



前言
LLaMA Factory 是一个简单易用且高效的大型语言模型训练与微调平台,可以在有限的算力条件下快速完成模型训练。它的高效性与轻量级优势,核心在于通过注入额外模块或矩阵(如 LoRA、Prefix Tuning 等技术)对原有 LLM 模型进行针对性训练 —— 大部分参数被冻结无需参与训练,省去了全量微调的繁琐与资源消耗。
讲在前面: 为什么使用Llama Factory ?什么样的场景下适合使用Llama Factory。
Llama Factory的核心在于它解决了「技术门槛高、资源需求大、流程碎片化」,对于代码基础不是特别好的同学特别友好,并且支持监督微调(SFT)、奖励建模(RM)、强化学习(RLHF/DPO)等全链路训练的技术栈,相比于手搓代码更简单、更便捷、更高效。另外,Llama Factory适合以下三类场景:
- 「资源有限、轻量、高效」的轻量化微调场景
- 「垂直领域」的模型定制场景
- 「交互类应用」的快速落地测试场景
Llama Factory 实战
从官网(原始链接)下载Llama Factory包,或者使用如下命令:
git clone https://github.com/hiyouga/LLaMA-Factory.git
创建conda环境(运行环境):
conda create -n llama_factory python=3.10conda activate llama_factorycd LLaMA-Factorypip install -r requirements.txt
检验下是否安装成功(打印出一系列参数表明安装成功,如果想知道Llama Factory中不同参数的用处,也可以使用该命令来查看):
llamafactory-cli train -h
下载需要进行微调的模型到本地(以llama/llama3-8B为例)
modelscope download --model llama/Meta-Llama-3-8B-Instruct --local_dir ./dir
--local\_dir 表示大模型参数文件下载后存储的地址,根据自己的需求进行更改。
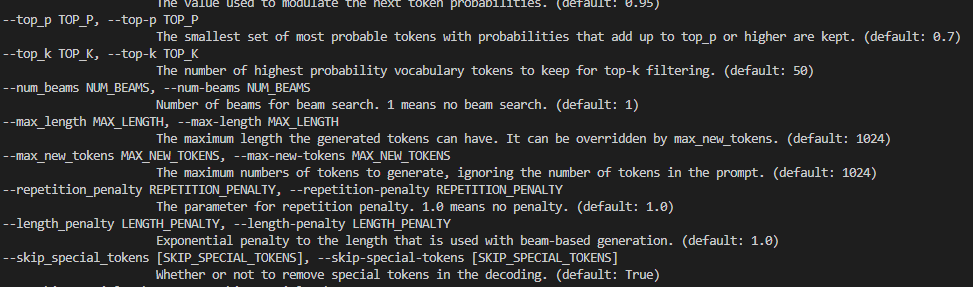
LLaMA-Factory 内置了基于 Gradio 开发的 ChatBot 推理页面,可用于对模型效果进行人工测试。在 LLaMA-Factory 目录下,执行以下命令即可启动该页面:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat --model_name_or_path llama/Meta-Llama-3-8B-Instruct --template llama3
支持模型的Template,请参考以下链接:
https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#supported-models
运行后会自动跳转到以下页面(http://127.0.0.1:7860/):
以上是LLaMA-Factory启动方式,下面具体描述下如何通过LLaMA-Factory来对LLM开源模型进行微调,主要分为三个阶段:
- 数据准备,
- SFT指令微调;
- Merg模型合并。
一、数据准备
我们将SFT的任务定义为一个简单的"生成式推荐"任务,
言简意赅:根据用户的需求来推荐对应的电影,对应的训练数据应该如下:
{"prompt":"推荐Adventure, Animation, Children, Comedy, Fantasy类型的电影","response":"Toy Story (1995)"}
对应的数据集,可以发送"MovieLens"获取,或者自行根据MovieLens 32M数据集进行构建。
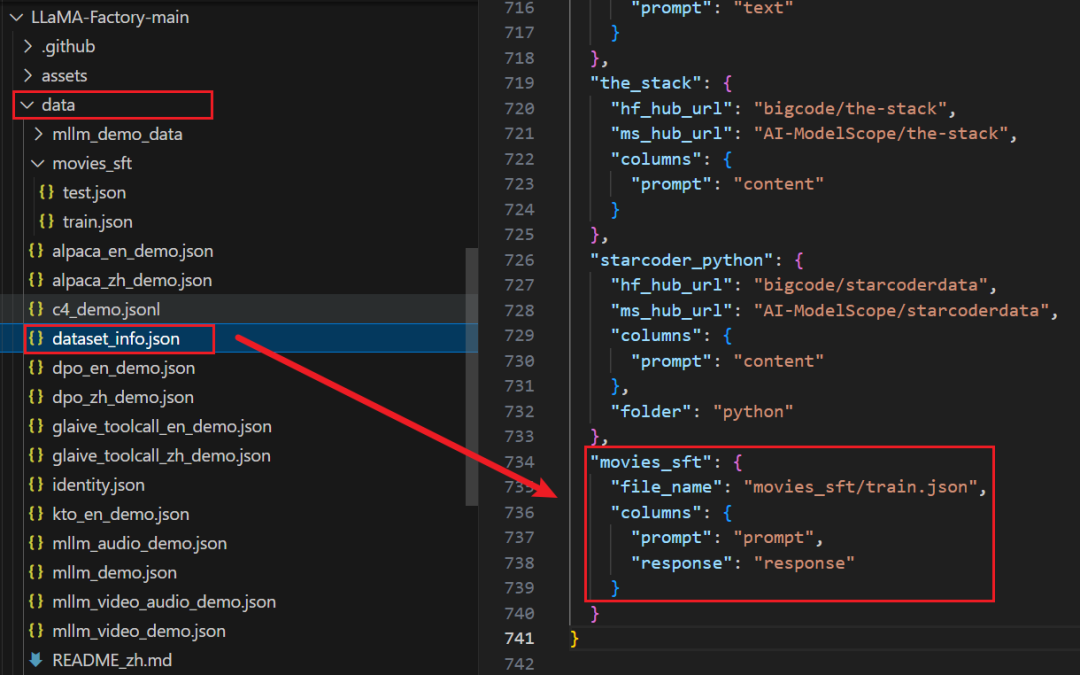
将响应的数据放在LLaMA-Factory项目的data目录下,包括train.json和test.json;
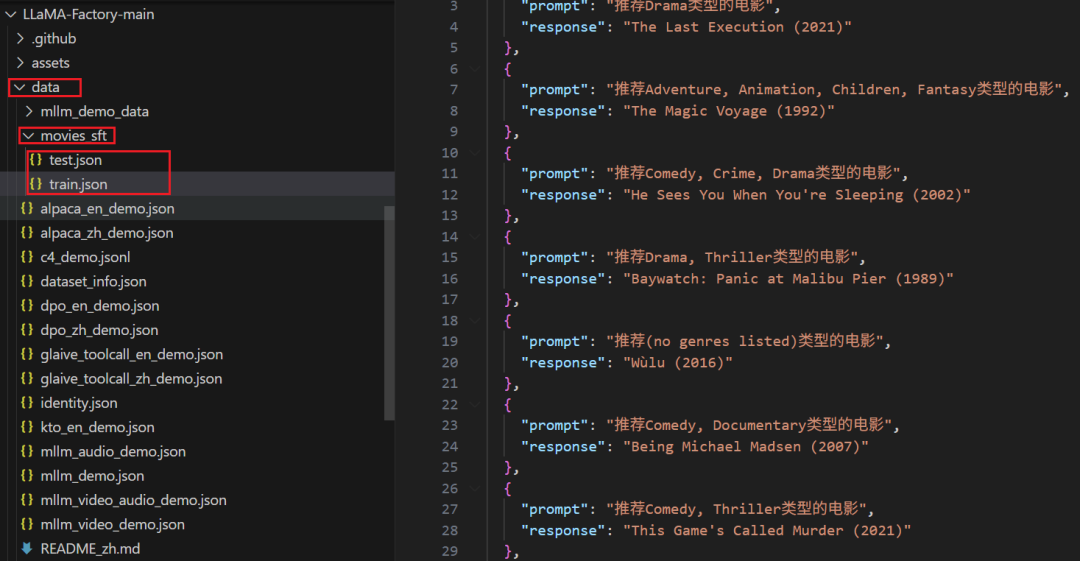
并需要在项目的data/dataset_info.json中加入数据集的相关信息进行注册,设置生成式推荐的数据集名称是"gen_recommend",再填入文件路径和数据集json文件中的字段;这样做是为了,SFT训练阶段开源直接根据数据集名称自动映射到对应的数据集上。
二、SFT指令微调
执行以下命令,即可开始训练;
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train --stage sft --do_train --model_name_or_path llama/Meta-Llama-3-8B-Instruct --dataset movies_sft --dataset_dir ./data --template llama3 --finetuning_type lora --output_dir llama/SFT-Meta-Llama-3-8B-Instruct --overwrite_cache --overwrite_output_dir --cutoff_len 1024 --preprocessing_num_workers 16 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --logging_steps 50 --warmup_steps 20 --save_steps 100 --eval_steps 100 --learning_rate 5e-5 --num_train_epochs 5.0 --max_samples 1000 --val_size 0.1 --plot_loss --fp16
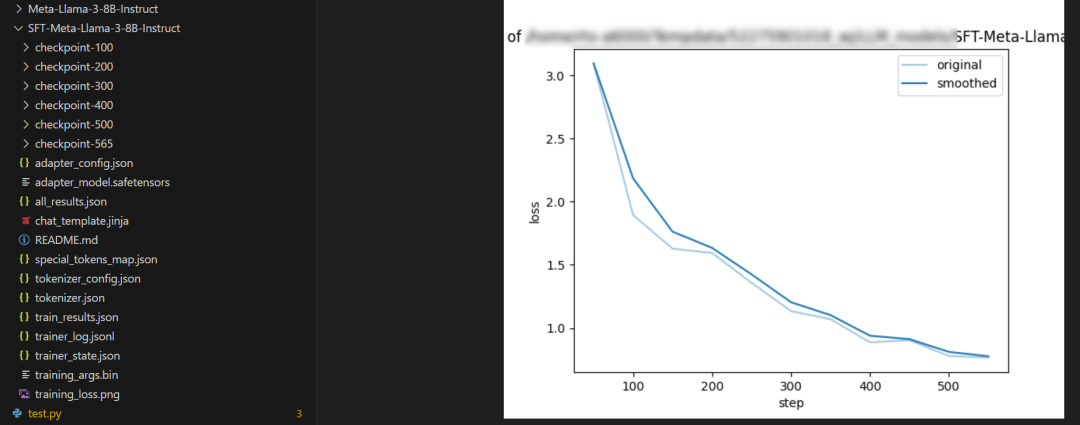
训练完成之后,可以在LoRA的模型文件中看到整个训练过程的loss。
三、Merg模型合并
经过基于 LoRA的训练完成后,一般需要进行 Merge 操作,这是为了将 LoRA模型的权重 融合回原始基础模型中,从而得到一个完整、可独立部署的模型。
LLaMA-Factory中是通过启动基于Gadio的WeChat服务的时候,通过添加两个参数 分别是:--adapter\_name\_or\_path和 finetuning\_type,告知服务当前调用的LLM是经过了LoRA训练,然后自动加载LoRA训练后得到的模型。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat --model_name_or_path llama/Meta-Llama-3-8B-Instruct --finetuning_type lora --adapter_name_or_path llama/SFT-Meta-Llama-3-8B-Instruct --template llama3
还有一种更简单的方式:直接通过代码来对原模型参数和LoRA后的模型参数进行merge,然后在启动服务的时候,直接将基座模型的路径改成merge后的路径即可。
import os
import argparse
import shutil
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
def parse_args():
parser = argparse.ArgumentParser("Merge LoRA adapter into base model")
parser.add_argument("--output_lora", required=True, help="LoRA adapter 目录")
parser.add_argument("--model_name", required=True, help="基座模型目录")
parser.add_argument("--out_dir", default=None, help="合并后模型输出目录")
parser.add_argument("--cpu", action="store_true", help="在 CPU 上合并")
return parser.parse_args()
def main():
args = parse_args()
lora_dir = os.path.abspath(args.output_lora)
base_dir = os.path.abspath(args.model_name)
out_dir = os.path.abspath(args.out_dir or lora_dir + "-merged")
os.makedirs(out_dir, exist_ok=True)
# 检查文件存在性
for f, desc in [(lora_dir, "LoRA目录"), (base_dir, "基座目录")]:
assert os.path.isdir(f), f"{desc}不存在: {f}"
assert os.path.isfile(os.path.join(lora_dir, "adapter_config.json")), "缺少 adapter_config.json"
assert os.path.isfile(os.path.join(base_dir, "config.json")), "基座目录缺少 config.json"
# 设置设备与 dtype
device_map = None if args.cpu else "auto"
dtype = torch.float32 if args.cpu else (torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16)
# 加载基座模型
base = AutoModelForCausalLM.from_pretrained(
base_dir, torch_dtype=dtype, device_map=device_map, trust_remote_code=True, local_files_only=True
)
# 加载LoRA并合并
merged = PeftModel.from_pretrained(base, lora_dir, is_trainable=False).merge_and_unload()
# 保存完整模型和 tokenizer
merged.save_pretrained(out_dir, safe_serialization=True, max_shard_size="2GB")
AutoTokenizer.from_pretrained(base_dir, trust_remote_code=True, local_files_only=True).save_pretrained(out_dir)
# 尝试保存 generation_config
if hasattr(base, "generation_config") and base.generation_config is not None:
try: base.generation_config.save_pretrained(out_dir)
except: pass
# 拷贝可选额外文件
for extra in ["chat_template.jinja"]:
src = os.path.join(base_dir, extra)
if os.path.isfile(src): shutil.copy2(src, os.path.join(out_dir, extra))
if __name__ == "__main__":
main()
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









