







说在前面
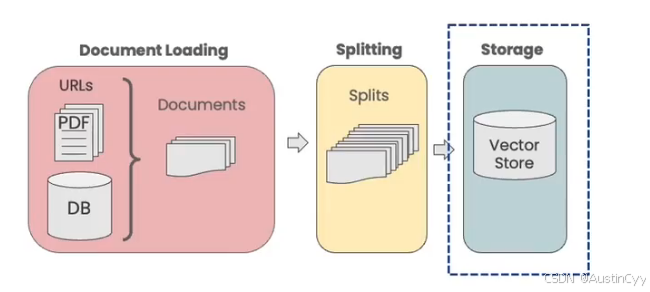
在上一节我们已经实现了将 文档划分成小的 chunk(块),之后便来到了向量存储的环节。这一节,我们将介绍 Vectorstores and Embeddings (向量存储和嵌入)的基本概念,指出向量数据库相似性搜索可能出现的失败模式。
Main Content
Embedding
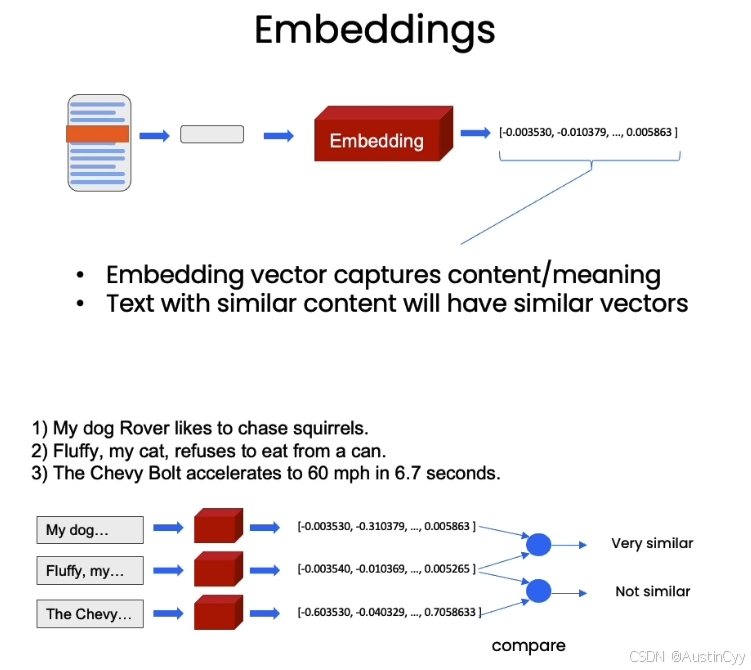
Embedding (嵌入)可以简单理解为将文本转换为一个数值表示,往往是向量的形式。可以推断出,具有相似语义的文本嵌入后的数值表示是相似的,这意味着我们可以通过比较这些向量表示,来找出相似的文本片段。
Vector Store
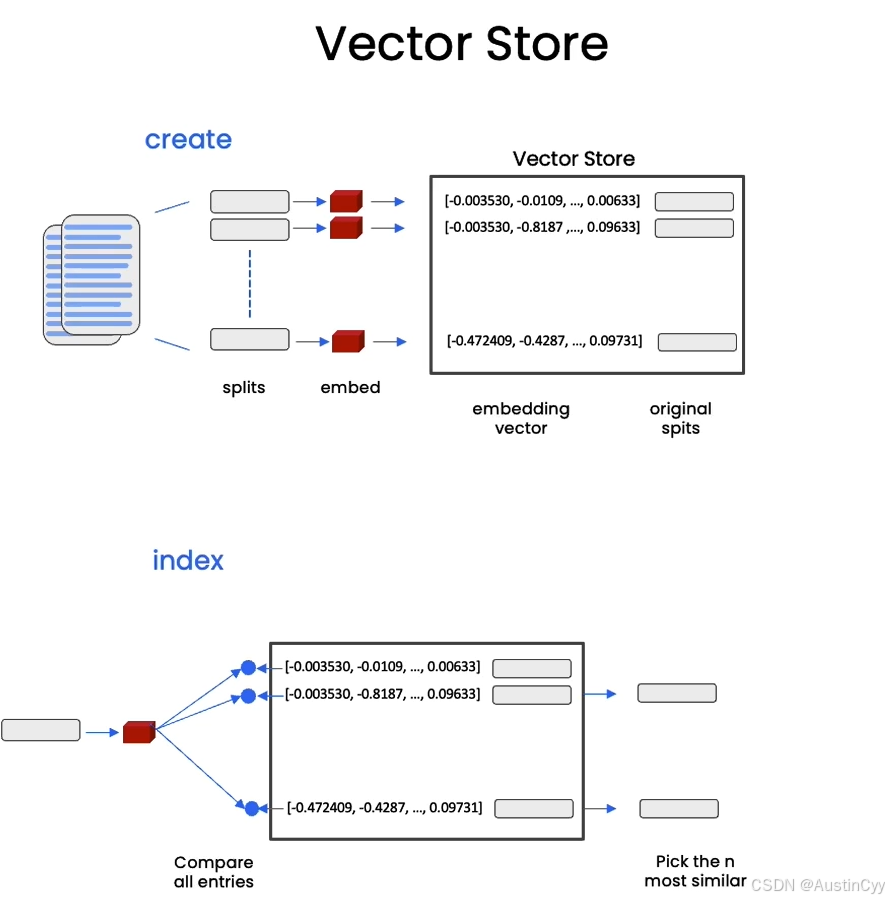
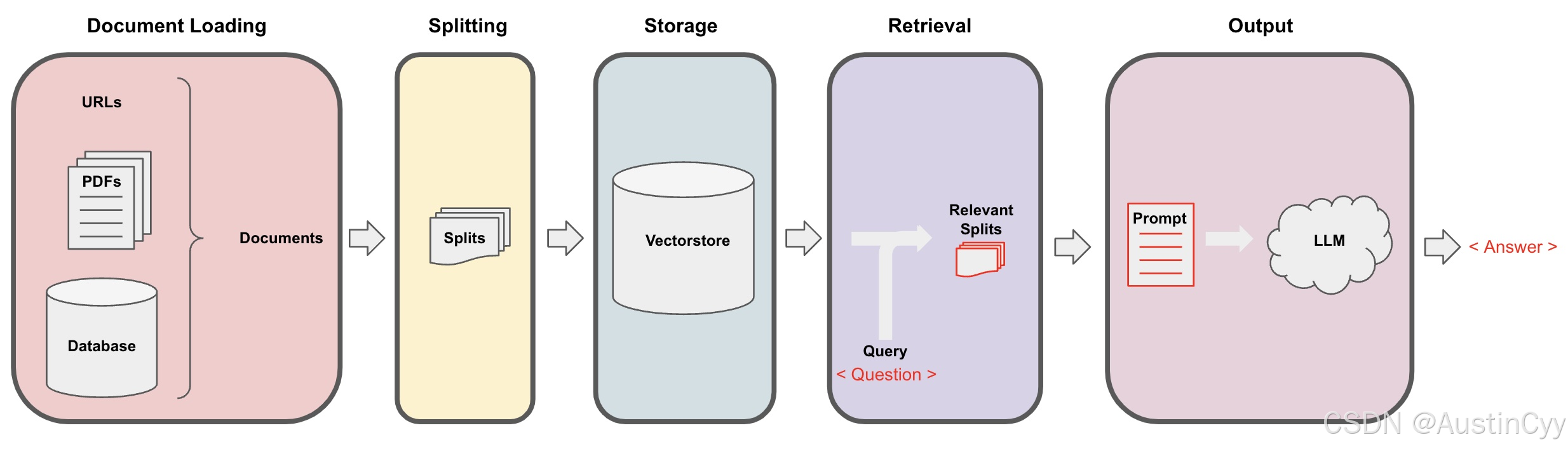
完整的流程是,我们首先加载文档,然后对文档进行拆分,创建这些文档的嵌入(Embedding),然后存储在向量存储中(Vector Store)。向量存储其实可以理解成一个数据库,我们可以在其中查找相似的向量。
当我们试图找到与手头问题相关的文档时,向量存储的优势就能体现出来。我们此时,拿出问题,创建一个嵌入,将其与向量存储中的所有不同的向量进行比较,然后跳出最相似的几个向量,将这几个最相似的向量与问题一起传递给LLM中,然后得到一个答案。
至此,我们已经学习到完整的 RAG 流程
前置工作
1.导入环境变量,配置 API。
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
2.加载需要用到的PDF文档(吴恩达老师机器学习课程cs229的pdf讲义)。其中我们复制了一次第一讲的数据,用于模拟一些不干净的数据。(Document Loading)
from langchain.document_loaders import PyPDFLoader
# Load PDF
loaders = [
# Duplicate documents on purpose - messy data
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),
PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:
docs.extend(loader.load())
3.文档加载后,使用 RecursiveCharacterTextSplitter 对文档进行分割。可以看到分出来 209个 chunk。(Document Splitting)
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)
len(splits)

Embeddings
我们首先使用使用 toy 数据,来对创建 Embedding 时发生了什么进行研究。
1.使用 OpenAIEmbeddings 来完成 Embedding 操作。
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()
2.设定几个示例句子,前两个句子很相似,第三个则与前两个无关。
sentence1 = "i like dogs"
sentence2 = "i like canines"
sentence3 = "the weather is ugly outside"
3.分别为每一个句子创建一个 Embedding。
embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)
4.使用 Numpy 对这些 Embedding 进行比较,看看哪些是相似的。这里我们使用 numpy.dot() 计算点积来比较这两个嵌入,只需知道计算结果越大相似度越高。可以看到,前两个句子的相似度很高达到 0.96,后面的相似度大于都是0.76左右。
import numpy as np
np.dot(embedding1, embedding2)

np.dot(embedding1, embedding3)

np.dot(embedding2, embedding3)

Vectorstores
下面将使用真实数据,即提前加载好的 PDF 文档及逆行演示。
1.此处使用的向量存储器是 Chroma。(LangChain 集成了 30多种不同的向量存储器。)选择 Chroma 是因为它轻量,且是存储在内存中,启动和使用非常容易。
from langchain.vectorstores import Chroma
2.创建变量 persist_directory 保存地址路径。稍后会在文档 slash chroma中使用。
persist_directory = 'docs/chroma/'
3.确保这个位置是没有东西存在的,避免出现问题。
!rm -rf ./docs/chroma # remove old database files if any
4.创建向量存储器。
vectordb = Chroma.from_documents(
documents=splits,
embedding=embedding,
persist_directory=persist_directory
)
5.检查一下集合的计数,是 209 跟文档分割后的数量相同。
print(vectordb._collection.count())

Similarity Search
下面对向量存储的相似性搜索进行演示。
1.设计一个跟课堂相关的问题。
question = "is there an email i can ask for help"
2.我们将使用相似性搜索方法,传入问题,并传入 k=3,k 指定了我们想要返回得文档数量。
docs = vectordb.similarity_search(question,k=3)
3.查看返回的文档的数量,可以看到与指定的相同。
len(docs)

4.查看第一个文档的内容,会发现他是关于一个电子邮件地址的。与问题相符
docs[0].page_content

5.运行下面的命令,持久化向量数据库。
vectordb.persist()
Failure modes
下面将讨论一些边缘情况,展示失败的地方。
重复的 Chunk
1.换一个问题进行相似度查找。
question = "what did they say about matlab?"
docs = vectordb.similarity_search(question,k=5)
2.查看返回的前两个文档的内容。
docs[0]

docs[1]

这地方我们会发现,返回的前两个文档内容是相同的。这是因为,我们之前在加载文件的时候,加载了两个相同的文件,相当于我们让两个不同的 chunk 中有相同的信息,并且我们把这两个 chunk 都传递给了 LLM,然而第二段相同的信息并没有实际的价值,如果这两个 chunk 的内容不同的话得到的效果应该会更好。
结构化的查询
1.设定一个新的问题,第三节课上它们讲述的关于 regression 的内容是什么。
question = "what did they say about regression in the third lecture?"
docs = vectordb.similarity_search(question,k=5)
2.理论上我们查找的结果应该都是 lecture03 中的,但是查看结果的 metadata 可以看到结果包含 lecture01 和 lecture02 的。
for doc in docs:
print(doc.metadata)

3.打印来自 lecture01 的文档内容,发现其中讲到了关于 regression 的内容。
print(docs[4].page_content)

不难发现当我们在向量存储中去检索结构化的数据时,会发生错误。原因是,在向量存储中,我们是基于语义的相似度进行检索的,而这种方式会损失结构化的数据中的细节,纯粹的计算相似度并不会要求,返回的文档必须来自第三堂课。之后的章节会讲解如何解决这种问题。
还有其他的模式错误。 比如,当我们将 k 值设定的过大时,可能会返回一些不符合预期的结果等。
总结
本节讲解并演示了 Embedding 和 Vectorstores 的概念和搜索原理,并说明了这种方式存在一些问题,后面的章节会做介绍和说明。

















 1915
1915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









