



作者 | 论文推土机 编辑 | 自动驾驶Daily
原文链接:https://zhuanlan.zhihu.com/p/15333349697
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Zheng, Y., Xia, Z., Zhang, Q., Zhang, T., Lu, B., Huo, X., ... & Zhao, D. (2024). Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving.arXiv preprint arXiv:2412.02689. 主要回答了三个问题:
Is there a data scaling law in the field of end-to-end autonomous driving?
How does data quantity influence model performance when scaling training data?
Can data scaling endow autonomous driving cars with the generalization to new scenarios and actions?
答案是:
A power-law data scaling law in open-loop metric but different in closed-loop metric.
Data distribution plays a key role in the data scaling law of end-to-end autonomous driving.
The data scaling law endows the model with combinatorial generalization, which powers the model's zero-shot ability for new scenarios.
通过实验证明,本文证明了log-log scaling law存在,数据分布对模型训练结果有影响。scaling law能够提升模型的泛化能力。
文章的模型结构如下:
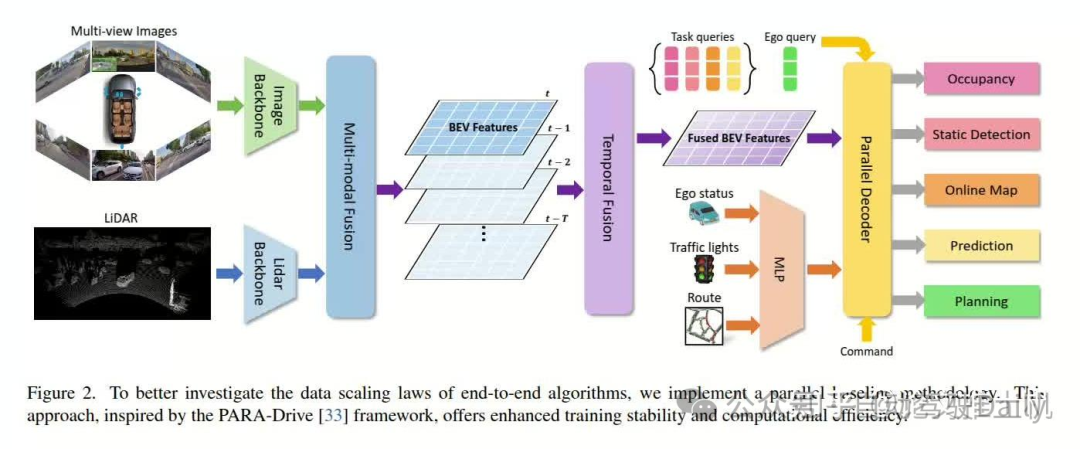
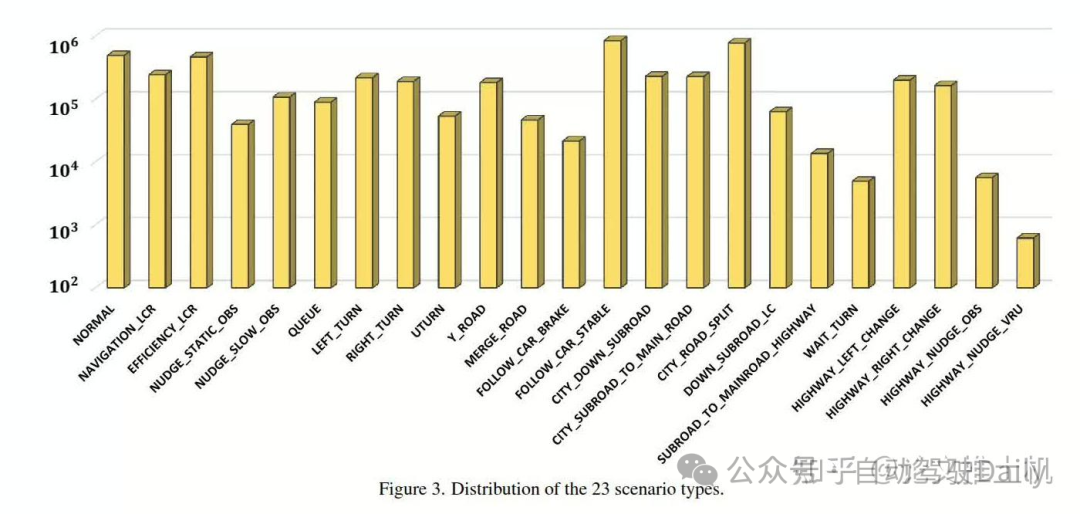
然后把数据分成了23类:
模型结构非常简约, 如图中所示,就不多说了。最后的loss是:
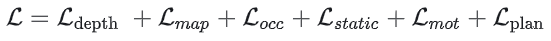
planning的ego query用于预测自车trajectory:“Then the queries are used to predict multi-modal future planning trajectories with corresponding scores.”其中planniing score是:
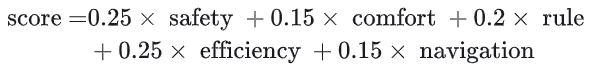
主要看看实验结果。
power law: 无论是开环测试还是闭环测试,都存在power law曲线,本文的线性曲线是xy轴都取了log的。从open loop的测试结果来看,随着数据增长,关系保持线性。
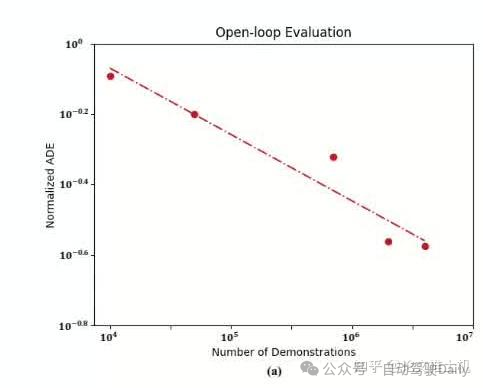
但是在close loop测试中,线性关系在2 million数据之后发生变化:
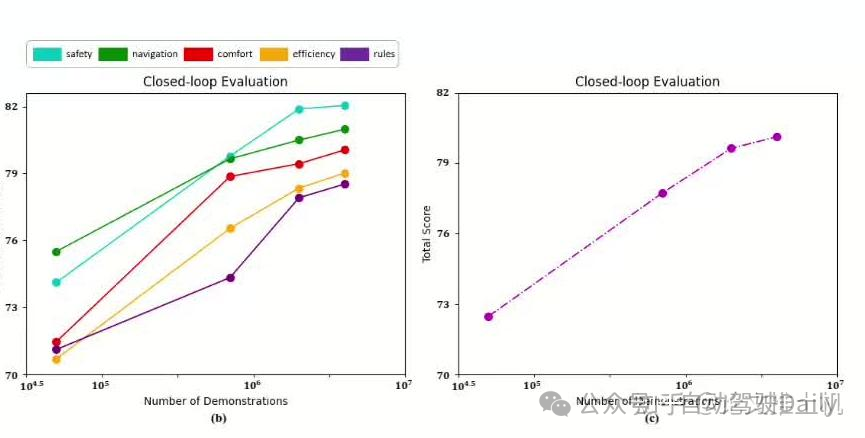
可以看到,各个指标得分虽然随数据增长score仍然在提升,但是到达某个阈值之后,线性曲线增长变慢:“about 2 million training demonstrations), the growth rate decelerates as data continues to expand”。
然后看下data quality和系统表现之间的关系,这里挑出了两组场景DOWN SUBROAD LC and SUBROAD TO MAINROAD HIGHWAY作为测试场景,这两个场景的系统表现比较差,所以文章将他们作为测试集来看随着数据增加,系统表现在这两个场景下的表现是否发生变化:结论是有变化。随着数据增加,这两个场景的系统表现也在提升:“The results reveal that for these long-tailed scenarios, doubling the specific training data while keeping the total data volume constant led to improvements in planning performance”。当数据干到原来的四倍的时候,效果有点明显:“Furthermore, quadrupling the specific training data yielded even more substantial gains, with performance improvements between 22.8% and 32.9%.”
然后再来看泛化能力,这里提出来两个场景的数据不用于训练,来看系统在没有见过的场景下的表现能力,为了能有更好的对比,我们再找出来一些类似的场景放在一起看看:
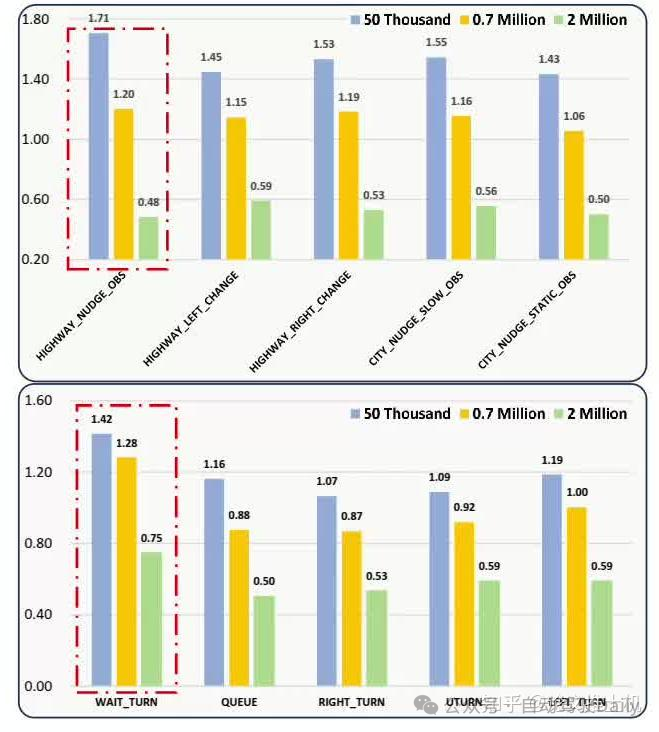
可以看到,在没有见过的数据集上面,所致额数据提升,系统表现也在提升,在类似的场景的数据集上系统表现的变化也是和数据相关的。然后还有一个有趣的现象,文章还发现,通过某些单一场景的训练,系统还学到了额外的泛化能力,他能在单一场景的组合表达的场景中提升系统表现:“By learning high-speed driving and low-speed nudging obstacles separately from the training data, the model acquired the ability to generalize to high-speed HIGHWAY NUDGE OBS scenarios; through learning to turn and queuing at red lights, the model developed the capability to generalize to WAIT TURN scenarios”。但是呢,其实这里的结论还是存在一定前提得,网络的设计和任务的定义也会在很大程度上影响着数据对网络的提升效果,如果网络设计不合理,或者参数量有限,能够存储的信息也就有限,所以也不一定能学到特别好的泛化能力。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









