




 文章讲述了如何在Linux终端使用Python处理.doc文档,包括使用python-docx生成内容、转换为PDF,以及遇到的问题如是否依赖Office/WPS,最后确认了在CentOS环境下Python-docx包的可用性。还介绍了如何调整表格、样式和插入图片等操作。
文章讲述了如何在Linux终端使用Python处理.doc文档,包括使用python-docx生成内容、转换为PDF,以及遇到的问题如是否依赖Office/WPS,最后确认了在CentOS环境下Python-docx包的可用性。还介绍了如何调整表格、样式和插入图片等操作。

需求
需求总结为:
使用python处理doc文档,生成内容和格式,并将doc转成pdf. 这些要运行在Linux终端,并且不能使用收费的服务。
技术选择
- python选择的包为 python-docx
- doc转pdf选择的是 unoconv
面对的问题和解决
python-docx包相关
office 和 wps包都卸载的情况下,这个包python-docx还能用吗?
提前用这个包将功能写好了,卸载wps后看还能不能使用。
测试结果是毫无问题,程序依然能够运行,不依赖外置的office和wps安装的模块。
Linux 上面能够使用吗?
结论是可以的
测试系统是centos, python3.7环境
python-docx 包是 python-docx==0.8.11
# 创建虚拟环境
python -m venv env
# 安装包
pip install python-docx==0.8.11
安装包的过程比较容易,没有过多的依赖

运行代码, 文档依然可以正常的生成!
unoconv -f pdf 测试文档生成.docx

doc 转pdf怎么使用
- 网上找了很多,完成该需求有些是需要依赖office的,比如最常见的docx2pdf 包,没有装office就忽略吧,换言之Linux系统上也先别想了!
from docx2pdf import convert
convert("input.docx", "output.pdf")
- stackoverflow上推荐的在Linux端需要提前安装Libreoffice,调用Libreoffice的功能。
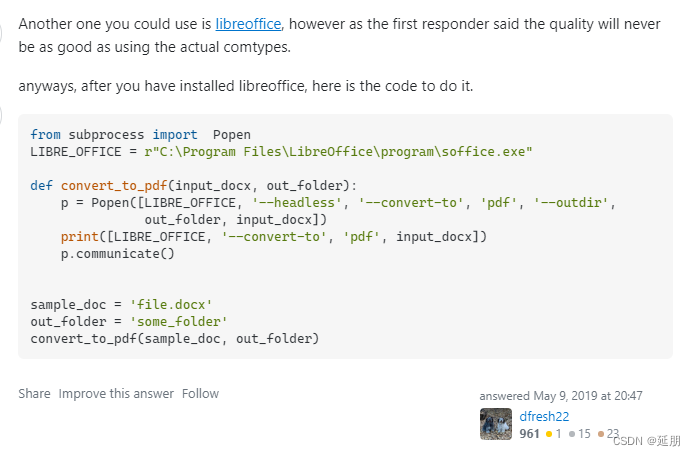
- Aspose包直接有python包可供调用,只是生成的pdf带有水印,需要购买。
import aspose.words as aw
doc = aw.Document("in.docx")
doc.save("out.pdf")
- unoconv 也是需要依赖Libreoffice,在安装此命令的时候能自动解决Libreoffice的依赖,不需要单独安装Libreoffice进行使用,相对比较方便。
- 常见问题
生成pdf乱码问题,需要向Linux中添加字体!
将Windows路径C:\Windows\Fonts 下的字体拷贝到 Linux路径/usr/share/fonts/ 中就能解决。
python-docx包处理文档
读取文档并添加表格
如下code,添加默认的表格。
from docx import Document
# 读取文档
document = Document('测试文档.docx')
# 添加表格
table = document.add_table(rows=7, cols=6)
# 将文档保存
document.save(os.path.join(os.getcwd(), '测试文档生成.docx'))
添加的表格如下图:
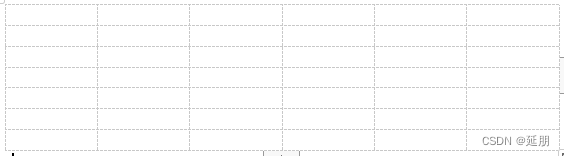
这肯定不是我们想要的表格, 我们想要的表格是:
- 有实线的边框
- 字体可以居中
- 能够根据数据来调整行数
下面是我写的代码:
import math
import os
from xml.dom.minidom import Element
from docx import Document
from docx.opc.oxml import parse_xml
from docx.oxml import OxmlElement
from docx.oxml.ns import qn, nsdecls
from docx.shared import RGBColor
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT, WD_TABLE_ALIGNMENT
import random
def set_cell_border(cell, **kwargs):
"""
Set cell`s border
Usage:
set_cell_border(
cell,
top={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
bottom={"sz": 12, "color": "#00FF00", "val": "single"},
left={"sz": 24, "val": "dashed", "shadow": "true"},
right={"sz": 12, "val": "dashed"},
)
"""
tc = cell._tc
tcPr = tc.get_or_add_tcPr()
# check for tag existnace, if none found, then create one
tcBorders = tcPr.first_child_found_in("w:tcBorders")
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# list over all available tags
for edge in ('left', 'top', 'right', 'bottom', 'insideH', 'insideV'):
edge_data = kwargs.get(edge)
if edge_data:
tag = 'w:{}'.format(edge)
# check for tag existnace, if none found, then create one
element = tcBorders.find(qn(tag))
if element is None:
element = OxmlElement(tag)
tcBorders.append(element)
# looks like order of attributes is important
for key in ["sz", "val", "color", "space", "shadow"]:
if key in edge_data:
element.set(qn('w:{}'.format(key)), str(edge_data[key]))
def add_table(table, data: dict):
pre = ['科目', '得分']
keys = list(data.keys())
cnt = 0
key = keys[0]
# 添加内容
for i, row in enumerate(table.rows):
for j, cell in enumerate(row.cells):
# 设置可以居中
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
set_cell_border(
cell,
top={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},
bottom={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},
left={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},
right={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},
# 注释的这两个参数能调整内边框
# insideH={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"},
# end={"sz": 0.5, "val": "single", "color": "#000000", "space": "0"}
)
# 获取单元格中的段落对象
paragraph = cell.paragraphs[0]
paragraph.alignment = WD_TABLE_ALIGNMENT.CENTER
if i == 0:
# 给边框填充背景
color: Element = parse_xml(r'<w:shd {} w:fill="{color_value}"/>'.format(
nsdecls('w'), color_value=RGBColor(0, 0, 139)))
cell._tc.get_or_add_tcPr().append(color)
# 和上面一样,这里的run可以设置一些属性
run = paragraph.add_run(pre[j % 2])
continue
if cnt < len(data):
if j % 2 == 0:
key = keys[cnt]
paragraph.add_run(key)
else:
paragraph.add_run(str(data[key]))
cnt += 1
document = Document('测试文档.docx')
data = {
'python': random.randint(80, 100),
'c++': random.randint(80, 100),
'golang': random.randint(80, 100),
'c': random.randint(80, 100),
'sql': random.randint(80, 100),
'java': random.randint(80, 100),
'javascript': random.randint(80, 100),
'mysql': random.randint(80, 100),
'neo4j': random.randint(80, 100),
'hive': random.randint(80, 100),
}
table = document.add_table(rows=math.ceil(len(data) / 3) + 1, cols=6)
add_table(table, data)
document.save(os.path.join(os.getcwd(), '测试文档生成.docx'))
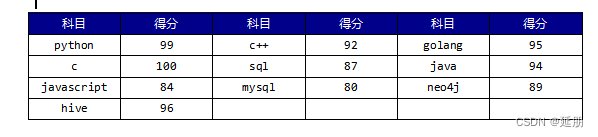
插入到docx文件的表格如下图所示:
借助docx中的样式添加内容
在模板docx中添加样式
添加了新的列表项目符号样式
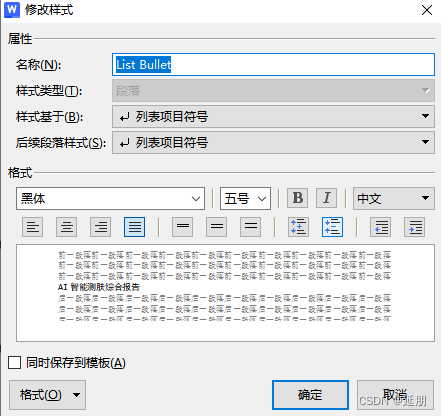
效果如下,给添加的内容加上 ·

代码中加载该文档,给需要生成的内容添加该样式:
from docx import Document
from docx.shared import Pt
# 读取文档
document = Document('测试文档.docx')
_ = document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
# 设置段前和段后的间距
_.paragraph_format.space_before = Pt(0)
_.paragraph_format.space_after = Pt(0)
添加其他样式同理。
表格单元格的宽度设置
from docx.shared import Cm, Inches
document = Document('测试文档.docx')
table = document.add_table(rows=7, cols=6)
table.autofit = False
table.columns[0].width = Inches(1.4)
table.columns[1].width = Inches(0.6)
table.columns[3].width = Inches(0.6)
table.columns[2].width = Inches(1.4)
table.columns[5].width = Inches(0.6)
table.columns[4].width = Inches(1.4)
插入图片
# 向已经有的段落添加图片
# width 参数用来调整图片的大小
document.paragraphs[2].add_run().add_picture("../qrcode.png", width=Cm(2.8))
# 直接插入图片
document.add_paragraph("在下面插入一张图片")
document.add_picture("../qrcode.png", width=Cm(2.8))
# 清理原有段落图片
document.paragraphs[1].clear()
欢迎关注,共同交流,后续有优化还会更新。

















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









