




 本文详细介绍Python中re模块的功能,包括多种匹配方法如search、findall等,并通过实例演示了不同模式匹配的效果,涵盖了基本匹配、重复模式、贪婪与非贪婪匹配等内容。
本文详细介绍Python中re模块的功能,包括多种匹配方法如search、findall等,并通过实例演示了不同模式匹配的效果,涵盖了基本匹配、重复模式、贪婪与非贪婪匹配等内容。
re模块中的函数
- re.search() 搜索文本中模式匹配的内容, 看代码:
import re
# 预先编译模式
regexes = [
re.compile(p)
for p in ['this', 'that']
]
text = 'Does this text match the pattern?'
# {!r}和{}的区别,发现前者输出的字符包含单引号,而后者则无
print('Text: {!r}\n'.format(text))
for regex in regexes:
print('Seeking "{}" ->'.format(regex.pattern),
end=' ')
# search 搜索匹配的模式
if regex.search(text):
print('match!')
else:
print('no match')
- re.findall() 来进行多重匹配, 返回的是与模式匹配的所有字符串.
- re.finditer()和re.findall() 功能相同,只不过返回的是匹配Match的实例。
re.findall() 示例:
import re
text = 'abbaaabbbbaaaaa'
pattern = 'ab'
for match in re.findall(pattern, text):
print('Found {!r}'.format(match), 'type: ', type(match))
输出:
Found 'ab' type: <class 'str'>
Found 'ab' type: <class 'str'>
re.finditer()编写测试正则表达式的函数。
import re
# 用来进行查询匹配的函数
def test_patterns(text, patterns):
"""
提供文本和模式,查找文本中所有的匹配的模式
text: string
patterns: list
"""
# Look for each pattern in the text and print the results
for pattern, desc in patterns:
print("'{}' ({})\n".format(pattern, desc))
print(" '{}'".format(text))
for match in re.finditer(pattern, text):
s = match.start()
e = match.end()
substr = text[s:e]
n_backslashes = text[:s].count('\\')
prefix = '.' * (s + n_backslashes)
print(" {}'{}'".format(prefix, substr))
print()
return
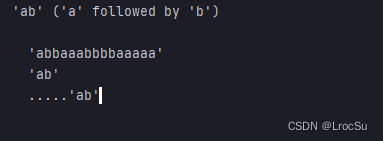
测试Demo和输出:
if __name__ == '__main__':
test_patterns('abbaaabbbbaaaaa',
[('ab', "'a' followed by 'b'"),
])
4. re.match() 匹配开头
5. re.fullmatch() 匹配整个字符串
6. search(text, pos)可以指定搜索的位置
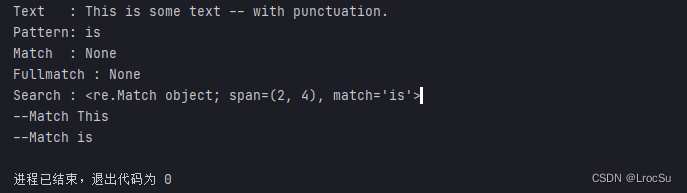
测试例子:
text = 'This is some text -- with punctuation.'
pattern = 'is'
print('Text :', text)
print('Pattern:', pattern)
# 匹配开头
m = re.match(pattern, text)
print('Match :', m)
# 匹配整个字符串
s = re.fullmatch(pattern, text)
print('Fullmatch :', s)
s = re.search(pattern, text)
print('Search :', s)
# search 可以指定搜索的位置
pattern2 = re.compile(r'\b\w*is\w*\b')
pos = 0
while True:
match = pattern2.search(text, pos)
if not match:
break
print("--Match", text[match.start():match.end()])
pos = match.end()
输出:
匹配格式
匹配符号
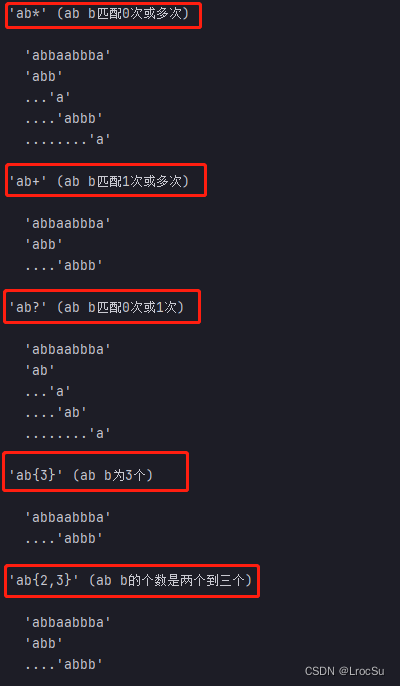
匹配模式中有五种匹配重复的符号, 调用上面的测试函数,见如下测试示例:
if __name__ == '__main__':
test_patterns(
'abbaabbba',
[('ab*', 'ab b匹配0次或多次'),
('ab+', 'ab b匹配1次或多次'),
('ab?', 'ab b匹配0次或1次'),
('ab{3}', 'ab b为3个'),
('ab{2,3}', 'ab b的个数是两个到三个')],
)
输出为:
其他符号:
# [ab] 匹配a或b
# ^代表排除 [^abc] 代表排除abc
# [A-Z] 包含所有大写的ASCII 字母
# [a-z] 包含所有小写的ASCII 字母
# . 模式应该匹配该位置的单个字符
# . 加重复符号 可以得到非常长的匹配 如 .* .*?
重要的转义码:
| 转义码 | 含义 |
|---|---|
| \d | 数字 |
| \D | 反过来 非数字 |
| \s | 空白符 (制表符、空格和换行) |
| \S | 非空白符 |
| \w | 字母数字 |
| \W | 非字母数字 |
正则中的锚定码:
| 锚定码 | 含义 |
|---|---|
| ^ | 字符串或行的开头 |
| $ | 字符串或行的结尾 |
| \A | 字符串开头 |
| \Z | 字符串末尾 |
| \b | 空串在开头或末尾 |
| \B | 空串不在开头或末尾 |
匹配的模式
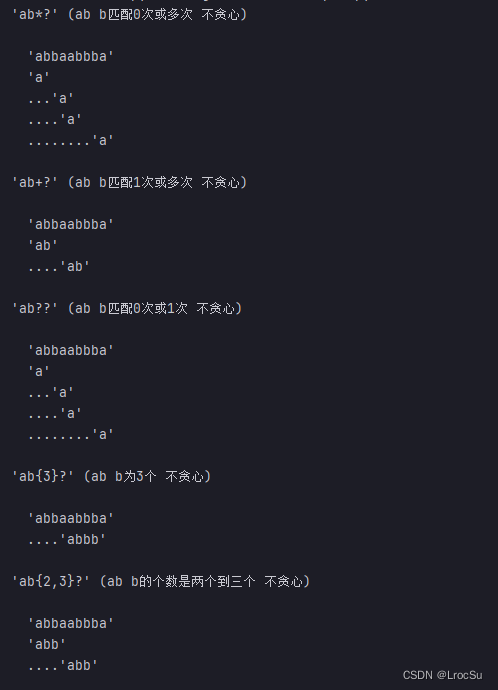
贪心模式【默认】:尽可能多的匹配
在匹配重复字符【*+?{}】后面加上?可以关闭这种贪心的方式
如下测试实例:
if __name__ == '__main__':
test_patterns(
'abbaabbba',
[('ab*?', 'ab b匹配0次或多次 不贪心'),
('ab+?', 'ab b匹配1次或多次 不贪心'),
('ab??', 'ab b匹配0次或1次 不贪心'),
('ab{3}?', 'ab b为3个 不贪心'),
('ab{2,3}?', 'ab b的个数是两个到三个 不贪心')],
)
如下是不贪心模式的输出:
实战测试
python中使用转义字符 \ 比较好的方式,加上r 前缀表示原始字符串。
测试锚定码:
test_patterns(
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球',
[
(r'^\w+', '锚定字符串的开头部分'),
(r'\A\w+', '锚定字符串的开头部分'),
(r'\w+\S*$', '锚定字符串的结尾部分'),
(r'\w+\S*\Z', '锚定字符串的结尾部分'),
(r'\w*用\w*', '锚定字符串中包含用的句子'),
(r'\b请\w+', '锚定字符串中以 请 字开头的句子'),
(r'\w杯\b', '锚定字符串中以 杯 字结尾的句子'),
(r'\B踢\B', '踢, 不在开始和结尾')
],
)
输出:
'^\w+' (锚定字符串的开头部分)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
'你好'
'\A\w+' (锚定字符串的开头部分)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
'你好'
'\w+\S*$' (锚定字符串的结尾部分)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
------------------------'加油踢球'
'\w+\S*\Z' (锚定字符串的结尾部分)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
------------------------'加油踢球'
'\w*用\w*' (锚定字符串中包含用的句子)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
----'本字符串用来展示案例'
'\b请\w+' (锚定字符串中以 请 字开头的句子)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
----------------'请关注世界杯'
'\w杯\b' (锚定字符串中以 杯 字结尾的句子)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
--------------------'界杯'
'\B踢\B' (t, not start or end of word)
'你好, 本字符串用来展示案例, 请关注世界杯, 加油踢球'
--------------------------'踢'
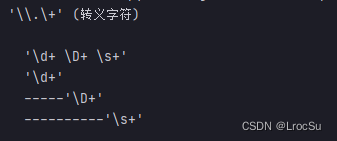
如何正则中匹配转义字符?
test_patterns(
r'\d+ \D+ \s+',
[(r'\\.\+', '转义字符')],
)
输出为:

















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









