




论文信息
论文标题: An Empathy-Based Sandbox Approach to Bridge the Privacy Gap among Attitudes, Goals, Knowledge, and Behaviors - CHI 2024
论文作者: Chaoran Chen et .al - Notre Dame
论文链接: https://dl.acm.org/doi/10.1145/3613904.3642363
研究领域: privacy awareness, privacy intervention, sandbox, generated personas
研究背景
该研究旨在解决 隐私态度-行为差距(Privacy Attitude-Behavior Gap) 这一挑战,即用户在保护个人数据方面的态度与实际行为之间存在不一致性 。
作者认为,弥合这一差距面临两大主要障碍:
- 系统不透明性(System Opaqueness): 系统提供的信息不对称(asymmetric information),使得用户难以理解数据被收集的种类以及第三方如何使用这些数据,从而无法做出知情的隐私决策 。
- 用户顾虑(User Hesitation): 用户害怕在不透明的系统中尝试不同的隐私设置会导致意外的数据泄露,这种恐惧心理进一步阻碍了他们进行实验和学习,反而强化了系统的不透明性 。
现有的隐私干预方法(如隐私教育和数字助推)存在局限性:隐私教育耗时长且难以将知识转化为具体行为 ;数字助推(nudging)效果往往是短暂的,不能必然提升用户长期的隐私素养 。
核心方法与贡献
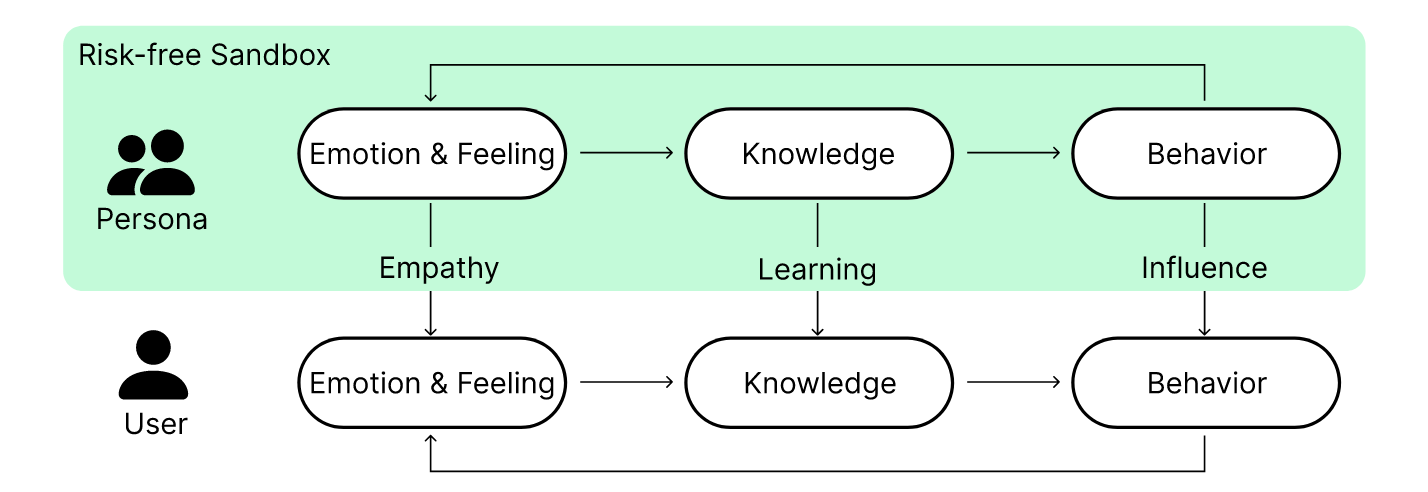
论文提出了基于同理心的沙盒方法(An Empathy-Based Sandbox Approach),其核心是让用户站在 人工生成的人物角色(Artificially Generated Personas)的角度,在一个无风险的沙盒环境(Risk-free Sandbox Environment) 中体验隐私属性如何改变系统结果 。
该方法旨在实现两个关键目标:
- 情感共鸣(Emotional Resonance): 当用户以人物角色身份体验系统结果时,能感受到人物角色可能体验到的情绪(如因隐私侵犯而产生的沮丧或愤怒),从而意识到当自己遇到类似事件时的感受 。
- 知识获取(Knowledge Acquisition): 用户通过体验其隐私行为的后果(如看到个性化广告或受到算法决策影响),能够识别其中的模式,并获得可泛化的知识,从而更直观地理解未来行为可能带来的结果 。
简单来说,即通过沙盒模拟的方式,用户可以通过合成的用户信息进行上网,实现在沙盒环境中隐私保护学习。虽然是模拟行为,但是用户却能够获得真实的情感反馈,并能有效地学习到隐私保护知识以及培养隐私保护意识。这样也就为解决 隐私态度-行为差距(Privacy Attitude-Behavior Gap)提供了一个新的思路。
技术实现与原型
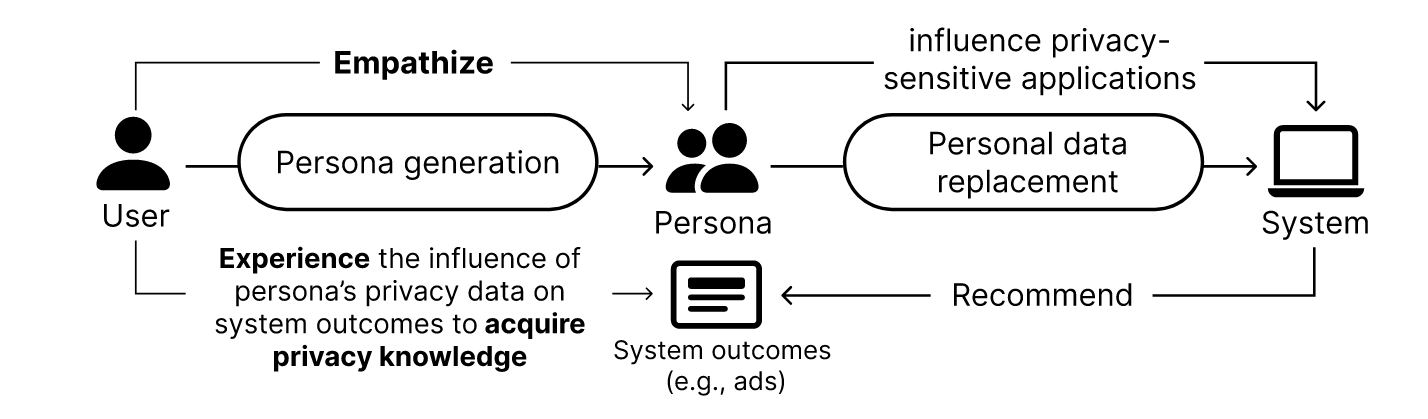
该方法包含两个核心阶段:人物角色生成和个人数据替换。
-
人物角色生成(Persona Generation):
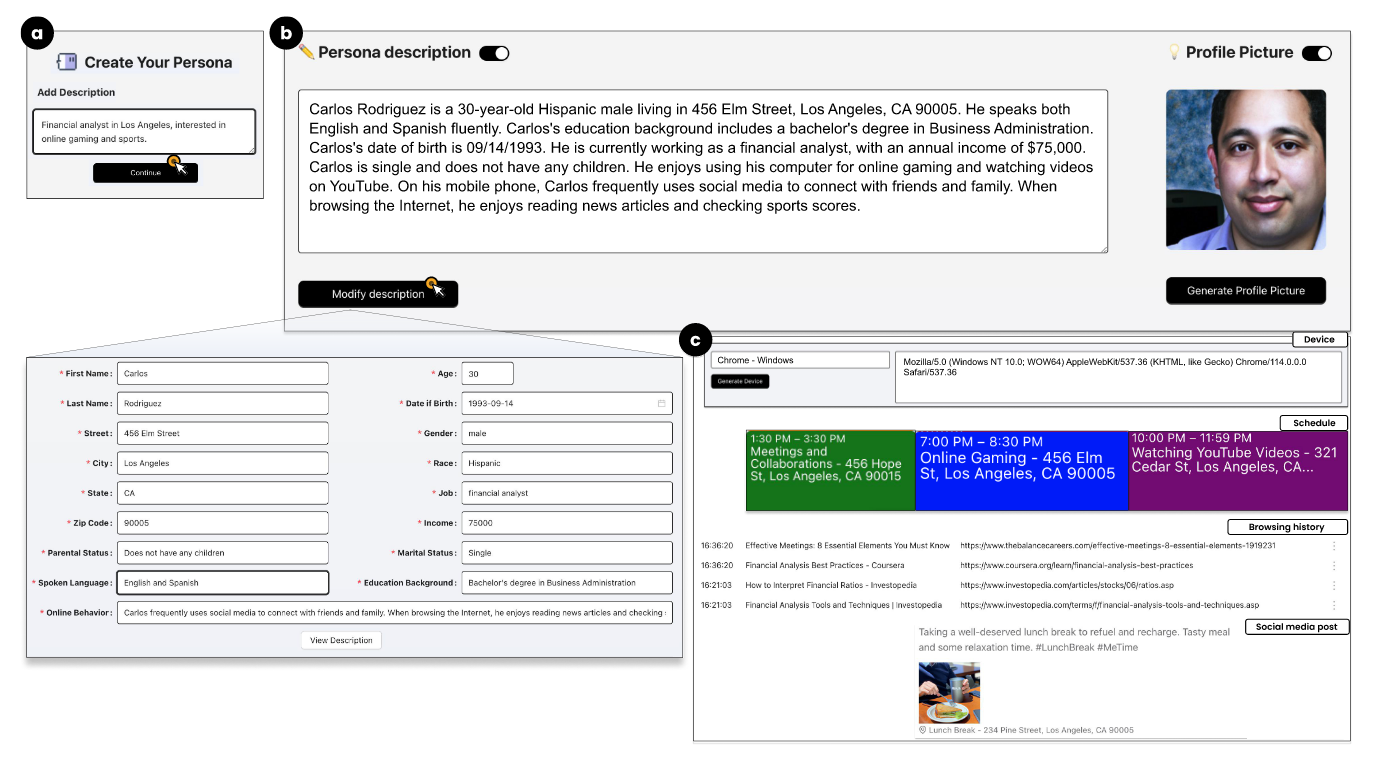
- 数据构成: 与传统UX人物角色不同,该方法生成的人物角色除了包含个人身份信息(PII)和人口统计信息外,还纳入了 纵向个人数据(Longitudinal Personal Data) ,如每周日程表、位置日志、浏览历史和社交媒体帖子 (所谓纵向个人数据我的理解是行为数据),还有用户头像图片。这些纵向数据提供了更丰富的上下文,有助于增强用户的同理心,同时对在线服务的个性化推荐至关重要 。
- 生成方法: 引入了一个新的数据生成管道,该管道利用大型语言模型(LLMs)(例如GPT-4)的输出来生成逼真的人物角色数据,并结合了 少样本学习(Few-shot learning)、情境化(Contextualization)和思维链(Chain-of-thoughts) 等提示词工程技术,以确保生成数据的细节丰富度和一致性 。
-
个人数据替换(Personal Data Replacement):
- 沙盒环境: 通过原型 “隐私沙盒”(Privacy Sandbox) 实现 。
- 运作机制: 用户以所选人物角色的身份与在线服务互动,沙盒会加载人物角色的合成个人数据并将其提供给在线服务,而不是用户的真实数据 。对于服务提供商而言,这些合成数据看起来是真实的,因此它们会根据人物角色的数据提供个性化内容(例如:定向广告)。
- 风险规避: 这为用户提供了一个无风险平台,让他们可以安全地实验隐私设置和行为,观察用户体验和隐私选择带来的具体后果 。
在实现上,该沙盒环境依托 Google Ad Center(Google 广告中心) 构建。由于 Google Ad Center 允许用户在控制面板中手动编辑其用于广告个性化的人口统计学信息(如年龄、性别、收入、教育程度等),因此我们的方法通过自动化脚本将合成角色(persona)输入到该平台,从而实现 persona 数据对真实用户信息的替换。这一机制无需访问 Google 后台或修改其内部系统,仅通过操作用户可控的前端界面,即可让广告系统基于合成数据生成个性化内容,达到在真实服务中模拟“另一个人”的效果,同时保护用户真实隐私。
实际人机交互过程
实际的用户与系统交互生成用户画像的流程整理如下:
- 提供初始指导(Guidance): 用户 在 Privacy Sandbox 平台上输入少量他愿意分享的个人信息(如兴趣、职业、地理位置等,可多可少)。这些信息作为生成人工角色(persona)的 guidance 也可以理解为一般生成数据时使用的 seed。
- 自动生成初步角色(Persona Generation): 系统基于 用户 的输入,利用结合 少样本学习(few-shot learning) 的 LLM 流水线,生成一个初步的合成角色。
- 审阅与编辑角色(Review & Modify): 用户 可在界面上查看该角色的完整档案(包括人口统计信息、周计划、浏览历史、社交媒体帖子等),并自由修改任何属性,确保角色符合其预期或实验目标。
- 保存与激活角色(Save & Activate): 一旦满意,用户 可保存该角色供未来使用。该沙盒有一个 Chrome 拓展,可以随时启动将用户的真实隐私数据临时替换为合成的用户数据。
- 数据替换执行(Personal Data Replacement): 该沙盒内存在一系列自动化技术在 Google Ad Center 内将用户真实数据替换为合成数据,该过程理论上可以实现全方位的数据替换。
- 与真实服务交互(Interact in Persona): 替换数据后,用户 像平常一样浏览网页、使用在线服务。但服务提供商(如 Google、社交媒体、广告网络)会将他视为 Carlos,并据此提供:
- 个性化广告
- 定制化内容推荐
- 基于角色画像的算法决策
- 实验与反思(Experiment & Learn): 在该过程中 用户可以主动尝试不同操作,并实时观察用户体验的变化(如广告内容、推荐结果),从而直观理解“隐私数据 → 系统输出”的因果关系。例如:
- 开启/关闭某网站的位置权限
- 主动提交某些个人信息
- 访问特定类型的网站
- 退出与清理(Deactivate & Clean Up): 实验结束后,用户 可停用沙盒。系统恢复原始浏览器环境,合成数据仅存在于本次会话中,不泄露 用户 的真实隐私。
用户研究与关键发现
该研究通过一个包含 15 名参与者的用户研究来验证其方法,主要使用定向广告作为系统结果的体现领域。
研究问题(Research Questions,RQs)
该研究旨在回答以下四个关键问题:
• RQ1: 使用我们的方法生成的人工隐私角色,与真实个人数据和基线 GPT 生成的数据相比,其逼真度如何?
• RQ2: 角色中合成隐私数据的不同特征如何影响用户感知到的真实性?
• RQ3: 我们用角色的合成数据替换用户真实个人数据的方法,能否引发系统结果(例如,在线广告)的变化?
• RQ4: 用户在使用 Privacy Sandbox 时,能否激发共情,并感知到隐私数据与系统结果之间的联系?
研究设计与步骤
研究过程分为三个阶段:
- Phase 1: 生成角色的定量评估(Quantitative evaluation of generated personas)
- Phase 2: 生成角色的定性调查(Qualitative investigation of generated personas)
- Phase 3: 分析广告-角色关联(Analyzing ad-persona connections)
Phase 1:生成角色的定量评估(Quantitative evaluation of generated personas)
-
目的: 评估三种不同来源角色的质量和用户感知。
-
角色分组: 参与者被随机展示来自以下三组的各一个角色:
- 我们方法生成的角色(Our generated persona): 使用论文提出的增强 LLM 输出的流程(包括少样本学习、情境化和思维链技术)生成的角色。
- 真实角色(Real persona): 从 8 名成人参与者那里收集的真实数据,经过匿名化处理,以在保护隐私的同时保持感知真实性(例如,用生成的头像替换真实照片,用假地址替换真实地址)。
- GPT 直接生成的角色(GPT-generated persona): 未使用论文提出的增强技术,仅使用 GPT-4 直接生成的基线角色。
-
评估方法: 参与者使用 5 点李克特量表对每个角色的清晰度(Clarity)、完整性(Completeness)、可信度(Credibility)、一致性(Consistency)和共情程度(Level of Empathy)进行评分。
Phase 2:生成角色的定性调查(Qualitative investigation of generated personas)
- 目的: 深入了解用户对生成角色的感知,并确定哪些隐私数据元素增强或削弱了真实性感知(RQ2)。
- 方法: 结合了Think Aloud 和半结构化访谈。
- 过程:
- 实验者先介绍 Privacy Sandbox 的使用方法,确保参与者了解如何生成和修改角色。
- 参与者对两个先前未见过的生成角色(来自我们方法生成的组)进行“边想边说”式的探索,评论角色隐私数据(包括个人描述、日程、浏览历史、社交媒体帖子等)的真实性。
- 如果参与者认为某些元素不真实或需要调整,他们可以直接修改角色的属性并解释修改的原因。
Phase 3:分析广告-角色关联(Analyzing ad-persona connections)
- 目的: 调查数据替换是否有效 (RQ3),以及用户能否感知到隐私数据与系统结果之间的联系 (RQ4)。
- 角色使用: 参与者对两个新的角色(均来自我们方法生成的组)执行此任务。
- 沙盒激活: 参与者阅读角色信息后,点击“激活”(“active”)按钮。Privacy Sandbox 启动一个新的浏览器窗口,并自动将参与者的真实个人数据替换为角色的合成数据。
- 替换的数据包括: Google 广告中心内的个人资料、浏览历史、实时地理位置和 IP 地址。
- 浏览与识别: 参与者被要求浏览两个随机选择的网站(选自预设的五个网站列表),识别定向投放给当前角色的广告,并以“边想边说”的方式解释这些广告与角色的隐私属性是如何关联的。
实验材料与度量 (Materials and Measurements)
网站选择(Websites)
研究选择了 5 个具有代表性的网站来测试个性化广告,选择标准包括:涵盖不同主题、存在多个广告,且广告来源于 Google Ads(因其普及性和对用户数据的广泛访问)。
| 网站 | 主题 | 广告数量 |
|---|---|---|
| www.weather.com | 天气预报 | 8 |
| www.cnn.com | 全国新闻 | 8 |
| www.researchgate.net | 学术论文 | 3 |
| www.usnews.com | 全国新闻 | 3 |
| www.fashionista.com | 时尚 | 5 |
系统结果度量(RQ3):广告重叠率
为了定量评估数据替换(即角色切换)是否有效改变了系统结果(广告投放),研究计算了广告重叠率(Advertisement Overlap Rate)
广告重叠率(ad overlap rate) = 重复广告的数量(number of duplicated ads between personas) 网上的广告总数(total number of ads in a website) \text{广告重叠率(ad overlap rate)} = \frac{\text{重复广告的数量(number of duplicated ads between personas)}}{\text{网上的广告总数(total number of ads in a website)}} 广告重叠率(ad overlap rate)=网上的广告总数(total number of ads in a website)重复广告的数量(number of duplicated ads between personas)
如果广告重叠率低于 50%,则表明当用户切换角色时,超过一半的广告是独特的,证明沙盒的数据替换机制是有效的。结果显示,所有网站的广告重叠率均低于 50%(如 www.cnn.com 为 15.00%,www.weather.com 为 46.81%)。
实验结果
RQ1:用户对合成隐私角色真实性的主观感受
RQ1 比较了三种角色类型(我们方法生成的角色、GPT 直接生成的基线角色和真实角色)在 可信度、一致性、清晰度和共情程度 方面的差异。
-
可信度(Credibility):
- 真实角色的得分最高(平均值 μ = 4.83 ) . \mu = 4.83). μ=4.83).
- 论文方法生成的角色得分( μ = 3.67 \mu = 3.67 μ=3.67)高于 GPT 直接生成的基线角色( μ = 3.17 \mu = 3.17 μ=3.17),但与真实角色相比,仍存在显著差距。
- 这表明当前生成模型在实现真实角色级别的可信度方面仍有不足。
-
一致性(Consistency):
- 在一致性方面,我们方法生成的角色与真实角色之间没有发现显著差异。
- 然而,真实角色与 GPT 直接生成的基线角色之间存在显著差异。 这说明研究中引入的增强 LLM 输出的生成流程(少样本学习、情境化和思维链) 有效地提高了生成数据内部的一致性。
-
清晰度(Clarity):
- 所有三组角色在信息清晰度方面没有发现显著差异。
-
共情(Empathy):
- 认知共情(Cognitive Empathy): 我们方法生成的角色( μ = 3.67 \mu = 3.67 μ=3.67)比 GPT 直接生成的基线角色( μ = 2.17 \mu = 2.17 μ=2.17)显著更高。这表明我们创建的角色在帮助用户理解角色行为背后的动机方面更有效。
- 情感共情(Emotional Empathy): 三组角色之间没有观察到显著差异。
- 启示: 总体共情得分(包括认知和情感)适中偏低。研究推测,仅浏览角色的资料(Profile)在引发共情方面的效果有限,实际的交互体验可能对于培养更强的共情至关重要。
RQ2:影响生成角色感知真实性的因素
RQ2 旨在了解哪些因素会增强或削弱用户对生成角色真实性的感知。
- 熟悉度与逼真度的权衡(Trade-off):
- 参与者对某个角色(如金融分析师)越熟悉,他们越可能注意到生成数据中的细微缺陷,从而降低角色的感知真实性。
- 作者指出,理想情况下,用户应认为角色既熟悉又真实,但在当前 LLM 的限制下,需要在熟悉度和真实性之间保持平衡。
- 与个人经验的偏差(Deviation from Personal Experiences):
- 当角色的某些属性(如收入、工作时长、专业程度)与参与者自己的经验或对该人群的认知不符时,会引发怀疑或不满。
- 具体属性问题: 例如,有六名参与者认为金融分析师等角色的给定年收入($70,000)过低,不符合其领域经验。
- 整体印象问题: 一些参与者认为角色“太完美以至于不像真实人物”,或者看起来“像一个被控制的人”,从而引发了更深层次的真实性质疑。
- 数据细节不一致: 参与者认为角色的工作时间过长(例如,一周七天、每天至少 8 小时)。浏览历史过于以工作为中心,缺乏生活化内容,并且存在不同记录时间戳相同的问题。社交媒体帖子被认为过于积极和肤浅,缺乏真实情感深度。
- 数据内部的一致性(Consistency within the data):
- 尽管我们方法生成的角色总体上因一致性而受到赞扬,但仍存在直接的数据不一致:例如,在每周日程中,相同的事件每天发生在不同的地点,或社交媒体帖子中包含不一致的人物或场景图片。
RQ3:隐私数据替换对系统结果的影响
RQ3 旨在验证 Privacy Sandbox 的数据替换机制是否能有效改变系统结果,通过衡量 广告重叠率(Advertisement Overlap Rate) 来实现。
- 广告重叠率: 广告重叠率的计算公式是重复广告数量除以网站上的广告总数。
- 有效性验证: 所有五个选定网站的广告重叠率均低于 50%。例如,在 www.cnn.com 上的重叠率为 15.00% 。
- 结论: 这一结果证实了当用户在不同角色之间切换时,他们会看到独特的广告。这有力地验证了 Privacy Sandbox 的数据替换机制是有效和可行的,能够根据角色的隐私属性改变在线服务(定向广告)的输出。
RQ4:感知隐私数据与系统结果的关联
RQ4 探究用户在使用沙盒与角色身份互动时,能否激发共情并感知到隐私数据与系统结果(定向广告)之间的联系。
- 基于隐私属性的直接关联:
- 所有参与者在以角色身份浏览网站时,都遇到了与该角色的隐私属性相关的广告。
- 参与者能够明确识别广告与角色的兴趣、职业、日常活动、地理位置等属性之间的对应关系。
- 当遇到高度相关的广告时,参与者表现出明显的兴奋或惊讶等情感反应。这种情感和认知上的参与证明了用户对角色的认知共情和情感共情被激发。
- 这种经验使参与者能够识别并内化分享特定隐私属性的后果,从而增强其隐私知识。
- 基于个人联想和刻板印象的间接关联:
- 有趣的是,用户有时会根据个人偏见或社会刻板印象来推断广告的关联性。
- 案例: 一名参与者认为轮胎广告与一名非裔美国人角色相关,是基于“非裔美国文化喜欢改装轮胎”的刻板印象,尽管角色资料中并未提及任何相关信息。
- 风险: 这种基于偏见的推断虽然反映了认知共情,但引发了对用户获取知识准确性的担忧。这说明用户的个人观点可能会扭曲他们对隐私属性与系统结果之间关系的理解。
讨论与启示
-
熟悉度与角色真实性对共情的影响:
- 熟悉度与真实性的权衡: 心理学研究表明,用户更容易对熟悉的人产生更强的共情。然而,对于人工生成的隐私角色而言,用户的熟悉度与对角色感知到的真实性之间存在一种权衡(trade-off)
- 负面影响: 如果参与者对某一领域(如金融分析师)越熟悉,他们就越有可能注意到生成数据中的瑕疵,认为角色“看起来是假的”。这种感知上的不真实性反过来会对用户对角色的共情程度产生负面影响。
-
个人观点对共情和隐私素养的影响:
- 个人偏见的影响: 用户的共情不仅受熟悉度影响,还受他们的个人观点和偏见的影响。
- 扭曲理解: 参与者基于个人经验、观察甚至社会刻板印象(例如,对某一职业或群体的刻板印象)来判断角色的隐私属性是否合理,这种偏差会降低角色感知到的真实性。
- 知识获取的准确性担忧: 结果显示,用户有时会基于个人联想和刻板印象来解释定向广告的出现,而不是基于角色的特定隐私属性。这引发了对用户通过沙盒获取知识的准确性的担忧。
- 未来方向: 建议开发感知工具(sense-making tools),例如可视化工具,帮助用户更客观地理解隐私数据与系统结果之间的关系。
-
隐私知识的获取:
- 系统结果的敏感性: 研究证实,通过 Privacy Sandbox 进行的隐私数据修改,确实能影响网站和应用程序的系统结果(例如,定向广告)。
- 经验学习: 用户在亲身体验到与角色隐私属性相关的高度相关广告时,会表现出兴奋或惊讶等情感反应。他们能够识别并内化分享特定隐私属性的后果。
- 教学潜力: 这证明了该方法有潜力支持用户进行经验学习(experiential learning),并作为一种“支架式教学”(scaffolding)的方式,帮助用户体验他们原本无法自主管理或理解的隐私属性对系统后果的影响。
- 来验证: 尽管定性发现显示了该方法的巨大潜力,但未来需要进行严谨的前测和后测(pre-tests and post-tests),以及纵向部署研究(longitudinal deployment studies),以科学验证知识获取和行为改变的实际效果。
-
LLMs 偏差及其影响:
- 偏差的双重作用: LLMs 可能会放大既有的刻板印象。然而,在沙盒环境中,如果生成的角色隐私数据中包含的偏差反映了真实世界的偏见,这有助于外部推荐系统产生更逼真的系统结果。
- 伦理风险: 长期和重复暴露于带有偏见的生成角色可能会强化用户的刻板印象。在采用此方法时,需要警告用户潜在的偏差风险,并研究减轻这种影响的方法。
-
伦理与法律考量:
- 除了潜在的刻板印象强化,该方法还有被恶意滥用的风险。 例如,可能被用于生成难以检测的机器人或进行网络钓鱼活动。因此,必须施加更严格的技术和政策限制来减轻潜在的安全隐患。
局限性与未来工作
- 生成一致性: 存在生成数据中的不一致性和 归纳偏差(inductive biases)问题。未来计划通过模型微调、将事实存储为知识图谱和知识注入技术来提高数据的一致性。
- Privacy Sandbox 原型: 当前原型仅作为概念验证,仅支持浏览器任务,且支持的隐私数据类型(如传感器数据和搜索历史)有限。未来将扩展沙盒以支持移动应用和智能家居设备等其他平台和数据类型。
- 实验周期: 目前的实验是短期的,未能验证用户长期的行为改变(Privacy Literacy的长期提升)。
- 下游任务的普适性: 尽管当前研究使用了定向广告,但该方法预计可推广到动态社交媒体推送、算法决策和个性化新闻推荐等更广泛的下游任务。
在现实世界中,用户因为系统不透明性以及对“意外暴露个人数据”的恐惧 而不敢随意调整隐私设置,就像在布满地雷的迷宫中寸步难行。而这篇论文构建的沙盒环境则提供了一个零风险的训练场,它允许用户暂时“穿上”人工生成的虚拟角色的身份外衣,并在该角色的身份下体验各种隐私选择所带来的真实系统后果(例如,看到精准的定向广告)。通过这种角色扮演和共情 的方式,用户得以在没有泄露自己真实隐私数据的前提下,直观地感知隐私数据与系统结果之间的因果关系,从而有效地获取隐私知识和情感共鸣,最终促使他们做出与自身隐私目标相符的长期行为改变。
其实可以大胆一些,让进行实验的何必只有 真人呢,让 Agent 参与到实验来,甚至可以构建大规模的 Agent 社区来做更加全面的模拟和分析,帮助我们进行下一步的人机交互设计。

















 7930
7930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









