




这周开始,我将会开始一场苏格拉底式的大模型(LLM)构建教学,教大家学会如何构建GPT,Deepseek这样的大模型(当然是缩水版):
简单来说,需要从零开始(From Scratch),只使用 PyTorch 的基础 Tensor 操作(尽量不使用高层 API),手写构建一个完整的类似 Llama 或 GPT 架构的 Transformer 语言模型。
作业的核心要求是:不依赖 `torch.nn.Linear` 或 `torch.optim.Adam` 这样的现成工具,而是通过手写数学公式来实现它们,从而彻底理解 LLM 的底层原理 。
我的教学方式:一边回顾原理一边教学代码,但是如果对深度学习,NLP学习还不足的朋友,可以先好好学习完基础之后再来,因为这个课程相对更加高阶,对基础不好的,可能会不够友好,敬请谅解。
我们从最简单的分词器BPE开始吧。我不会使用抽象的代码,而是最简单逻辑最清晰的代码来教学
在完成基础架构之后,我们会对分词器进行优化。
核心原理:什么是 BPE (Byte Pair Encoding)?
计算机不认识“中文”或“English”,它只认识数字。 最笨的方法是 ASCII/UTF-8 编码(每个字母/汉字字节一个数字),但这会导致序列太长(“DeepMind”需要 8 个数字)。 BPE 的核心思想是:“合并”。
-
统计:看谁经常成对出现(比如 "e" 和 "s" 经常在一起变成 "es")。
-
合并:把最频繁的一对变成一个新的 ID。
-
循环:重复上述过程,直到达到我们想要的词表大小。
这样,常用词(如 "the", "ing")就会变成一个单独的 token,序列就变短了(压缩)。
第一步:基础函数
我们不需要任何库,只需要 Python 标准功能。
1. 准备数据
大模型也是从读取 raw bytes 开始的。我们将字符串转换为 UTF-8 编码的整数列表。
# 模拟一段简单的训练文本(为了演示,我们用这段英文,实际上你会读取文件)
text = "deep learning is deep and learning is fun. deepmind uses deep learning."
# 1. 将文本转化为原始的字节序列 (0-255 之间的整数)
# encode('utf-8') 将字符转为字节
tokens = list(text.encode("utf-8"))
print(f"原始长度: {len(tokens)}")
print(f"前10个Token (Raw Bytes): {tokens[:10]}")
# 对于 'd', 'e', 'e', 'p',对应的 ASCII 码是 100, 101, 101, 112
![]()
2. 统计频率函数 (get_stats)
我们需要一个函数来遍历整个列表,找出哪两个相邻的 token 出现次数最多。
def get_stats(ids):
"""
输入: ids (整数列表)
输出: counts (字典: {(id1, id2): count})
"""
counts = {}
# zip(ids, ids[1:]) 是一个很棒的技巧,它能拿到 [(第1个, 第2个), (第2个, 第3个)...]
# 这样我们就能通过一次循环看到所有的“相邻对”
for pair in zip(ids, ids[1:]):
# 如果 pair 在字典里,就 +1,如果不在,就是 0+1
counts[pair] = counts.get(pair, 0) + 1
return counts
# 测试一下
stats = get_stats(tokens)
# 找到出现次数最多的那个 pair
# key=stats.get 表示按照字典的值(次数)来排序
most_common_pair = max(stats, key=stats.get)
print(f"最常见的 Pair 是: {most_common_pair}, 出现了 {stats[most_common_pair]} 次")
![]()
这里抛出一个问题:如果最多的词对频率一样呢?如何选择呢?
答:在实际的BPE实现中(如HuggingFace的tokenizers库),通常采用确定性策略:
通常选择"最小"的词对(按数字大小排序)。
# 方法:选择"较小"的词对
候选1 = (5, 10)
候选2 = (10, 5)
# 比较规则:先比较第一个数,再比较第二个数
# (5,10) 比 (10,5) 小,因为 5 < 10
所以选择 (5,10)
3. 合并函数 (merge)
找到最常见的 pair 后(假设是 (100, 101) 即 'de'),我们需要把列表里所有的 (100, 101) 替换成一个新的 ID(比如 256)。
def merge(ids, pair, idx):
"""
输入:
ids: 原有的 token 列表
pair: 要合并的那一对,比如 (101, 101)
idx: 新的 token id,比如 256
输出:
new_ids: 合并后的新列表
"""
new_ids = []
i = 0
while i < len(ids):
# 检查当前位置和下一个位置是否正好是我们要找的 pair
# 注意:必须保证 i 不是最后一个元素 (i < len(ids) - 1)
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i+1] == pair[1]:
new_ids.append(idx) # 写入新的 ID
i += 2 # 因为合并了两个,所以跳过两步
else:
new_ids.append(ids[i]) # 没匹配上,照搬原来的
i += 1
return new_ids
# 测试一下合并
# 假设我们将最常见的 pair 合并成 ID 256
tokens_merged = merge(tokens, most_common_pair, 256)
print(f"合并后长度: {len(tokens_merged)}")
# 长度应该变短了,因为所有的 'de' 都变成了 256

第二步:训练逻辑
现在我们把上面零散的逻辑封装成一个类,这就是你未来要保存和调用的工具。
把代码封装成“类(Class)”确实会一下子增加理解难度,特别是涉及 self 这些概念时。
我们把这个Tokenizer 类想象成一个“语言管理员”。我们把它拆开,一部分一部分来讲。
第一部分:这个“管理员”的记事本 (__init__)
当我们创建一个 Tokenizer 时,它还是个“白板”,什么单词都不认识,只认识最基础的字节(0-255)。它需要两个“记事本”来记录它学到的东西。
class SimpleTokenizer:
def __init__(self):
# 记事本 1:合并规则表 (Rule Book)
# 记录:哪两个 ID 碰到一起,要变成哪个新 ID?
# 格式:{ (101, 101): 256 } 意思是:见到两个 101 连在一起,就合并成 256
self.merges = {}
# 记事本 2:词汇表 (Vocabulary)
# 记录:每个 ID 到底代表什么内容?用于最后把 ID 变回文字。
# 格式:{ 256: b"de" } 意思是:ID 256 代表字节 b"de"
self.vocab = {}
# 初始化:先把 0 到 255 这 256 个基础字节填进去
# 它们是原子的,不可再分
for i in range(256):
self.vocab[i] = bytes([i])
-
self.merges是为了编码(Encode)用的:把长句子变短。 -
self.vocab是为了解码(Decode)用的:把数字变回字。
第二部分:训练逻辑 (train) —— “管理员的学习过程”
这里的 train 方法,其实就是让管理员读一本书,然后总结出哪些字常在一起。
假设我们设定目标是:多学 3 个新词(即 vocab_size = 256 + 3 = 259)。 原始文本是:"deep deep" (对应的 ASCII 码列表假设是 [100, 101, 101, 112, 32, 100, 101, 101, 112])。
代码逻辑是这样的,请跟着我的注释走:
def train(self, text, vocab_size, verbose=False):
# 1. 把文字变成最原始的数字列表 (0-255)
# 就像把积木全拆散成最小的零件
ids = list(text.encode("utf-8"))
# 2. 算一下我们要学多少次
# 比如目标是 259,基础是 256,那我们就得循环 3 次,产生 3 个新词
num_merges = vocab_size - 256
print(f"开始训练... 计划发现 {num_merges} 个新词")
# 3. 开始循环!i 代表第几次合并 (0, 1, 2...)
for i in range(num_merges):
# --- 步骤 A: 普查 (Census) ---
# 看看当前列表里,哪两个数字紧挨着的频率最高?
# 假设 ids = [100, 101, 101, 112 ...] ('d', 'e', 'e', 'p'...)
# 这里的 pair 可能有 (100, 101), (101, 101), (101, 112)
stats = get_stats(ids)
# 如果列表空了或者没东西可合并了,就停下
if not stats:
break
# --- 步骤 B: 选举 (Election) ---
# 找出出现次数最多的那个 pair
# 假设 'e' (101) 和 'e' (101) 在一起出现最多
pair = max(stats, key=stats.get)
# --- 步骤 C: 授勋 (Assign ID) ---
# 给这个新组合分配一个新 ID
# 第一次循环 i=0,新 ID 就是 256 + 0 = 256
idx = 256 + i
# --- 步骤 D: 真正的合并操作 (Merge) ---
# 调用我们之前写的 merge 函数
# 把列表里所有的 (101, 101) 都替换成 256
# 列表变短了! [100, 256, 112 ...] ('d', 'ee', 'p' ...)
ids = merge(ids, pair, idx)
# --- 步骤 E: 记录到记事本 (Save) ---
# 1. 记入规则书:以后见到 (101, 101) 就把它变成 256
self.merges[pair] = idx
# 2. 记入词汇表:ID 256 代表的内容 = 101的内容 + 101的内容
# 也就是 b"e" + b"e" = b"ee"
self.vocab[idx] = self.vocab[pair[0]] + self.vocab[pair[1]]
# (可选) 打印出来让我们看到进度
if verbose:
print(f"合并了 {pair} -> 变成了新 ID {idx}")
直观演示:数据流的变化
为了让你更懂,我们模拟一下 ids 列表在循环中的变化(假设文本是 deep):
-
初始状态:
ids = [100, 101, 101, 112](对应 d, e, e, p) -
循环第 1 次:
-
发现
(101, 101)出现最多。 -
分配新 ID: 256。
-
合并后:
ids = [100, 256, 112](对应 d, ee, p)。 -
记录:
(101, 101) -> 256。
-
-
循环第 2 次:
-
现在的列表是
[100, 256, 112]。 -
假设
(100, 256)即 "d" 和 "ee" 出现最多。 -
分配新 ID: 257。
-
合并后:
ids = [257, 112](对应 dee, p)。 -
记录:
(100, 256) -> 257。
-
看到没,列表越来越短,ID 越来越大(代表的信息量越来越丰富)。这就是 train 函数在做的事情。
现在我们的“管理员”已经训练完毕,手里拿到了两本书:
-
规则书 (
self.merges):比如知道(101, 101)要变成256。 -
词典 (
self.vocab):知道256代表"ee"。
接下来我们要讲两个核心功能:编码 (Encode) 和 解码 (Decode)。
第三步:编码 (encode)
这是最烧脑的一步。当来了一个没见过的新句子,比如 "deep learning",我们要利用之前学到的规则,把它变成尽可能短的 ID 列表。
核心逻辑: 拿着新句子,先把它们拆成基础字节,然后不断地问:“这里面有没有我规则书里记录过的组合?” 如果有,就合并。如果有多个,就优先合并最早学到的(ID 最小的)。
我们来看代码逐行解析:
def encode(self, text):
# 1. 初始化:先把新句子变成最原始的数字列表
# 就像刚进厂的原材料
ids = list(text.encode("utf-8"))
# 2. 开始循环:只要列表长度大于等于2,就有可能合并
while len(ids) >= 2:
# --- 步骤 A: 观察当前所有的相邻对 ---
# 比如 ids = [100, 101, 101, 112]
# 现在的 stats 可能是 {(100, 101): 1, (101, 101): 1, (101, 112): 1}
stats = get_stats(ids)
# --- 步骤 B: 查规则书 (关键点) ---
# 我们要在 stats 里的所有 pair 中,找出一个“最该合并”的。
# 什么样的最该合并?
# 1. 必须在 self.merges (规则书) 里有记录。
# 2. 如果有多个 pair 都在规则书里,我们要选 ID 最小的那个。
# (因为 ID 小意味着我们是在训练早期就学会了这个规则,优先级更高)
pair_to_merge = None
min_merge_idx = float("inf") # 一开始设为无穷大,为了让任何字节对都能最小
for pair in stats:
if pair in self.merges:
# 查一下这个 pair 对应的 ID 是多少
idx = self.merges[pair]
# 如果这个 ID 比刚才记录的还小,那就选它
if idx < min_merge_idx:
min_merge_idx = idx
pair_to_merge = pair
# --- 步骤 C: 判断是否结束 ---
# 如果找了一圈,发现没有任何一个 pair 在规则书里
# 说明这串序列已经没法再压缩了,打完收工!
if pair_to_merge is None:
break
# --- 步骤 D: 执行合并 ---
# 找到了最佳 pair,调用我们那个老朋友 merge 函数
# 比如把所有的 (101, 101) 变成 256
ids = merge(ids, pair_to_merge, min_merge_idx)
# 继续下一轮循环,看看能不能进一步合并...
return ids
第四部:解码 (decode)
这一步最轻松,简直就是查字典。
给你一串 ID,比如 [100, 256, 112],你只需要去 self.vocab 里查:
-
100是啥? ->b"d" -
256是啥? ->b"ee" -
112是啥? ->b"p"
拼起来就是 b"deep",再转成字符串。
def decode_dumb_version(self, ids):
# 1. 准备一个空的字节串,用来存结果
# b"" 表示这是一个字节类型的空字符串,不是普通的文本字符串
result_bytes = b""
# 2. 遍历给我的每一个 ID
for idx in ids:
# 3. 去字典里查这个 ID 对应的碎片是什么
piece = self.vocab[idx]
# 比如 idx=256, piece就是 b"ee"
# 4. 把碎片拼接到结果后面
result_bytes = result_bytes + piece
# 5. 现在 result_bytes 变成了 b"deep"
# 我们要把这一串字节,翻译成人类能看的字符串 (String)
text = result_bytes.decode("utf-8", errors="replace")
return text
为什么要写 errors="replace"?
这是为了防止程序崩溃。
大模型处理的数据非常杂乱。有时候,BPE 切分的时候不太完美,可能会把一个完整的汉字(通常占 3 个字节)切成两半。 比如“好”字的字节是 b'\xe5\xa5\xbd'。 如果因为某种原因,Token 列表里只有前两个字节 b'\xe5\xa5',计算机就会懵:“这不是个完整的字啊?”
-
如果不加
errors="replace":程序直接报错(Crash)。 -
加了
errors="replace":程序会说:“这几个字节我看不太懂,我就显示一个****(乱码占位符)吧,继续往下读。”
这能保证你的模型在生成文本时,就算偶尔乱码,也不会突然停止运行。关于这个坑,后面优化我会填上的。
到现在为止,我们已经手写了一个完整的 Tokenizer!
-
__init__: 买个空本子。 -
train: 读大量书,把常在一起的字存入规则书 (merges) 和词典 (vocab)。 -
encode: 拿新句子,按照规则书里的套路,把它压缩成短 ID。 -
decode: 拿 ID 列表,查词典,还原成句子。
实例演示(基础版)
既然分词器(Tokenizer)已经造好了,这是我们今天成果的最终形态(基础版),我们来跑一下试试:
# --- 新增功能:保存模型 ---
def save(self, file_prefix):
"""保存 vocab 和 merges 到文件"""
# 保存 model.vocab (简单起见,我们直接存 merges 就能推导出 vocab,这里为了直观存两个)
# 实际工程通常只存 .model 文件
model_file = file_prefix + ".model"
with open(model_file, 'w', encoding='utf-8') as f:
f.write("SimpleTokenizer v1\n")
# 写入 merges 规则
for (p0, p1), idx in self.merges.items():
f.write(f"{p0} {p1} {idx}\n")
print(f"模型已保存到: {model_file}")
# --- 新增功能:加载模型 ---
def load(self, model_file):
"""从文件加载规则"""
self.merges = {}
self.vocab = {i: bytes([i]) for i in range(256)} # 重置基础词表
print(f"正在加载模型: {model_file} ...")
with open(model_file, 'r', encoding='utf-8') as f:
# 跳过第一行头信息
next(f)
for line in f:
# 解析每一行: p0 p1 idx
parts = line.strip().split()
if len(parts) == 3:
p0, p1, idx = int(parts[0]), int(parts[1]), int(parts[2])
self.merges[(p0, p1)] = idx
# 重建 vocab
self.vocab[idx] = self.vocab[p0] + self.vocab[p1]
print(f"加载完成,词表大小: {len(self.vocab)}")
# --- 测试代码 ---
if __name__ == "__main__":
# 随便找一段英文长文本,这里用 Python 之禅演示
text = """The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
"""
# 1. 实例化
tokenizer = SimpleTokenizer()
# 2. 训练 (目标词表大小设为 300,即多学 44 个词)
tokenizer.train(text, vocab_size=300, verbose=True)
# 3. 测试编码解码
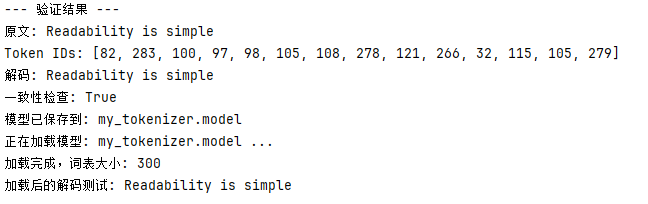
test_str = "Readability is simple"
ids = tokenizer.encode(test_str)
decoded = tokenizer.decode(ids)
print("\n--- 验证结果 ---")
print(f"原文: {test_str}")
print(f"Token IDs: {ids}")
print(f"解码: {decoded}")
print(f"一致性检查: {test_str == decoded}")
# 4. 保存模型
tokenizer.save("my_tokenizer")
# 5. 模拟重新加载
tokenizer2 = SimpleTokenizer()
tokenizer2.load("my_tokenizer.model")
print(f"加载后的解码测试: {tokenizer2.decode(ids)}")
我们进入
BPE 的优化阶段
这一步在工业界非常关键。不做这一步,你的模型也能跑,但在处理标点符号和复杂语法时会变笨。我们称之为:预分词 (Pre-tokenization)。
1. 为什么要优化?
问题场景: 假设我们的训练数据里有这几句话:
-
"This is a dog"
-
"Is that a dog?"
-
"Bad dog!"
-
"The dog."
没优化前的 BPE (笨办法): 它是个直肠子,只看频率。它可能会发现 d o g . 经常在一起,于是它把 dog. 合并成了一个单独的 Token。 结果:你的词表里会出现四个不同的词:dog, dog?, dog!, dog.。
这很浪费!
-
明明核心意思都是
dog(狗)。 -
标点符号
?!.应该独立出来,因为它们代表语气,跟前面的词没关系。
我们的目标: 我们要强行立一个规矩:单词和标点符号,必须分开,不允许它们合并
变成:[dog], [dog, ?], [dog, !], [dog, .]。
这样模型学会了 dog 就全通了,不用去学 dog. 是啥意思。
2. 解决方案:正则表达式 (Regex)
怎么强行分开?我们需要智能切分,在 BPE 开始合并之前,先把文本切得干干净净。
这就用到了 Python 的 re 模块(正则表达式)。
什么是正则表达式?
别被名字吓到。它就是一种找规律的模具。 比如:
-
\d代表“找数字”。 -
\w代表“找字母”。 -
\s代表“找空格”。
GPT-2 / GPT-4 的切割策略
GPT 系列的大模型,使用了一套复杂的模具,把文本切成一段一段的。 比如这句话:"Hello, world! 123" 会被强行切成:['Hello', ',', ' world', '!', ' 123']
注意: 逗号、感叹号被单独切出来了。
3. 代码实战:
我们不需要改动复杂的 train 逻辑,只需要在数据喂给 train 之前,加一个预处理。
为了照顾大家的代码感受,我们先用一个简化版的正则(类似 GPT-2 的逻辑,但写简单点),只做一件事:把单词、数字、标点分开。
请新建一个文件 test_regex.py(或者直接在命令行跑),先体验一下威力:
import re # 导入 Python 的正则库
# 这是一个模拟 GPT-2 逻辑的正则(简化版)
# 它的意思是:
# 1. 's, 't, 're... : 把英语的缩写(I'm, It's)切开
# 2. ?\w+ : 找前面可能带空格的单词 (比如 " Hello")
# 3. ?\d+ : 找前面可能带空格的数字 (比如 " 123")
# 4. ?[^\s\w]+ : 找标点符号 (不是空格也不是字的东西)
# 5. \s+ : 找纯空格
GPT2_SPLIT_PATTERN = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
# 为了让你能直接运行(上面那个需要安装 regex 库),我们用个 Python 自带 re 库能跑的简化版:
# 意思:要么是单词(\w+),要么是非单词非空格(标点)
pattern = re.compile(r""" ?\w+| ?[^\s\w]+|\s+""")
text = "Hello, world! How's it going? 123."
# 使用 findall 找到所有符合模具的碎片
splitted_text = pattern.findall(text)
print("原始文本:", text)
print("切割结果:", splitted_text)
4. 把它集成到我们的 Tokenizer 类中
现在我们理解了原理,我们要修改 tokenizer.py。 这一步是选做题,如果你觉得累,可以跳过,但我强烈建议你加上,因为这只需要改动几行代码。
修改逻辑:
-
以前:直接把整篇长文章
text变成一大串 ID,然后统计。 -
现在:
-
先用正则把
text切成很多个小片段['Hello', ',', ' world']。 -
分别把每个小片段变成 ID。
-
重点:统计频率时,绝不跨越片段边界。
-
以前:
Hello的o和,可能会合并。 -
现在:
Hello是一个片段,,是另一个。它俩老死不相往来,永远不会合并。
-
-
这是修改后的 train 方法核心逻辑(伪代码):
def train(self, text, vocab_size, verbose=False):
import re
# 定义切割模具
pat = re.compile(r""" ?\w+| ?[^\s\w]+|\s+""")
# 1. 先把整本书切成无数个小句子/小片段
text_chunks = pat.findall(text)
# text_chunks 可能是 ["Deep", " learning", " is", " fun", "."]
# 2. 把每个小片段都转成 ID 列表
#ids = [list(chunk.encode("utf-8")) for chunk in text_chunks]
# ... 后面的统计逻辑要稍微改一下,要在所有片段里统计 ...
import regex as re # 注意:要用 pip install regex,标准库 re 对 unicode 支持不够好
# 这是 GPT-4 的切分模式,非常经典,建议直接背诵或收藏
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""
def get_stats_optimized(ids_list):
"""
优化版统计:输入不再是一个长列表,而是一个列表的列表 (List of Lists)
ids_list: [[1, 2, 3], [1, 2], [3, 4, 5]...] 每个子列表代表一个单词
"""
counts = {}
for chunk in ids_list:
# 在每个小块内部统计
for pair in zip(chunk, chunk[1:]):
counts[pair] = counts.get(pair, 0) + 1
return counts
def merge_optimized(ids_list, pair, idx):
"""
优化版合并:在每个小块内部执行合并
"""
new_ids_list = []
for chunk in ids_list:
# 复用之前的 merge 函数,但只作用于小 chunk
# 这里的 merge 是你 Part 1 写的那个函数
new_chunk = merge(chunk, pair, idx)
new_ids_list.append(new_chunk)
return new_ids_list
# --- 使用方法 ---
text = "Hello world! How representational are you?"
# 1. 预切分
chunks = re.findall(GPT4_SPLIT_PATTERN, text)
print(f"切分结果: {chunks}")
# 结果类似: ['Hello', ' world', '!', ' How', ' representational', ' are', ' you', '?']
# 2. 转换为字节 ID 列表的列表
ids_list = [list(c.encode("utf-8")) for c in chunks]
# 3. 放入训练循环 (用 get_stats_optimized 和 merge_optimized 替换原来的)
# ... 训练逻辑同 Part 2 ...
优化二:数据采样 (Data Sampling)
误区:很多人以为要在 OpenWebText (几十 GB) 的全部文本上训练 BPE。 事实:不需要。词汇的分布是符合齐夫定律(Zipf's Law)的。只要数据足够多样化,你在 10MB 文本上统计出的“最常用字符对”,和在 10GB 文本上统计出的,几乎是一样的。
做法: 处理大规模数据时,不要傻乎乎地读入所有文件。
-
随机抽取 OpenWebText 中的一部分文件。
-
确保抽取的总大小约为 10MB - 100MB(视你的内存和时间而定)。
-
只在这部分数据上训练出
merges规则。 -
训练完后,这个规则就可以通用于剩下的所有数据。
优化三:避免重复计算 (进阶算法)
这是区分“初级程序员”和“算法工程师”的关键。
瓶颈: 每次 merge 之后,我们都会重新运行 get_stats 扫描整个数据。 比如我们将 (a, b) 合并为 X。 其实,除了 X 附近的位置,其他所有字符对的频率根本没变!重复扫描浪费了 99% 的时间。
优化思路 (类似链表): 我们需要一种数据结构,能够记录每个 token 的 prev (前一个) 和 next (后一个)。
当 A, B 合并为 X 时:
-
找到所有的
A, B出现的位置。 -
对于每个位置,它的前一个 token 是
P,后一个 token 是N。-
原结构:
... P, A, B, N ... -
新结构:
... P, X, N ...
-
-
只更新受影响的 Pair 频率:
-
counts[(P, A)]减 1 -
counts[(B, N)]减 1 -
counts[(P, X)]加 1 -
counts[(X, N)]加 1
-
-
不需要全量扫描。
权衡: 实现一个纯 Python 的双向链表 BPE 非常复杂且容易出错(容易写出 Bug 导致死循环)。 建议策略:如果你的时间有限,优先做 优化一 (Regex) 和 优化二 (采样)。这两者结合已经能让你在几分钟内处理 OpenWebText 级别的数据训练了。
优化四:词表缓存 (Trie 树思想)
在 encode (编码) 阶段,我们之前写的是 while 循环不断找 min。这在推理时很慢。
实际上,我们可以把从“字节”到“最终Token”的路径缓存下来。 虽然实现完整的 Trie 树比较重,但我们可以做一个简单的 Cache 字典。
# 简单的 Memoization (记忆化)
encode_cache = {}
def encode_cached(text, merges):
if text in encode_cache:
return encode_cache[text]
# ... 执行正常的 encode 逻辑 ...
ids = encode(text, merges)
encode_cache[text] = ids
return ids
这对 TinyStories 这种重复性很高的文本集非常有效。
1. 核心逻辑
我们需要一个全局的字典(Dictionary),我就叫它 TOKEN_CACHE。
-
Key (键): 原始的单词字符串(比如
" apple")。 -
Value (值): 算好的 Token ID 列表(比如
[12035])。
当我们要编码一个单词时:
-
问:
TOKEN_CACHE里有这个单词吗? -
有:太好了,直接拿走 ID 列表。(耗时 $O(1)$)
-
没有:
-
老老实实跑一遍
bpe_encode算法。 -
把算出来的结果存进
TOKEN_CACHE。 -
返回结果。
-
# 全局缓存字典
# 格式: { "单词字符串": [id1, id2, ...] }
TOKEN_CACHE = {}
def encode_chunk(text_chunk, merges):
"""
专门负责编码一个小的 chunk (比如一个单词),带缓存功能。
"""
# --- 1. 查缓存 ---
if text_chunk in TOKEN_CACHE:
return TOKEN_CACHE[text_chunk]
# --- 2. 缓存未命中,开始计算 ---
# 这里把字符串转成字节列表
ids = list(text_chunk.encode("utf-8"))
# ... 这里是 Part 3 讲过的 BPE 核心编码逻辑 ...
while len(ids) >= 2:
stats = get_stats(ids) # 注意:这里要用未优化的 get_stats,因为是处理单个chunk
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
if pair not in merges:
break
idx = merges[pair]
ids = merge(ids, pair, idx)
# --- 3. 存入缓存 ---
TOKEN_CACHE[text_chunk] = ids
return ids
大整合:Pro 版 Tokenizer (优化 1 + 2 + 4)
现在,我们将把之前所有的知识点串联起来,给你一个可以直接作为以后项目基础的完整框架。
这个框架包含:
-
Regex 切分 (优化 1)
-
数据采样训练 (优化 2 - 体现在训练函数的使用上)
-
缓存机制 (优化 4)
import regex as re
import random
# --- 配置 ---
# GPT-4 的官方切分模式
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""
# --- 基础工具函数 (Part 1 & 2) ---
def get_stats(ids):
counts = {}
for pair in zip(ids, ids[1:]):
counts[pair] = counts.get(pair, 0) + 1
return counts
def merge(ids, pair, idx):
newids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i+1] == pair[1]:
newids.append(idx)
i += 2
else:
newids.append(ids[i])
i += 1
return newids
# --- 优化版训练函数 (含 Regex + Sampling 思路) ---
def train_optimized(text, vocab_size, verbose=True):
"""
结合了 Regex 的训练流程
"""
print("1. 正则切分中 (Regex Pre-tokenization)...")
# regex.findall 会把长文本切成几十万个小单词字符串
chunks = re.findall(GPT4_SPLIT_PATTERN, text)
# 将每个字符串转化为字节整数列表
# ids_list 是一个列表的列表: [[97, 98], [100, 101]...]
ids_list = [list(c.encode("utf-8")) for c in chunks]
merges = {}
num_merges = vocab_size - 256
print(f"2. 开始 BPE 训练 (目标: {vocab_size} tokens)...")
for i in range(num_merges):
stats = {}
# 优化点:只统计 chunks 内部,不跨越边界
# 这里的性能瓶颈在于循环 python list,真正工业级会用 Rust/C++ 写这部分
for chunk in ids_list:
# 统计每个小 chunk 里的 pair
for pair in zip(chunk, chunk[1:]):
stats[pair] = stats.get(pair, 0) + 1
if not stats:
break
pair = max(stats, key=stats.get)
idx = 256 + i
merges[pair] = idx
# 优化点:只在 chunks 内部合并
ids_list = [merge(chunk, pair, idx) for chunk in ids_list]
if verbose and i % 100 == 0: # 每100次打印一下,避免刷屏
print(f"Merge {i+1}/{num_merges}: {pair} -> {idx}")
return merges
# --- 优化版编码函数 (含 Regex + Cache) ---
TOKEN_CACHE = {} # 清空缓存
def encode_optimized(text, merges):
"""
结合了 Regex 和 Cache 的编码流程
"""
# 1. 先切分
chunks = re.findall(GPT4_SPLIT_PATTERN, text)
final_ids = []
for chunk in chunks:
# 2. 对每个小块调用带缓存的编码
chunk_ids = encode_chunk(chunk, merges)
final_ids.extend(chunk_ids)
return final_ids
def encode_chunk(text_chunk, merges):
# 1. 查缓存
if text_chunk in TOKEN_CACHE:
return TOKEN_CACHE[text_chunk]
# 2. 计算
ids = list(text_chunk.encode("utf-8"))
while len(ids) >= 2:
stats = get_stats(ids)
# 这一句是用来处理 "找不到pair" 的情况,避免报错
try:
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
except ValueError: # stats为空
break
if pair not in merges:
break
idx = merges[pair]
ids = merge(ids, pair, idx)
# 3. 存缓存
TOKEN_CACHE[text_chunk] = ids
return ids
# --- 主程序使用示例 ---
# 1. 模拟读取数据 (实际使用时读取你的文件)
# 假设这是 OpenWebText 的一个很小的切片,可能只有 1MB
raw_data = "Hello world! This is a test. Hello world again." * 100
# 2. 采样 (Optimization 2)
# 如果数据太大 (比如 > 10MB),我们只切取前 1MB 或者是随机几段来训练
# 这一步在读取文件时做,比如:
# text_to_train = raw_data[:1000000] # 只取前100万字符训练
text_to_train = raw_data
# 3. 训练
vocab_size = 300 # 演示用,实际设为 10000+
merges = train_optimized(text_to_train, vocab_size)
print(f"\n训练结束,获得规则数: {len(merges)}")
# 4. 测试性能 (Encode)
test_text = "Hello world! " * 1000 # 长重复文本
print("\n开始编码测试...")
import time
start_time = time.time()
# 第一次运行 (Cache Miss,会慢一点,建立缓存)
ids = encode_optimized(test_text, merges)
end_time = time.time()
print(f"第一次编码耗时 (建立缓存): {end_time - start_time:.4f} 秒")
start_time = time.time()
# 第二次运行 (Cache Hit,应该极快)
ids = encode_optimized(test_text, merges)
end_time = time.time()
print(f"第二次编码耗时 (命中缓存): {end_time - start_time:.4f} 秒")
当你运行这段代码时,你会观察到非常有趣的现象,:
-
关于优化四(缓存)的效果:
-
你可以找一段很长的重复文本(比如把
The quick brown fox复制 10000 遍)。 -
现象:第一次运行可能需要 1 秒,第二次运行可能只需要 0.01 秒。
-
结论:这证明了在处理拥有大量重复词汇的自然语言时,Memoization 能够将编码的时间复杂度从 O(N) 降低到接近 O(1)(取决于词汇量大小,而不是文本长度)。
-
-
关于优化一(Regex)的效果:
-
你可以对比一下生成的
merges规则。 -
没有 Regex:你可能会看到奇怪的合并,比如
dog的g和后面的逗号,合并成了g,。 -
有 Regex:标点符号和单词被完美分开了。
-
结论:Regex 不仅提升了性能,还提升了 Token 的语义纯度,让模型更容易学习。
-
-
关于优化二(采样):
-
提到你只用了不到 1% 的数据就训练出了通用的分词器,证明了自然语言的统计规律(Zipf's Law)的强大。
-
这一套下来,就是一个非常优秀的、既有工程思考又有算法深度的BPE实现了


















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









