




 本文探讨了机器学习的可行性,重点介绍了VC维理论在保证机器学习可靠性方面的作用。通过Hoeffding不等式解释了样本数量与预测准确性之间的关系,并讨论了在有噪声情况下VC Bound的有效性。同时,文章提到了误差度量在分类和回归问题中的应用,以及如何处理不同错误类型的权重问题。
本文探讨了机器学习的可行性,重点介绍了VC维理论在保证机器学习可靠性方面的作用。通过Hoeffding不等式解释了样本数量与预测准确性之间的关系,并讨论了在有噪声情况下VC Bound的有效性。同时,文章提到了误差度量在分类和回归问题中的应用,以及如何处理不同错误类型的权重问题。
文章目录
本系列是台湾大学资讯工程系林軒田(Hsuan-Tien Lin)教授开设的《 机器学习基石》课程的梳理。重在梳理,而非详细的笔记,因此可能会略去一些细节。
该课程共16讲,分为4个部分:
- 机器什么时候能够学习?(When Can Machines Learn?)
- 机器为什么能够学习?(Why Can Machines Learn?)
- 机器怎样学习?(How Can Machines Learn?)
- 机器怎样可以学得更好?(How Can Machines Learn Better?)
本文是第2部分,对应原课程中的4-8讲。
本部分的主要内容:
- 用案例引出学习可行性的疑问;
- 详细介绍VC维理论,它给出了机器学习的可靠性保证;
- 介绍误差的度量,以及对误差权重不同的情况的处理方法。
1 学习可行性的疑问
先来一个小学奥数题/公务员考试题:
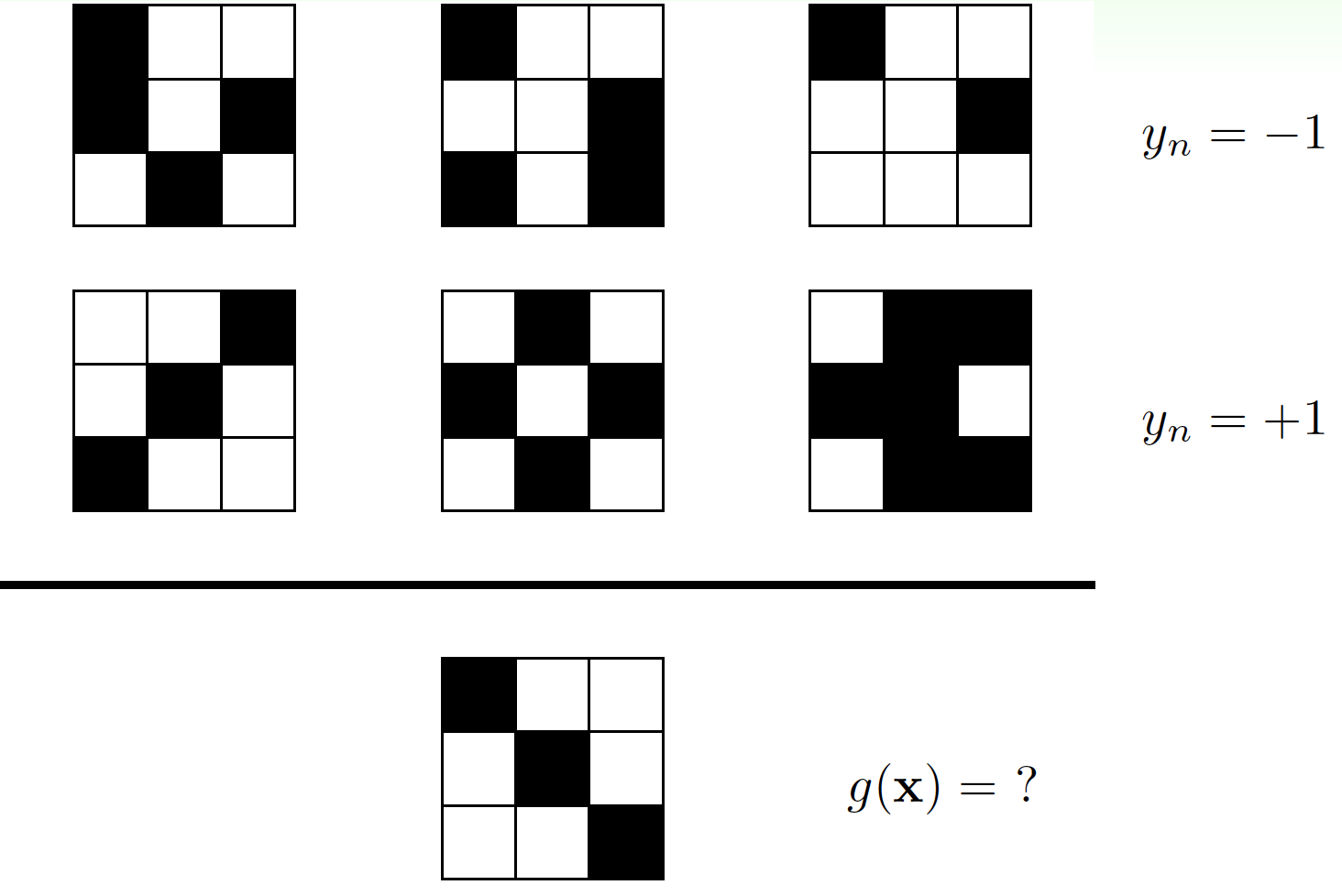
其实这个题没有标准答案,以下两种解答都是对的:
- 对称为 + 1 +1 +1,非对称为 − 1 -1 −1,因此答案是 + 1 +1 +1;
- 最左上角的格子白色为 + 1 +1 +1,黑色为 − 1 -1 −1,因此答案是 − 1 -1 −1;
因此,选择不同的规则,你会获得不同的答案。那么,如果给你一些历史数据,机器学习出某种规则,是否也会遇到这样的情况呢?
2 机器学习的可靠性保证
2.1 Hoeffding不等式
来看另一个问题:有一个罐子,里面装有许许多多黄色和绿色的小球,该如何估计黄球的比例?
很简单,抽样就行了。抽出一部分样本,计算得到样本中的黄球比例 ν \nu ν,用这个比例作为罐子中的黄球比例 μ \mu μ的估计即可。这样的估计准不准呢?在统计学中,有Hoeffding不等式给出准确率的界限:
P [ ∣ ν − μ ∣ > ϵ ] ≤ 2 exp ( − 2 ϵ 2 N ) \mathbb{P}[\vert\nu-\mu\vert>\epsilon]\le 2\exp{(-2\epsilon^2 N)} P[∣ν−μ∣>ϵ]≤2exp(−2ϵ2N)
其中 N N N为抽样的样本个数。这个式子的意思是, ν \nu ν和 μ \mu μ相差较远的概率会有一个上限,在大样本下,这个上限会比较小,因此 ν = μ \nu=\mu ν=μ可以叫做概率近似正确(PAC,probably approximately correct)。
2.2 机器学习中的Hoeffding不等式
现在将这个过程类比到机器学习中。罐子中的小球对应于 X \mathcal{X} X中的单个数据 x \mathbf{x} x,给定假设集中的一个假设 h h h,罐子中黄球的比例就对应于 X \mathcal{X} X中使得 h ( x ) = f ( x ) h(\mathbf{x})=f(\mathbf{x}) h(x)=f(x)的 x \mathbf{x} x的比例。现在抽取出一部分样本,这个样本对应于现有的数据集 D \mathcal{D} D,我们可以很容易地知道对 D \mathcal{D} D中每一个数据 ( x n , y n ) (\mathbf{x}_n,y_n) (xn,yn)是否有 h ( x n ) = y n h(\mathbf{x}_n)=y_n h(xn)=yn,若相等,对应的小球为黄色,反之为绿色。我们的目的,是要知道在整个 X \mathcal{X} X中满足 h ( x ) = f ( x ) h(\mathbf{x})=f(\mathbf{x}) h(x)=f(x)的 x \mathbf{x} x的比例有多少。
若 N N N足够大,且 x n \mathbf{x}_n xn为i.i.d.,对于某个固定的 h h h来说,就可以用已知的 E in ( h ) = 1 N ∑ n = 1 N 1 [ h ( x n ) ≠ y n ] E_{\text{in}}(h)=\dfrac{1}{N}\sum\limits_{n=1}^{N} \mathbf{1}_{[h(\mathbf{x}_n)\ne y_n]} Ein(h)=N1n=1∑N1[h(xn)=yn]去推断 E out ( h ) = E x ∼ P 1 [ h ( x ) ≠ f ( x ) ] E_{\text{out}}(h)=\mathop{\mathcal{E}}\limits_{\mathbf{x}\sim P}\mathbf{1}_{[h(\mathbf{x})\ne f(\mathbf{x})]} Eout(h)=x∼PE1[h(x)=f(x)],从而判断该 h h h的表现如何,如下图:
根据Hoeffding不等式,就是
P [ ∣ E in ( h ) − E out ( h ) ∣ > ϵ ] ≤ 2 exp ( − 2 ϵ 2 N ) \mathbb{P}[\vert E_{\text{in}}(h)-E_{\text{out}}(h)\vert>\epsilon]\le 2\exp{(-2\epsilon^2 N)} P[∣Ein(h)−Eout(h)∣>ϵ]≤2exp(−2ϵ2N)
如果 E in ( h ) E_{\text{in}}(h) Ein(h)和 E out ( h ) E_{\text{out}}(h) Eout(h)足够接近,并且 E in ( h ) E_{\text{in}}(h) Ein(h)足够小,这就能保证 E out ( h ) E_{\text{out}}(h) Eout(h)足够小,也就能判断出对于抽样过程 P P P,有 h ≈ f h\approx f h≈f。
但是,这只能用来判断某个 h h h是否足够好。如果现在是用算法 A \mathcal{A} A从假设集 H \mathcal{H} H中选出一个 h h h,再套用上面的不等式,就会有问题。试想一下,假设有150个人,每人丢5次硬币,就有超过99%的概率会出现有某个丢5次硬币都是正面的人,这能说明他的丢硬币技术比其他人高吗?如果选择他作为我们的“ g g g”,能保证他以后再去丢硬币,得到正面的概率也比其他人更大吗?
同理,如果是从 H \mathcal{H} H中选出一个在样本 D \mathcal{D} D内误差最小的 g g
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4027
4027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









