



前言
为了提高RAG的性能,结合大模型的RAG技术涌现出很多的改进方案SELF-RAG,Adaptive RAG,CRAG等技术相继被提出,今天笔者就来介绍CRAG这个技术,并采用langchain全家桶中的LangGraph框架实现CRAG。看看CRAG比传统RAG强多少。
纠正性检索增强生成——CRAG
纠正性检索增强生成(Corrective Retrieval-Augmented Generation,CRAG)https://arxiv.org/pdf/2401.15884 是一种先进的自然语言处理技术,旨在提高基于检索的生成(Retrieval-Augmented Generation,RAG)方法的鲁棒性和准确性。CRAG通过引入一个轻量级的检索评估器来评估检索到的文档的质量,并根据评估结果触发不同的知识检索动作,以确保生成结果的准确性和可靠性。
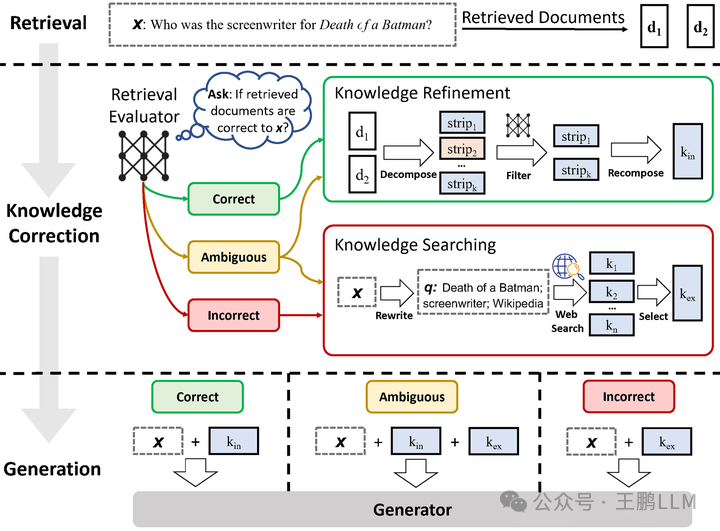
CRAG(纠正性检索增强生成)的工作流程如上方图所示主要包括以下几个步骤:
检索文档:首先,基于用户的查询,系统执行检索操作以获取相关的文档或信息。
评估检索质量:CRAG使用一个轻量级的检索评估器对检索到的每个文档进行质量评估,计算出一个量化的置信度分数。
触发知识检索动作:根据置信度分数,CRAG将触发以下三种动作之一:
- 正确:如果评估器认为文档与查询高度相关,将采用该文档进行知识精炼。
- 错误:如果文档被评估为不相关或误导性,CRAG将利用网络搜索寻找更多知识来源。
- 模糊:对于相关性不确定的文档,CRAG会结合正确和错误的处理策略,以提高检索的鲁棒性。
知识精炼:对于评估为正确的文档,CRAG将进行知识精炼,抽取关键信息并过滤掉无关信息。
网络搜索:在需要时,CRAG会执行网络搜索以寻找更多高质量的知识来源,以纠正或补充检索结果。
分解-重组:CRAG采用一种分解-重组算法,将检索到的文档解构为关键信息块,筛选重要信息,并重新组织成结构化知识。
生成文本:最后,利用经过优化和校正的知识,提高了生成文本的准确性和鲁棒性。
LangGraph简介
LangGraph 是 LangChain 的一个重要扩展库,它允许开发者构建基于大型语言模型(LLMs)的复杂应用,特别是那些需要循环或多个智能体(agents)协作的应用。以下是 LangGraph 的一些关键特性和概念:
- 状态图(StateGraph):LangGraph 使用状态图来表示整个应用的状态,图中的节点和边定义了应用的流程和逻辑4。
- 节点(Nodes):在 LangGraph 中,节点可以是任何可调用的 Python 函数,也可以是 LangChain 中的可运行组件,如链(Chains)或智能体(Agents)。每个节点执行特定的任务,如推理、调用工具或生成响应。
- 边(Edges):边定义了节点之间的连接和数据流。LangGraph 支持不同类型的边,包括:
- 起始边(Starting Edge):定义任务的起始节点。
- 普通边(Normal Edge):表示一个节点完成后立即跳转到下一个节点。
- 条件边(Conditional Edge):基于条件函数的结果决定跳转到哪个节点4。
- 循环和多智能体支持:LangGraph 支持构建循环图,允许智能体在循环中被调用,直到任务完成。这对于需要迭代或多步骤交互的应用非常有用。
- 状态管理:LangGraph 允许开发者定义和维护一个中央状态对象,该对象会根据节点的跳转不断更新。状态对象的属性可以自定义,以适应不同的应用需求。
LangGraph 设计为与框架无关,这意味着每个节点都是一个常规的 Python 函数,可以轻松地与现有的 Python 生态系统集成。LangGraph 扩展了 LangChain 表达式语言(LCEL),允许协调多个链或智能体,提供了一种高级的 LCEL 语言,使得逻辑更清晰。通过 LangGraph,开发者可以创建出能够处理更复杂交互和循环逻辑的智能体应用,从而推动基于大型语言模型的应用开发向更高级别的自动化和智能化发展。

实战部分
当然本次实现的不是完整版的CRAG,相比于原论文,简化了评估检索质量这一步和省掉了知识精炼和分解-重组这两个步骤。
代码主要参考下方,但是在llm模型,embeding模型,以及prompt上做了一些修改。
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb
初始化知识库和大模型LLM
这里的向量服务器是采用xinference 本地部署的bge-base-zhv1.5,大模型部分采用的glm4免费送的一些token
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.embeddings import XinferenceEmbeddings
###向量服务
xinference = XinferenceEmbeddings(
server_url="*******", model_uid="bge-base-zhv15"
)
###知识收集和预处理
urls = [
"https://spaces.ac.cn/archives/9907",
"https://spaces.ac.cn/archives/9920"
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# 向量入库
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=xinference,
)
retriever = vectorstore.as_retriever()
### 初始化llm
llm = ChatOpenAI(
temperature=0.95,
model="glm-4",
openai_api_key="*******",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
搜索结果评价 agent的定义
# 搜索结果评价 agent
system = """
请扮演是一位评估检索文档与用户问题相关性的评分员。
如果文档包含与问题相关的关键词或语义,请将其评为yes,否则评为no
直接给出"yes" 和 "no" .\\n"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "以下是:\\n 检索文档: \\n\\n {document} \\n\\n 用户问题: {question}"),
]
)
retrieval_grader = grade_prompt | llm | StrOutputParser()
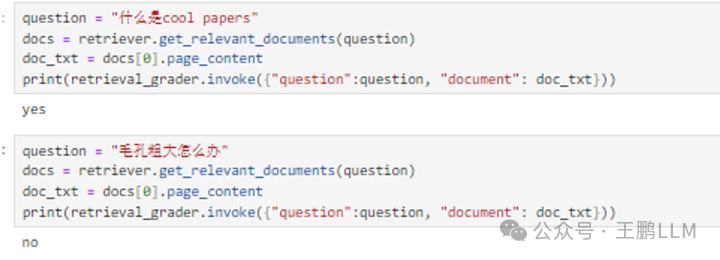
##测试搜索结果评价 agent
question = "什么是cool paper"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[0].page_content
print(retrieval_grader.invoke({"question":question, "document": doc_txt}))
## 评价结果: yes
RAG agent的定义
#RAG agent
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
prompt = hub.pull("rlm/rag-prompt")
# Post-processing
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = prompt | llm | StrOutputParser()
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
## rag结果: Cool Papers是一个辅助科研人员刷论文的网站,它逐日收录论文并提供了站内检索系统。该网站还引入了venue分支,收录了如ICLR、IC等会议历年的论文集。Cool Papers的开发得到了GPT4和Kimi等人工智能模型的支持,可以帮助用户快速了解论文内容。
搜索query优化agent定义
#搜索query 优化agent
system = """您是一位搜索query优化专家,负责将搜索输入的问题转换成一个更优的版本,一定不要改变原义,更适合网络搜索,尽量精简一点"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"这是用户的问题:: \\n\\n {question} \\n 请直接输出优化后的问题:",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
##优化结果: "cool paper 定义及特点"
搜索工具定义
### web Search 工具
from langchain_community.tools.tavily_search import TavilySearchResults
import os
os.environ["TAVILY_API_KEY"] = "******"
web_search_tool = TavilySearchResults(k=3)
web_search_tool.invoke({"query": "如何有效缩小毛孔?"})
搜索结果如下:
[{‘url’: ‘https://beautyfoomall.com/blogs/news/毛孔大怎么办什么可以收缩毛孔’, ‘content’: ‘Dec 8, 2021 — Dec 8, 2021… 毛孔粗大。缩小面部毛孔可根据皮肤的不同种类进行治疗,利用护肤品补水、射频、激光、食疗等方法是可以延缓皮肤衰老,缩小面部毛孔 … 有效!Cellreturn\xa0…’}, {‘url’: ‘https://zhuanlan.zhihu.com/p/281404233’, ‘content’: ‘12种有效方法收缩毛孔的教你怎么样让毛孔变小 · 1、化妆前,可以用冰凉的毛巾收缩紧致毛孔 · 2、使用化妆棉创造水嫩豆腐肌 · 3、多喝水,从内到外让肌肤水水 · 4、用饭团搓\xa0…’}, {‘url’: ‘https://fashion.sina.cn/zl/2016-06-23/detail-ifxtmses0755122.d.html’, ‘content’: ‘Jun 22, 2016 — Jun 22, 2016鸡蛋+橄榄油鸡蛋打散,加入橄榄油,搅匀,敷脸15分钟,洗干净。如果蛋液能放在冰箱里冰镇,效果更好,不仅可以收缩毛孔,还可以美白。’}, {‘url’: ‘https://www.zhihu.com/question/40366369’, ‘content’: ‘Feb 14, 2016 — Feb 14, 2016从目前来看,用护肤品把毛孔“彻底缩小”的确有难度,不过要让毛孔暂时一段时间内“视觉上缩小”还是有办法的。 反对那种一谈毛孔粗大就建议别人去医美的言论\xa0…’}, {‘url’: ‘https://skintypesolutions.com/zh/blogs/皮肤护理/皮肤科医生建议如何收缩毛孔’, ‘content’: ‘Nov 14, 2023 — Nov 14, 2023在这篇文章中,我将解释导致毛孔扩大的原因,并提供基于证据的策略来帮助缩小毛孔并使其不那么明显。 我将帮助您找到最好的毛孔缩小剂产品和美容程序。’}]
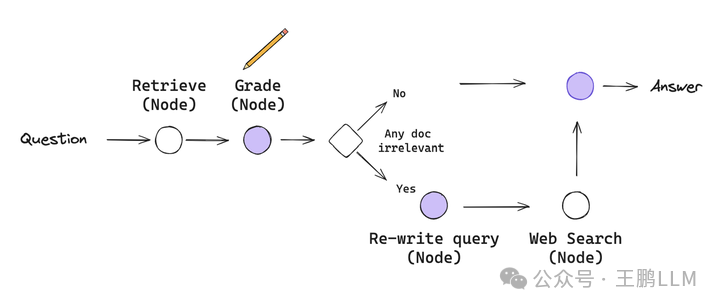
流程图的定义
###定义agent graph
from langchain.schema import Document
from typing_extensions import TypedDict
from typing import List
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
print(documents[0])
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
if"yes"in score:
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
print("优化后的qurey是:" + better_question)
return {"documents": documents, "question": better_question}
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\\n".join([d["content"] for d in docs])
print("搜索结果是:" + web_results)
web_results = Document(page_content=web_results)
documents.append(web_results)
return {"documents": documents, "question": question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
question = state["question"]
web_search = state["web_search"]
filtered_documents = state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return"transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return"generate"
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search_node", web_search) # web search
# Build graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search_node")
workflow.add_edge("web_search_node", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
流程图的可视化
from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except:
# This requires some extra dependencies and is optional
pass
流程图可视化结果
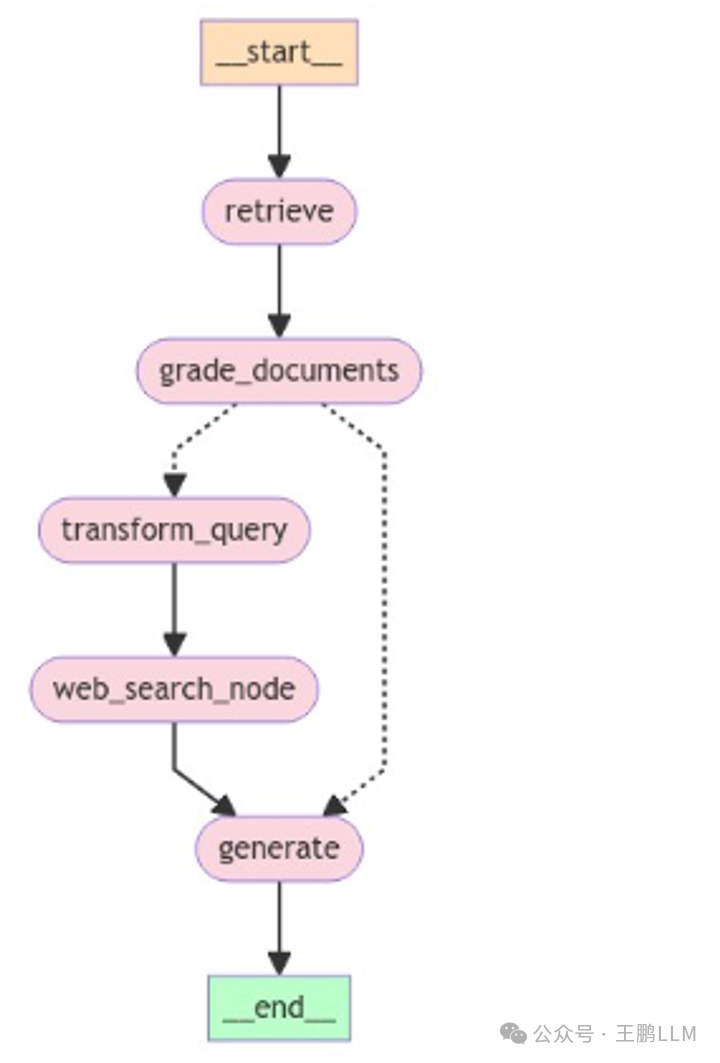
开始问问题
第一个是知识库有的问题,所以走的是左边的路线,直接本地rag后,检索质量评估结果不错,最终生成结果。
:Cool Papers是一个用于刷论文的辅助网站,开发者曾在博客中分享其开发体验和更新进度。该网站逐日收录论文,并经历了几次较大的变化,如引入venue分支,收录了一些会议历年的论文集。随着时间的积累,Cool Papers还增加了一个站内检索系统以提高检索效率。
from pprint import pprint
# Run
inputs = {"question": "Cool Papers 是什么"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("---------------------------------")
# Final generation
pprint(value["generation"])

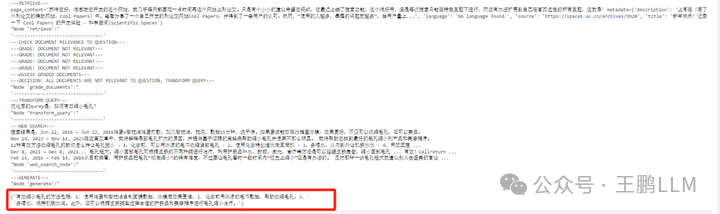
第一个是知识库没有的问题,所以走的是右边的路线,直接本地rag后,检索质量评估结果很差,然后走web搜索rag 生成结果:有效缩小毛孔的方法包括:1. 使用鸡蛋和橄榄油自制面膜敷脸,冰镇后效果更佳;2. 化妆前用冰凉的毛巾敷脸,帮助收缩毛孔;3.多喝水,保持肌肤水润。此外,还可以根据皮肤类型选择合适的护肤品和美容程序进行毛孔缩小治疗
from pprint import pprint
# Run
inputs = {"question": "如何缩小毛孔?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("---------------------------------")
# Final generation
pprint(value["generation"])
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









