 Ollama大模型部署工具安装与使用指南
Ollama大模型部署工具安装与使用指南





Ollama 是一个开源的本地大语言模型(LLM)运行框架,允许用户在自己的计算机上轻松部署和运行各种大型语言模型,如 LLaMA、Mistral 等。它支持多种操作系统,包括 Windows、macOS 和 Linux,并提供了命令行界面和 REST API 接口;接下来我们就来尝试本地安装并部署一下大模型;
一、安装
1.1 系统要求
- 硬件:建议至少8GB内存,40GB以上磁盘空间(推荐SSD),对于GPU加速建议NVIDIA显卡,显存至少8GB;
- 软件:
- Windows 10或更新版本(64位)
- macOS 10.15或更新版本
- Ubuntu 20.04+ 或其他Linux发行版
- CUDA Toolkit(如果需要GPU支持)
1.2 下载安装包
登陆Ollama官网,选择对应系统的安装包下载,Mac和Windows按照提示安装即可,Linux在终端执行官网提供的指令;
安装完毕后在终端执行如下指令查看版本号,出现版本号表示安装成功;
# 查看版本号
ollama --version二、运行
2.1 启动
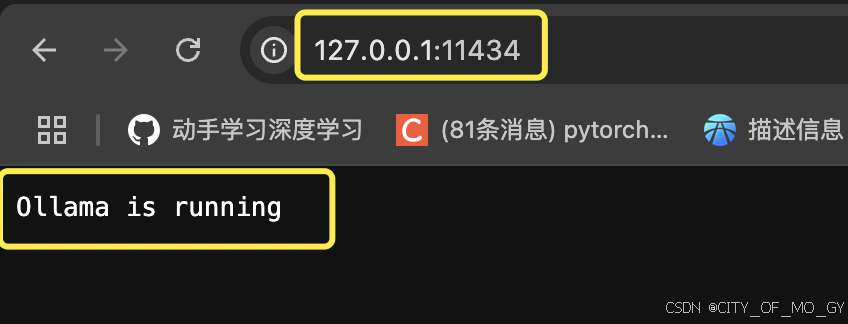
终端输入下面指令启动Ollama;
ollama serve到浏览器访问 ‘127.0.0.1:11434’ ,如果页面出现 ‘Ollama is running’表示启动成功;
2.2 拉取模型
在终端通过下面命令拉取模型,具体模型名称及版本号可以到Ollama官方的模型库寻找;
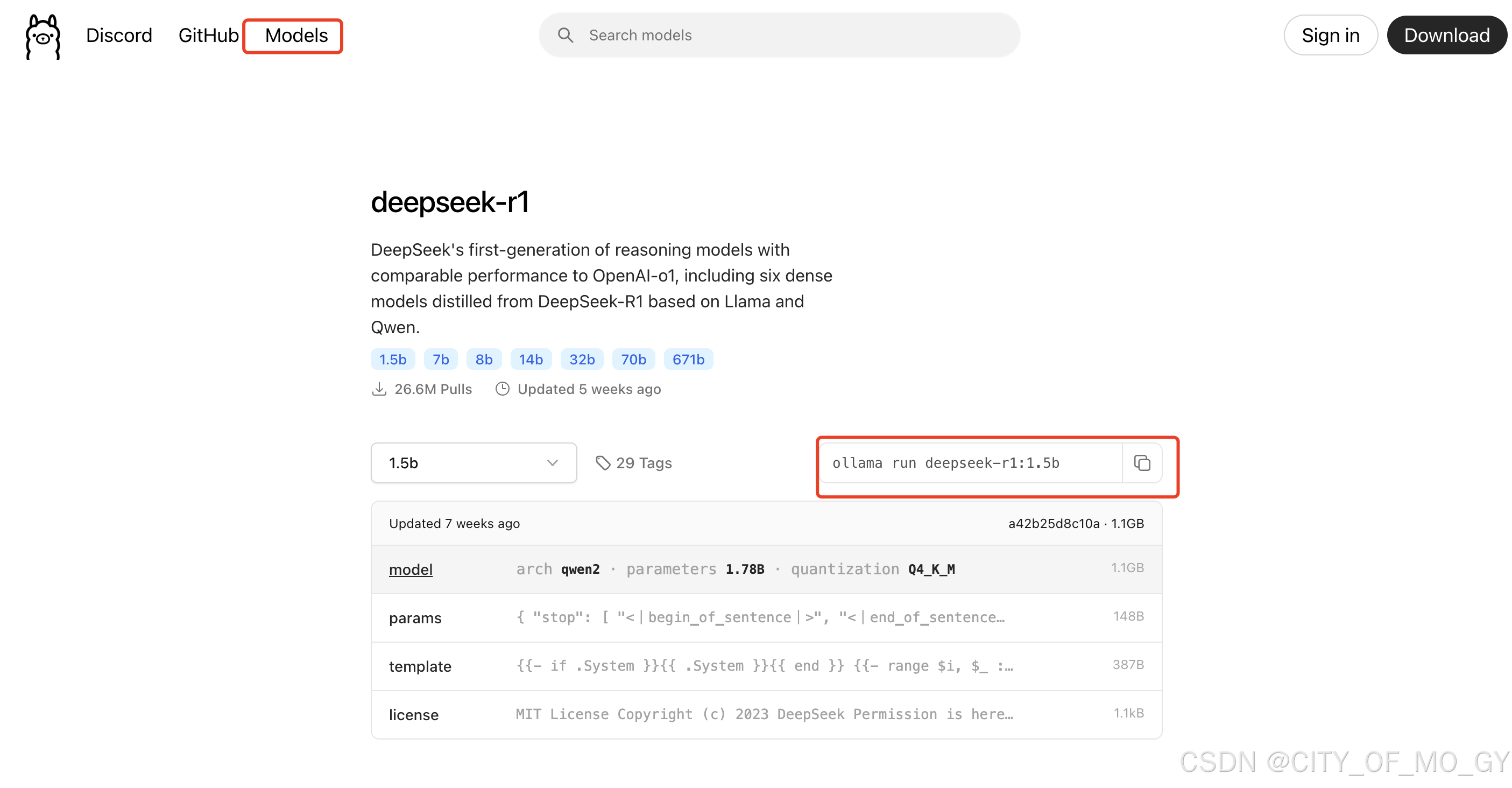
# 以deepseek-R1为例
ollama pull deepseek-r1:1.5b2.3 部署大模型
在终端通过如下指令运行大模型:
# 以上面拉取的deepseek-R1为例
ollama run deepseek-r1:1.5b在终端输入你的问题,就可以简单实现与大模型的对话了;

2.4 自定义模型加载
通过PULL命令只可以拉取官方商城维护的预训练模型,如果我们通过LLaMA-Factory等工具微调了一个垂类大模型,想通过Ollama来部署,该如何操作呢?
2.4.1 创建Modelfile
首先,我们需要创建一个Modelfile文件,在这个文件中,我们需要指定包含safetensors模型权重的文件夹的绝对路径,具体内容如下:
# Modelfile
FROM /path/to/safetensors/directory2.4.2 创建模型
紧接着在Modelfile同级目录运行如下命令来创建模型,myself-model为创建的模型的名字,可以自由定义:
ollama create myself-model 2.4.3 运行模型
通过如下命令可以查看创建的模型是否已经存在;
ollama list如果在模型列表中看到有自己创建的模型,就可以像运行上面模型一样来运行自定义模型:
ollama run myself-model:latest2.5 其他常用命令
| 命令 | 作用 |
| ollama rm model_name | 删除列表加载的模型 |
| ollama cp model1 model2 | 复制现有模型model1命名为model2 |
| ollama show model_name | 展示模型的详细信息 |
| ollama ps | 列出当前加载的模型 |
| ollama stop model_name | 关闭指定模型 |
三、模型调用
通过‘ollama serve’命令就可以开启Ollama服务,上面介绍了通过CLI(命令行界面)访问Ollama服务,但其实Ollama还支持多种形式的访问,例如通过API,或者通过python脚本访问等,这里我们简单列举一下如何通过API和python的方式进行模型调用;
3.1 API调用
前面通过‘ollama serve’命令开启Ollama服务后,Ollama会同时对外提供一个11434的本地访问端口,下面我们使用curl命令进行模型调用;
在本地电脑新打开一个终端,输入下面的命令,即可访问指定模型:
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:1.5b",
"prompt":"请介绍你自己!"
}'注意:
1)http请求中的localhost是本地回环地址,即127.0.0.1;
2)11434是Ollama默认端口号;
3)api/generate是服务端对应功能的路由;
4)-d后面的字符串是访问的请求数据,包含模型名称以及提示词;
3.2 python调用
Ollama同时也提供了pythonAPI的第三方安装包,通过编写python脚本即可调用;
# 安装ollama python安装包
pip install ollama创建一个python脚本:
import ollama
resp = ollama.chat(model="deepseek-r1:1.5b",
messages=[{"role":"user","content":"请介绍一下你自己!"}])
print(resp["message"]["content"]) 四、Open-WebUI
上述介绍了Ollama工具的简单使用以及常用的命令,目前已有很多webUI开源工具支持对Ollama的界面化调用,其中使用最多的就是Open-WebUI,接下来我们就介绍如何安装open-webUI,通过open-webUI来调用通过Ollama本地部署的大模型;
4.1 安装open-webui
安装open-webui非常的简单方便,可以安装python版本,也可以通过docker进行部署;这里我们通过pip安装python版本;需要注意的一点是python解释器的版本必须是3.11,我使用的是3.11.11版本,可供参考;
pip install open-webui4.2 启动open-webui
安装完成后,通过下面命令就可以直接启动,默认端口号8080;
open-webui serve
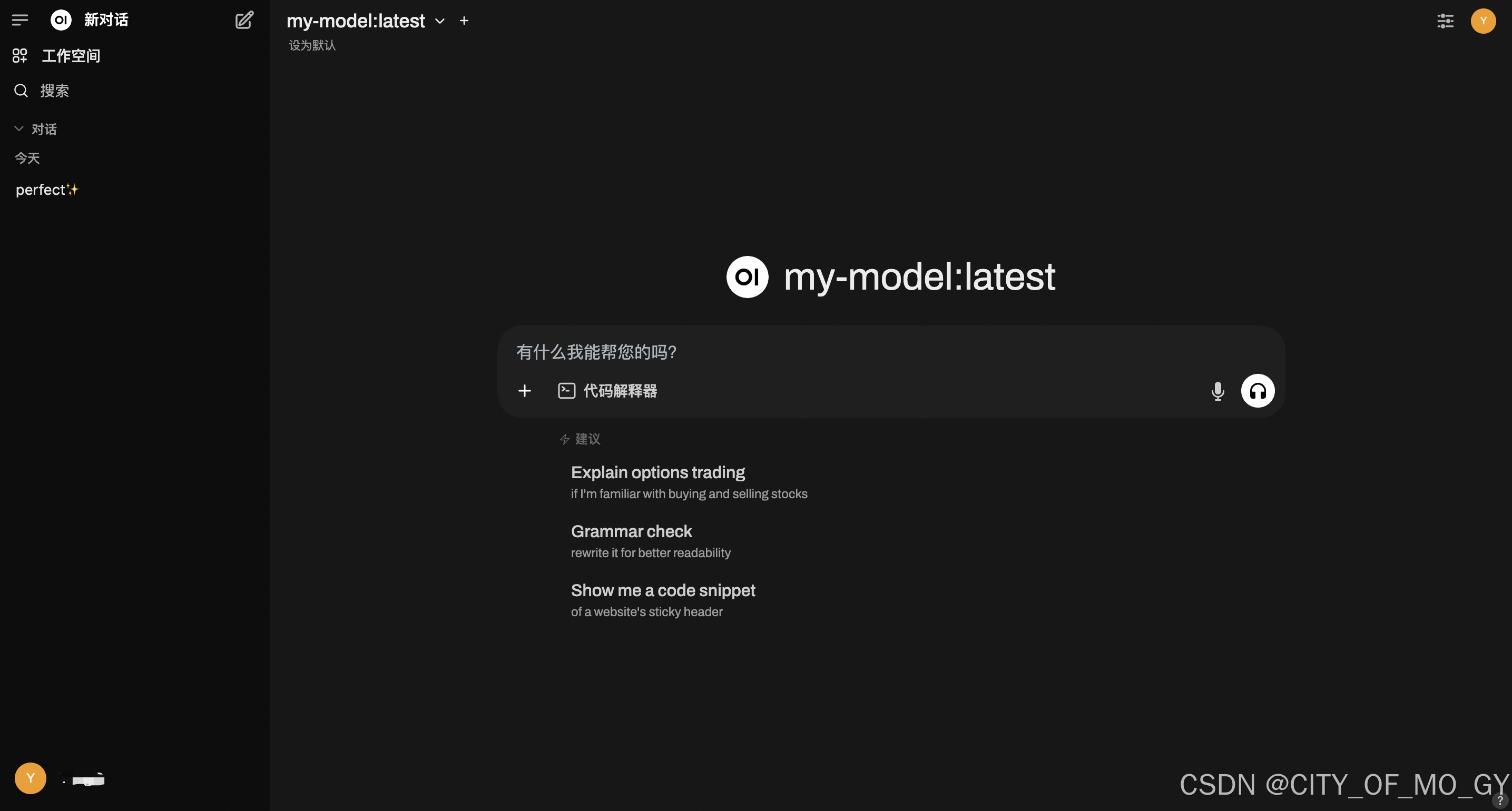
本地通过浏览器访问‘http://0.0.0.0:8080’,第一次登陆需要注册账号(账号管理在本地),第一个注册的用户为管理员,进去之后即可看到如下界面;
4.3 连接本地Ollama
点击左下角用户图标,选择‘管理员面板’;
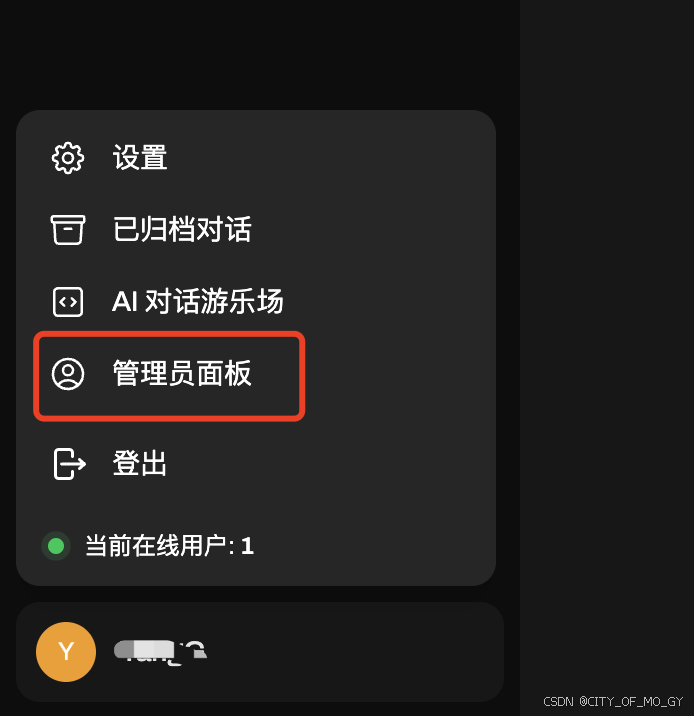
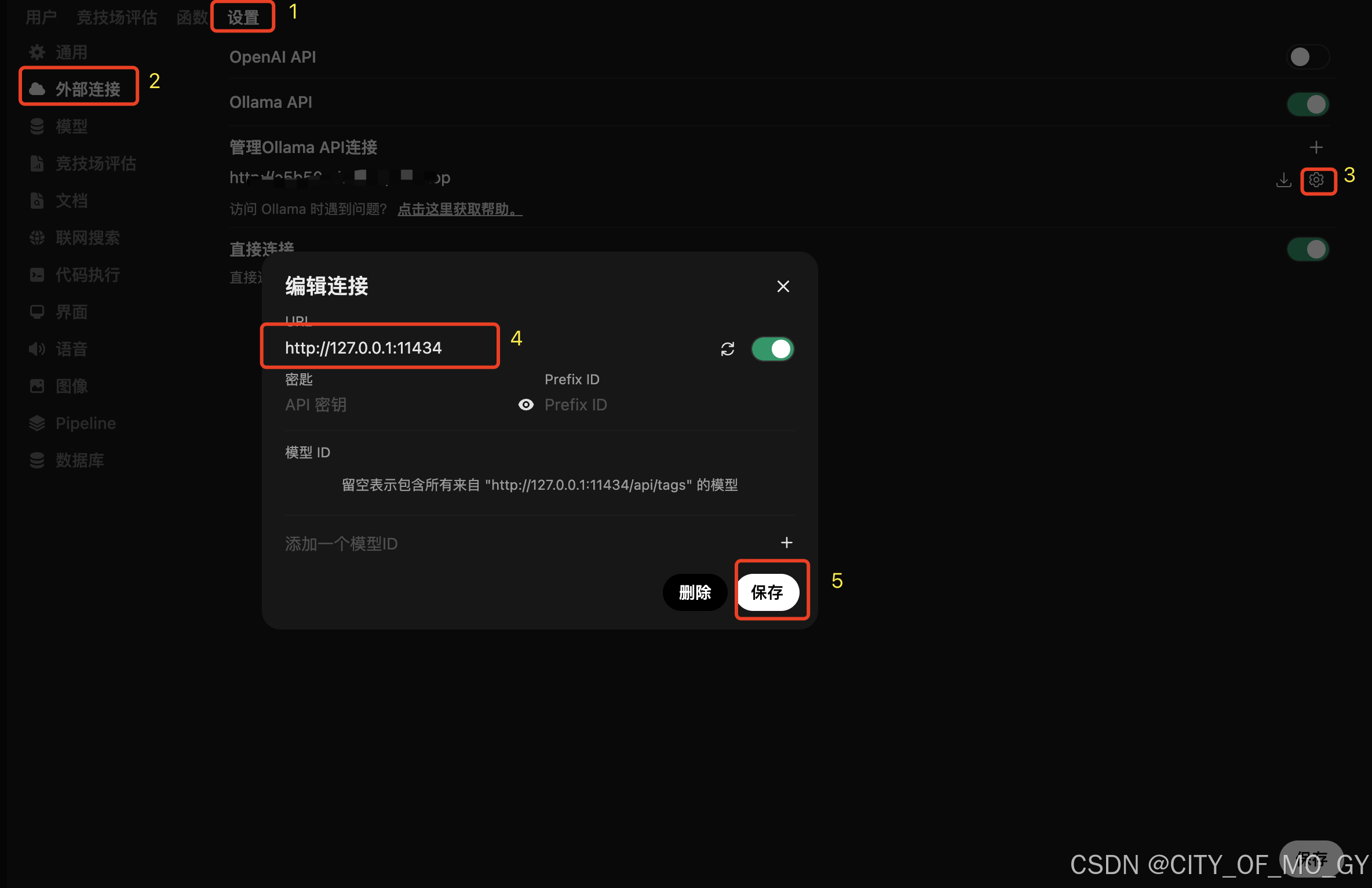
依次点击设置——外部连接——设置图标,修改URL为本地Ollama的API请求链接,点击保存;
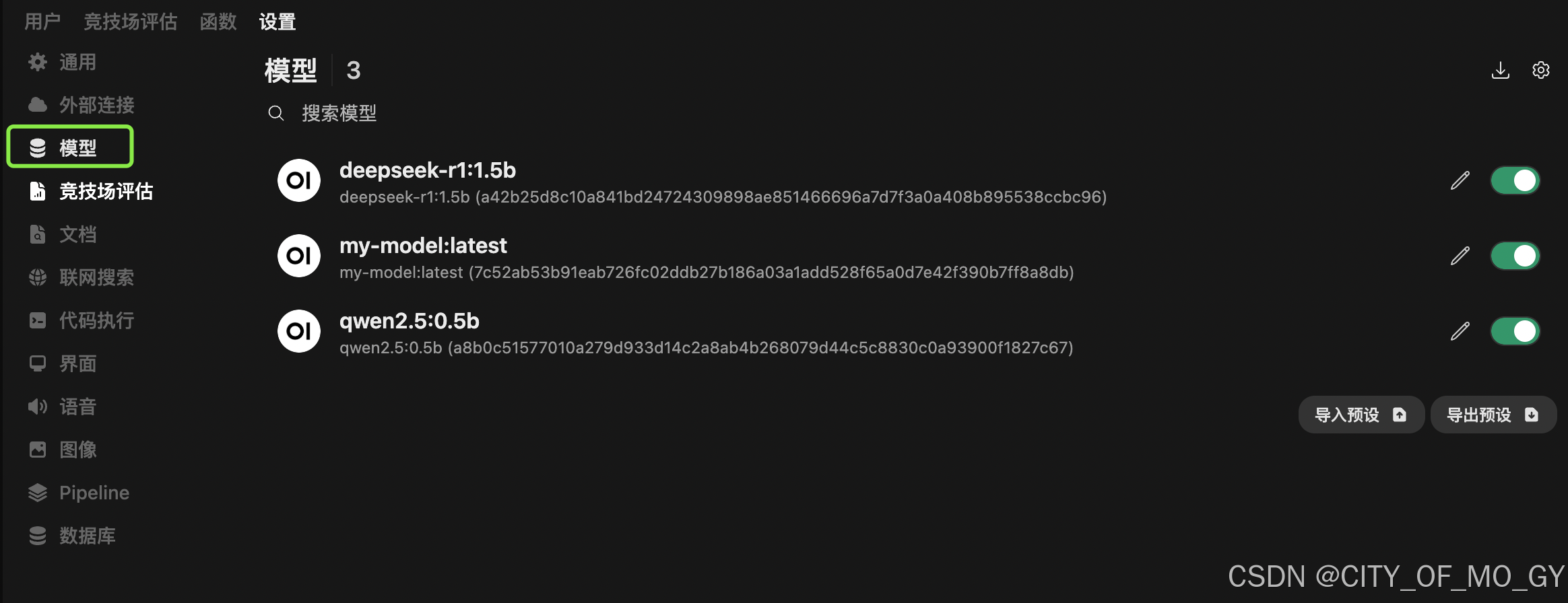
 点击模型,就会在界面上显示出来本地pull的模型列表,即CLI输入ollama list返回的模型列表;
点击模型,就会在界面上显示出来本地pull的模型列表,即CLI输入ollama list返回的模型列表;
4.4 模型调用
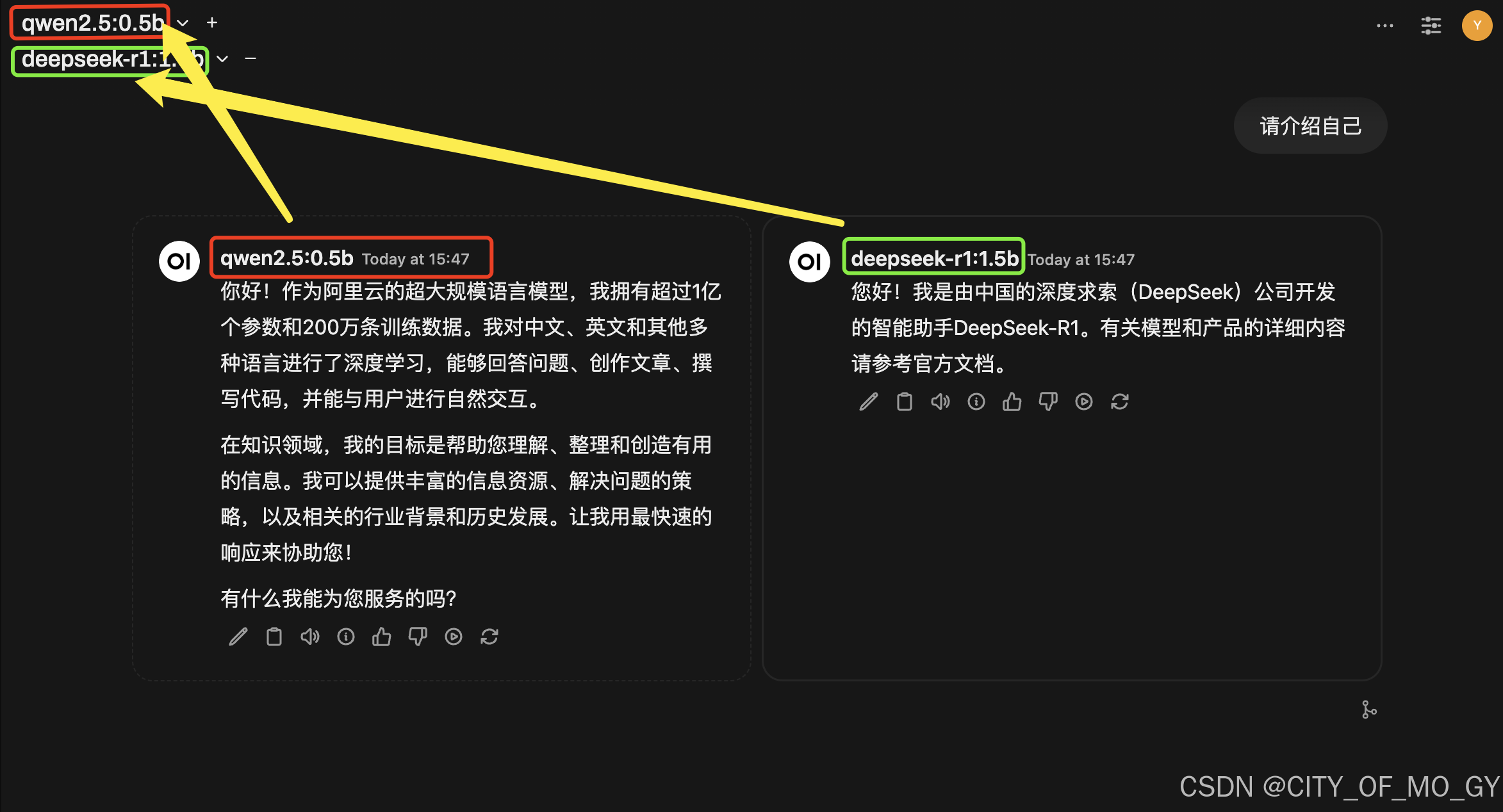
点击左上角‘新对话’,点击向下的箭头,选择要调用的模型;
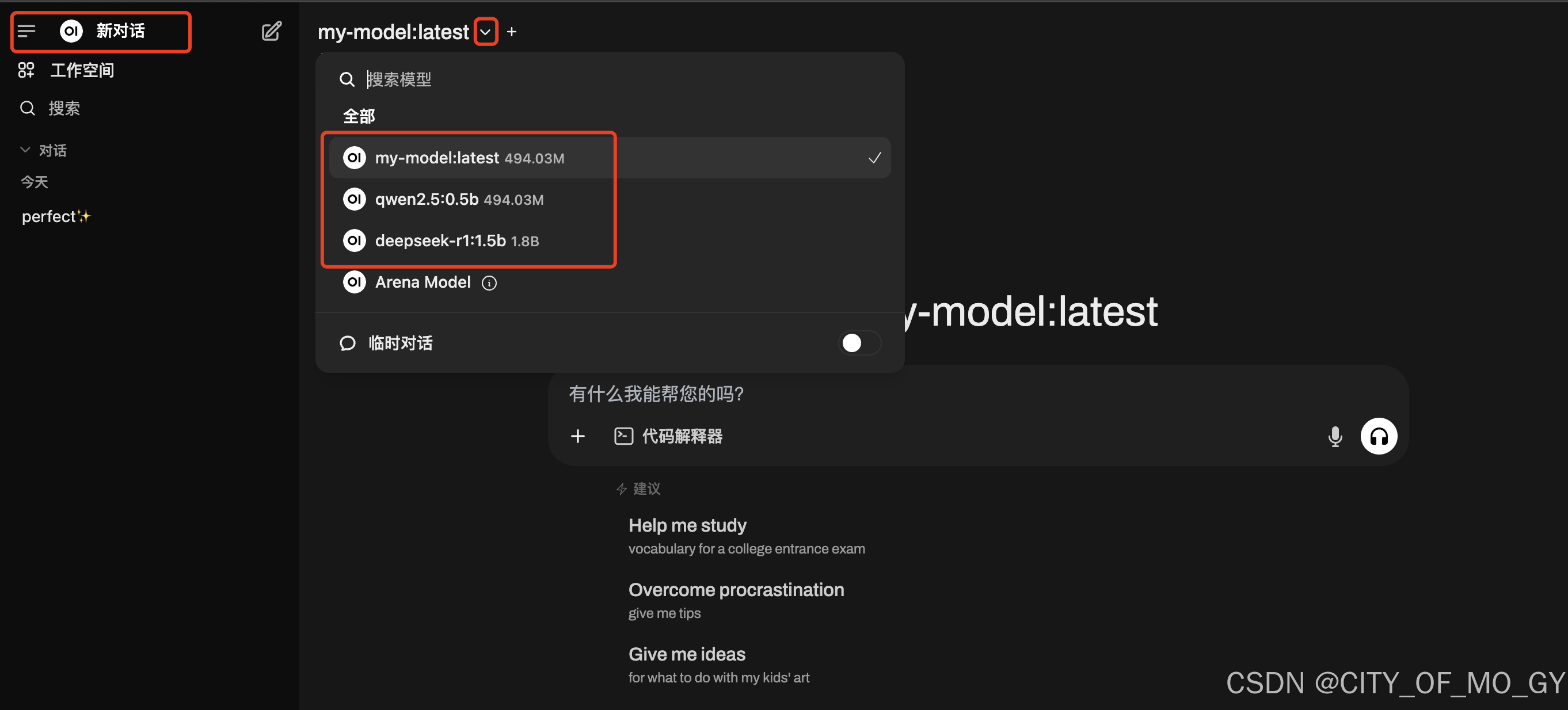
PS:点击后面的“+”可以多个不同模型进行同时推理,进行输出结果对比;


















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









