




说在前面
上一节中,我们已经初步构建了一个问答机器人,实现了实现了对数据的问答功能。但美中不足的是,仅仅通过RetrievalQA构建的问答机器人只能回答当前问题,无法参考上下文给出答案,因为它没有记忆。
Main Content
本节通过给机器人添加记忆(Memory)模块,赋予它记忆力,实现真正的连贯性聊天。并将创建一个ChatBot 来实现一个完整的 RAG 流程。
前置工作
导入环境变量
import os
import openai
import sys
sys.path.append('../..')
import panel as pn # GUI
pn.extension()
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
Memory
使用 ConversationBufferMemory 创建记忆模块。参考 Memory
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
ConversationalRetrievalChain
ConversationalRetrievalChain结合了上下文管理和基于检索的问答,旨在处理包含聊天历史记录的对话链路。
from langchain.chains import ConversationalRetrievalChain
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
question = "Is probability a class topic?"
result = qa({"question": question})
result['answer']

question = "why are those prerequesites needed?"
result = qa({"question": question})
result['answer']

第一个问题是有关“probability”的,紧接着第二个回答解释了“probability”为什么是先修课程。两个问答在内容上是连贯的,因为ConversationalRetrievalChain回答第二个问题时已经知道第一个问题的上下文。
Create a chatbot that works on your documents
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
def load_db(file, chain_type, k):
# load documents
loader = PyPDFLoader(file)
documents = loader.load()
# split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# define embedding
embeddings = OpenAIEmbeddings()
# create vector database from data
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# define retriever
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model_name=llm_name, temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
import panel as pn
import param
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True)
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
Create a chatbot
结合Panel和Param搭建RAG系统,实现可交互的Chatbot:
cb = cbfs()
file_input = pn.widgets.FileInput(accept='.pdf')
button_load = pn.widgets.Button(name="Load DB", button_type='primary')
button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')
bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks)
conversation = pn.bind(cb.convchain, inp)
jpg_pane = pn.pane.Image( './img/convchain.jpg')
tab1 = pn.Column(
pn.Row(inp),
pn.layout.Divider(),
pn.panel(conversation, loading_indicator=True, height=300),
pn.layout.Divider(),
)
tab2= pn.Column(
pn.panel(cb.get_lquest),
pn.layout.Divider(),
pn.panel(cb.get_sources ),
)
tab3= pn.Column(
pn.panel(cb.get_chats),
pn.layout.Divider(),
)
tab4=pn.Column(
pn.Row( file_input, button_load, bound_button_load),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )),
pn.layout.Divider(),
pn.Row(jpg_pane.clone(width=400))
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')),
pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4))
)
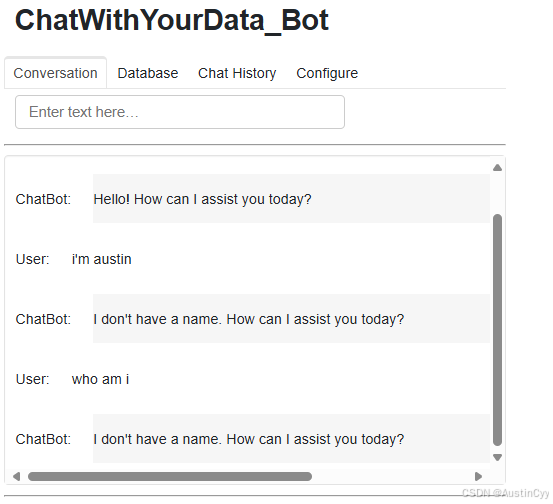
dashboard
可以在这里体验一下构建出来的 Chatbot 能够实现记忆功能。
总结
本课程介绍了如何使用LangChain访问私有数据,并建立个性化的问答系统。按照RAG工作流的顺序,分别讨论了:文档加载、文档分割、存储、检索和输出五大环节。最后创建了一个完全功能的、端到端的聊天机器人。

















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









