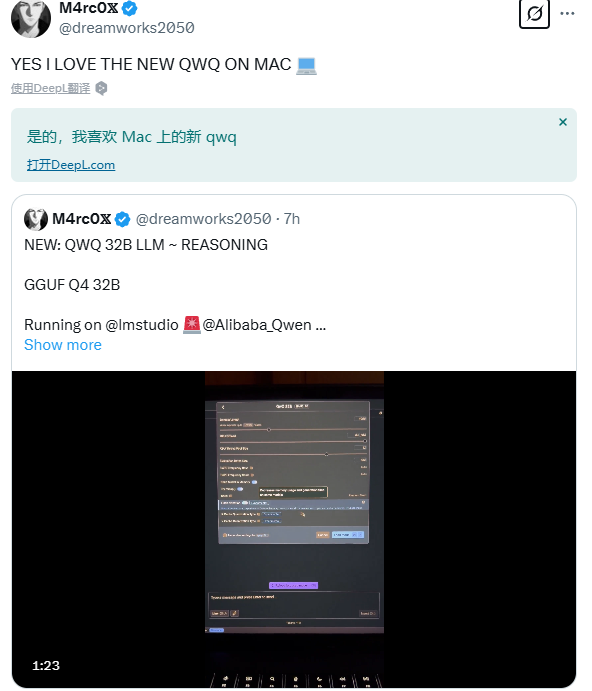
QwQ-32B仅用了40s的思考时间就给出了正确答案。
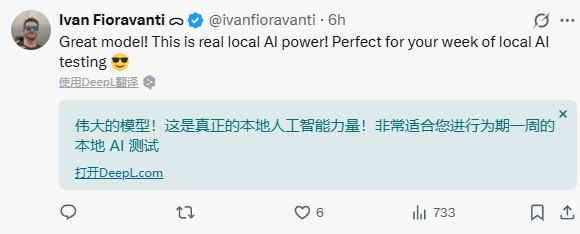
评论区说:这是真正的本地人工智能力量!
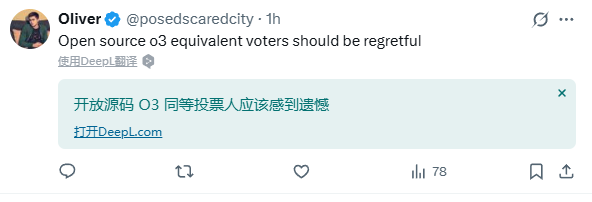
也有人表示:太遗憾了!你们这些人干嘛在奥特曼要开源的时候投票给o3类似模型啊?(另一个选项是手机可跑的端侧模型)
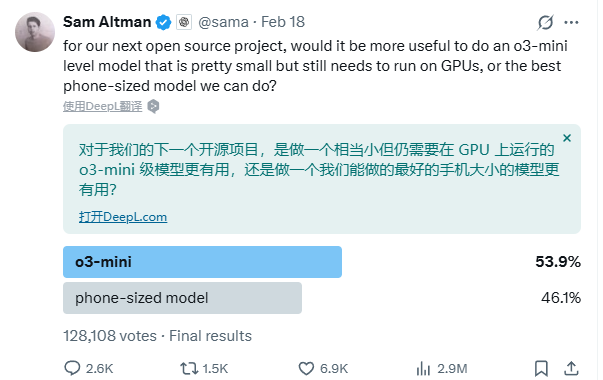
写道这里不得不吐槽一句,OpenAI的开源是真慢啊,预热了一下又没影了。
 写在最后:算力不再成为问题
写在最后:算力不再成为问题
昨天看外媒的报道说,R1带火了消费级显卡,新款游戏芯片RTX 5090被黄牛炒到150%。这是因为DeepSeek的模型不再需要高端AI芯片,普通消费级产品就能满足运行需求。
那么QwQ-32B这波震撼之余,可能带货的就是M4 Max的苹果电脑了。
从最初的庞然大物发展到可以家用,计算机走了几十年的时间。从GPT-3发布后的不到五年中,我们就有了在笔电上能run起来的超强模型。
然后终将有一天,我们会在手机上部署更强悍更轻量的模型。
就像一位网友所说:
哦,我的天哪,现在每个人都会在接下来的两周里讨论QwQ-32B,DeepSeek 也会准备好另一个模型,然后 OpenAI 将别无选择,只能推出 ChatGPT 5,在 AGI 之前这一切都不会停止。

① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









