




组的概念
小括号来定义组: ()
定义组的方式
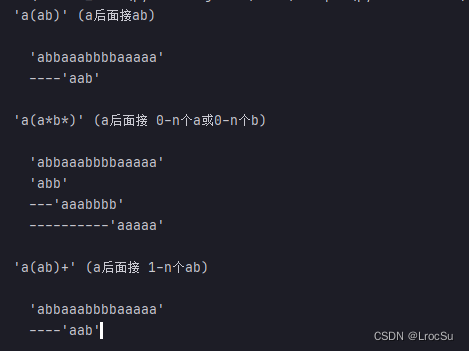
测试例子:
test_patterns(
'abbaaabbbbaaaaa',
[('a(ab)', 'a后面接ab'),
('a(a*b*)', 'a后面接 0-n个a或0-n个b'),
('a(ab)+', 'a后面接 1-n个ab')],
)
输出:
解析组
用组来解析的示例:
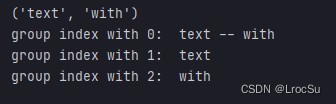
# 用组来解析
text = 'This is some text -- with punctuation.'
regex = re.compile(r'(\bt\w+)\W+(\w+)')
match = regex.search(text)
print(match.groups())
print("group index with 0: ", match.group(0))
print("group index with 1: ", match.group(1))
print("group index with 2: ", match.group(2))
输出的内容:
命名组
格式: (?Ppattern)
可以让匹配的组的内容一个字典的模式进行获取,?P 相当于给它添加个Key
命名组的使用方式:
text = 'This is some text -- with punctuation.'
regex = re.compile(r'(?P<t_word>\bt\w+)\W+(?P<other_word>\w+)')
match = regex.search(text)
print(' ', match.groups())
print(' ', match.groupdict())
输出:

尝试使用
更新前面的测试函数,添加进去匹配的组:
def test_patterns(text, patterns):
for pattern, desc in patterns:
print('{!r} ({})\n'.format(pattern, desc))
print(' {!r}'.format(text))
for match in re.finditer(pattern, text):
s = match.start()
e = match.end()
prefix = ' ' * (s)
print(
' {}{!r}{} '.format(prefix,
text[s:e],
' ' * (len(text) - e)),
end=' ',
)
print("匹配的组: ", match.groups())
if match.groupdict():
print("匹配的组字典: ", '{}{}'.format(
' ' * (len(text) - s),
match.groupdict()),
)
print()
return
测试的代码:
test_patterns(
'abbaabbba',
[(r'a((a*)(b*))', 'a后面接 0-n个a或0-n个b'),
(r'a((a+)|(b+))', 'a 后面接多个a 或接多个b'),
(r'a((?:a+)|(?:b+))', '非捕获组的模式'),
(r'a((a|b)+)', 'a 后面接[ab] 一个或多个 其实就是ab的交替'),
],
)
输出内容:

非捕获组
上例子中提到了一个非捕获组的模式。
非捕获组,定义包含子模式的组。它使该组不被捕获,这意味着与该组匹配的子字符串将不包括在捕获列表中。
观察下面的测试例子的区别:

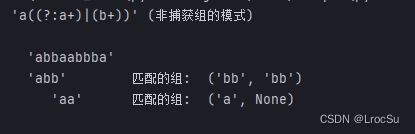
观察以上两图,被 ?: 描述的组匹配的子字符串将不包括在捕获列表中。
搜索模式附加的选项
用法一
● 使用的函数 compile() search() match()
● 使用OR拼接多种搜索选项
搜索选项包括的参数:
- IGNORECASE 忽略大小写,正则匹配中忽略大小写。
text = 'This is some text -- with punctuation.'
pattern = r'\bT\w+'
with_case = re.compile(pattern) # 不忽略大小写
without_case = re.compile(pattern, re.IGNORECASE) # 忽略大小写
- MULTILINE 将有换行符的字符串当成多行处理—> 直接影响^$的锚定效果
text = 'This is some text -- with punctuation.\nA second line.'
pattern = r'(^\w+)|(\w+\S*$)'
single_line = re.compile(pattern) # 单行模式
multiline = re.compile(pattern, re.MULTILINE) # 多行模式
- DOTALL 可以允许点字符可以匹配换行符。
text = 'This is some text -- with punctuation.\nA second line.'
pattern = r'.+'
no_newlines = re.compile(pattern) # .不可以匹配\n
dotall = re.compile(pattern, re.DOTALL) # .能够匹配\n
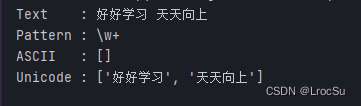
- ASCII python3默认匹配模式和文本都是unicode的,如果定义为非unicode则需要此参数
text = u'好好学习 天天向上'
pattern = r'\w+'
ascii_pattern = re.compile(pattern, re.ASCII)
unicode_pattern = re.compile(pattern)
输出-所以可以在模式里面使用中文的原因:
用法二
如何不以参数的形式,写入模式中这些选项?
将以上的选项嵌入模式中:
比如开启大小写,只需要在模式表达式开头增加(?i)
对比下面效果:
text = 'This is some text -- with punctuation.'
pattern = r'\bT\w+'
with_case = re.compile(pattern) # 不忽略大小写
without_case = re.compile(pattern, re.IGNORECASE) # 忽略大小写
pattern2 = r'(?i)\bT\w+' # 忽略大小写
without_case2 = re.compile(pattern2)
s = with_case.findall(text)
for _ in s:
print("with_case", "pattern", _)
print("------------------------------")
s = without_case.findall(text)
for _ in s:
print("without_case", "pattern", _)
print("------------------------------")
s = without_case2.findall(text)
for _ in s:
print("without_case2", "pattern2", _)
输出效果:
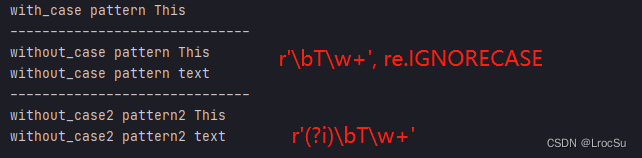
两种方式效果相同,所以在不能指定选项参数的时候,将大小写规则compile进模式中,是一种很好的方法。

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









