








问题描述
将字符串中的数字提取出来并返回为结果
--提取前-- >>>> ---提取后---
OLD_MIXED NEW_MIXED
--------- >>>> ----------
ORACLE
520 520
521 521
13DB14BD 1314
2DB2 22
3M3D 33
ZH11AN31 1131
DBA10ABD 10
MYSQL
POSTGRESQL
--------- >>>> ----------
构造测试数据
drop table t_num;
create table t_num(tid int,tmixed varchar(10));
insert into t_num values(1,'ORACLE');
insert into t_num values(2,'520');
insert into t_num values(3,'521');
insert into t_num values(4,'13DB14BD');
insert into t_num values(5,'2DB2');
insert into t_num values(6,'3M3D');
insert into t_num values(7,'ZH11AN31');
insert into t_num values(8,'DBA10ABD');
insert into t_num values(9,'MYSQL');
insert into t_num values(10,'POSTGRESQL');
-- tid的个数需要 >= tname列的数据最大长度
drop table t_10;
create table t_10(tid int);
insert into t_10 values(1);
insert into t_10 values(2);
insert into t_10 values(3);
insert into t_10 values(4);
insert into t_10 values(5);
insert into t_10 values(6);
insert into t_10 values(7);
insert into t_10 values(8);
insert into t_10 values(9);
insert into t_10 values(10);
commit;
函数认识
translate
字符转换函数
TRANSLATE(x,from_string,to_string)函数在x中查找from_string中的字符,并将其转换成to_string中对应的字符
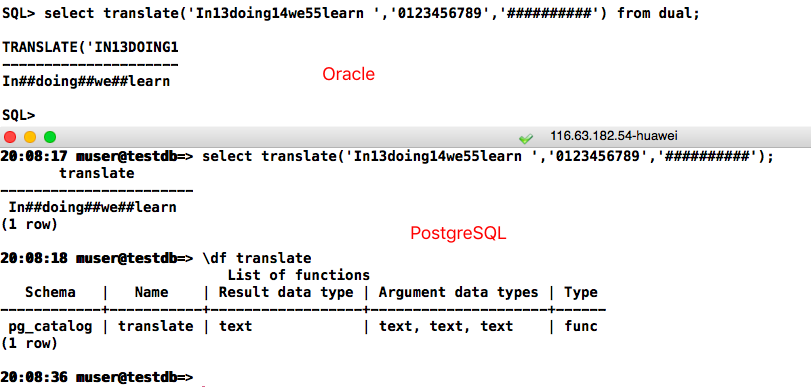
-- Oracle
select translate('In13doing14we55learn ','0123456789','##########') from dual;
-- postgresql
select translate('In13doing14we55learn ','0123456789','##########');
replace
字符替换函数
- PostgreSQL的replace替换函数需要3个入参
-- Oracle,默认替换成空字符串 ''
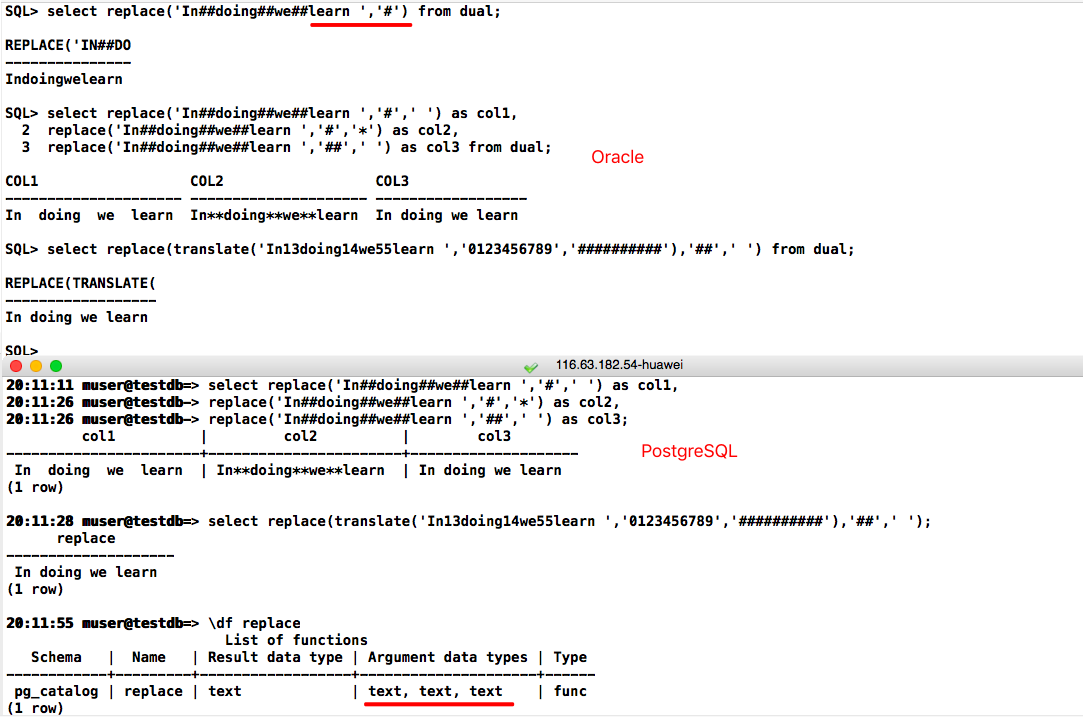
select replace('In##doing##we##learn ','#') from dual;
-- postgresql 等价写法
select replace('In##doing##we##learn ','#','');
-- postgresql/Oracle
select replace('In##doing##we##learn ','#',' ') as col1,
replace('In##doing##we##learn ','#','*') as col2,
replace('In##doing##we##learn ','##',' ') as col3;
select replace(translate('In13doing14we55learn ','0123456789','##########'),'##',' ');
rpad
往源字符串的左/右侧填充字符
rpad( string1, padded_length, [ pad_string ] )
- string1:源字符串
- padded_length:最终返回的字符串长度,若最终返回的字符串的长度比源字符串的小,那么此函数实际上对源字符串进行截断处理
- pad_string:用于填充的字符,循环填充,不填默认为空字符
select rpad('newday',3),rpad('newday',3,'G'),rpad('newday',8,'G'),rpad('newday',11,'GO');

lpad 则是往左侧填充,用法等同
instr
字符位置查找函数
-- 格式一:instr(源字符串, 目标字符串)
instr( string1, string2 )
-- 格式二:instr(源字符串, 目标字符串)
instr( string1, string2 [, start_position [, nth_appearance ] ] )
解析:string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2
注:在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。只检索一次,也就是说从字符的开始到字符的结尾就结束。
20:13:15 pg14@postgres=# \df instr
List of functions
-[ RECORD 1 ]-------+-----------------------------------------------------------------------------------------------------
Schema | public
Name | instr
Result data type | integer
Argument data types | string character varying, string_to_search character varying, beg_index integer, occur_index integer
Type | func
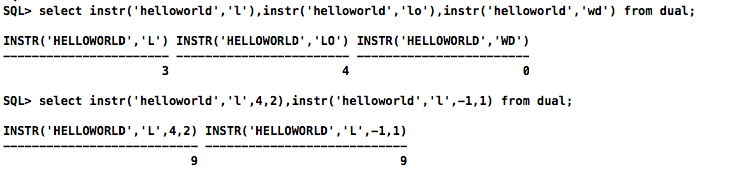
-- 默认第一次出现“l”的位置;第一次出现“lo”时第一个字母“l”出现的位置;匹配不到返回0
select instr('helloworld','l'),instr('helloworld','lo'),instr('helloworld','wd') from dual;
-- 第4(l)号位置开始查找第2次出现的“l”的位置;倒数第1(d)号位置开始往回查找第一次出现的“l”的位置
select instr('helloworld','l',4,2),instr('helloworld','l',-1,1) from dual;
strpos
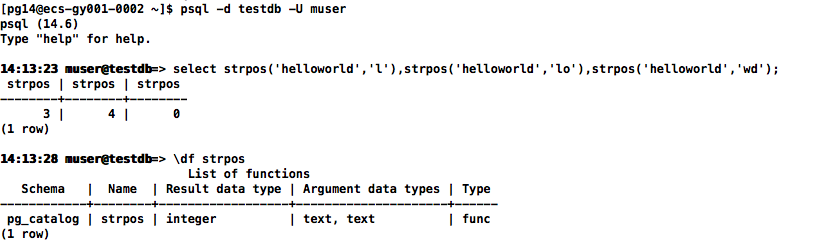
在PostgreSQL数据库没有instr函数,可以用strpos函数替代
11:44:21 muser@testdb=> \df strpos
List of functions
Schema | Name | Result data type | Argument data types | Type
------------+--------+------------------+---------------------+------
pg_catalog | strpos | integer | text, text | func
(1 row)
select strpos('helloworld','l'),strpos('helloworld','lo'),strpos('helloworld','wd');
也可以通过自定义函数来代替instr的实现:
-- 实现 1
CREATE FUNCTION instr(varchar, varchar) RETURNS integer AS
$$ DECLARE pos integer;
BEGIN
pos := instr($1, $2, 1);
RETURN pos;
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
-- 实现 2
CREATE FUNCTION instr(string varchar,
string_to_search varchar,
beg_index integer) RETURNS integer AS
$$ DECLARE pos integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
length integer;
ss_length integer;
BEGIN
IF beg_index > 0 THEN
temp_str := substring(string FROM beg_index);
pos := position(string_to_search IN temp_str);
IF pos = 0 THEN
RETURN 0;
ELSE
RETURN pos + beg_index - 1;
END IF;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search);
length := char_length(string);
beg := length + beg_index - ss_length + 2;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
pos := position(string_to_search IN temp_str);
IF pos > 0 THEN
RETURN beg;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
-- 实现 3
CREATE FUNCTION instr(string varchar,
string_to_search varchar,
beg_index integer,
occur_index integer) RETURNS integer AS
$$ DECLARE pos integer NOT NULL DEFAULT 0;
occur_number integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
i integer;
length integer;
ss_length integer;
BEGIN
IF beg_index > 0 THEN
beg := beg_index;
temp_str := substring(string FROM beg_index);
FOR i IN 1 .. occur_index LOOP
pos := position(string_to_search IN temp_str);
IF i = 1 THEN
beg := beg + pos - 1;
ELSE
beg := beg + pos;
END IF;
temp_str := substring(string FROM beg + 1);
END LOOP;
IF pos = 0 THEN
RETURN 0;
ELSE
RETURN beg;
END IF;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search);
length := char_length(string);
beg := length + beg_index - ss_length + 2;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
pos := position(string_to_search IN temp_str);
IF pos > 0 THEN
occur_number := occur_number + 1;
IF occur_number = occur_index THEN
RETURN beg;
END IF;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plpgsql STRICT IMMUTABLE;
substr
字符串截取函数
substr(参数1,参数2[,参数3]):该函数返回被截后的子字符串
- 参数1为要截取的字符串
- 参数2为截取的开始位置
- 参数3可选,表示截取长度,默认截取到末尾
pg和mysql的substr()函数的第一个位置都是为1的,pg为0的时候返回数据是有值的,但mysql为0时候返回数据为空
-- PostgreSQL
select substr('abcdef',1),substr('abcdef',8),substr('abcdef',0,3),substr('abcdef',1,3),substr('abcdef',-2),substr('abcdef',-3,2);
-- Oracle
select substr('abcdef',1),substr('abcdef',8),substr('abcdef',0,3),substr('abcdef',1,3),substr('abcdef',-2),substr('abcdef',-3,2) from dual;
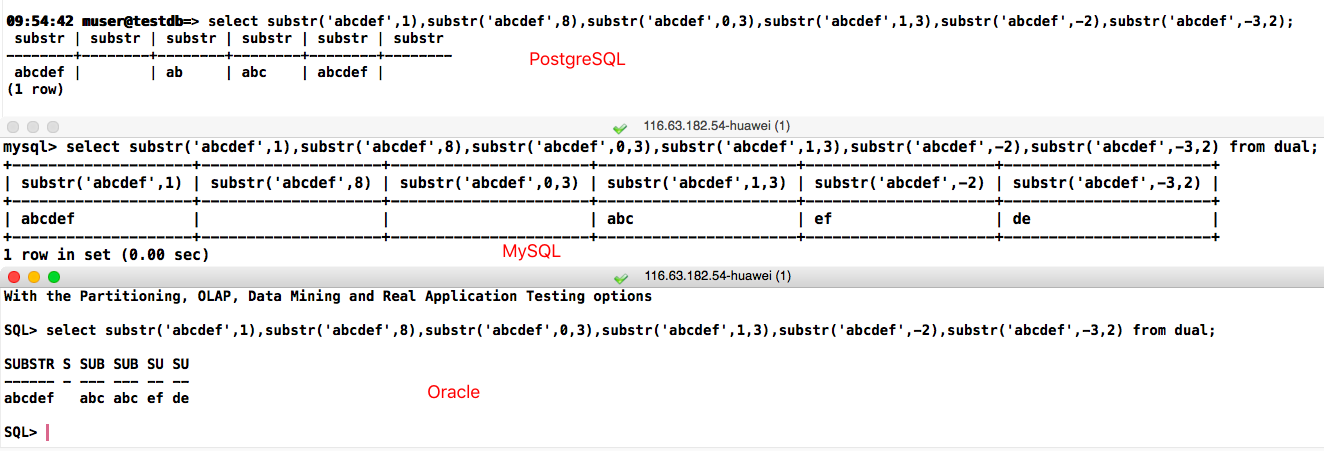
- 在 oracle 中,substr(x, 0, 3)与substr(x, 1, 3)的意思相同,都是截取第一个到第三个元素
- 在 postgresql 中,substr(x, 0, 3)截取前两位元素,substr(x, 1, 3)截取前三位元素
- 在 mysql 中,substr(x, 0, 3)返回空字符串’',substr(x, 1, 3)截取前三位元素
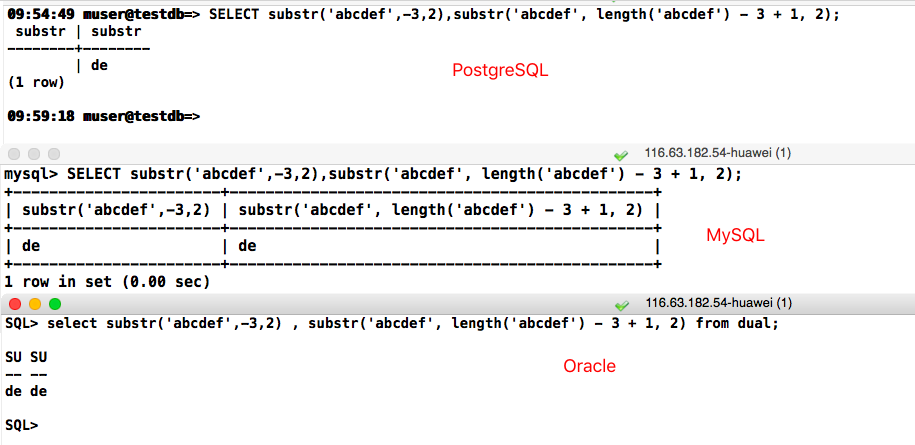
substr参数为负数时结果不一致,由于截取方式不同,Oracle负数是从右开始计算下标,Postgre负数依旧是从左开始计算下标,可以通过长度计算获取开始截取的下标
-- PostgreSQL
SELECT substr('abcdef',-3,2),substr('abcdef', length('abcdef') - 3 + 1, 2);
-- Oracle
select substr('abcdef',-3,2) , substr('abcdef', length('abcdef') - 3 + 1, 2) from dual;
ascii
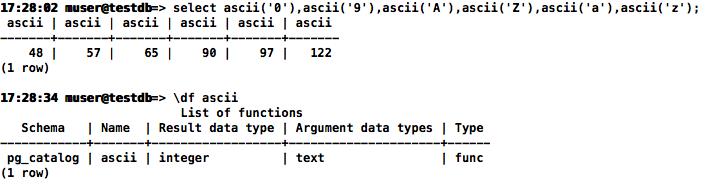
获取字符对应的ascii值
字符 ‘0’ ~ ‘9’ 对应十进制数字 48 ~ 57
字符 ‘A’ ~ ‘Z’ 对应十进制数字 65 ~ 90
字符 ‘a’ ~ ‘z’ 对应十进制数字 97 ~ 122
select ascii('0'),ascii('9'),ascii('A'),ascii('Z'),ascii('a'),ascii('z');
Oracle
select tid,tmixed as old_mixed,to_number(
case when replace(translate(tmixed,'0123456789','9999999999'),'9') is not null
then replace(translate(tmixed,replace(translate(tmixed,'0123456789','9999999999'),'9'),rpad('#',length(tmixed),'#')),'#')
else tmixed
end
) as new_mixed
from t_num
where instr(translate(tmixed,'0123456789','9999999999'),'9') > 0;
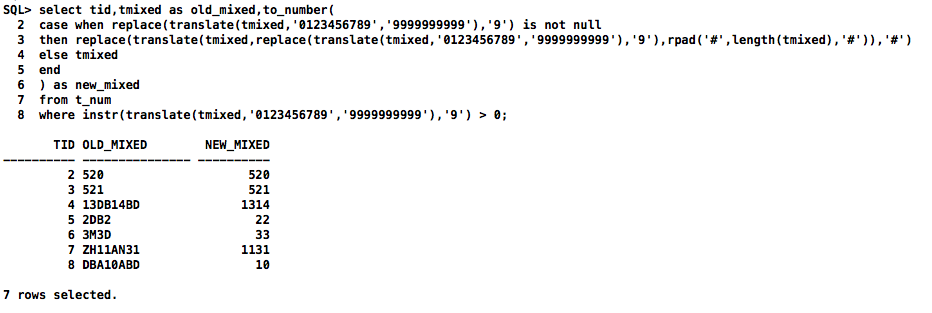
拆分理解:
col old_mixed format a15
col col1 format a15
col col2 format a15
col col3 format a15
select tid,tmixed as old_mixed,
replace(translate(tmixed,'0123456789','9999999999'),'9') as col1,
rpad('#',length(tmixed),'#') as col2,
replace(translate(tmixed,replace(translate(tmixed,'0123456789','9999999999'),'9'),rpad('#',length(tmixed),'#')),'#') as col3
from t_num;

过滤条件where将数字都转换成9再获取第一次出现9的位置,以此来区分该行数据是否存在数字【 >0 】
select tid,tmixed,instr(translate(tmixed,'0123456789','9999999999'),'9') from t_num;
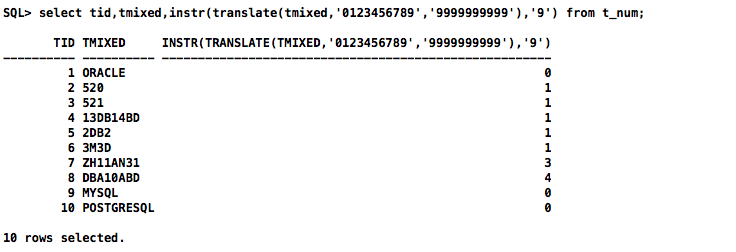
PostgreSQL
select tid,tmixed as old_mixed,cast(
case when replace(translate(tmixed,'0123456789','9999999999'),'9','') is not null
then replace(translate(tmixed,replace(translate(tmixed,'0123456789','9999999999'),'9',''),rpad('#',length(tmixed),'#')),'#','')
else tmixed
end as integer
) as new_mixed
from t_num
where strpos(translate(tmixed,'0123456789','9999999999'),'9') > 0;
子查询部分同Oracle,区别在于replace函数写法需要写明替换的第三个入参,替换成空字符,过滤条件where拆分:处理函数不同,但原理等同
select
tid,tmixed,
translate(tmixed,'0123456789','9999999999'),
strpos(translate(tmixed,'0123456789','9999999999'),'9')
from t_num;
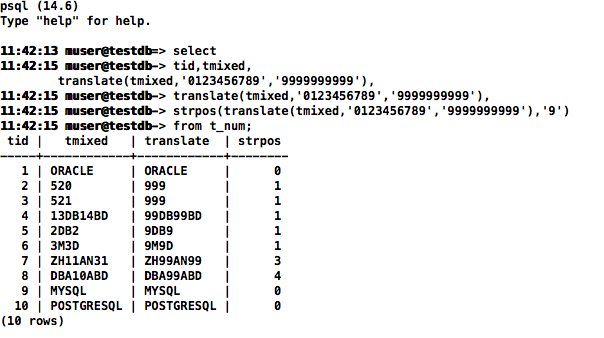
MySQL
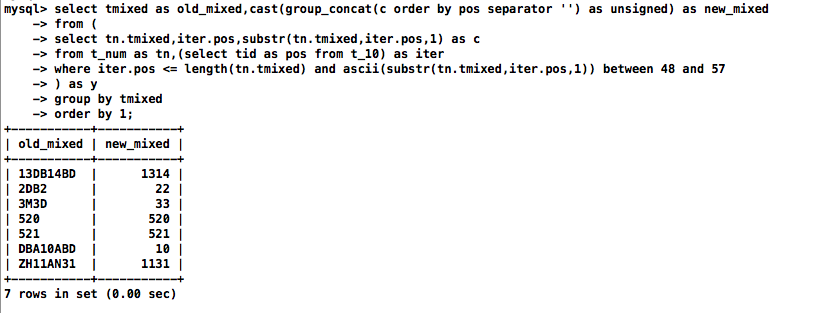
MySQL不支持translate函数,因此需遍历每一行数据并逐字符对其进行处理,使用group_concat将数字拼接起来得到tmixed完整的数字部分,再将结果转换为数字unsigned
select tmixed as old_mixed,cast(group_concat(c order by pos separator '') as unsigned) as new_mixed
from (
select tn.tmixed,iter.pos,substr(tn.tmixed,iter.pos,1) as c
from t_num as tn,(select tid as pos from t_10) as iter
where iter.pos <= length(tn.tmixed) and ascii(substr(tn.tmixed,iter.pos,1)) between 48 and 57
) as y
group by tmixed
order by 1;
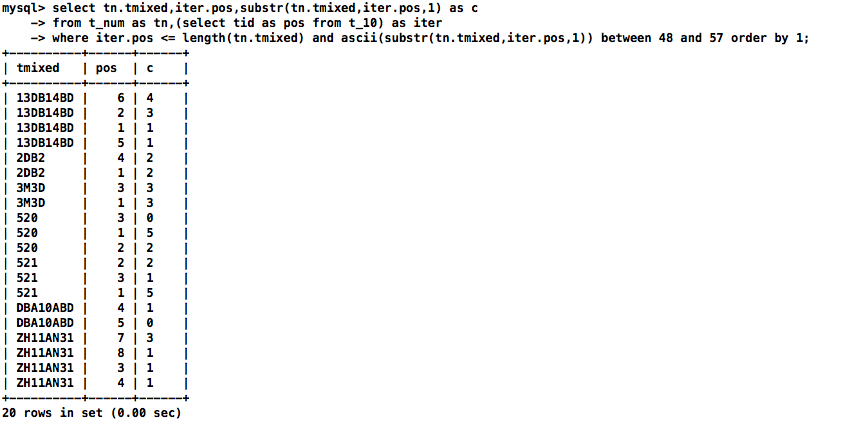
拆分认识:遍历所有字符并过滤ascii值为0~9的,即提取数字字符
select tn.tmixed,iter.pos,substr(tn.tmixed,iter.pos,1) as c
from t_num as tn,(select tid as pos from t_10) as iter
where iter.pos <= length(tn.tmixed) and ascii(substr(tn.tmixed,iter.pos,1)) between 48 and 57 order by 1;

















 7
7

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









