



前言
1 准确率弊端
虽然准确率计算过程简单也十分容易理解,但是准确率却存在着一个不容忽视的弊端。例如,现在需要训练一个癌细胞诊断模型来识别癌细胞,且在训练数据中其中负样本(非癌细胞)有10万个,而正样本(癌细胞)只有200个。假如某个模型将其中的105个预测为正样本,100095个预测为负样本。最终经过核对后发现,正样本中有5个预测正确,负样本中有99900个样本预测正确。那么此时该模型在训练集上的准确率为
但显然,这样的一个模型对于辅助医生决策来说并没有任何作用。如果模型极端一点将所有的样本都预测为负样本,那模型的准确率更是高达。因此,在面对类似这种样本不均衡的任务中,并不能够将准确率作为评估模型的唯一指标。此时就需要引入精确率和召回率来作为新的评价指标。
2 精确率与召回率计算
我们仍旧以猫狗识别任务为例。
假定现在有一个猫狗识别程序,并且假定狗为正类别(Positives)猫为负类别(Negatives)。程序在对12张狗和10张猫的混合图片进行识别后,判定其中8张图片为狗,14张图片为猫。经人工核对后,在这8张程序判定为狗的图片中仅仅只有5张图片的确为狗,因此这5张图片就被称为预测正确的正样本(True Positives, TP);而余下的3张被称为预测错误的正样本(False Positives, FP)。同时,在这14张程序判定为猫的图片中,仅有7张为真实的猫,即预测正确的负样本(True Negatives, TN);而余下的7张被称为预测错误的负样本(False Negatives, FN)。
此时,根据这一识别结果,我们便可以得到如图1所示的混淆矩阵(Confuse Matrix)。
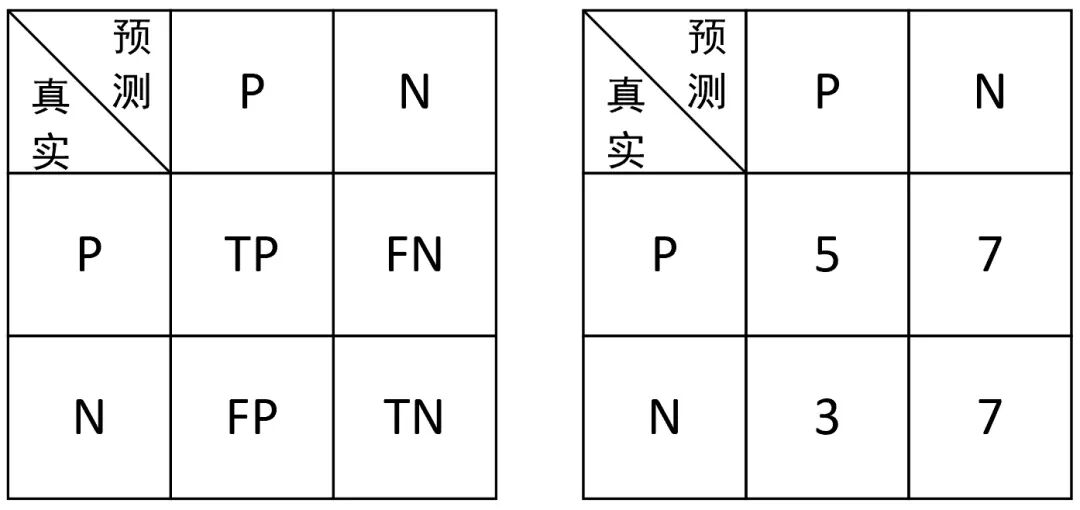
图1. 混淆矩阵图
如何来读这个混淆矩阵呢?读的时候首先横向看,然后纵向看。例如读TP的时候,首先横向表示真实的正样本,其次是纵向表示预测的正样本,因此TP表示的就是将正样本预测为正样本的个数,即预测正确,因此,同理共有以下4种情况。
(1) TP: 表示将正样本预测为正样本,即预测正确。
(2) FN: 表示将正样本预测为负样本,即预测错误。
(3) FP: 表示将负样本预测为正样本,即预测错误。
(4) TN: 表示将负样本预测为负样本,即预测正确。
如果此时突然问FP表示什么含义,又该怎样迅速地反应出来呢?我们知道FP从字面意思来看表示的是错误的正类,也就是说实际上它并不是正类,而是错误的正类,即实际上为负类,因此,FP表示的就是将负样本预测为正样本的含义。再看一个FN,其字面意思为错误的负类,也就是说实际上它表示的是正类,因此FN的含义就是将正样本预测为负样本。
在定义完上述4种分类情况后就能得出各种场景下的计算指标公式,如式下所示。
注意: 当中时称为值,同时也是用得最多的评价指标。
可以看到,精确率计算的是预测对的正样本在整个预测为正样本中的比重,而召回率计算的是预测对的正样本在整个真实正样本中的比重,因此一般来讲,召回率越高也就意味着这个模型寻找正样本的能力越强(例如在判断是否为癌细胞的时候,寻找正样本癌细胞的能力就十分重要),而则是精确率与召回率的调和平均。
因此,根据精确率和召回率的定义,我们还可以通过更直观的图示来进行说明,如图3-8所示。
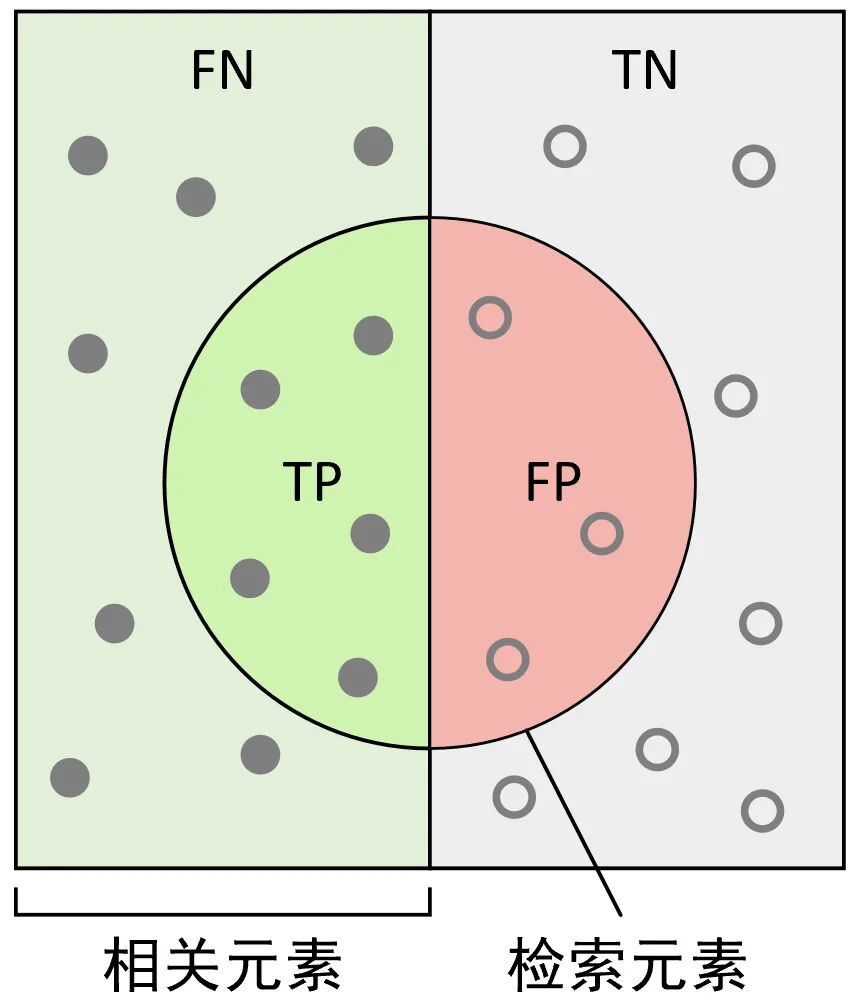
图 2. 分类情况分布图
如图2所示,左侧的所有实心样本点为正样本(相关元素),右侧的所有空心点为负样本,中间的圆形区域为模型预测的正样本(检索元素),即圆形左侧为模型将正样本预测为正样本的情况,右侧为模型将负样本预测为正样本的情况。例如现在可以想象这么一个场景,某一次我们在使用搜索引擎搜索相关内容(正样本)时,搜索引擎一共检索返回了30个搜索页面(搜索引擎认为的正样本),而搜索引擎返回的结果就相当于是图3-8中对应的圆形区域,所以精确率和召回率还可以通过图3来形象地进行表示。
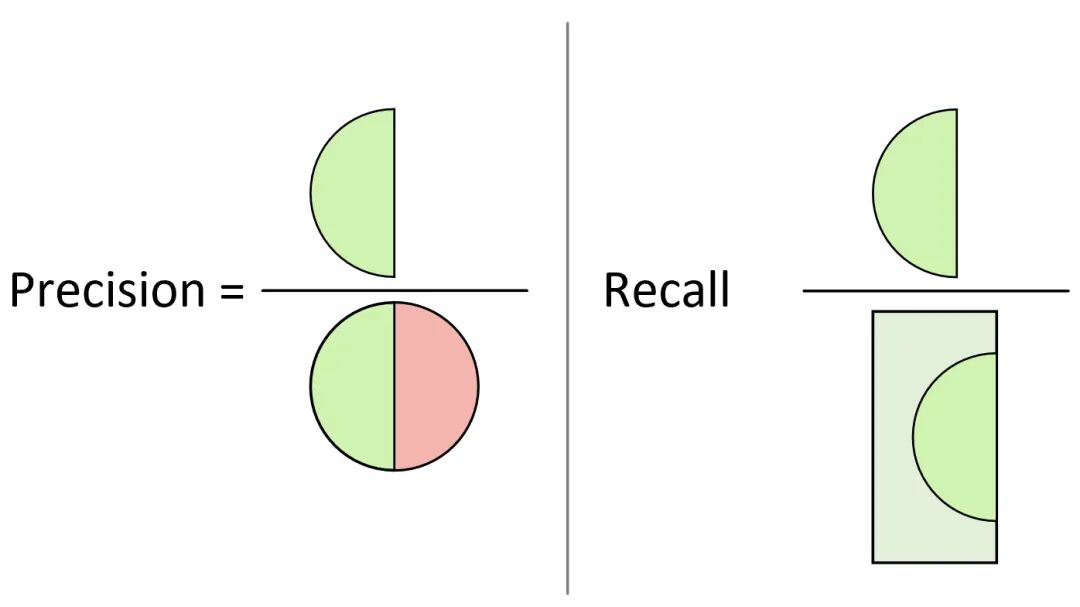
图 3. 精确率召回率图示
从图3中更能直观地看出,精确率计算的是预测正确的正样本在整个被预测为正样本中的占比;而召回率计算的是预测正确的正样本在所有真实正样本中的占比。
- 准确率与召回率区别
============
介绍到这里可能有读者会问,在上述问题中既然精确率和召回率都能够解决准确率所带来的弊端,那可不可以只用其中一个呢?答案是不可以。下面我们再次以上面的癌细胞判别模型为例,并以3种情况来进行示例说明。
1. 情况一
将所有样本均预测为正样本,此时有,,,,则
2. 情况二
将其中50个样本预测为正样本,100150个预测为负样本。最终经过核对后发现,正样本中有50个预测正确,负样本中有100000个样本预测正确。此时有,,,,则
3. 情况三
将其中的210个样本预测为正样本,99990个预测为负样本。最终经过核对后发现,正样本中有190个预测正确,负样本中有99980个样本预测正确。此时有,,,,则
根据这3种情况下模型的表现结果可以知道,如果仅从单一指标来看无论是准确率、精确率还是召回率都不能全面地来评估一个模型。并且,至少应该选择精确率和召回率同时作为评价指标。同时可以发现,精确率和召回率之间一定程度上存在着某种相互制约的关系,即如果一味地只追求提高精确率那么召回率可能就很低,反之亦然。
所以,在实际情况中我们会根据需要来选择不同的侧重点,当然最理想的情况就是在取得高召回率的同时还能保持较高的精确率。最后,我们也可以直接计算来进行综合评估,例如上述3种情况对应的值分别为,和。因此,对于一个分类模型来说,如果想要在精确率和召回率之间取得一个较好的平衡,最大化值是一个有效的方法。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









