




说在前面
接下来几节是基于吴恩达的《LangChain Chat with Your Data》课程的学习笔记。该系列课程是《LangChain for LLM Application Development》的进阶版本,将深入拓展 LangChain 提供的个人数据访问能力,指导开发者如何使用 LangChain 开发能够访问用户个人数据、提供个性化服务的大模型应用。
本节将讲解文档加载(Document Loading)。为了与你的数据对话,首先需要使用 LangChain 文档加载器把非结构化的数据处理为标准格式。LangChain 提供80+种文档加载器,可以从不同的数据源(网站、数据库、YouTube等)加载数据,将数据转换为PDF、CSV、HTML等不同格式。
Main Content
未来创建一个可以与你的数据LLM应用,你首先需要将数据加载成可以处理的格式。LangChain 中的文档加载器(Document Loader)的任务就是这个。LangChain 中提供了80多种文档加载器,下面将介绍几种重要的加载器。
文档加载器(Document Loader)的功能是将各种数据源加载到一个标准文档对象中(各种类型的文件,各种来源的文件)。
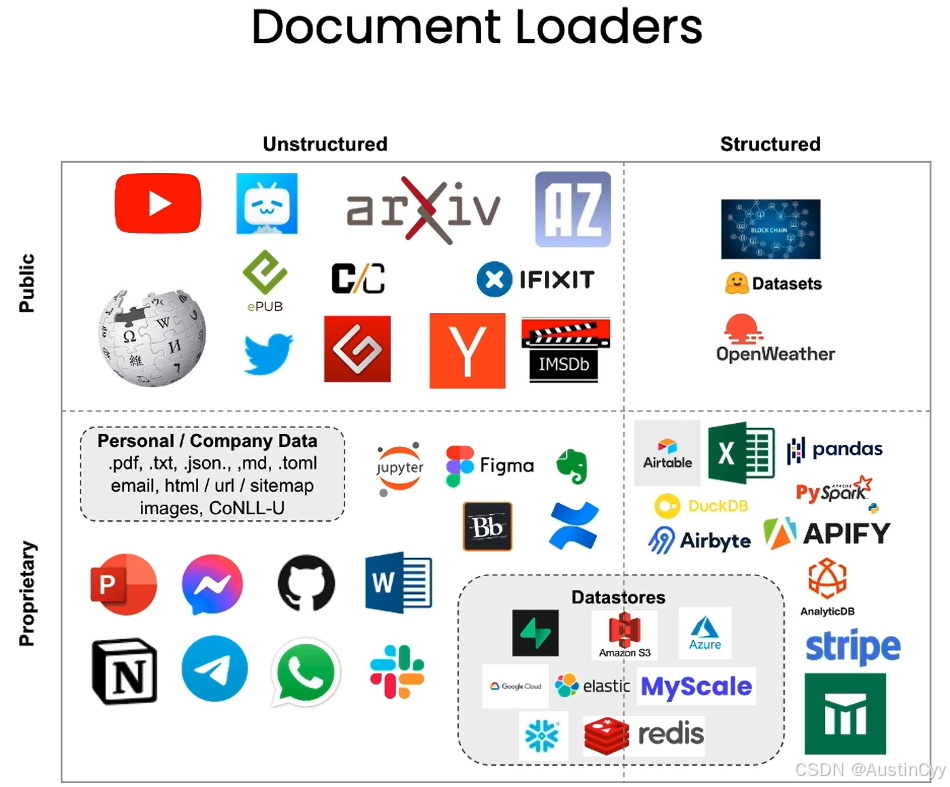
下面是文档加载器的大致分类。
前置工作
导入环境变量。
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
加载PDF文件使用文档加载器 PyPDFLoader。
1.使用 PyPDFLoader 加载 pdf 文件。
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf")
pages = loader.load()
注: PyPDFLoader 按页加载,每一页都是一个 Document,包含文本(page_content)和元数据(metadata)。
2.显示pages 的长度,即PDF的页数。为22.
len(pages)

3.提取 pages[0] 这一页,然后打印其部分文本内容。
page = pages[0]
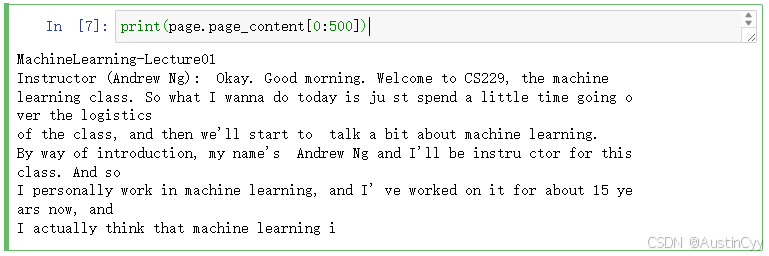
print(page.page_content[0:500])
4.打印其元数据。说明了其来源(source)和对应的页码(page)。
page.metadata

YouTube
LangChain可以读取YouTube视频,使用OpenAI Whisper模型将视频转换为文本。
1.导入必须的库 GenericLoader,FileSystemBlobLoader,OpenAIWhisperParser,YoutubeAudioLoader。
from langchain.document_loaders.generic import GenericLoader, FileSystemBlobLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
2.加载YouTube的视频,并转换为文本。
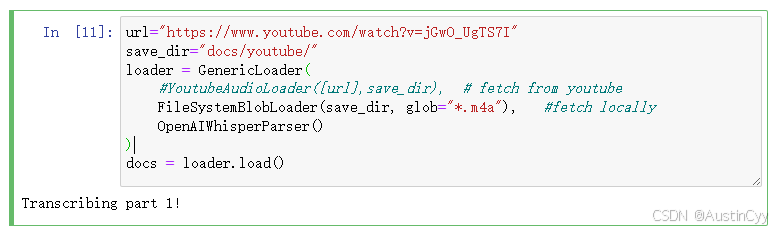
url="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
#YoutubeAudioLoader([url],save_dir), # fetch from youtube
FileSystemBlobLoader(save_dir, glob="*.m4a"), #fetch locally
OpenAIWhisperParser()
)
docs = loader.load()
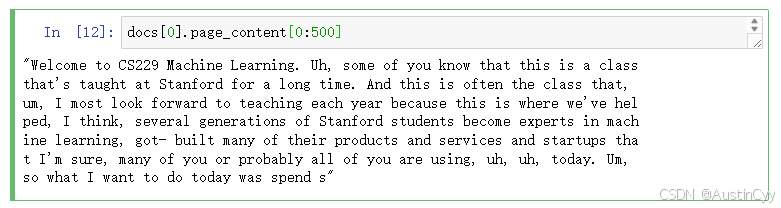
3.打印加载的文件的部分内容。可以看到已成功的转换为文本。
docs[0].page_content[0:500]
URLs
WebBaseLoader 可以使用URL直接抓取页面的内容。
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/titles-for-programmers.md")
docs = loader.load()
print(docs[0].page_content[:500])
抓取的内容如下所示,可以看出来里面有很多的空格和换行,这说明了我们进一步对文档的格式化的意义。
handbook/titles-for-programmers.md at master · basecamp/handbook · GitHub
Skip to content
Navigation Menu
Toggle navigation
Sign in
Product
GitHub Copilot
Write better code with AI
Security
Find and fix vulnerabilities
Actions
Automa
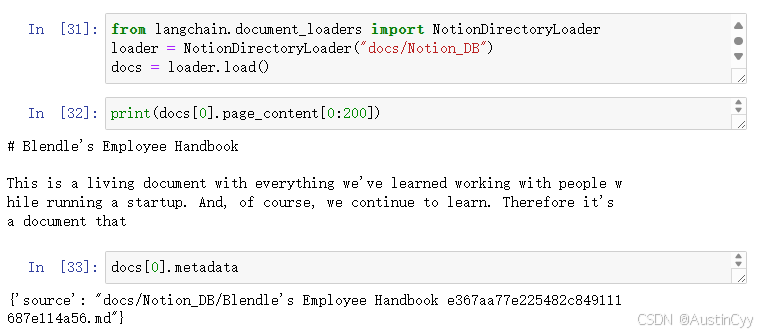
Notion
Notion 是一个数据库,我们可以使用 NotionDirectoryLoader,来加载我们存储在Notion上的数据来构建LLM应用。
from langchain.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("docs/Notion_DB")
docs = loader.load()
总结
本节介绍了几种类型的数据加载器,可以看到可以很方便的加载各种形式的数据,但是LangChain一共有80+种不同的加载器,我们在实践过程中要根据需要进行选择。

















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









